
Desde 2008, nuestra empresa se ha dedicado principalmente a la gestión de infraestructura y al soporte técnico las 24 horas para proyectos web: tenemos más de 400 clientes, lo que representa aproximadamente el 15% del comercio electrónico en Rusia. En consecuencia, se admite una arquitectura muy diversa. Si algo cae, debemos arreglarlo en 15 minutos. Pero para entender que ha ocurrido un accidente, debe monitorear el proyecto y responder a los incidentes. Como hacerlo
Creo que la organización del sistema de monitoreo correcto está en problemas. Si no hubo problemas, mi discurso consistió en una tesis: "Instale Prometheus + Grafana y los complementos 1, 2, 3." Desafortunadamente, esto no funciona ahora. Y el principal problema es que todos siguen creyendo en algo que existía en 2008, en términos de componentes de software.
Con respecto a la organización del sistema de monitoreo, me arriesgo a decir que ... no existen proyectos con monitoreo competente. Y la situación es tan mala si algo cae, existe el riesgo de que pase desapercibido: todos están seguros de que "todo está siendo monitoreado".
Quizás todo está siendo monitoreado. Pero como?
Todos nos topamos con una historia similar a la siguiente: cierta despojo, cierto administrador está trabajando, un equipo de desarrollo se acerca a ellos y les dice: "lo tenemos, ahora está monitoreado". Que monitor Como funciona
Ok Hacemos un seguimiento de la manera antigua. Pero ya está cambiando, y resulta que usted monitoreó el servicio A, que se convirtió en el servicio B, que interactúa con el servicio C. Pero el equipo de desarrollo le dice: "¡Instale el software, debe monitorear todo!"
Entonces, ¿qué ha cambiado? - ¡Todo ha cambiado!
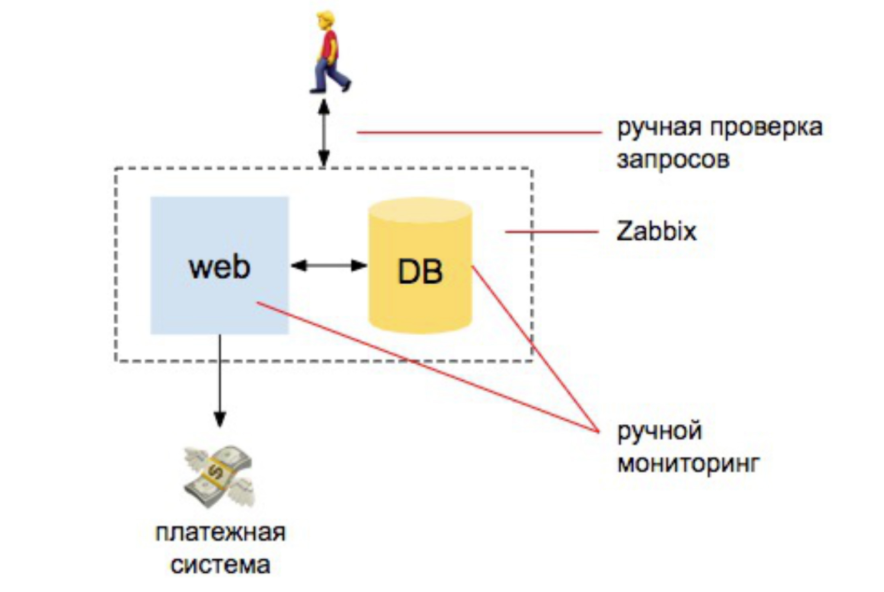
2008 año. Todo esta bien
Hay un par de desarrolladores, un servidor, un servidor de base de datos. A partir de aquí todo va. Tenemos algunos infa, ponemos zabbix, Nagios, cactus. Y luego establecemos alertas claras en la CPU, en el funcionamiento de los discos, en el lugar de los discos. También hacemos un par de comprobaciones manuales de que el sitio responde que los pedidos llegan a la base de datos. Y eso es todo, estamos más o menos protegidos.
Si comparamos la cantidad de trabajo que el administrador hizo para garantizar el monitoreo, entonces fue 98% automático: la persona que está monitoreando debería entender cómo instalar Zabbix, cómo configurarlo y configurar alertas. Y 2% - para verificaciones externas: que el sitio responda y solicite a la base de datos que hayan llegado nuevos pedidos.
