 Variti desarrolla protección contra bots y ataques DDoS, y también realiza pruebas de estrés y carga. En la conferencia HighLoad ++ 2018, hablamos sobre cómo proteger los recursos de varios tipos de ataques. En resumen: aísle partes del sistema, use servicios en la nube y CDN y actualice regularmente. Pero sin empresas especializadas, la protección aún no se puede hacer :)
Variti desarrolla protección contra bots y ataques DDoS, y también realiza pruebas de estrés y carga. En la conferencia HighLoad ++ 2018, hablamos sobre cómo proteger los recursos de varios tipos de ataques. En resumen: aísle partes del sistema, use servicios en la nube y CDN y actualice regularmente. Pero sin empresas especializadas, la protección aún no se puede hacer :)Antes de leer el texto, puede familiarizarse con breves resúmenes
en el sitio web de la conferencia .
Y si no le gusta leer o simplemente quiere ver un video, la grabación de nuestro informe se encuentra debajo del spoiler.
Muchas compañías ya saben cómo hacer pruebas de estrés, pero no todas lo hacen. Algunos de nuestros clientes piensan que su sitio es invulnerable porque tienen un sistema de alta carga y protege contra ataques. Mostramos que esto no es del todo cierto.
Por supuesto, antes de realizar las pruebas, obtenemos el permiso del cliente, firmado y sellado, y con nuestra ayuda no podemos hacer un ataque DDoS a nadie. Las pruebas se llevan a cabo en el momento elegido por el cliente, cuando la asistencia de su recurso es mínima y los problemas de acceso no afectarán a los clientes. Además, dado que algo siempre puede salir mal durante el proceso de prueba, tenemos contacto constante con el cliente. Esto permite no solo informar sobre los resultados alcanzados, sino también cambiar algo durante la prueba. Al final de las pruebas, siempre elaboramos un informe en el que señalamos los defectos descubiertos y damos recomendaciones para eliminar las debilidades del sitio.
Como trabajamos
Durante las pruebas, emulamos una botnet. Dado que trabajamos con clientes que no están ubicados en nuestras redes, para evitar que la prueba finalice en el primer minuto debido a la activación de límites o protección, cargamos la carga no desde una IP, sino desde nuestra propia subred. Además, para crear una carga significativa, tenemos nuestro propio servidor de prueba bastante potente.
Postulados
Mucho no es bueno
Cuanta menos carga podamos llevar al recurso al fracaso, mejor. Si logra que el sitio deje de funcionar desde una solicitud por segundo, o incluso desde una solicitud por minuto, está bien. Porque de acuerdo con la ley de la mezquindad, los usuarios o atacantes caen accidentalmente en esta vulnerabilidad.
La falla parcial es mejor que la falla completa
Siempre aconsejamos que los sistemas sean heterogéneos. Además, vale la pena separarlos a nivel físico, y no solo en contenedores. En el caso de la separación física, incluso si algo falla en el sitio, es probable que no deje de funcionar por completo, y los usuarios aún tendrán acceso a al menos parte de la funcionalidad.
La arquitectura adecuada es la base de la sostenibilidad.
La tolerancia a fallas de un recurso y su capacidad para resistir ataques y cargas deben establecerse en la etapa de diseño, de hecho, en la etapa de dibujar los primeros diagramas de bloques en un cuaderno. Porque si aparecen errores fatales, puedes corregirlos en el futuro, pero es muy difícil.
No solo el código debe ser bueno, sino también una configuración
Mucha gente piensa que un buen equipo de desarrollo es una garantía de resistencia de servicio. Es realmente necesario un buen equipo de desarrollo, pero también debe haber una buena operación, buenos DevOps. Es decir, necesitamos especialistas que configuren correctamente Linux y la red, escriban correctamente las configuraciones en nginx, configuren límites y más. De lo contrario, el recurso funcionará bien solo en la prueba, y en la producción en algún momento todo se romperá.
Diferencias entre estrés y pruebas de estrés
La prueba de carga le permite identificar los límites del sistema. La prueba de esfuerzo tiene como objetivo encontrar las debilidades del sistema y se utiliza para romper este sistema y ver cómo se comportará en el proceso de falla de ciertas partes. Al mismo tiempo, la naturaleza de la carga generalmente permanece desconocida para el cliente hasta el comienzo de las pruebas de tensión.
