Ya nos hemos familiarizado con el
motor de indexación PostgreSQL y la interfaz de los métodos de acceso y hemos discutido los
índices hash ,
los árboles B , así como los índices
GiST y
SP-GiST . Y este artículo presentará el índice GIN.
Ginebra
"Gin? ... Gin es, al parecer, un licor tan americano? .."
"No soy un trago, ¡oh, chico curioso!" Una vez más, el viejo se encendió, otra vez se dio cuenta de sí mismo y otra vez se tomó de la mano. "No soy un trago, sino un espíritu poderoso e impávido, y no hay tal magia en el mundo que no pueda hacer".- Lazar Lagin, "Viejo Khottabych".
Gin significa índice invertido generalizado y debe considerarse como un genio, no una bebida.-
LÉAMEConcepto general
GIN es el índice invertido generalizado abreviado. Este es un llamado
índice invertido . Manipula los tipos de datos cuyos valores no son atómicos, sino que consisten en elementos. Llamaremos a estos tipos compuestos. Y estos no son los valores que se indexan, sino elementos individuales; cada elemento hace referencia a los valores en los que ocurre.
Una buena analogía de este método es el índice al final de un libro, que para cada término, proporciona una lista de páginas donde aparece este término. El método de acceso debe garantizar una búsqueda rápida de elementos indexados, al igual que el índice de un libro. Por lo tanto, estos elementos se almacenan como un
árbol B familiar (se usa una implementación diferente y más simple, pero no importa en este caso). Un conjunto ordenado de referencias a las filas de la tabla que contienen valores compuestos con el elemento está vinculado a cada elemento. El orden no es esencial para la recuperación de datos (el orden de clasificación de los TID no significa mucho), pero es importante para la estructura interna del índice.
Los elementos nunca se eliminan del índice GIN. Se supone que los valores que contienen elementos pueden desaparecer, surgir o variar, pero el conjunto de elementos de los que están compuestos es más o menos estable. Esta solución simplifica significativamente los algoritmos para el trabajo concurrente de varios procesos con el índice.
Si la lista de TID es bastante pequeña, puede caber en la misma página que el elemento (y se llama "la lista de publicación"). Pero si la lista es grande, se necesita una estructura de datos más eficiente, y ya estamos conscientes de ello: es B-tree nuevamente. Dicho árbol se encuentra en páginas de datos separadas (y se llama "el árbol de publicación").
Entonces, el índice GIN consiste en el árbol B de elementos, y los árboles B o listas planas de TID están vinculados a las filas de hojas de ese árbol B.
Al igual que los índices GiST y SP-GiST, discutidos anteriormente, GIN proporciona un desarrollador de aplicaciones con la interfaz para admitir varias operaciones sobre tipos de datos compuestos.
Búsqueda de texto completo
El área principal de aplicación para el método GIN es acelerar la búsqueda de texto completo, lo que, por lo tanto, es razonable usar como ejemplo en una discusión más detallada de este índice.
