¿Cómo trabajar efectivamente con json en R?
Es una continuación de publicaciones anteriores .
Planteamiento del problema
Como regla general, la fuente principal de datos en formato json es la API REST. El uso de json, además de la independencia de la plataforma y la conveniencia de la percepción humana de los datos, permite el intercambio de sistemas de datos no estructurados con una estructura de árbol compleja.
En las tareas de construir una API, esto es muy conveniente. Es fácil garantizar el control de versiones de los protocolos de comunicación, es fácil proporcionar la flexibilidad del intercambio de información. Al mismo tiempo, la complejidad de la estructura de datos (los niveles de anidación pueden ser 5, 6, 10 o incluso más) no da miedo, ya que escribir un analizador flexible para un solo registro que tenga en cuenta todo y todo no es tan difícil.
Las tareas de procesamiento de datos también incluyen la obtención de datos de fuentes externas, que incluyen en formato json. R tiene un buen conjunto de paquetes, en particular jsonlite , diseñado para convertir json en objetos R ( list o, data.frame , si la estructura de datos lo permite).
Sin embargo, en la práctica, a menudo surgen dos clases de problemas cuando se usa jsonlite y similares se vuelven extremadamente ineficientes. Las tareas se parecen a esto:
- procesar una gran cantidad de datos (unidad de medida - gigabytes) obtenidos durante la operación de varios sistemas de información;
- combinando una gran cantidad de respuestas estructuradas variables recibidas durante un paquete de solicitudes API REST parametrizadas en una representación rectangular uniforme (
data.frame ).
Un ejemplo de una estructura similar en las ilustraciones:
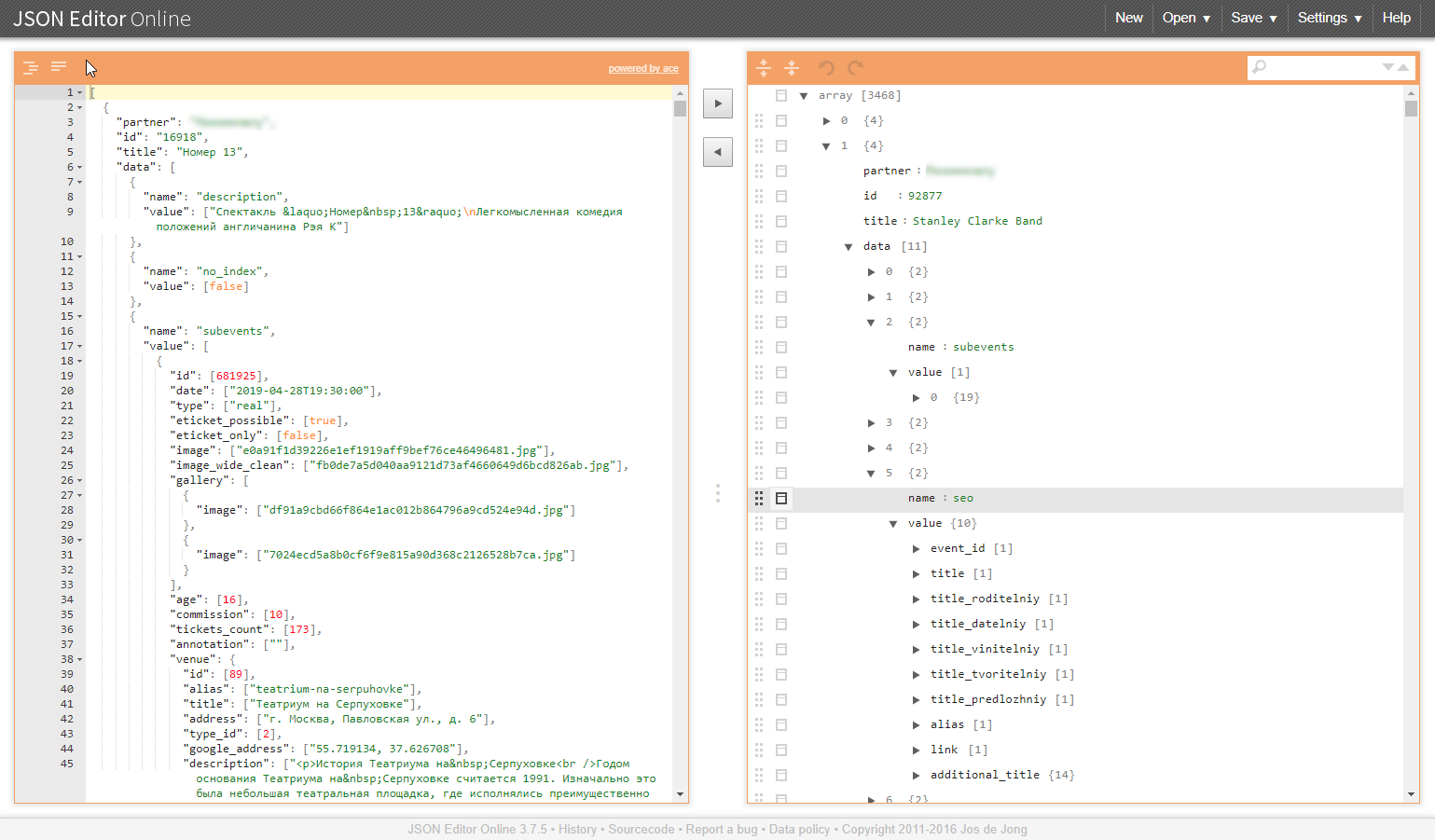
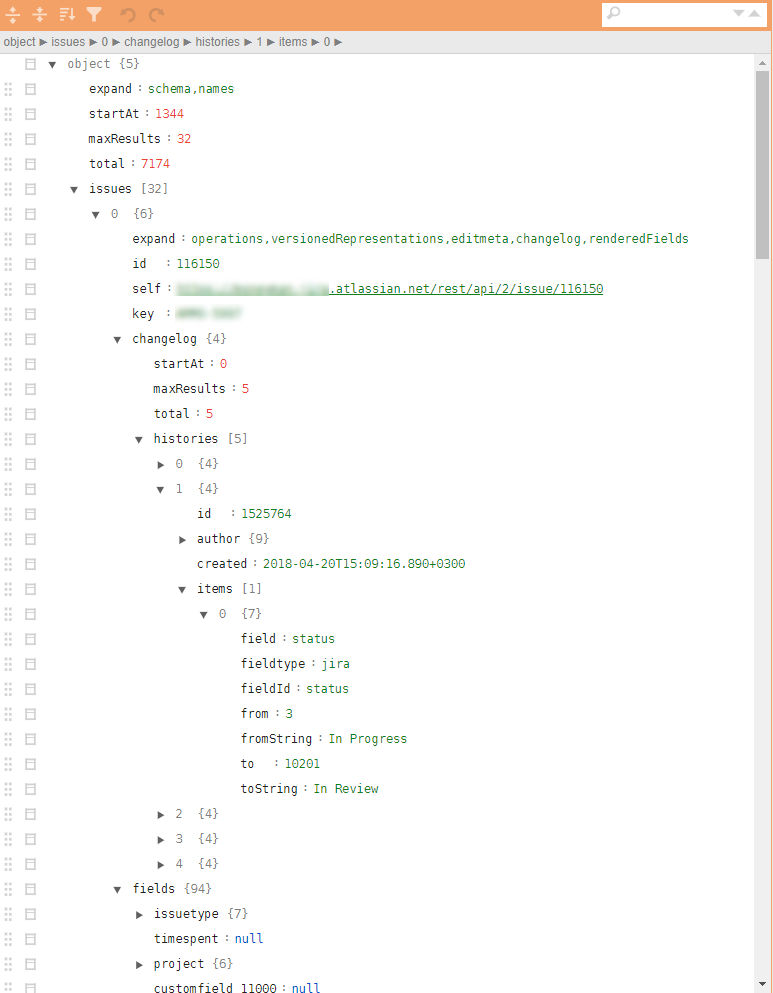
¿Por qué son problemáticas estas clases de tareas?
Gran cantidad de datos
Como regla, la descarga de sistemas de información en formato json es un bloque de datos indivisible. Para analizarlo correctamente, debe leerlo todo y revisar todo su volumen.
