¡Hola! Continuamos una serie de publicaciones dedicadas al lanzamiento del curso
"Desarrollador web en Python" y ahora estamos compartiendo con ustedes la traducción de otro artículo interesante.
En Zendesk, usamos Python para crear productos de aprendizaje automático. En las aplicaciones de aprendizaje automático, uno de los problemas más comunes que hemos encontrado es la pérdida de memoria y los picos. El código Python generalmente se ejecuta en contenedores que usan marcos de procesamiento distribuido como
Hadoop ,
Spark y
AWS Batch . A cada contenedor se le asigna una cantidad fija de memoria. Tan pronto como la ejecución del código exceda el límite de memoria especificado, el contenedor dejará de funcionar debido a errores que ocurren debido a la falta de memoria.

Puede solucionar el problema rápidamente asignando aún más memoria. Sin embargo, esto puede conducir al desperdicio de recursos y afectar la estabilidad de las aplicaciones debido a ráfagas de memoria impredecibles. Las causas de una pérdida de memoria pueden ser las
siguientes :
- Almacenamiento prolongado de objetos grandes que no se eliminan;
- Enlaces de bucle invertido en código;
- Base C bibliotecas / extensiones que conducen a la pérdida de memoria;
Es una buena práctica perfilar el uso de la memoria con las aplicaciones para comprender mejor la eficiencia del espacio de código y los paquetes utilizados.
Este artículo analiza los siguientes aspectos:
- Perfil de uso de memoria de la aplicación a lo largo del tiempo
- Cómo verificar el uso de memoria en una parte específica del programa;
- Consejos para la depuración de errores causados por problemas de memoria.
Perfiles de memoria con el tiempoPuede echar un vistazo al uso de memoria variable durante la ejecución de un programa Python usando el paquete
memory-profiler .
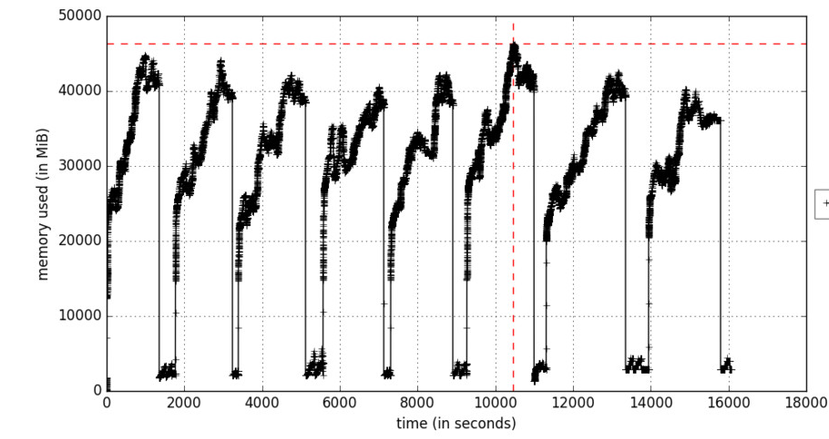 Figura A. Perfiles de memoria en función del tiempo
Figura A. Perfiles de memoria en función del tiempoLa
opción include-children habilitará el uso de memoria por parte de cualquier proceso hijo generado por procesos padres. La Figura A refleja el proceso de aprendizaje iterativo, que hace que la memoria aumente en ciclos en esos momentos cuando se procesan los paquetes de datos de entrenamiento. Los objetos se eliminan durante la recolección de basura.
Si el uso de memoria aumenta constantemente, esto se considera una amenaza potencial de pérdida de memoria.