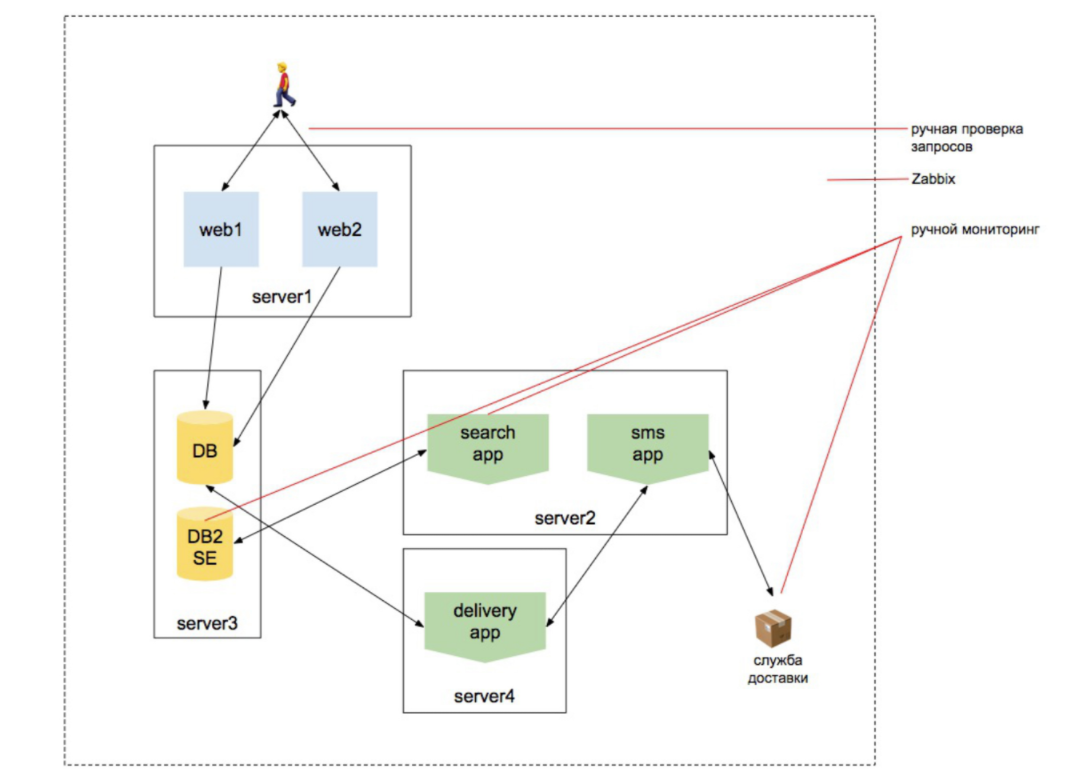
Año 2010. La carga está creciendo
Comenzamos a escalar la web, agregamos un motor de búsqueda. Queremos asegurarnos de que el catálogo de productos contenga todos los productos. Y esa búsqueda de productos funciona. Que la base de datos funciona, que se están haciendo pedidos, que el sitio responde externamente y que responde desde dos servidores, y que el usuario no es expulsado del sitio mientras está reequilibrando a otro servidor, etc. Hay más entidades.
Además, la entidad asociada con la infraestructura sigue siendo la más grande en la cabeza del gerente. Aún así, la idea se me ocurre que la persona que está monitoreando es la persona que instalará zabbix y podrá configurarlo.
Pero al mismo tiempo, hay trabajos para realizar verificaciones externas, crear un conjunto de scripts para consultar el indexador de búsqueda, un conjunto de scripts para verificar que la búsqueda cambia durante el proceso de indexación, un conjunto de scripts que verifican que los productos se transfieren al servicio de entrega, etc. etc.

Nota: Escribí un "conjunto de guiones" 3 veces. Es decir, la persona responsable de la supervisión ya no es la que solo instala zabbix. Esta es la persona que comienza a codificar. Pero nada ha cambiado en las mentes del equipo todavía.