Características distintivas de los ataques L7
Por lo general, dividimos los tipos de carga en cargas a nivel de L7 y L3 y 4. L7 es una carga a nivel de aplicación, la mayoría de las veces se entiende solo como HTTP, pero nos referimos a cualquier carga a nivel de protocolo TCP.
Los ataques L7 tienen ciertas características distintivas. En primer lugar, llegan directamente a la aplicación, es decir, es poco probable que puedan reflejarse por medios de red. Tales ataques usan lógica, y debido a esto consumen CPU, memoria, disco, base de datos y otros recursos de manera muy eficiente y con poco tráfico.
Inundación HTTP
En el caso de cualquier ataque, la carga es más fácil de crear que de manejar, y en el caso de L7 esto también es cierto. El tráfico de ataque no siempre es fácil de distinguir del legítimo, y la mayoría de las veces se puede hacer por frecuencia, pero si todo se planifica correctamente, entonces es imposible entender dónde está el ataque y dónde están las solicitudes legítimas de los registros.
Como primer ejemplo, considere un ataque de inundación HTTP. El gráfico muestra que, por lo general, tales ataques son muy potentes, en el ejemplo a continuación, el número máximo de solicitudes superó los 600 mil por minuto.

HTTP Flood es la forma más fácil de crear una carga. Por lo general, se toma algún tipo de herramienta de prueba de carga, por ejemplo, ApacheBench, y se establecen la solicitud y el propósito. Con un enfoque tan simple, es probable que se encuentre con el almacenamiento en caché del servidor, pero es fácil moverse. Por ejemplo, agregar líneas aleatorias a la consulta, lo que obliga al servidor a proporcionar constantemente una nueva página.
Además, no se olvide del agente de usuario en el proceso de creación de una carga. Los administradores del sistema filtran muchos agentes de usuario de herramientas de prueba populares y, en este caso, la carga simplemente no llega al backend. Puede mejorar significativamente el resultado insertando un encabezado más o menos válido del navegador en la solicitud.
Para toda su simplicidad, los ataques HTTP Flood tienen sus inconvenientes. En primer lugar, se requieren grandes capacidades para crear una carga. En segundo lugar, tales ataques son muy fáciles de detectar, especialmente si provienen de la misma dirección. Como resultado, las solicitudes comienzan a ser filtradas inmediatamente por los administradores del sistema o incluso a nivel de proveedor.
Que buscar
Para reducir la cantidad de solicitudes por segundo y aún así no perder eficiencia, debe mostrar un poco de imaginación y explorar el sitio. Por lo tanto, puede cargar no solo el canal o el servidor, sino también partes individuales de la aplicación, por ejemplo, bases de datos o sistemas de archivos. También puede buscar lugares en el sitio que hagan grandes cálculos: calculadoras, páginas de selección de productos y más. Finalmente, a menudo sucede que hay un script php en el sitio que genera una página de varios cientos de miles de líneas. Tal script también carga mucho el servidor y puede convertirse en un objetivo para el ataque.
Donde mirar
Cuando escaneamos un recurso antes de probarlo, primero miramos, por supuesto, el sitio mismo. Estamos buscando todo tipo de campos de entrada, archivos pesados, en general, todo lo que puede crear problemas para un recurso y ralentiza su funcionamiento. Aquí, las herramientas de desarrollo comunes en Google Chrome y Firefox ayudan a mostrar el tiempo de respuesta de la página.
También escaneamos subdominios. Por ejemplo, hay una cierta tienda en línea, abc.com, y tiene un subdominio admin.abc.com. Lo más probable es que este sea el panel de administración con autorización, pero si le aplica una carga, puede crear problemas para el recurso principal.
El sitio puede tener un subdominio api.abc.com. Lo más probable es que este sea un recurso para aplicaciones móviles. La aplicación se puede encontrar en la App Store o Google Play, poner un punto de acceso especial, diseccionar la API y registrar cuentas de prueba. El problema es que a menudo las personas piensan que todo lo que está protegido por autorización es inmune a los ataques de denegación de servicio. Supuestamente, la autorización es el mejor CAPTCHA, pero no lo es. Hacer 10-20 cuentas de prueba es simple, y al crearlas, tenemos acceso a funciones complejas y sin disfraz.
