A veces, cuando se desarrolla un producto de alta carga, surge una situación en la que es necesario procesar no tantas solicitudes como sea posible, sino limitar el número de solicitudes por unidad de tiempo. En nuestro caso, este es el número de notificaciones push enviadas a los usuarios finales. Lea más sobre algoritmos de limitación de velocidad, sus ventajas y desventajas, debajo del corte.
Primero, un poco sobre nosotros. Pushwoosh es un servicio b2b para la comunicación entre nuestros clientes y sus usuarios. Brindamos a las empresas soluciones integrales para comunicarse con los usuarios a través de notificaciones push, correo electrónico y otros canales de comunicación. Además de enviar mensajes, ofrecemos herramientas para segmentar la audiencia, recopilar y procesar estadísticas y mucho más. Para hacer esto, desde cero creamos un producto de alta carga en la unión de muchas tecnologías, de las cuales solo una pequeña parte son PHP, Golang, PostgreSQL, MongoDB, Apache Kafka. Muchas de nuestras soluciones son únicas, por ejemplo, notificaciones de alta velocidad. Procesamos más de 2 mil millones de solicitudes de API por día, tenemos más de 3 mil millones de dispositivos en nuestra base de datos y, durante todo el tiempo, enviamos más de 500 mil millones de notificaciones a estos dispositivos.
Y aquí llegamos a una situación en la que las notificaciones deben enviarse a millones de dispositivos no tan rápido como sea posible (como en la alta velocidad ya mencionada), pero limitando artificialmente la velocidad para que los servidores de nuestros clientes a los que irán los usuarios cuando abran la notificación no caigan al mismo tiempo carga
Aquí, varios algoritmos de limitación de velocidad nos ayudan, lo que nos permite limitar el número de solicitudes por unidad de tiempo. Como regla general, esto se usa, por ejemplo, al diseñar una API, ya que de esta manera podemos proteger el sistema del exceso accidental o malicioso de solicitudes, como resultado de lo cual se produce un retraso o denegación de servicio a otros clientes. Si se implementa la limitación de velocidad, todos los clientes están limitados a un número fijo de solicitudes por unidad de tiempo. Además, la limitación de velocidad se puede utilizar al acceder a partes del sistema asociadas con datos confidenciales; Por lo tanto, si un atacante obtiene acceso a ellos, entonces no podrá acceder rápidamente a todos los datos.
Hay muchas formas diferentes de implementar la limitación de velocidad. En este artículo, consideraremos los pros y los contras de varios algoritmos, así como los problemas que pueden surgir al escalar estas soluciones.
Algoritmos de límite de velocidad de procesamiento de solicitudes
Cubo con fugas (Cubo con fugas)
Leaky Bucket es un algoritmo que proporciona el enfoque más simple e intuitivo para limitar la velocidad de procesamiento mediante una cola, que puede representarse como un "bucket" que contiene solicitudes. Cuando se recibe una solicitud, se agrega al final de la cola. A intervalos regulares, se procesa el primer elemento de la cola. Esto también se conoce como la cola FIFO . Si la cola está llena, se descartan las solicitudes adicionales (o "fuga").

La ventaja de este algoritmo es que suaviza los arrebatos y procesa las solicitudes a aproximadamente la misma velocidad, es fácil de implementar en un solo servidor o equilibrador de carga, es eficiente en el uso de la memoria, ya que el tamaño de la cola para cada usuario es limitado.
Sin embargo, con un fuerte aumento en el tráfico, la cola puede llenarse con solicitudes antiguas y privar al sistema de la capacidad de procesar solicitudes más recientes. Tampoco garantiza que las solicitudes se procesen en un tiempo fijo. Además, si carga equilibradores para proporcionar tolerancia a fallas o aumentar el rendimiento, debe implementar una política de coordinación y garantizar la restricción global entre ellos.
Existe una variación de este algoritmo: Token Bucket ("cubo con tokens" o "algoritmo de cesta de marcadores").
En tal implementación, los tokens se agregan al "depósito" a una velocidad constante, y cuando se procesa la solicitud, el token del "depósito" se elimina; Si no hay suficientes tokens, la solicitud se descarta. Simplemente puede usar la marca de tiempo como tokens.