Pero el mundo está cambiando, volviéndose cada vez más complicado. Una capa de virtualización, se agregan varios sistemas nuevos. Comienzan a interactuar entre ellos. ¿Quién dijo "huele a microservicios"? Pero cada servicio aún se ve individualmente como un sitio. Podemos recurrir a él y comprender que proporciona la información necesaria y trabaja por sí mismo. Y si usted es un administrador que participa constantemente en un proyecto que se ha estado desarrollando durante 5-7-10 años, tiene este conocimiento acumulado: aparece un nuevo nivel, se dio cuenta, aparece otro nivel, se dio cuenta ...
Pero rara vez alguien acompaña al proyecto durante 10 años.
Resumen de monitoreo del hombre
Supongamos que llegaste a una nueva startup que inmediatamente obtuvo 20 desarrolladores, escribió 15 microservicios y eres el administrador al que se le dice: "Construye un CI / CD. Por favor ". Usted construyó un CI / CD y de repente escuchó: "Es difícil para nosotros trabajar con la producción en el" cubo "sin comprender cómo funcionará la aplicación en él. Haznos una caja de arena en el mismo "cubo".
Haces un cajón de arena en este cubo. Inmediatamente le dicen: "Queremos una base de datos de etapas, que se actualice todos los días desde la producción, para comprender que funciona en la base de datos, pero al mismo tiempo no estropear la base de datos de producción".
Vives en todo eso. Faltan 2 semanas para el lanzamiento, te dicen: "Ahora todo sería monitoreado ..." Eso es supervisar la infraestructura del clúster, supervisar la arquitectura de microservicios, supervisar el trabajo con servicios externos ...
Y sus colegas se quitan de la cabeza un esquema tan familiar y dicen: “¡Entonces, aquí todo está claro! Instale un programa que lo supervise todo ". Sí: Prometheus + Grafana + complementos.
Y agregan al mismo tiempo: "Tienes dos semanas, asegúrate de que todo sea confiable".
En el montón de proyectos que vemos, se asigna una persona para el monitoreo. Imagine que queremos contratar a una persona durante 2 semanas para monitorear, y le escribiremos un currículum. ¿Qué habilidades debe poseer esta persona, dado todo lo que hemos dicho antes?
- Debe comprender el monitoreo y los detalles del trabajo de la infraestructura de hierro.
- Debe comprender los detalles específicos del monitoreo de Kubernetes (y todos quieren un "cubo", porque puedes ignorar todo, esconderte, porque el administrador lo resolverá), por sí mismo, su infraestructura y entender cómo monitorear las aplicaciones dentro.
- Debe comprender que los servicios se comunican entre sí de manera especial y conocer los detalles de la interacción de los servicios entre ellos. Es bastante realista ver un proyecto en el que algunos de los servicios se comunican sincrónicamente, porque no hay otra manera. Por ejemplo, el backend pasa a REST, en gRPC al servicio de catálogo, recibe una lista de productos y regresa. No puedes esperar aquí. Y con otros servicios, funciona de forma asíncrona. Transfiera el pedido al servicio de entrega, envíe una carta, etc.
¿Probablemente ya has navegado de todo esto? Y el administrador, que necesita monitorear esto, nadó aún más. - Debe poder planificar y planificar correctamente, a medida que el trabajo se vuelve más y más.
- Por lo tanto, debe crear una estrategia a partir del servicio creado para comprender cómo monitorearlo específicamente. Necesita una comprensión de la arquitectura del proyecto y su desarrollo + comprensión de las tecnologías utilizadas en el desarrollo.
Recordemos un caso absolutamente normal: parte de los servicios en php, parte de los servicios en Go, parte de los servicios en JS. De alguna manera trabajan entre ellos. De aquí proviene el término "microservicio": hay tantos sistemas separados que los desarrolladores no pueden entender el proyecto en su conjunto. Una parte del equipo escribe servicios en JS que funcionan por sí solos y no saben cómo funciona el resto del sistema. La otra parte escribe servicios en Python y no entra en la forma en que funcionan otros servicios, están aislados en su campo. Tercero: escribe servicios en php u otra cosa.
Todas estas 20 personas se dividen en 15 servicios, y solo hay un administrador que debe entender todo esto. Basta! acabamos de dividir el sistema en 15 microservicios, porque 20 personas no pueden entender todo el sistema.
Pero necesita ser monitoreado de alguna manera ...