El artículo relacionado con GiST ya ha proporcionado una pequeña introducción a la búsqueda de texto completo, así que vayamos directamente al grano sin repeticiones. Está claro que los valores compuestos en este caso son
documentos , y los elementos de estos documentos son
lexemas .
Consideremos el ejemplo del artículo relacionado con GiST:
postgres=# create table ts(doc text, doc_tsv tsvector); postgres=# insert into ts(doc) values ('Can a sheet slitter slit sheets?'), ('How many sheets could a sheet slitter slit?'), ('I slit a sheet, a sheet I slit.'), ('Upon a slitted sheet I sit.'), ('Whoever slit the sheets is a good sheet slitter.'), ('I am a sheet slitter.'), ('I slit sheets.'), ('I am the sleekest sheet slitter that ever slit sheets.'), ('She slits the sheet she sits on.'); postgres=# update ts set doc_tsv = to_tsvector(doc); postgres=# create index on ts using gin(doc_tsv);
Una posible estructura de este índice se muestra en la figura:
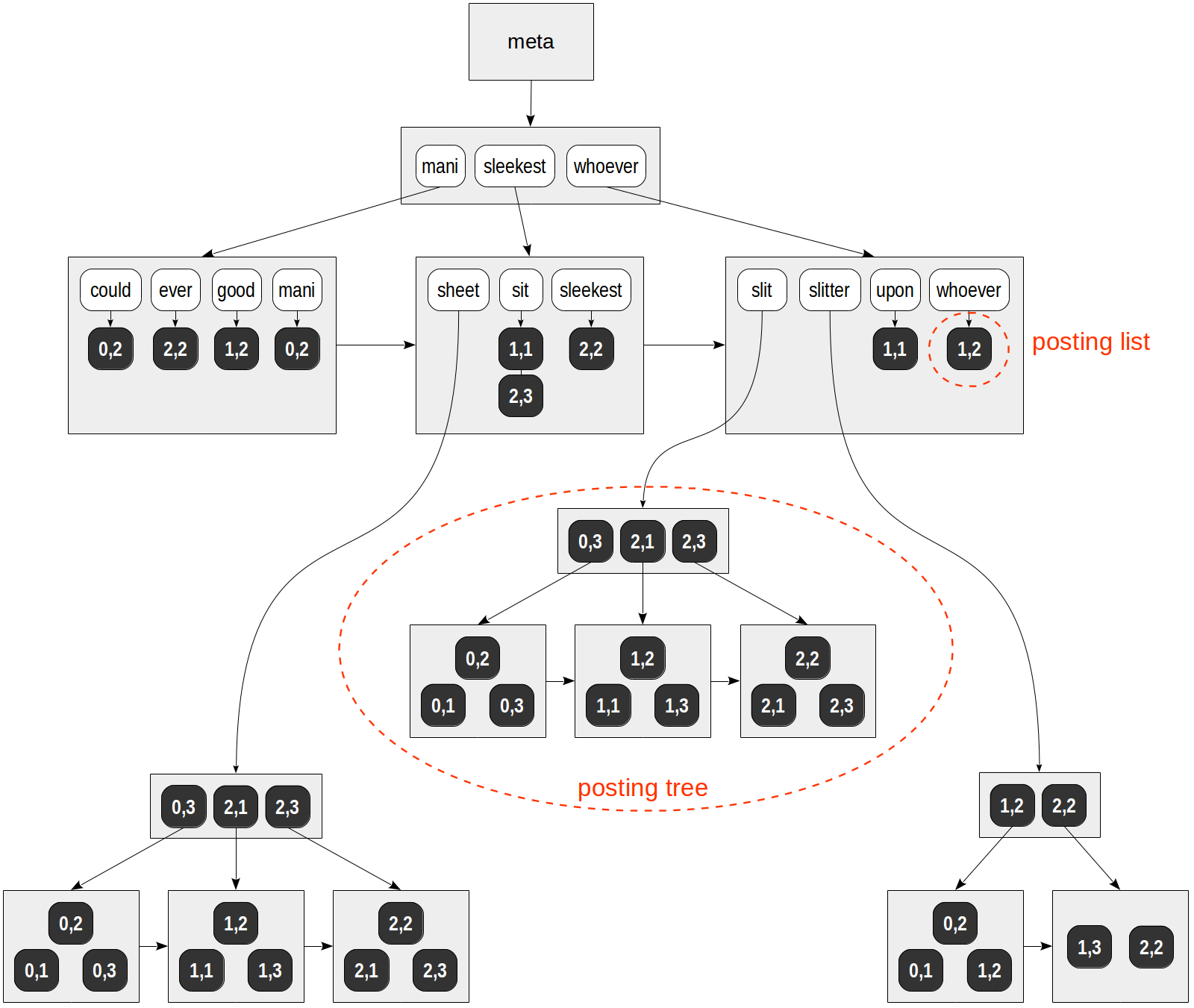
A diferencia de todas las figuras anteriores, las referencias a las filas de la tabla (TID) se denotan con valores numéricos sobre un fondo oscuro (el número de página y la posición en la página) en lugar de con flechas.
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
En este ejemplo especulativo, la lista de TID se ajusta a páginas regulares para todos los lexemas, excepto "hoja", "rendija" y "cortadora". Estos lexemas aparecieron en muchos documentos, y las listas de TID para ellos se han colocado en árboles B individuales.
Por cierto, ¿cómo podemos determinar cuántos documentos contienen un lexema? Para una mesa pequeña, una técnica "directa", que se muestra a continuación, funcionará, pero aprenderemos más qué hacer con las más grandes.
postgres=# select (unnest(doc_tsv)).lexeme, count(*) from ts group by 1 order by 2 desc;
lexeme | count ----------+------- sheet | 9 slit | 8 slitter | 5 sit | 2 upon | 1 mani | 1 whoever | 1 sleekest | 1 good | 1 could | 1 ever | 1 (11 rows)
Tenga en cuenta también que, a diferencia de un árbol B normal, las páginas del índice GIN están conectadas por una lista unidireccional en lugar de una bidireccional. Esto es suficiente ya que el recorrido de un árbol se realiza de una sola manera.
Ejemplo de consulta
¿Cómo se realizará la siguiente consulta para nuestro ejemplo?
postgres=# explain(costs off) select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) (4 rows)
Los lexemas individuales (claves de búsqueda) se extraen primero de la consulta: "mani" y "slitter". Esto se realiza mediante una función API especializada que tiene en cuenta el tipo de datos y la estrategia determinados por la clase de operador:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'tsvector_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- @@(tsvector,tsquery) | 1 matching search query @@@(tsvector,tsquery) | 2 synonym for @@ (for backward compatibility) (2 rows)
En el árbol B de lexemas, a continuación encontramos ambas claves y revisamos listas listas de TID. Obtenemos:
para "mani" - (0,2).
para "cortadora" - (0,1), (0,2), (1,2), (1,3), (2,2).