Existen variaciones utilizando varios "cubos", mientras que tanto los tamaños como la tasa de recepción de tokens en ellos pueden ser diferentes para "cubos" individuales. Si no hay suficientes tokens en el primer "depósito" para procesar la solicitud, entonces se verifica su presencia en el segundo, etc., pero la prioridad del procesamiento de la solicitud se reduce (como regla, esto se usa en el diseño de interfaces de red cuando, por ejemplo, puede cambiar el valor del campo Paquete procesado DSCP ).
La diferencia clave con la implementación de Leaky Bucket es que los tokens pueden acumularse cuando el sistema está inactivo y las ráfagas pueden suceder más tarde, mientras que las solicitudes se procesarán (ya que hay suficientes tokens), mientras que Leaky Bucket garantiza la suavización de la carga. incluso en caso de inactividad.
Ventana fija
Este algoritmo utiliza una ventana de n segundos para rastrear solicitudes. Por lo general, se utilizan valores como 60 segundos (minuto) o 3600 segundos (hora). Cada solicitud entrante aumenta el contador de esta ventana. Si el contador excede un cierto valor umbral, la solicitud se descarta. Típicamente, la ventana está determinada por el límite inferior del intervalo de tiempo actual, es decir, cuando la ventana tiene 60 segundos de ancho, la solicitud que llega a las 12:00:03 irá a la ventana 12:00:00.
La ventaja de este algoritmo es que proporciona el procesamiento de solicitudes más recientes, sin depender del procesamiento de las solicitudes anteriores. Sin embargo, una sola ráfaga de tráfico cerca del borde de la ventana puede duplicar el número de solicitudes procesadas, ya que permite solicitudes tanto para la ventana actual como para la siguiente por un corto período de tiempo. Además, si muchos usuarios están esperando que se restablezca el contador de la ventana, por ejemplo, al final de la hora, pueden provocar un aumento en la carga en este momento debido al hecho de que accederán a la API al mismo tiempo.
Registro deslizante
Este algoritmo implica el seguimiento de las marcas de tiempo de cada solicitud de usuario. Estos registros se almacenan, por ejemplo, en un conjunto o tabla hash y se ordenan por hora; los registros fuera del intervalo monitoreado se descartan. Cuando llega una nueva solicitud, calculamos el número de registros para determinar la frecuencia de las solicitudes. Si la solicitud está fuera de la cantidad permitida, se descarta.
La ventaja de este algoritmo es que no está sujeto a los problemas que surgen en los bordes de la ventana fija , es decir, se observará estrictamente el límite de velocidad. Además, dado que las solicitudes de cada cliente se monitorean individualmente, no hay crecimiento de carga máxima en ciertos puntos, lo cual es otro problema del algoritmo anterior.
Sin embargo, almacenar información sobre cada solicitud puede ser costoso, además, cada solicitud requiere calcular el número de solicitudes anteriores, potencialmente en todo el clúster, como resultado de lo cual este enfoque no se adapta bien para manejar grandes ráfagas de tráfico y ataques de denegación de servicio.
Ventana corredera
Este es un enfoque híbrido que combina el bajo costo de procesamiento de una ventana fija y el manejo avanzado de situaciones límite. Registro deslizante . Al igual que en la ventana fija simple, rastreamos el contador de cada ventana y luego tomamos en cuenta el valor ponderado de la frecuencia de solicitud de la ventana anterior en función de la marca de tiempo actual para suavizar las ráfagas de tráfico. Por ejemplo, si ha pasado el 25% del tiempo de la ventana actual, tenemos en cuenta el 75% de las solicitudes de la ventana anterior. La cantidad relativamente pequeña de datos necesarios para rastrear cada clave nos permite escalar y trabajar en un grupo grande.

Este algoritmo le permite escalar la limitación de velocidad, mientras mantiene un buen rendimiento. Además, esta es una forma comprensible de transmitir información sobre la limitación del número de solicitudes a los clientes, y también evita los problemas que surgen al implementar otros algoritmos de limitación de velocidad.