Naturalmente, miramos el historial, en robots.txt y WebArchive, ViewDNS, estamos buscando versiones antiguas del recurso. A veces sucede que los desarrolladores implementaron, digamos, mail2.yandex.net, pero la versión anterior, mail.yandex.net, permaneció. Este mail.yandex.net ya no es compatible, no se le asignan recursos de desarrollo, pero continúa consumiendo la base de datos. En consecuencia, al usar la versión anterior, puede usar efectivamente los recursos del backend y todo lo que está detrás del diseño. Por supuesto, esto no siempre sucede, pero todavía encontramos algo como esto con bastante frecuencia.
Naturalmente, diseccionamos todos los parámetros de solicitud, estructura de cookies. Puede, por ejemplo, insertar algún valor en la matriz JSON dentro de la cookie, crear más anidamiento y hacer que el recurso funcione de manera irrazonablemente larga.
Buscar carga
Lo primero que viene a la mente cuando se investiga un sitio es cargar la base de datos, ya que casi todos tienen una búsqueda, y desafortunadamente casi todos la tienen, está pobremente protegida. Por alguna razón, los desarrolladores no prestan suficiente atención a la búsqueda. Pero hay una recomendación: no haga el mismo tipo de solicitudes, ya que puede encontrar el almacenamiento en caché, como es el caso de la inundación HTTP.
Hacer consultas aleatorias en la base de datos tampoco es siempre eficiente. Es mucho mejor crear una lista de palabras clave que sean relevantes para la búsqueda. Si vuelve al ejemplo de una tienda en línea: supongamos que el sitio vende neumáticos para automóviles y le permite establecer el radio de los neumáticos, el tipo de automóvil y otros parámetros. En consecuencia, las combinaciones de palabras relevantes harán que la base de datos funcione en condiciones mucho más complejas.
Además, vale la pena usar la paginación: es mucho más difícil para una búsqueda devolver la penúltima página de un problema que la primera. Es decir, con la ayuda de la paginación, puede diversificar un poco la carga.
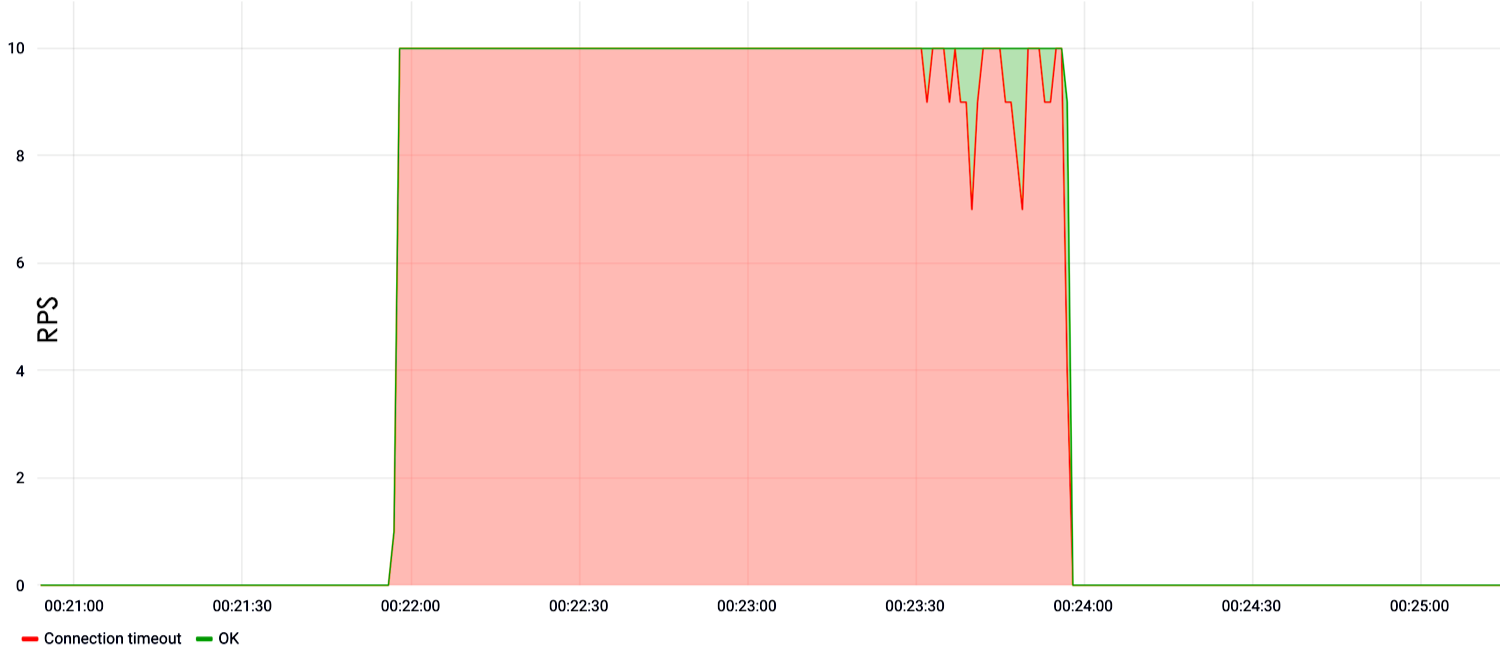
En el siguiente ejemplo, mostramos la carga en la búsqueda. Se puede ver que desde el primer segundo de la prueba a una velocidad de diez solicitudes por segundo, el sitio se cayó y no respondió.
Si no hay búsqueda?
Si no hay búsqueda, esto no significa que el sitio no contenga otros campos de entrada vulnerables. Este campo puede ser una autorización. Ahora a los desarrolladores les gusta crear hashes complejos para proteger la base de datos de inicio de sesión de los ataques a las tablas del arco iris. Esto es bueno, pero estos hashes consumen grandes recursos de CPU. Una gran cantidad de autorizaciones falsas conduce a una falla del procesador y, como resultado, el sitio deja de funcionar en la salida.