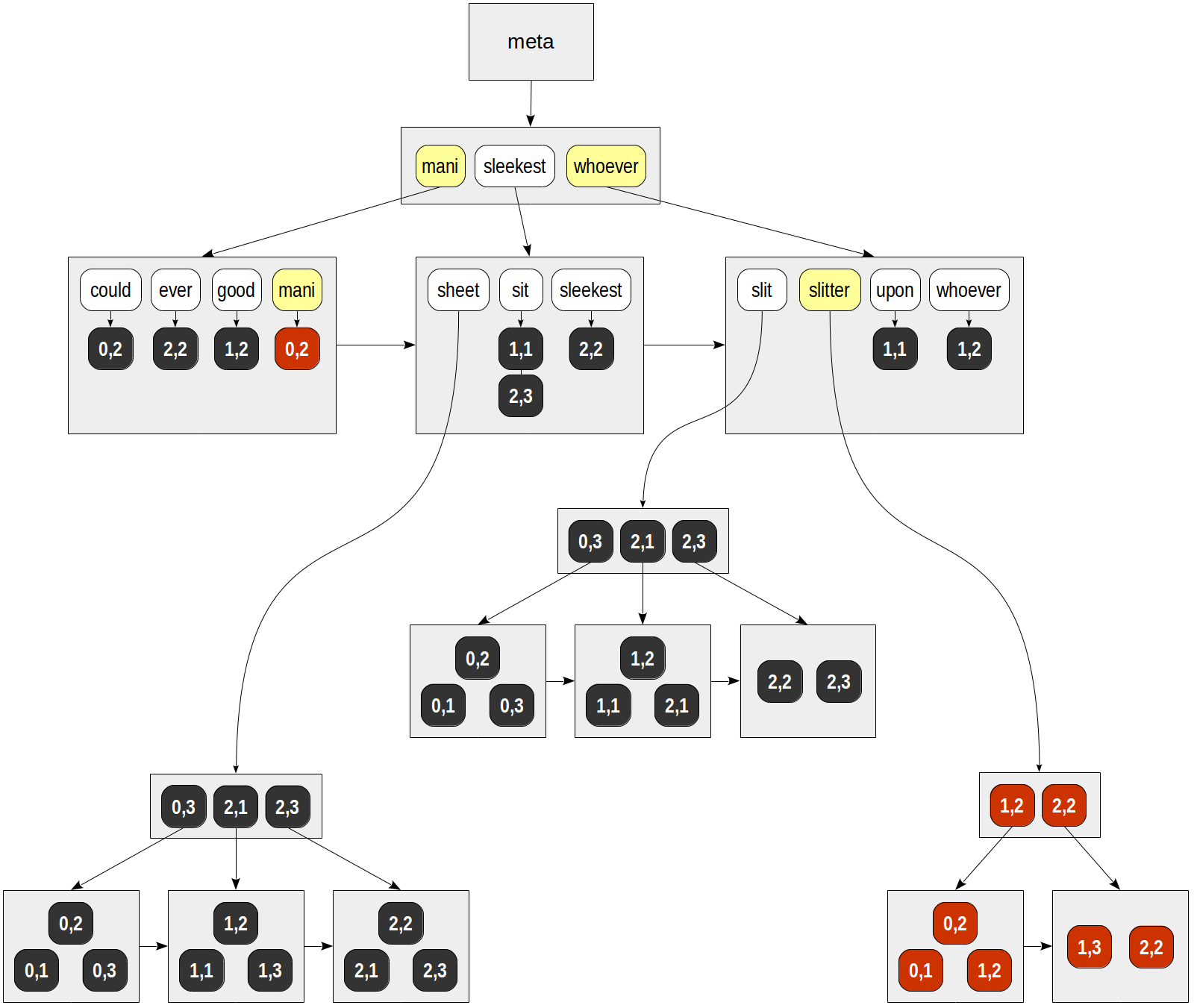
Finalmente, para cada TID encontrado, se llama a una función de coherencia API, que debe determinar cuál de las filas encontradas coincide con la consulta de búsqueda. Dado que los lexemas en nuestra consulta están unidos por Boolean "y", la única fila devuelta es (0,2):
| | | consistency | | | function TID | mani | slitter | slit & slitter -------+------+---------+---------------- (0,1) | f | T | f (0,2) | T | T | T (1,2) | f | T | f (1,3) | f | T | f (2,2) | f | T | f
Y el resultado es:
postgres=# select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
doc --------------------------------------------- How many sheets could a sheet slitter slit? (1 row)
Si comparamos este enfoque con el ya discutido para GiST, la ventaja de GIN para la búsqueda de texto completo parece evidente. Pero hay más en esto de lo que parece.
El problema de una actualización lenta
La cuestión es que la inserción o actualización de datos en el índice GIN es bastante lenta. Cada documento generalmente contiene muchos lexemas para indexar. Por lo tanto, cuando solo se agrega o actualiza un documento, tenemos que actualizar masivamente el árbol de índice.
Por otro lado, si varios documentos se actualizan simultáneamente, algunos de sus lexemas pueden ser iguales, y la cantidad total de trabajo será menor que cuando se actualizan los documentos uno por uno.
El índice GIN tiene un parámetro de almacenamiento "fastupdate", que podemos especificar durante la creación del índice y actualizarlo más tarde:
postgres=# create index on ts using gin(doc_tsv) with (fastupdate = true);
Con este parámetro activado, las actualizaciones se acumularán en una lista desordenada separada (en páginas conectadas individuales). Cuando esta lista se hace lo suficientemente grande o durante la aspiración, todas las actualizaciones acumuladas se realizan instantáneamente en el índice. La lista para considerar "suficientemente grande" está determinada por el parámetro de configuración "gin_pending_list_limit" o por el parámetro de almacenamiento del mismo nombre del índice.
