Introducción a los sistemas operativos
Hola Habr! Quiero llamar su atención sobre una serie de artículos-traducciones de una literatura interesante en mi opinión: OSTEP. Este artículo analiza en profundidad el trabajo de los sistemas operativos tipo Unix, a saber, el trabajo con procesos, varios programadores, memoria y otros componentes similares que componen el sistema operativo moderno. El original de todos los materiales que puedes ver
aquí . Tenga en cuenta que la traducción se realizó de manera no profesional (con bastante libertad), pero espero haber conservado el significado general.
El trabajo de laboratorio sobre este tema se puede encontrar aquí:
Otras partes:
Y puedes mirar mi canal en
telegram =)
Introducción al programador
La esencia del problema: cómo desarrollar una política de planificación
¿Cómo deben desarrollarse los marcos de políticas básicas del planificador? ¿Cuáles deberían ser los supuestos clave? ¿Qué métricas son importantes? ¿Qué técnicas básicas se utilizaron en la informática temprana?Supuestos de carga de trabajo
Antes de discutir posibles políticas, para comenzar haremos algunas digresión simplificadoras sobre los procesos que se ejecutan en el sistema, que colectivamente se denominan
carga de trabajo . Al definir una carga de trabajo como una parte crítica de las políticas de construcción y cuanto más sepa sobre la carga de trabajo, mejor política podrá escribir.
Hacemos los siguientes supuestos sobre los procesos que se ejecutan en el sistema, a veces también llamados
trabajos (tareas). Casi todas estas suposiciones no son realistas, sino necesarias para el desarrollo del pensamiento.
- Cada tarea ejecuta la misma cantidad de tiempo,
- Todas las tareas se establecen al mismo tiempo,
- La tarea en cuestión hasta su finalización,
- Todas las tareas usan solo la CPU,
- Se conoce el tiempo de ejecución de cada tarea.
Métricas del programador
Además de algunos supuestos sobre la carga, necesita alguna herramienta más para comparar diferentes políticas de planificación: las métricas del planificador. Una métrica es solo una medida de algo. Hay una serie de métricas que se pueden usar para comparar planificadores.
Por ejemplo, utilizaremos una métrica llamada tiempo de respuesta. El tiempo de respuesta de una tarea se define como la diferencia entre el tiempo que lleva completar la tarea y el tiempo que la tarea ingresa al sistema.
Tturnaround = Tcompletion - TarrivalComo asumimos que todas las tareas llegaron al mismo tiempo, entonces Ta = 0 y, por lo tanto, Tt = Tc. Este valor cambiará naturalmente cuando cambiemos los supuestos anteriores.
Otra métrica es la
justicia (equidad, honestidad). La productividad y la honestidad a menudo son características opuestas en la planificación. Por ejemplo, un planificador puede optimizar el rendimiento, pero a costa de esperar a que se ejecuten otras tareas, reduciendo así la integridad.
PRIMERO EN PRIMERA SALIDA (FIFO)
El algoritmo más básico que podemos implementar se llama FIFO o
first come (in), first serve (out) . Este algoritmo tiene varias ventajas: es muy simple de implementar y se ajusta a todos nuestros supuestos, haciendo el trabajo bastante bien.
Considere un ejemplo simple. Supongamos que se establecieron 3 tareas al mismo tiempo. Pero suponga que la tarea A llegó un poco antes que todos los demás, por lo que estará en la lista de ejecución antes que las demás, al igual que B en relación con C. Suponga que cada una de ellas tarda 10 segundos en completarse. ¿Cuál será el tiempo promedio para completar estas tareas?
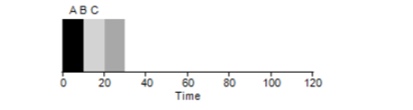
Contando los valores: 10 + 20 + 30 y dividiendo entre 3, obtenemos el tiempo de ejecución promedio del programa igual a 20 segundos.
Ahora intentemos cambiar nuestras suposiciones. En particular, el supuesto 1 y, por lo tanto, ya no asumiremos que cada tarea lleva la misma cantidad de tiempo. ¿Cómo se mostrará FIFO esta vez?
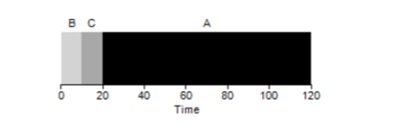
Como resultado, los diferentes tiempos de ejecución de las tareas tienen un impacto extremadamente negativo en la productividad del algoritmo FIFO. Suponga que la tarea A se ejecutará durante 100 segundos, mientras que B y C seguirán siendo 10 cada uno.