La presencia en el sitio de todo tipo de formularios para comentarios y comentarios es una ocasión para enviar textos muy grandes allí o simplemente crear una inundación masiva. A veces, los sitios aceptan archivos adjuntos, incluso en formato gzip. En este caso, tomamos un archivo de 1TB, usando gzip lo comprimimos a unos pocos bytes o kilobytes y lo enviamos al sitio. Luego se descomprime y se obtiene un efecto muy interesante.
API de descanso
Me gustaría prestar un poco de atención a servicios tan populares como la API Rest. Proteger la API Rest es mucho más difícil que un sitio normal. Para la API Rest, incluso los métodos triviales de protección contra el descifrado de contraseñas y otras actividades ilegítimas no funcionan.
La API Rest es muy fácil de romper porque accede a la base de datos directamente. Al mismo tiempo, la falla de dicho servicio conlleva consecuencias bastante serias para el negocio. El hecho es que la API Rest generalmente involucra no solo el sitio principal, sino también la aplicación móvil, algunos recursos comerciales internos. Y si todo esto cae, entonces el efecto es mucho más fuerte que en el caso del fallo de un sitio simple.
Carga de contenido pesado
Si se nos ofrece probar alguna aplicación normal de una página, página de inicio, sitio web de tarjetas de visita, que no tiene una funcionalidad compleja, estamos buscando contenido pesado. Por ejemplo, imágenes grandes que proporciona el servidor, archivos binarios, documentación en pdf: estamos tratando de extraerlo todo. Tales pruebas cargan bien el sistema de archivos y obstruyen los canales, y por lo tanto son efectivas. Es decir, incluso si no apaga el servidor, descargando un archivo grande a bajas velocidades, simplemente obstruirá el canal del servidor de destino y luego se producirá una denegación de servicio.
Un ejemplo de tal prueba muestra que a una velocidad de 30 RPS el sitio dejó de responder o generó 500 errores de servidor.

No te olvides de configurar servidores. A menudo puede encontrar que una persona compró una máquina virtual, instaló Apache allí, configuró todo de manera predeterminada, ubicó una aplicación php y, a continuación, puede ver el resultado.

Aquí la carga fue a la raíz y ascendió a solo 10 RPS. Esperamos 5 minutos y el servidor se bloqueó. Hasta el final, sin embargo, no se sabe por qué cayó, pero se supone que simplemente estaba lleno de memoria y, por lo tanto, dejó de responder.