Cual es el resultado? Como resultado, hay una persona que incluye todo lo que un equipo completo de desarrolladores no puede entender, y sin embargo, también debe saber y ser capaz de lo que hemos indicado anteriormente: infraestructura de hierro, infraestructura de Kubernetes, etc.
¿Qué puedo decir? Houston, tenemos problemas.
Monitorear un proyecto de software moderno es un proyecto de software en sí mismo
Desde la falsa creencia de que el monitoreo es software, tenemos fe en los milagros. Pero los milagros, por desgracia, no suceden. No puedes instalar zabbix y esperar a que todo funcione. No tiene sentido poner a Grafana y esperar que todo esté bien. La mayor parte del tiempo se dedicará a organizar controles sobre el funcionamiento de los servicios y su interacción entre ellos, controles sobre cómo funcionan los sistemas externos. De hecho, el 90% del tiempo se gastará no en escribir guiones, sino en el desarrollo de software. Y debe ser un equipo que entienda el trabajo del proyecto.
Si en esta situación se arroja a una persona para ser monitoreada, entonces ocurrirán problemas. Lo que está sucediendo en todas partes.
Por ejemplo, hay varios servicios que se comunican entre sí a través de Kafka. Llegó una orden, enviamos un mensaje sobre la orden a Kafka. Existe un servicio que escucha información sobre el pedido y realiza el envío de mercancías. Hay un servicio que escucha información sobre el pedido y envía una carta al usuario. Y luego todavía hay un montón de servicios, y comenzamos a confundirnos.
Y si todavía se lo da al administrador y a los desarrolladores en una etapa en la que queda poco tiempo antes del lanzamiento, una persona deberá comprender todo este protocolo. Es decir Un proyecto de esta escala lleva un tiempo considerable, y esto debería incorporarse al desarrollo del sistema.
Pero muy a menudo, especialmente en la grabación, en las startups, vemos cómo se pospone la supervisión hasta más tarde. “Ahora haremos la Prueba de concepto, comenzaremos con ella, la dejaremos caer, estamos listos para sacrificarnos. Y luego lo supervisaremos todo ”. Cuando (o si) el proyecto comienza a ganar dinero, la empresa quiere reducir aún más funciones, ya que comenzó a funcionar, por lo que debe ir más allá. Y está en el punto donde al principio necesita monitorear todo lo anterior, lo que no toma el 1% del tiempo, sino mucho más. Y, por cierto, los desarrolladores necesitarán monitoreo, y es más fácil ponerlos en nuevas funciones. Como resultado, se escriben nuevas características, todo está envuelto y usted está en un interminable punto muerto.
Entonces, ¿cómo monitorea un proyecto desde el principio, y qué sucede si tiene un proyecto que necesita monitorear, pero no sabe por dónde comenzar?
Primero, necesitas planear.
Digresión de letras: muy a menudo comienza con el monitoreo de la infraestructura. Por ejemplo, tenemos Kubernetes. Para empezar, colocamos Prometeo con Grafana, colocamos los complementos bajo la supervisión del "cubo". No solo los desarrolladores, sino también los administradores tienen una práctica desafortunada: "Instalaremos este complemento, y el complemento probablemente sepa cómo hacerlo". A la gente le gusta comenzar con acciones simples y comprensibles, en lugar de acciones importantes. Y la infraestructura de monitoreo es fácil.Primero, decida qué y cómo desea monitorear, y luego levante el instrumento, porque otras personas no pueden pensar por usted. Sí, ¿y deberían? Otras personas pensaban para sí mismas sobre el sistema universal, o no pensaban en absoluto cuando se escribió este complemento. Y el hecho de que este complemento tenga 5 mil usuarios no significa que traiga ningún beneficio. Tal vez se convertirá en el 5001 simplemente porque ya había 5.000 personas allí antes.
Si comenzó a monitorear la infraestructura y el back-end de su aplicación dejó de responder, todos los usuarios perderán contacto con la aplicación móvil. Un error saldrá volando. Ellos vendrán a ti y te dirán: "La aplicación no funciona, ¿qué haces aquí?" "Estamos monitoreando". - "¿Cómo monitorea si no ve que la aplicación no funciona?"