Pero este enfoque tiene inconvenientes: primero, la búsqueda se ralentiza (ya que la lista desordenada debe revisarse además del árbol) y, en segundo lugar, una próxima actualización puede llevar mucho tiempo inesperadamente si la lista desordenada se ha desbordado.
Búsqueda de una coincidencia parcial
Podemos usar la coincidencia parcial en la búsqueda de texto completo. Por ejemplo, considere la siguiente consulta:
gin=# select doc from ts where doc_tsv @@ to_tsquery('slit:*');
doc -------------------------------------------------------- Can a sheet slitter slit sheets? How many sheets could a sheet slitter slit? I slit a sheet, a sheet I slit. Upon a slitted sheet I sit. Whoever slit the sheets is a good sheet slitter. I am a sheet slitter. I slit sheets. I am the sleekest sheet slitter that ever slit sheets. She slits the sheet she sits on. (9 rows)
Esta consulta encontrará documentos que contienen lexemas que comienzan con "hendidura". En este ejemplo, tales lexemas son "slit" y "slitter".
Una consulta ciertamente funcionará de todos modos, incluso sin índices, pero GIN también permite acelerar la siguiente búsqueda:
postgres=# explain (costs off) select doc from ts where doc_tsv @@ to_tsquery('slit:*');
QUERY PLAN ------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) (4 rows)
Aquí, todos los lexemas que tienen el prefijo especificado en la consulta de búsqueda se buscan en el árbol y se unen mediante booleano "o".
Lexemas frecuentes e infrecuentes
Para ver cómo funciona la indexación en los datos en vivo, tomemos el archivo del correo electrónico "pgsql-hackers", que ya hemos utilizado al analizar GiST.
Esta versión del archivo contiene 356125 mensajes con la fecha de envío, asunto, autor y texto.
fts=# alter table mail_messages add column tsv tsvector; fts=# update mail_messages set tsv = to_tsvector(body_plain);
NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... UPDATE 356125
fts=# create index on mail_messages using gin(tsv);
Consideremos un lexema que ocurre en muchos documentos. La consulta que utiliza "unnest" no funcionará en un tamaño de datos tan grande, y la técnica correcta es utilizar la función "ts_stat", que proporciona la información sobre lexemas, la cantidad de documentos donde ocurrieron y la cantidad total de ocurrencias.
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') order by ndoc desc limit 3;
word | ndoc -------+-------- re | 322141 wrote | 231174 use | 176917 (3 rows)
Vamos a elegir "escribió".
Y tomaremos algunas palabras que no son frecuentes para el correo electrónico de los desarrolladores, digamos "tatuaje":
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') where word = 'tattoo';
word | ndoc --------+------ tattoo | 2 (1 row)
¿Hay algún documento donde ocurran ambos lexemas? Parece que hay:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row)
Surge una pregunta sobre cómo realizar esta consulta. Si obtenemos listas de TID para ambos lexemas, como se describió anteriormente, la búsqueda evidentemente será ineficiente: tendremos que pasar por más de 200 mil valores, de los cuales solo quedará uno. Afortunadamente, utilizando las estadísticas del planificador, el algoritmo comprende que el lexema "escrito" ocurre con frecuencia, mientras que el "tatuaje" ocurre con poca frecuencia. Por lo tanto, se realiza la búsqueda del lexema infrecuente, y los dos documentos recuperados se comprueban para detectar la aparición del lexema "escrito". Y esto queda claro en la consulta, que se realiza rápidamente:
fts=# \timing on fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row) Time: 0,959 ms
La búsqueda de "escrito" solo lleva mucho más tiempo:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count -------- 231174 (1 row) Time: 2875,543 ms (00:02,876)
Esta optimización ciertamente funciona no solo para dos lexemas, sino también en casos más complejos.
Limitar el resultado de la consulta
Una característica del método de acceso GIN es que el resultado siempre se devuelve como un mapa de bits: este método no puede devolver el resultado TID por TID. Es por esto que todos los planes de consulta en este artículo usan escaneo de mapa de bits.
Por lo tanto, la limitación del resultado del análisis de índice utilizando la cláusula LIMIT no es del todo eficiente. Preste atención al costo previsto de la operación (campo "costo" del nodo "Límite"):
fts=# explain (costs off) select * from mail_messages where tsv @@ to_tsquery('wrote') limit 1;
QUERY PLAN ----------------------------------------------------------------------------------------- Limit (cost=1283.61..1285.13 rows=1) -> Bitmap Heap Scan on mail_messages (cost=1283.61..209975.49 rows=137207) Recheck Cond: (tsv @@ to_tsquery('wrote'::text)) -> Bitmap Index Scan on mail_messages_tsv_idx (cost=0.00..1249.30 rows=137207) Index Cond: (tsv @@ to_tsquery('wrote'::text)) (5 rows)
El costo se estima en 1285.13, que es un poco mayor que el costo de construir todo el mapa de bits 1249.30 (campo "costo" del nodo Escaneo de índice de mapa de bits).