Limitación de velocidad en sistemas distribuidos
Políticas de sincronización
Si desea establecer la limitación de velocidad global al acceder a un clúster que consta de varios nodos, debe implementar una política de restricción. Si cada nodo rastreaba solo su propia restricción, entonces el usuario podría evitarla simplemente enviando solicitudes a diferentes nodos. De hecho, cuanto mayor sea el número de nodos, mayor será la probabilidad de que el usuario pueda superar el límite global.
La forma más fácil de establecer límites es configurar una "sesión fija" en el equilibrador para que el usuario se dirija al mismo nodo. Las desventajas de este método son la falta de tolerancia a fallas y problemas de escala cuando los nodos del clúster están sobrecargados.
La mejor solución, que permite reglas más flexibles para el equilibrio de carga, es utilizar un almacén de datos centralizado (de su elección). Puede almacenar contadores de la cantidad de solicitudes para cada ventana y usuario. Los principales problemas de este enfoque son el aumento del tiempo de respuesta debido a las solicitudes de almacenamiento y las condiciones de carrera.
Condiciones de carrera
Uno de los mayores problemas con un almacén de datos centralizado es la posibilidad de condiciones de carrera al competir. Esto sucede cuando utiliza el enfoque natural de obtener y establecer, en el que extrae el contador actual, lo incrementa y luego envía el valor resultante de vuelta a la tienda. El problema con este modelo es que durante el tiempo requerido para completar el ciclo completo de estas operaciones (es decir, leer, incrementar y escribir), pueden ingresar otras solicitudes, en cada una de las cuales el contador se almacenará con un valor no válido (inferior). Esto permite al usuario enviar más solicitudes de las que proporciona el algoritmo de limitación de velocidad.
Una forma de evitar este problema es establecer un bloqueo alrededor de la tecla en cuestión, evitando el acceso para leer o escribir cualquier otro proceso en el contador. Sin embargo, esto puede convertirse rápidamente en un cuello de botella de rendimiento y no se escala bien, especialmente cuando se utilizan servidores remotos, como Redis, como un almacén de datos adicional.
Un enfoque mucho mejor es "establecer - luego - obtener", basado en operadores atómicos, lo que le permite aumentar y verificar rápidamente los valores del contador sin interferir con las operaciones atómicas.
Optimización del rendimiento
Otra desventaja de usar un almacén de datos centralizado es el aumento en el tiempo de respuesta debido al retraso en la verificación de los contadores utilizados para implementar la limitación de velocidad (tiempo de ida y vuelta o "retraso de ida y vuelta "). Desafortunadamente, incluso verificar un almacenamiento rápido como Redis resultará en demoras adicionales de unos pocos milisegundos por solicitud.
Para definir una restricción con un retraso mínimo, es necesario realizar verificaciones en la memoria local. Esto se puede hacer relajando las condiciones para verificar la velocidad y eventualmente usando un modelo consistente.
Por ejemplo, cada nodo puede crear un ciclo de sincronización de datos en el que se sincronizará con el repositorio. Cada nodo transmite periódicamente el valor del contador para cada usuario y la ventana que afectó, a la tienda, que actualizará atómicamente los valores. Entonces el nodo puede recibir nuevos valores y actualizar datos en la memoria local. Este ciclo eventualmente permitirá que todos los nodos en el clúster estén actualizados.
El período durante el cual los nodos están sincronizados debe ser personalizable. Los intervalos de sincronización más cortos conducirán a una menor discrepancia de datos cuando la carga se distribuya de manera uniforme en varios nodos del clúster (por ejemplo, en el caso en que el equilibrador determine los nodos de acuerdo con el principio de "round-robin"), mientras que los intervalos más largos crean menos carga de lectura / escritura para el almacenamiento y reduzca el costo en cada nodo para recibir datos sincronizados.
Comparación de algoritmos de limitación de velocidad
Específicamente, en nuestro caso, no debemos rechazar las solicitudes de los clientes para la API, sino que sobre la base de los datos, por el contrario, no las creemos; sin embargo, no tenemos derecho a "perder" solicitudes. Para hacer esto, al enviar una notificación, utilizamos el parámetro send_rate, que indica el número máximo de notificaciones que enviaremos por segundo al enviar.