Aquí hay un código de muestra que refleja esto:
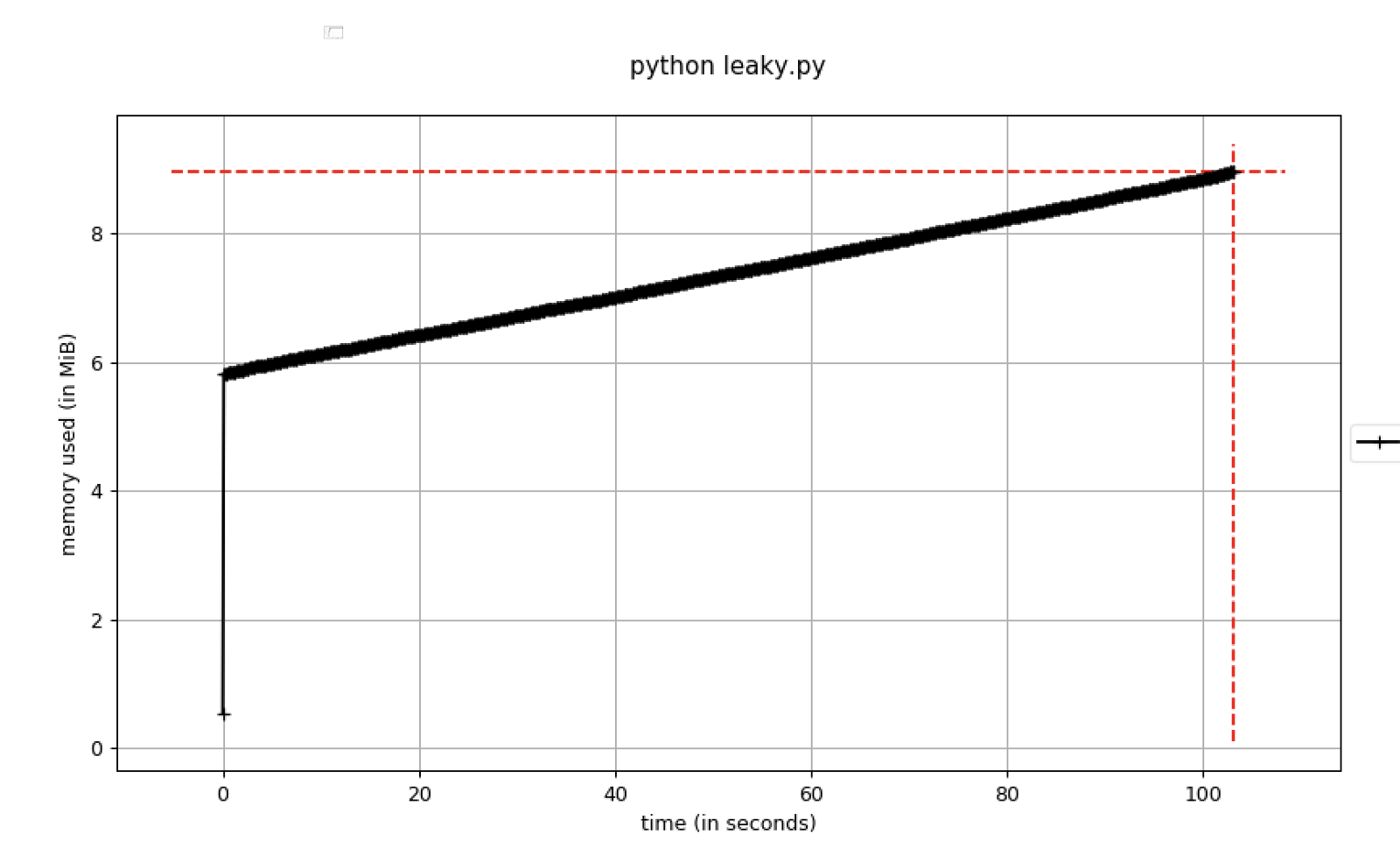 Figura B. El uso de memoria aumenta con el tiempo
Figura B. El uso de memoria aumenta con el tiempoDebe establecer puntos de interrupción en el depurador tan pronto como el uso de la memoria exceda un cierto umbral. Para hacer esto, puede usar el
parámetro pdb-mmem , que es conveniente durante la resolución de problemas.
Volcado de memoria en un momento específicoEs útil estimar el número esperado de objetos grandes en el programa y si deben duplicarse y / o convertirse a varios formatos.
Para un análisis más detallado de los objetos en la memoria, puede crear un montón de volcado en ciertas líneas del programa utilizando
muppy .