Por lo tanto, el índice tiene una capacidad especial para limitar el número de resultados. El valor umbral se especifica en el parámetro de configuración "gin_fuzzy_search_limit" y es igual a cero de forma predeterminada (no tiene lugar ninguna limitación). Pero podemos establecer el valor umbral:
fts=# set gin_fuzzy_search_limit = 1000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 5746 (1 row)
fts=# set gin_fuzzy_search_limit = 10000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 14726 (1 row)
Como podemos ver, el número de filas devueltas por la consulta difiere para diferentes valores de parámetros (si se utiliza el acceso al índice). La limitación no es estricta: se pueden devolver más filas de las especificadas, lo que justifica la parte "difusa" del nombre del parámetro.
Representación compacta
Entre el resto, los índices GIN son buenos gracias a su compacidad. Primero, si se produce el mismo lexema en varios documentos (y este suele ser el caso), se almacena en el índice solo una vez. En segundo lugar, los TID se almacenan en el índice de forma ordenada, y esto nos permite usar una compresión simple: cada TID siguiente de la lista se almacena realmente como su diferencia del anterior; Esto suele ser un número pequeño, que requiere muchos menos bits que un TID completo de seis bytes.
Para tener una idea del tamaño, construyamos un árbol B a partir del texto de los mensajes. Pero una comparación justa ciertamente no va a suceder:
- GIN está construido en un tipo de datos diferente ("tsvector" en lugar de "texto"), que es más pequeño,
- Al mismo tiempo, el tamaño de los mensajes para el árbol B debe acortarse a aproximadamente dos kilobytes.
Sin embargo, continuamos:
fts=# create index mail_messages_btree on mail_messages(substring(body_plain for 2048));
Construiremos también el índice GiST:
fts=# create index mail_messages_gist on mail_messages using gist(tsv);
El tamaño de los índices al "vacío completo":
fts=# select pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')) as gin, pg_size_pretty(pg_relation_size('mail_messages_gist')) as gist, pg_size_pretty(pg_relation_size('mail_messages_btree')) as btree;
gin | gist | btree --------+--------+-------- 179 MB | 125 MB | 546 MB (1 row)
Debido a la compacidad de la representación, podemos intentar usar el índice GIN durante la migración desde Oracle como un reemplazo para los índices de mapa de bits (sin entrar en detalles, proporciono
una referencia a la publicación de Lewis para mentes curiosas). Como regla general, los índices de mapa de bits se usan para campos que tienen pocos valores únicos, lo cual es excelente también para GIN. Y, como se muestra
en el primer artículo , PostgreSQL puede construir un mapa de bits basado en cualquier índice, incluido GIN, sobre la marcha.
GiST o GIN?
Para muchos tipos de datos, las clases de operador están disponibles tanto para GiST como para GIN, lo que plantea una pregunta sobre qué índice utilizar. Quizás, ya podamos sacar algunas conclusiones.
Como regla, GIN supera a GiST en precisión y velocidad de búsqueda. Si los datos no se actualizan con frecuencia y se necesita una búsqueda rápida, lo más probable es que GIN sea una opción.
Por otro lado, si los datos se actualizan intensamente, los costos generales de actualizar GIN pueden parecer demasiado grandes. En este caso, tendremos que comparar ambas opciones y elegir la que tenga características más equilibradas.
Matrices
Otro ejemplo de uso de GIN es la indexación de matrices. En este caso, los elementos de la matriz entran en el índice, lo que permite acelerar una serie de operaciones sobre las matrices:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'array_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- &&(anyarray,anyarray) | 1 intersection @>(anyarray,anyarray) | 2 contains array <@(anyarray,anyarray) | 3 contained in array =(anyarray,anyarray) | 4 equality (4 rows)
Nuestra
base de datos de demostración tiene una vista de "rutas" con información sobre vuelos. Entre el resto, esta vista contiene la columna "days_of_week", una variedad de días de la semana en que se realizan los vuelos. Por ejemplo, un vuelo de Vnukovo a Gelendzhik sale los martes, jueves y domingos:
demo=# select departure_airport_name, arrival_airport_name, days_of_week from routes where flight_no = 'PG0049';
departure_airport_name | arrival_airport_name | days_of_week ------------------------+----------------------+-------------- Vnukovo | Gelendzhik | {2,4,7} (1 row)
Para construir el índice, "materialicemos" la vista en una tabla:
demo=# create table routes_t as select * from routes; demo=# create index on routes_t using gin(days_of_week);
Ahora podemos usar el índice para conocer todos los vuelos que salen los martes, jueves y domingos:
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7];
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (4 rows)
Parece que hay seis de ellos:
demo=# select flight_no, departure_airport_name, arrival_airport_name, days_of_week from routes_t where days_of_week = ARRAY[2,4,7];
flight_no | departure_airport_name | arrival_airport_name | days_of_week -----------+------------------------+----------------------+-------------- PG0005 | Domodedovo | Pskov | {2,4,7} PG0049 | Vnukovo | Gelendzhik | {2,4,7} PG0113 | Naryan-Mar | Domodedovo | {2,4,7} PG0249 | Domodedovo | Gelendzhik | {2,4,7} PG0449 | Stavropol | Vnukovo | {2,4,7} PG0540 | Barnaul | Vnukovo | {2,4,7} (6 rows)
¿Cómo se realiza esta consulta? Exactamente de la misma manera que la descrita anteriormente:
- Desde la matriz {2,4,7}, que desempeña el papel de la consulta de búsqueda aquí, se extraen elementos (palabras clave de búsqueda). Evidentemente, estos son los valores de "2", "4" y "7".