Por lo tanto, tenemos un cierto trabajador que realiza el trabajo en el tiempo asignado (en mi ejemplo, leyendo un archivo), que recibe la interfaz RateLimitingInterface como entrada, indicando si es posible ejecutar una solicitud en un momento dado y cuánto tiempo se ejecutará.
interface RateLimitingInterface { public function __construct(int $rate); public function canDoWork(float $currentTime): bool; }
Todos los ejemplos de código se pueden encontrar en GitHub aquí .
Explicaré de inmediato por qué necesita transferir un intervalo de tiempo a Worker. El hecho es que es demasiado costoso ejecutar un demonio separado para procesar el envío de un mensaje con un límite de velocidad, por lo que send_rate se usa realmente como parámetro "número de notificaciones por unidad de tiempo", que es 0.01 - 1 segundo dependiendo de la carga.
De hecho, procesamos hasta 100 solicitudes diferentes con send_rate por segundo, asignando 1 / N segundos para cada cantidad de tiempo, donde N es el número de empujones procesados por este demonio. El parámetro que más nos interesa durante el procesamiento es si se respetará send_rate (se permiten pequeños errores en una dirección u otra) y la carga en nuestro hardware (número mínimo de accesos al almacenamiento, consumo de CPU y memoria).
Para comenzar, averigüemos en qué momentos el trabajador realmente funciona. Para simplificar, este ejemplo procesó un archivo de 10,000 líneas con send_rate = 1000 (es decir, leemos 1000 líneas por segundo del archivo).
En las capturas de pantalla, los marcadores marcan los momentos y la cantidad de llamadas fgets para todos los algoritmos. En realidad, esto puede ser una apelación a una base de datos, un recurso de terceros o cualquier otra consulta, cuyo número queremos limitar por unidad de tiempo.
En la escala X: el tiempo desde el inicio del procesamiento, de 0 a 10 segundos, cada segundo se divide en décimas, por lo que el horario es de 0 a 100).