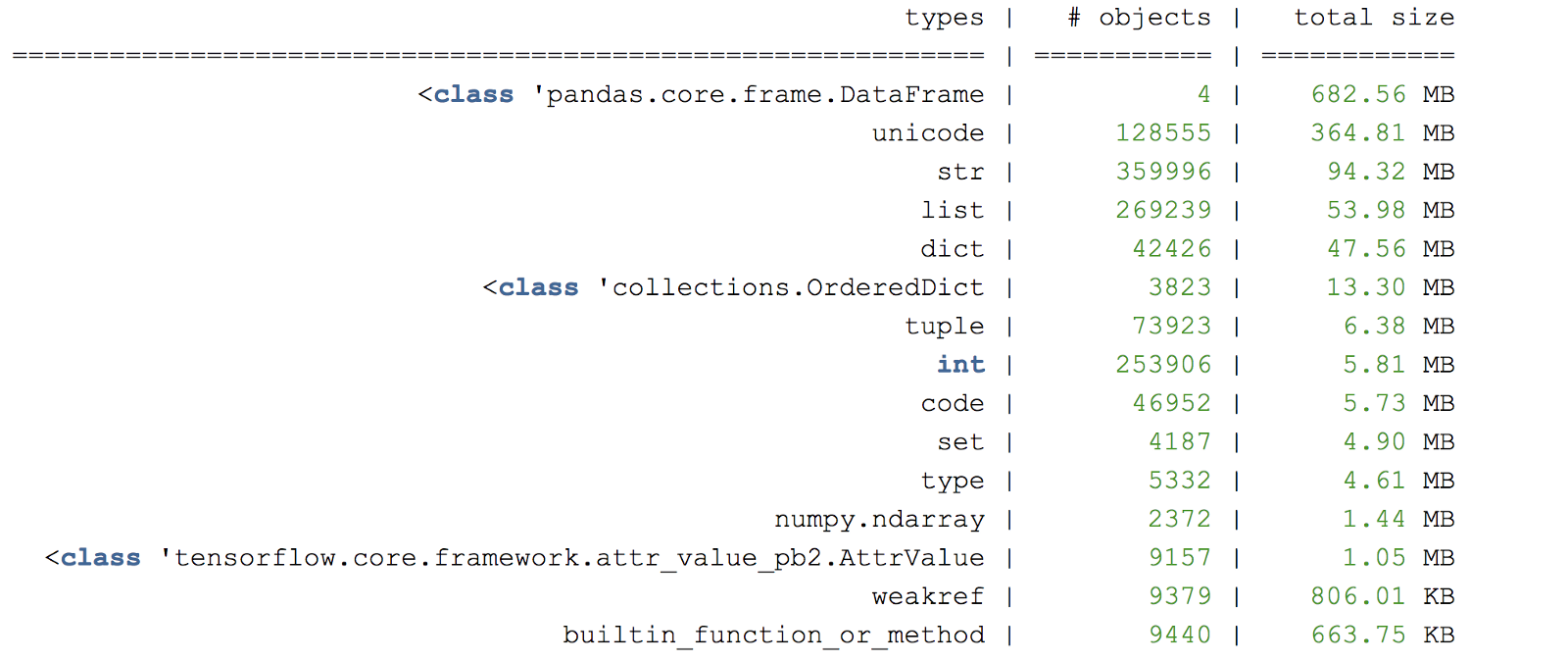 Figura C. Ejemplo de volcado de almacenamiento dinámico
Figura C. Ejemplo de volcado de almacenamiento dinámicoOtra biblioteca útil de creación de perfiles de memoria es
objgraph , que le permite generar gráficos para verificar el origen de los objetos.
Punteros útilesUn enfoque útil es crear un pequeño "caso de prueba" que ejecute el código apropiado que causa una pérdida de memoria. Considere usar un subconjunto de datos seleccionados al azar si la entrada completa tardará mucho tiempo en procesarse.
Realizar tareas con alta carga de memoria en un proceso separadoPython no necesariamente libera memoria inmediatamente para el sistema operativo. Para asegurarse de que se haya liberado la memoria, debe iniciar un proceso separado después de ejecutar un fragmento de código. Puede obtener más información sobre el recolector de basura en Python
aquí .
El depurador puede agregar referencias a objetos.Si
se usa un depurador de punto de interrupción como
pdb , todos los objetos creados a los que el depurador hace referencia manualmente permanecerán en la memoria. Esto puede crear una falsa sensación de pérdida de memoria, porque los objetos no se eliminan de manera oportuna.
Tenga cuidado con los paquetes que pueden causar pérdida de memoria.Algunas bibliotecas en Python pueden potencialmente causar una pérdida, por ejemplo,
pandas tiene varios problemas conocidos de
pérdida de memoria .
¡Que tengas una buena búsqueda de fugas!
Enlaces utiles:docs.python.org/3/c-api/memory.htmldocs.python.org/3/library/debug.htmlEscriba en los comentarios si este artículo le fue útil. Y aquellos que quieran aprender más sobre nuestro curso, los invitamos a
la jornada de puertas abiertas , que se realizará el 22 de abril.