- En el árbol de elementos, se encuentran las claves extraídas, y para cada una de ellas se selecciona la lista de TID.
- De todos los TID encontrados, la función de coherencia selecciona aquellos que coinciden con el operador de la consulta. Para
= operador, solo los TID coinciden con los que ocurrieron en las tres listas (en otras palabras, la matriz inicial debe contener todos los elementos). Pero esto no es suficiente: también es necesario que la matriz no contenga ningún otro valor, y no podemos verificar esta condición con el índice. Por lo tanto, en este caso, el método de acceso le pide al motor de indexación que vuelva a verificar todos los TID devueltos con la tabla.
Curiosamente, hay estrategias (por ejemplo, "contenidas en una matriz") que no pueden verificar nada y tienen que volver a verificar todos los TID encontrados con la tabla.
Pero, ¿qué hacer si necesitamos saber los vuelos que salen de Moscú los martes, jueves y domingos? El índice no admitirá la condición adicional, que entrará en la columna "Filtro".
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) Filter: (departure_city = 'Moscow'::text) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (5 rows)
Aquí está bien (el índice selecciona solo seis filas de todos modos), pero en los casos en que la condición adicional aumenta la capacidad selectiva, se desea tener dicho soporte. Sin embargo, no podemos simplemente crear el índice:
demo=# create index on routes_t using gin(days_of_week,departure_city);
ERROR: data type text has no default operator class for access method "gin" HINT: You must specify an operator class for the index or define a default operator class for the data type.
Pero la extensión "
btree_gin " ayudará, lo que agrega clases de operador GIN que simulan el trabajo de un árbol B normal.
demo=# create extension btree_gin; demo=# create index on routes_t using gin(days_of_week,departure_city); demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) -> Bitmap Index Scan on routes_t_days_of_week_departure_city_idx Index Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) (4 rows)
Jsonb
Un ejemplo más de un tipo de datos compuesto que tiene soporte GIN incorporado es JSON. Para trabajar con valores JSON, actualmente se definen varios operadores y funciones, algunos de los cuales se pueden acelerar utilizando índices:
postgres=# select opc.opcname, amop.amopopr::regoperator, amop.amopstrategy as str from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname in ('jsonb_ops','jsonb_path_ops') and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
opcname | amopopr | str ----------------+------------------+----- jsonb_ops | ?(jsonb,text) | 9 top-level key exists jsonb_ops | ?|(jsonb,text[]) | 10 some top-level key exists jsonb_ops | ?&(jsonb,text[]) | 11 all top-level keys exist jsonb_ops | @>(jsonb,jsonb) | 7 JSON value is at top level jsonb_path_ops | @>(jsonb,jsonb) | 7 (5 rows)
Como podemos ver, hay dos clases de operadores disponibles: "jsonb_ops" y "jsonb_path_ops".