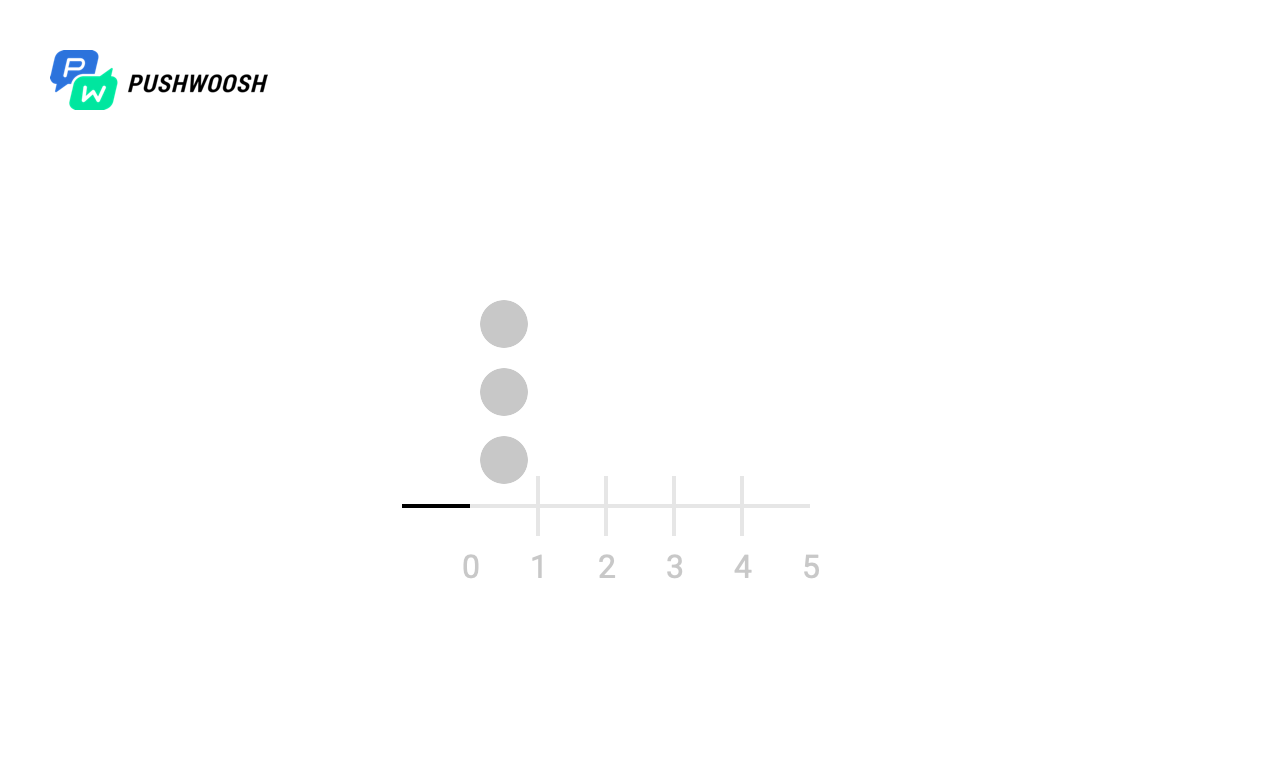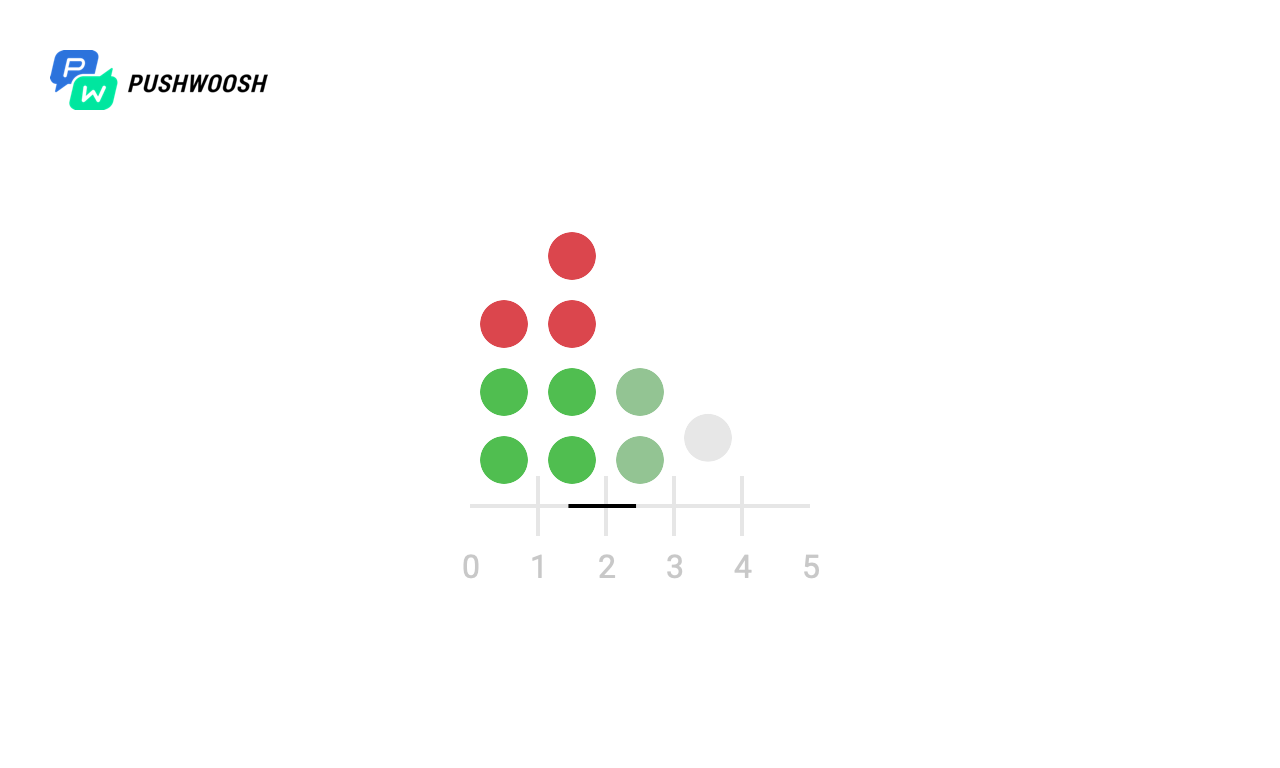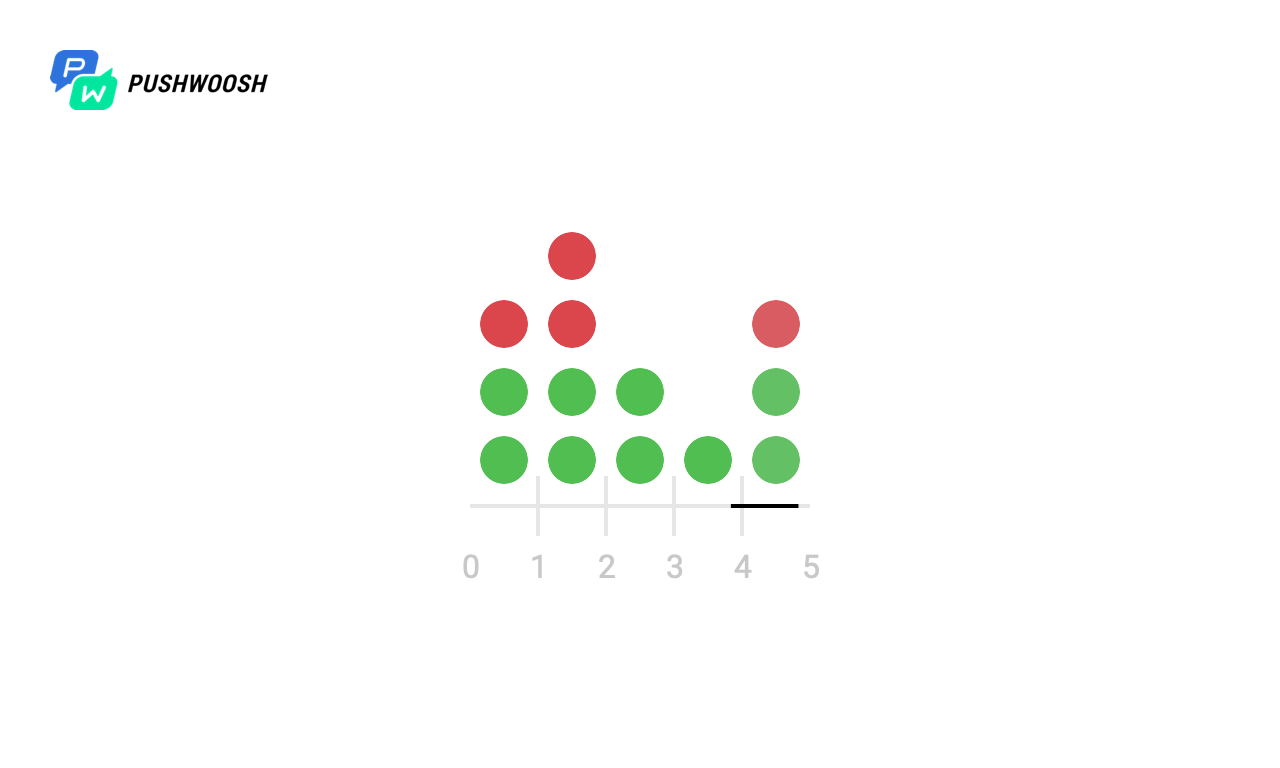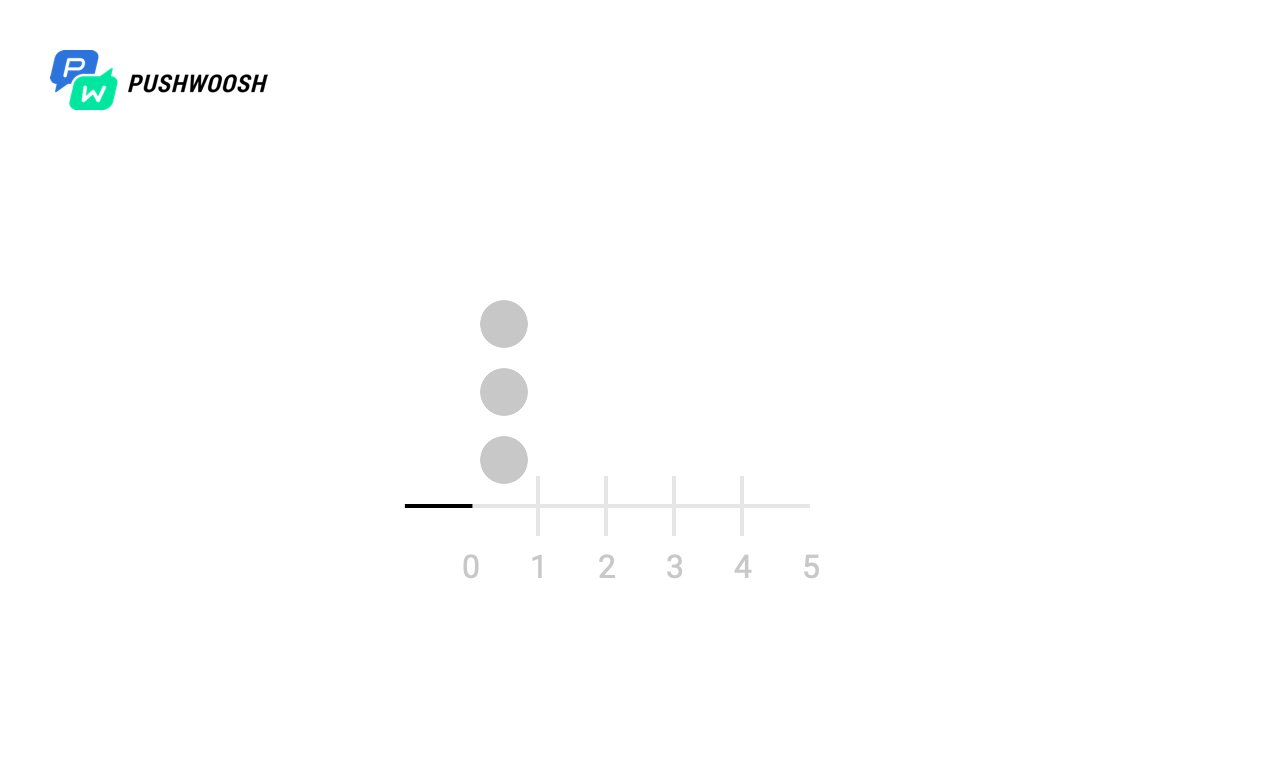
Vemos que a pesar del hecho de que todos los algoritmos hacen frente a la observancia de send_rate (para esto están destinados), la ventana fija y el registro deslizante "entregan" toda la carga casi simultáneamente, lo que no nos conviene mucho, mientras que Token Bucket y Sliding Windows lo distribuye uniformemente por unidad de tiempo (con la excepción de la carga máxima en el momento del inicio, debido a la falta de datos sobre la carga en momentos anteriores).
Debido al hecho de que, en realidad, el código generalmente no funciona con el sistema de archivos local, pero con un almacenamiento de terceros, la respuesta puede demorarse, puede haber problemas de red y muchos otros problemas, intentaremos verificar cómo se comportará este o aquel algoritmo cuando las solicitudes tarden un tiempo no fue Por ejemplo, después de 4 y 6 segundos.
Aquí, puede parecer que la ventana fija no funcionó correctamente y se procesó 2 veces más que las solicitudes esperadas en el primero y de 7 a 8 segundos, pero en realidad no es así, ya que el tiempo se cuenta desde el momento del lanzamiento en el gráfico, y el algoritmo usa la marca de tiempo de Unix actual .
En general, nada ha cambiado fundamentalmente, pero vemos que Token Bucket suaviza la carga más suavemente y nunca excede el límite de velocidad especificado, pero el registro deslizante en caso de tiempo de inactividad puede exceder el valor permitido.
Conclusión
Examinamos todos los algoritmos básicos para implementar la limitación de velocidad, cada uno de los cuales tiene sus pros y sus contras y es adecuado para diversas tareas. Esperamos que después de leer este artículo, elija el algoritmo más adecuado para resolver su problema.