Basado en olas
En el último año o dos, los ataques de olas se han vuelto bastante populares. Esto se debe al hecho de que muchas organizaciones compran ciertas piezas de hardware para protección contra DDoS, que requieren una cierta cantidad de estadísticas para comenzar a filtrar los ataques. Es decir, no filtran el ataque en los primeros 30-40 segundos, porque acumulan datos y aprenden. En consecuencia, en estos 30-40 segundos, puede iniciar tanto que el recurso permanecerá durante mucho tiempo hasta que todas las solicitudes se clasifiquen.
En el caso del ataque, hubo un intervalo de 10 minutos a continuación, después del cual llegó una parte nueva y modificada del ataque.

Es decir, la defensa entrenada, comenzó a filtrar, pero llegó una parte nueva y completamente diferente del ataque, y la defensa comenzó a entrenar nuevamente. De hecho, el filtrado deja de funcionar, la protección se vuelve ineficaz y el sitio es inaccesible.
Los ataques de olas se caracterizan por valores muy altos en el pico, puede alcanzar cien mil o un millón de solicitudes por segundo, en el caso de L7. Si hablamos de L3 y 4, entonces puede haber cientos de gigabits de tráfico o, en consecuencia, cientos de mpps, si cuenta en paquetes.
El problema con tales ataques es la sincronización. Los ataques provienen de una botnet, y para crear un pico único muy grande, se requiere un alto grado de sincronización. Y esta coordinación no siempre funciona: a veces la salida es una especie de pico parabólico, que parece bastante patético.
No HTTP unificado
Además de HTTP en el nivel L7, nos encanta explotar otros protocolos. Como regla general, un sitio web normal, especialmente un alojamiento regular, tiene protocolos de correo y MySQL sobresaliendo. Los protocolos de correo se ven menos afectados que las bases de datos, pero también se pueden cargar de manera bastante eficiente y obtener una CPU sobrecargada en el servidor en la salida.
Con la ayuda de la vulnerabilidad SSH 2016, tuvimos bastante éxito. Ahora esta vulnerabilidad se ha solucionado para casi todos, pero esto no significa que SSH no se pueda cargar. Usted puede Solo se sirve una gran cantidad de autorizaciones, SSH consume casi toda la CPU en el servidor, y luego el sitio web ya está compuesto de una o dos solicitudes por segundo.
En consecuencia, estas una o dos consultas de registro no se pueden distinguir de una carga legítima.
Las muchas conexiones que abrimos en los servidores siguen siendo relevantes. Anteriormente, Apache pecaba, ahora nginx realmente pecó, ya que a menudo se configura de manera predeterminada. El número de conexiones que nginx puede mantener abiertas es limitado, por lo que abrimos este número de conexiones, la nueva conexión nginx ya no acepta y el sitio no funciona en la salida.
Nuestro clúster de prueba tiene suficiente CPU para atacar el protocolo de enlace SSL. En principio, como muestra la práctica, a las botnets también les gusta hacer esto a veces. Por un lado, está claro que no puedes prescindir de SSL, debido a la emisión, clasificación y seguridad de Google. SSL, por otro lado, desafortunadamente tiene un problema de CPU.
L3 y 4
Cuando hablamos de un ataque en los niveles L3 y 4, generalmente hablamos de un ataque en el nivel del canal. Tal carga es casi siempre distinguible de legítima si no es un ataque de inundación SYN. El problema de los ataques de inundación SYN para las características de seguridad es grande. El valor máximo de L3 y 4 fue 1.5-2 Tb / s. Este tráfico es muy difícil de manejar incluso para grandes empresas, incluidas Oracle y Google.
SYN y SYN-ACK son los paquetes que se utilizan para establecer la conexión. Por lo tanto, es difícil distinguir SYN-flood de una carga legítima: no está claro que esto sea SYN, que vino a establecer la conexión, o parte de la inundación.