La primera clase de operador "jsonb_ops" se usa por defecto. Todas las claves, valores y elementos de matriz llegan al índice como elementos del documento JSON inicial. Se agrega un atributo a cada uno de estos elementos, que indica si este elemento es una clave (esto es necesario para estrategias "existentes", que distinguen entre claves y valores).
Por ejemplo, representemos algunas filas de "rutas" como JSON de la siguiente manera:
demo=# create table routes_jsonb as select to_jsonb(t) route from ( select departure_airport_name, arrival_airport_name, days_of_week from routes order by flight_no limit 4 ) t; demo=# select ctid, jsonb_pretty(route) from routes_jsonb;
ctid | jsonb_pretty -------+------------------------------------------------- (0,1) | { + | "days_of_week": [ + | 1 + | ], + | "arrival_airport_name": "Surgut", + | "departure_airport_name": "Ust-Ilimsk" + | } (0,2) | { + | "days_of_week": [ + | 2 + | ], + | "arrival_airport_name": "Ust-Ilimsk", + | "departure_airport_name": "Surgut" + | } (0,3) | { + | "days_of_week": [ + | 1, + | 4 + | ], + | "arrival_airport_name": "Sochi", + | "departure_airport_name": "Ivanovo-Yuzhnyi"+ | } (0,4) | { + | "days_of_week": [ + | 2, + | 5 + | ], + | "arrival_airport_name": "Ivanovo-Yuzhnyi", + | "departure_airport_name": "Sochi" + | } (4 rows)
demo=# create index on routes_jsonb using gin(route);
El índice puede verse de la siguiente manera:
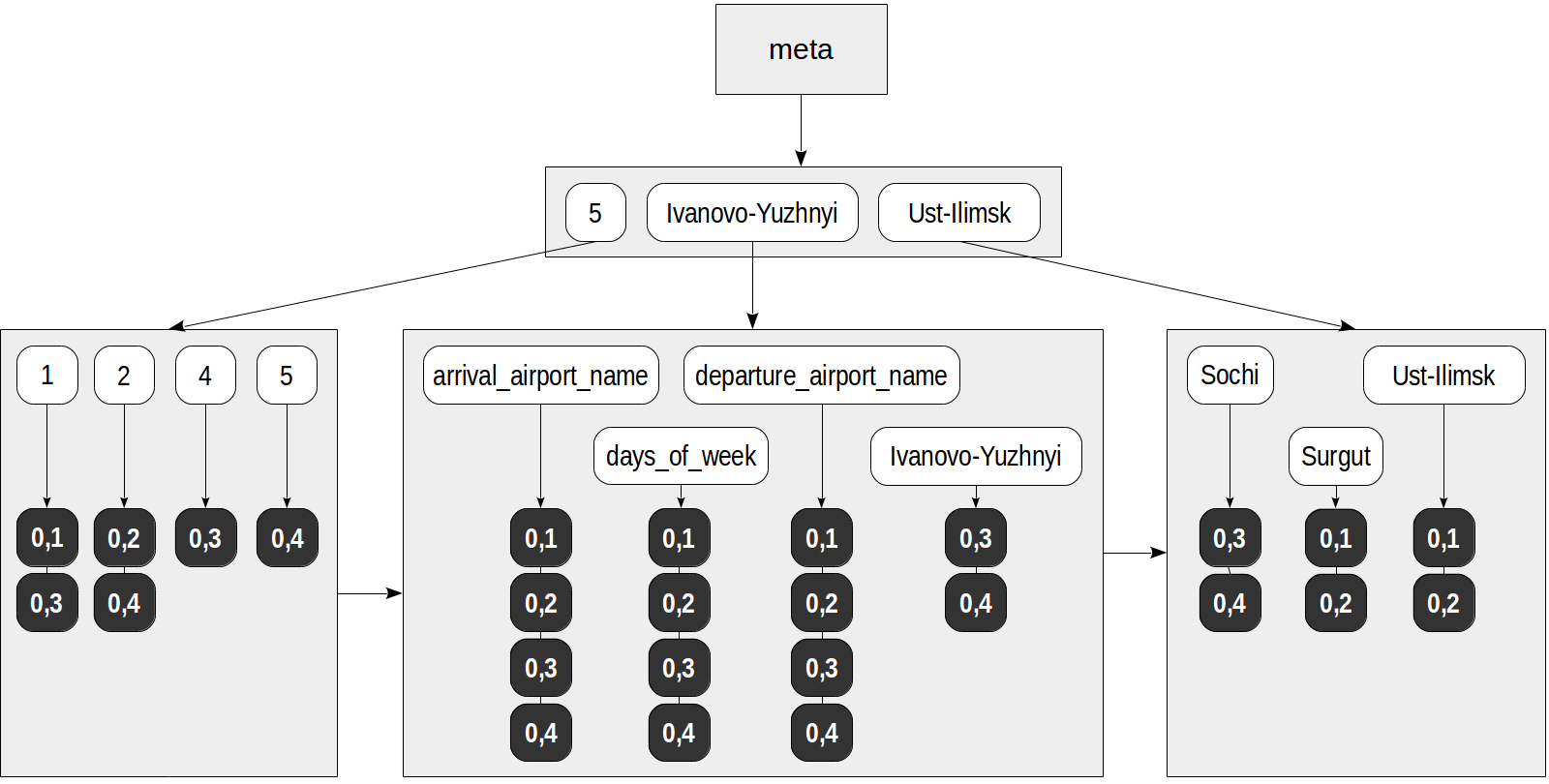
Ahora, una consulta como esta, por ejemplo, se puede realizar utilizando el índice:
demo=# explain (costs off) select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
QUERY PLAN --------------------------------------------------------------- Bitmap Heap Scan on routes_jsonb Recheck Cond: (route @> '{"days_of_week": [5]}'::jsonb) -> Bitmap Index Scan on routes_jsonb_route_idx Index Cond: (route @> '{"days_of_week": [5]}'::jsonb) (4 rows)
Comenzando con la raíz del documento JSON, el operador
@> verifica si se produce la ruta especificada (
"days_of_week": [5] ). Aquí la consulta devolverá una fila:
demo=# select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
jsonb_pretty ------------------------------------------------ { + "days_of_week": [ + 2, + 5 + ], + "arrival_airport_name": "Ivanovo-Yuzhnyi",+ "departure_airport_name": "Sochi" + } (1 row)
La consulta se realiza de la siguiente manera:
- En la consulta de búsqueda (
"days_of_week": [5] ) se extraen elementos (claves de búsqueda): "days_of_week" y "5".
- En el árbol de elementos se encuentran las claves extraídas, y para cada una de ellas se selecciona la lista de TID: para "5" - (0.4), y para "days_of_week" - (0,1), (0,2 ), (0.3), (0.4).
- De todos los TID encontrados, la función de coherencia selecciona aquellos que coinciden con el operador de la consulta. Para el operador
@> , los documentos que no contienen todos los elementos de la consulta de búsqueda no serán seguros, por lo que solo queda (0,4). Pero aún necesitamos volver a verificar el TID que queda con la tabla, ya que no está claro en el índice en qué orden se producen los elementos encontrados en el documento JSON.
Para descubrir más detalles de otros operadores, puede leer
la documentación .