- Creo que es necesario comenzar a monitorear desde el punto de entrada del usuario. Si el usuario no ve que la aplicación está funcionando, eso es todo, es un error. Y el sistema de monitoreo debería advertir sobre esto en primer lugar.
- Y solo entonces podemos monitorear la infraestructura. O hazlo en paralelo. La infraestructura es más simple: aquí finalmente podemos instalar zabbix.
- Y ahora necesita ir a las raíces de la aplicación para comprender dónde no funciona.
Mi pensamiento principal es que el monitoreo debe ir en paralelo con el proceso de desarrollo. Si elimina el equipo de monitoreo para otras tareas (crear un CI / CD, cajas de arena, reorganizar la infraestructura), el monitoreo comenzará a retrasarse y es posible que nunca se ponga al día con el desarrollo (o tarde o temprano tendrá que detenerse).
Todo por niveles
Así es como veo la organización del sistema de monitoreo.
1) Nivel de aplicación:
- monitorear la lógica de negocios de la aplicación;
- monitorear las métricas de salud de los servicios;
- Monitoreo de integración.
2) Nivel de infraestructura:
- monitorear el nivel de orquestación;
- software de sistema de monitoreo;
- monitoreando el nivel de "hierro".
3) Una vez más, el nivel de aplicación, pero como producto de ingeniería:
- recopilación y monitoreo de registros de aplicaciones;
- APM
- rastreo.
4) Alertas:
- organización de un sistema de alerta;
- organización de un sistema de vigilancia;
- organización de una "base de conocimiento" y procesamiento de incidentes de flujo de trabajo.
Importante : ¡llegamos a la alerta no después, sino de inmediato! No es necesario comenzar a monitorear y "de alguna manera más tarde" pensar quién recibirá las alertas. Después de todo, cuál es la tarea de monitoreo: comprender dónde algo no funciona en el sistema y dejar que las personas adecuadas lo sepan. Si esto se deja hasta el final, las personas correctas descubrirán que algo va mal, solo llamando "nada funciona para nosotros".
Capa de aplicación: supervisión de la lógica empresarial
Aquí estamos hablando de verificar el hecho de que la aplicación funciona para el usuario.
Este nivel debe hacerse en la etapa de diseño. Por ejemplo, tenemos un Prometheus condicional: rastrea al servidor que se dedica a las comprobaciones, extrae el punto final y el punto final va y comprueba la API.
Cuando a menudo se les pide que supervisen la página principal para asegurarse de que el sitio funciona, los programadores le dan un lápiz que se puede extraer cada vez que necesite asegurarse de que la API funcione. Y los programadores en este momento todavía toman y escriben / api / test / helloworld
¿La única manera de asegurarse de que todo funcione? - no!
- Crear tales controles es esencialmente tarea de los desarrolladores. Las pruebas unitarias deben ser escritas por programadores que escriben código. Porque si combina esto con el administrador "Amigo, aquí hay una lista de protocolos de API para las 25 funciones, ¡por favor supervise todo!" - Nada funcionará.
- Si imprime "hola mundo", nadie sabrá nunca que la API debería y realmente funciona. Cada cambio en la API debería conducir a un cambio en las comprobaciones.
- Si ya tiene un desastre de este tipo, detenga las funciones y seleccione los desarrolladores que escribirán estos cheques, o concilie con las pérdidas, concilie que nada se verifica y caerá.
Consejos técnicos
- Asegúrese de organizar un servidor externo para organizar las inspecciones; debe asegurarse de que su proyecto sea accesible al mundo exterior.
- Organice la validación en todo el protocolo API, no solo en los puntos finales individuales.
- Cree un punto final prometeo con los resultados de la prueba.
Nivel de aplicación - Monitoreo de métricas de salud
Ahora estamos hablando de indicadores de salud externos de los servicios.
Decidimos monitorear todos los "bolígrafos" de la aplicación utilizando controles externos que llamamos desde un sistema de monitoreo externo. Pero estos son precisamente los "bolígrafos" que el usuario "ve". Queremos asegurarnos de que los servicios en sí mismos funcionen para nosotros. Aquí hay una historia mejor: K8s tiene controles de salud para que al menos el cubo se asegure de que el servicio funcione. Pero la mitad de los cheques que vi son la misma impresión "hola mundo". Es decir aquí tira una vez después del despliegue, le respondió que todo está bien, y eso es todo. Y el servicio, si descansa en su propia API, tiene una gran cantidad de puntos de entrada para la misma API, que también necesita ser monitoreada, porque queremos saber que funciona. Y ya lo estamos monitoreando por dentro.