Inundación UDP
Por lo general, los atacantes no tienen las capacidades que tenemos nosotros, por lo que la amplificación se puede utilizar para organizar ataques. Es decir, un atacante escanea Internet y encuentra servidores vulnerables o configurados incorrectamente, que, por ejemplo, en respuesta a un paquete SYN, responden con tres SYN-ACK. Al falsificar la dirección de origen de la dirección del servidor de destino, puede usar un paquete para aumentar la capacidad, por ejemplo, tres veces, y redirigir el tráfico a la víctima.

El problema con las amplificaciones es su detección compleja. A partir de los últimos ejemplos, podemos citar el caso sensacional con la memoria caché vulnerable. Además, ahora hay muchos dispositivos IoT, cámaras IP, que también están configurados en su mayoría de manera predeterminada, y por defecto están configurados incorrectamente, por lo tanto, a través de dichos dispositivos, los atacantes suelen realizar ataques.

Inundación SYN difícil
SYN-flood es probablemente la vista más interesante de todos los ataques desde el punto de vista del desarrollador. El problema es que a menudo los administradores del sistema usan el bloqueo de IP para protección. Además, el bloqueo de IP afecta no solo a los administradores de sistemas que operan de acuerdo con los scripts, sino que, desafortunadamente, a algunos sistemas de seguridad que se compran por mucho dinero.
Este método puede convertirse en una catástrofe, porque si los atacantes cambian sus direcciones IP, la compañía bloqueará su propia subred. Cuando Firewall bloquea su propio clúster, las interacciones externas se bloquearán en la salida y el recurso se romperá.
Y lograr bloquear su propia red es fácil. Si la oficina del cliente tiene una red Wi-Fi, o si el estado de los recursos se mide usando varios monitores, entonces tomamos la dirección IP de este sistema de monitoreo o cliente de Wi-Fi de la oficina y la usamos como fuente. En la salida, el recurso parece estar disponible, pero las direcciones IP de destino están bloqueadas. Por lo tanto, la red Wi-Fi de la conferencia HighLoad, donde se presenta un nuevo producto de la compañía, puede bloquearse, y esto conlleva ciertos costos comerciales y económicos.
Durante las pruebas, no podemos usar la amplificación a través de la memoria caché de algunos recursos externos, porque existen acuerdos para suministrar tráfico solo a las direcciones IP permitidas. En consecuencia, usamos la amplificación a través de SYN y SYN-ACK, cuando el sistema responde enviando dos o tres SYN-ACK para enviar un SYN, y la salida se multiplica por dos o tres veces.
Las herramientas
Una de las principales herramientas que utilizamos para la carga en el nivel L7 es Yandex-tank. En particular, se utiliza un fantasma como arma, además hay varios scripts para generar cartuchos y analizar los resultados.
Tcpdump se usa para analizar el tráfico de red, y Nmap se usa para analizar el tráfico del servidor. Para crear una carga en el nivel L3 y 4, se utiliza OpenSSL y un poco de su propia magia con la biblioteca DPDK. DPDK es una biblioteca de Intel que le permite trabajar con una interfaz de red, evitando la pila de Linux y, por lo tanto, aumentando la eficiencia. Naturalmente, utilizamos DPDK no solo en el nivel L3 y 4, sino también en el nivel L7, porque le permite crear un flujo de carga muy alto, en unos pocos millones de solicitudes por segundo desde una máquina.
También utilizamos ciertos generadores de tráfico y herramientas especiales que escribimos para pruebas específicas. Si recordamos la vulnerabilidad bajo SSH, entonces con el conjunto anterior, no se puede escapar. Si atacamos el protocolo de correo, tomamos utilidades de correo o simplemente escribimos scripts en ellos.
Conclusiones
Como resultado, me gustaría decir:
- Además de la prueba de carga clásica, también se deben realizar pruebas de tensión. Tenemos un ejemplo del mundo real en el que un subcontratista asociado realizó solo pruebas de carga. Mostró que el recurso soporta la carga estándar. Pero luego apareció una carga anormal, los visitantes del sitio comenzaron a usar el recurso de manera un poco diferente, y en la salida el subcontratista estableció. Por lo tanto, vale la pena buscar vulnerabilidades incluso si ya está protegido de los ataques DDoS.
- Es necesario aislar algunas partes del sistema de otras. , , . , - . - , , , , OAuth2.
- .
- CDN , .
- . L3&4 , , , . L7 , . , - , .
- . , SSH daemon, . , , .