Además de las operaciones convencionales para tratar con JSON, la extensión "jsquery" ha estado disponible durante mucho tiempo, que define un lenguaje de consulta con capacidades más ricas (y ciertamente, con soporte de índices GIN). Además, en 2016, se emitió un nuevo estándar SQL, que define su propio conjunto de operaciones y lenguaje de consulta "Ruta SQL / JSON". Ya se ha logrado una implementación de este estándar, y creemos que aparecerá en PostgreSQL 11.
El parche de ruta SQL / JSON finalmente se confirmó en PostgreSQL 12, mientras que otras piezas aún están en camino. Con suerte, veremos la característica completamente implementada en PostgreSQL 13.
Internos
Podemos mirar dentro del índice GIN usando la extensión "
pageinspect ".
fts=# create extension pageinspect;
La información de la página meta muestra estadísticas generales:
fts=# select * from gin_metapage_info(get_raw_page('mail_messages_tsv_idx',0));
-[ RECORD 1 ]----+----------- pending_head | 4294967295 pending_tail | 4294967295 tail_free_size | 0 n_pending_pages | 0 n_pending_tuples | 0 n_total_pages | 22968 n_entry_pages | 13751 n_data_pages | 9216 n_entries | 1423598 version | 2
La estructura de la página proporciona un área especial donde los métodos de acceso almacenan su información; esta área es "opaca" para programas ordinarios como el vacío. La función "Gin_page_opaque_info" muestra estos datos para GIN. Por ejemplo, podemos conocer el conjunto de páginas de índice:
fts=# select flags, count(*) from generate_series(1,22967) as g(id),
flags | count ------------------------+------- {meta} | 1 meta page {} | 133 internal page of element B-tree {leaf} | 13618 leaf page of element B-tree {data} | 1497 internal page of TID B-tree {data,leaf,compressed} | 7719 leaf page of TID B-tree (5 rows)
La función "Gin_leafpage_items" proporciona información sobre los TID almacenados en las páginas {datos, hoja, comprimido}:
fts=# select * from gin_leafpage_items(get_raw_page('mail_messages_tsv_idx',2672));
-[ RECORD 1 ]--------------------------------------------------------------------- first_tid | (239,44) nbytes | 248 tids | {"(239,44)","(239,47)","(239,48)","(239,50)","(239,52)","(240,3)",... -[ RECORD 2 ]--------------------------------------------------------------------- first_tid | (247,40) nbytes | 248 tids | {"(247,40)","(247,41)","(247,44)","(247,45)","(247,46)","(248,2)",... ...
Tenga en cuenta que las páginas del árbol de TID en realidad contienen pequeñas listas comprimidas de punteros a filas de tabla en lugar de punteros individuales.
Propiedades
Veamos las propiedades del método de acceso GIN (
ya se han proporcionado consultas ).
amname | name | pg_indexam_has_property --------+---------------+------------------------- gin | can_order | f gin | can_unique | f gin | can_multi_col | t gin | can_exclude | f
Curiosamente, GIN admite la creación de índices de varias columnas. Sin embargo, a diferencia de un árbol B normal, en lugar de claves compuestas, un índice de varias columnas seguirá almacenando elementos individuales, y el número de columna se indicará para cada elemento.
Las siguientes propiedades de capa de índice están disponibles:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
Tenga en cuenta que no se admite la devolución de resultados TID por TID (exploración de índice); solo es posible el escaneo de mapa de bits.
La exploración hacia atrás tampoco es compatible: esta función es esencial solo para la exploración de índice, pero no para la exploración de mapa de bits.
Y las siguientes son propiedades de capa de columna:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
Aquí no hay nada disponible: sin clasificación (lo que está claro), sin uso del índice como cobertura (ya que el documento en sí no está almacenado en el índice), sin manipulación de NULL (ya que no tiene sentido para elementos de tipo compuesto) .
Otros tipos de datos
Hay algunas extensiones más disponibles que agregan soporte de GIN para algunos tipos de datos.
- " pg_trgm " nos permite determinar la "similitud" de las palabras al comparar cuántas secuencias iguales de tres letras (trigramas) están disponibles. Se añaden dos clases de operadores, "gist_trgm_ops" y "gin_trgm_ops", que admiten varios operadores, incluida la comparación mediante expresiones LIKE y regulares. Podemos usar esta extensión junto con la búsqueda de texto completo para sugerir opciones de palabras para corregir errores tipográficos.
- " hstore " implementa el almacenamiento "clave-valor". Para este tipo de datos, hay disponibles clases de operador para varios métodos de acceso, incluido GIN. Sin embargo, con la introducción del tipo de datos "jsonb", no hay razones especiales para usar "hstore".
- " intarray " amplía la funcionalidad de las matrices de enteros. El soporte de índice incluye GiST, así como GIN (clase de operador "gin__int_ops").
Y estas dos extensiones ya se han mencionado anteriormente:
- " btree_gin " agrega soporte GIN para los tipos de datos regulares para que puedan usarse en un índice de varias columnas junto con los tipos compuestos.
- " jsquery " define un idioma para las consultas JSON y una clase de operador para el soporte de índice de este idioma. Esta extensión no está incluida en una entrega estándar de PostgreSQL.
Sigue leyendo .