Cómo implementarlo técnicamente correctamente: cada servicio establece un punto final sobre su rendimiento actual, y en los gráficos de Grafana (o cualquier otra aplicación) vemos el estado de todos los servicios.
- Cada cambio en la API debería conducir a un cambio en las comprobaciones.
- Cree un nuevo servicio de inmediato con métricas de salud.
- El administrador puede dirigirse a los desarrolladores y preguntarles "agrégueme un par de funciones para que entienda todo y agregue información sobre esto a mi sistema de monitoreo". Pero los desarrolladores suelen responder: "No agregaremos nada dos semanas antes del lanzamiento".
Que los gerentes de desarrollo sepan que habrá tales pérdidas, que los jefes de los gerentes de desarrollo también lo sepan. Porque cuando todo cae, alguien aún llamará y exigirá monitorear el "servicio en constante caída" (c) - Por cierto, seleccione desarrolladores para escribir complementos para Grafana; esta será una buena ayuda para los administradores.
Capa de aplicación - Monitoreo de integración
El monitoreo de integración se enfoca en monitorear la comunicación entre los sistemas críticos del negocio.
Por ejemplo, hay 15 servicios que se comunican entre sí. Estos ya no son sitios individuales. Es decir no podemos extraer el servicio por sí solo, get / helloworld y entender que el servicio está funcionando. Debido a que el servicio web para realizar un pedido debe enviar información sobre el pedido al bus, el servicio de almacén debe recibir este mensaje del bus y trabajar con él. Y el servicio de distribución de correo electrónico debería manejar esto de alguna manera más, etc.
En consecuencia, no podemos entender, hurgando en cada servicio individual, que todo esto funcione. Porque tenemos un determinado autobús a través del cual todo se comunica e interactúa.
Por lo tanto, esta etapa debe indicar la etapa de prueba de servicios para interactuar con otros servicios. Habiendo monitoreado a un agente de mensajes, no puede organizar el monitoreo de la comunicación. Si hay un servicio que emite datos y un servicio que los recibe, al monitorear a un corredor, solo veremos datos que vuelan de un lado a otro. Incluso si de alguna manera logramos monitorear la interacción de estos datos en el interior (que algún productor publique los datos, alguien los lea, esta transmisión continúa yendo a Kafka), aún no nos dará información si un servicio dio un mensaje en una versión, pero otro servicio no esperaba esta versión y la omitió. No lo sabremos porque los servicios nos dirán que todo funciona.
Como recomiendo hacer:
- Para comunicación sincrónica: el punto final ejecuta solicitudes de servicios relacionados. Es decir tomamos este punto final, sacamos la secuencia de comandos dentro del servicio, que va a todos los puntos y dice "Puedo tirar allí, y tirar allí, puedo tirar ..."
- Para la comunicación asincrónica: mensajes entrantes: el punto final verifica el bus en busca de mensajes de prueba y muestra el estado del procesamiento.
- Para comunicación asíncrona: mensajes salientes: el punto final envía mensajes de prueba al bus.
Como suele suceder: tenemos un servicio que arroja datos en el bus. Acudimos a este servicio y le pedimos que hable sobre su salud de integración. Y si el servicio necesita vender algún mensaje en otro lugar (WebApp), generará este mensaje de prueba. Y si extraemos el servicio del lado de Procesamiento de pedidos, primero publica algo que puede publicar de forma independiente, y si hay cosas dependientes, luego lee un conjunto de mensajes de prueba del bus, comprende que puede procesarlos, informarlo y , si es necesario, publíquelos más, y sobre esto dice: todo está bien, estoy vivo.
Muy a menudo escuchamos la pregunta "¿cómo podemos probar esto en los datos de combate?" Por ejemplo, estamos hablando del mismo servicio de pedido. La orden envía mensajes al almacén donde se cancelan las mercancías: no podemos probar esto en los datos de combate, porque "¡mis mercancías se cancelarán!" Salida: en la etapa inicial, planifique toda esta prueba. Tienes pruebas unitarias que se burlan. Por lo tanto, hágalo a un nivel más profundo, donde tendrá un canal de comunicación que no dañará el negocio.