Problemas inducidos:
- se necesita una cantidad correspondiente de RAM y recursos informáticos;
- la velocidad de análisis depende en gran medida de la calidad de las bibliotecas utilizadas, e incluso si hay suficientes recursos, el tiempo de conversión puede ser decenas o incluso cientos de minutos;
- en el caso de una falla de análisis, no se obtiene ningún resultado en la salida, y no hay razón para esperar que todo salga bien, no hay razón, sino todo lo contrario;
- Tendrá mucho éxito si los datos analizados se pueden convertir a
data.frame .
Fusionar estructuras de árboles
Surgen tareas similares, por ejemplo, cuando es necesario recopilar los directorios requeridos por el proceso de negocio para el trabajo de un paquete de solicitudes a través de la API. Además, los directorios implican unificación y preparación para integrarse en la canalización analítica y posible carga en la base de datos. Y esto nuevamente hace que sea necesario convertir dichos datos de resumen en data.frame .
Problemas inducidos:
- las estructuras de los árboles no se convertirán en planas. los analizadores json convierten los datos de entrada en un conjunto de listas anidadas, que luego deben implementarse manualmente durante mucho tiempo y de forma dolorosa;
- la libertad en los atributos de los datos de salida (es posible que no se muestren los ausentes) conduce a la aparición de objetos
NULL que son relevantes en las listas, pero que no pueden "encajar" en el data.frame , lo que complica el posprocesamiento y complica incluso el proceso básico de fusionar hojas de filas individuales en data.frame (no importa rbindlist , bind_rows , 'map_dfr' o rbind ).
JQ - salida
En situaciones particularmente difíciles, el uso de enfoques muy convenientes del paquete jsonlite "convertir todo en objetos R" por las razones anteriores da un mal funcionamiento grave. Bueno, si logras llegar al final del procesamiento. Peor aún, si en el medio tienes que extender los brazos y rendirte.
Una alternativa a este enfoque es utilizar el preprocesador json, que opera directamente en los datos json. Biblioteca jq y contenedor jqr . La práctica muestra que no solo se usa poco, sino que pocos lo han escuchado y en vano.
Beneficios de la biblioteca jq .
- la biblioteca se puede usar en R, en Python y en la línea de comando;
- todas las transformaciones se realizan a nivel json, sin transformación en representaciones de objetos R / Python;
- el procesamiento se puede dividir en operaciones atómicas y usar el principio de cadenas (tubería);
- los ciclos para procesar vectores de objetos están ocultos dentro del analizador, la sintaxis de iteración se simplifica al máximo;
- la capacidad de llevar a cabo todos los procedimientos para la unificación de la estructura json, el despliegue y la selección de los elementos necesarios para crear un formato json que se convierta por lotes a
data.frame usando jsonlite ; - reducción múltiple del código R responsable del procesamiento de datos json;
- gran velocidad de procesamiento, dependiendo del volumen y la complejidad de la estructura de datos, la ganancia puede ser de 1-3 órdenes de magnitud;
- Mucho menos requisitos de RAM.
El código de procesamiento está comprimido para adaptarse a la pantalla y puede verse así:
cont <- httr::content(r3, as = "text", encoding = "UTF-8") m <- cont %>% # jqr::jq('del(.[].movie.rating, .[].movie.genres, .[].movie.trailers)') %>% jqr::jq('del(.[].movie.countries, .[].movie.images)') %>% # jqr::jq('del(.[].schedules[].hall, .[].schedules[].language, .[].schedules[].subtitle)') %>% # jqr::jq('del(.[].cinema.location, .[].cinema.photo, .[].cinema.phones)') %>% jqr::jq('del(.[].cinema.goodies, .[].cinema.subway_stations)') # m2 <- m %>% jqr::jq('[.[] | {date, movie, schedule: .schedules[], cinema}]') df <- fromJSON(m2) %>% as_tibble()
¡jq es muy elegante y rápido! Para aquellos para quienes es relevante: descargar, configurar, comprender. Aceleramos el procesamiento, simplificamos la vida para nosotros y nuestros colegas.
Publicación anterior: “Cómo comenzar a aplicar R en Enterprise. Un ejemplo de enfoque práctico " .