Nivel de infraestructura
El monitoreo de infraestructura es lo que durante mucho tiempo se ha considerado monitoreo en sí mismo.
- El monitoreo de la infraestructura puede y debe iniciarse como un proceso separado.
- No debe comenzar por monitorear la infraestructura de un proyecto en funcionamiento, incluso si realmente lo desea. Esto es un dolor para todos los devops. "Primero monitorizo el clúster, monitorizo la infraestructura", es decir Primero, controlará lo que se encuentra debajo, pero no entrará en la aplicación. Porque la aplicación es algo incomprensible para la devopa. Se lo filtraron y él no comprende cómo funciona. Y comprende la infraestructura y comienza con ella. Pero no, siempre debe controlar primero la aplicación.
- . , , - . on-call, , « ». .
-
:
- ELK. . - , .
- APM. APM (NewRelic, BlackFire, Datadog). , - , .
- Tracing. , . , tracing — . – ! . Jaeger/Zipkin
- : . Grafana. PagerDuty. (, …). ,
- : ( , ). Oncall : , , , — ( — , : , ). , — (« — »), .
- « » workflow : , , . , — ; .
, :
- — Prometheus + Grafana;
- — ELK;
- APM Tracing — Jaeger (Zipkin).
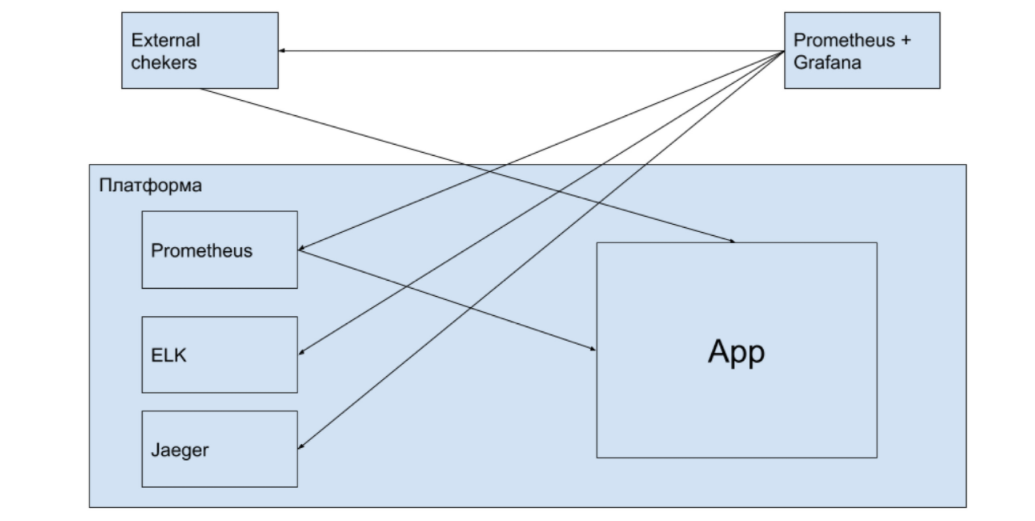
. , , , . , . , , , — .
, :
Prometheus Kubernetes — ?! , ? , , — , .
. . , Promtheus, , , . ? , , .
Conclusiones
- — , . 98% — . , , , --.
- : 30% , .
- , , - , — . , — .
- ( ) — .
- , , « » — , .
Saint Highload++.UPD ( ):
1. , , , «, , , ». , : DevOps , — , , , .
2. No estoy tratando de insinuar, dicen, "todo está mal en todas partes, pero aquí podemos monitorearlo, vengan a ITSumma". No, si se lanza el proyecto, el monitoreo no puede ser realizado por una compañía externa. Por supuesto, también tenemos objetivos comerciales, y lo que realmente estamos pensando hacer es introducir consultoría para apoyar el proyecto en el proceso de su desarrollo con el fin de transmitir cómo llevar a cabo adecuadamente la parte de monitoreo del desarrollo.Si está interesado en mis ideas y pensamientos al respecto, puede
leer el canal :-)