Como se puede ver en la figura, el tiempo promedio para el sistema es (100 + 110 + 120) / 3 = 110. Este efecto se llama
efecto convoy , cuando algunos consumidores a corto plazo de un recurso estarán en línea después de un consumidor pesado. Parece una línea de supermercado cuando un cliente con un carrito lleno está frente a usted. La mejor solución al problema es intentar cambiar el cajero o relajarse y respirar profundamente.
El trabajo más corto primero
¿Es posible de alguna manera resolver una situación similar con procesos pesados? Por supuesto Otro tipo de programación se llama
Shortest Job First (SJF). Su algoritmo también es bastante primitivo: como su nombre lo indica, las tareas más cortas se lanzarán primero una tras otra.
En este ejemplo, el resultado de iniciar los mismos procesos será una mejora en el tiempo de respuesta promedio de los programas y será
50 en lugar de 110 , que es casi 2 veces mejor.
Por lo tanto, dado el supuesto de que todas las tareas llegan al mismo tiempo, el algoritmo SJF parece ser el algoritmo más óptimo. Sin embargo, nuestras suposiciones aún no parecen realistas. Esta vez, cambiamos el supuesto 2 y esta vez imaginamos que las tareas pueden permanecer en cualquier momento, y no todas al mismo tiempo. ¿A qué problemas puede conducir esto?

Imagine que la tarea A (100s) llega primero y comienza a ejecutarse. En el tiempo t = 10, llegan las tareas B, C, cada una de las cuales tomará 10 segundos. Por lo tanto, el tiempo de ejecución promedio es (100+ (110-10) + (120-10)) \ 3 = 103. ¿Qué podría hacer el planificador para mejorar la situación?
El tiempo de finalización más corto primero (STCF)
Para mejorar la situación, omitimos el supuesto 3 de que el programa está en funcionamiento hasta su finalización. Además, necesitaremos soporte de hardware y, como habrás adivinado, utilizaremos un
temporizador para interrumpir una tarea de trabajo y
cambiar de contexto . Por lo tanto, el planificador puede hacer algo en el momento en que llegan las tareas B y C: detener la ejecución de la tarea A y poner las tareas B y C en proceso y, después de que terminen, continuar el proceso A. Este planificador se llama
STCF o
trabajo preventivo primero .
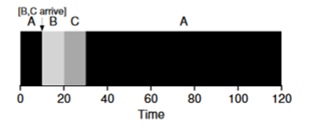
El resultado de este planificador será este resultado: ((120-0) + (20-10) + (30-10)) / 3 = 50. Por lo tanto, dicho planificador se vuelve aún más óptimo para nuestras tareas.
Tiempo de respuesta métrica
Por lo tanto, si conocemos el tiempo de ejecución de las tareas y si estas tareas usan solo la CPU, STCF será la mejor solución. Y una vez en los primeros días, estos algoritmos funcionaron y bastante bien. Sin embargo, ahora el usuario pasa la mayor parte del tiempo en el terminal y espera una interacción interactiva productiva del mismo. Así nació una nueva métrica:
tiempo de respuesta (respuesta).
El tiempo de respuesta se calcula de la siguiente manera:
Tresponse = Tfirstrun - TarrivalPor lo tanto, para el ejemplo anterior, el tiempo de respuesta será el siguiente: A = 0, B = 0, B = 10 (abg = 3.33).
Y resulta que el algoritmo STCF no es tan bueno en una situación en la que llegan 3 tareas al mismo tiempo; tendrá que esperar hasta que las tareas pequeñas se completen por completo. Por lo tanto, el algoritmo es bueno para la métrica de tiempo de respuesta, pero malo para la métrica de interactividad. Imagínese sentado en la terminal en un intento de escribir caracteres en el editor, tendría que esperar más de 10 segundos, porque el procesador ocupa otra tarea. Esto no es muy agradable.
Entonces nos enfrentamos a otro problema: ¿cómo podemos construir un programador que sea sensible al tiempo de respuesta?
Round robin
Para resolver este problema, se desarrolló el algoritmo
Round Robin (RR). La idea básica es bastante simple: en lugar de comenzar las tareas para completar la finalización, comenzaremos la tarea durante un cierto período de tiempo (llamado tiempo cuántico) y luego cambiaremos a otra tarea desde la cola. El algoritmo repite su trabajo hasta que se completen todas las tareas. En este caso, el tiempo de ejecución del programa debe ser un múltiplo del tiempo después del cual el temporizador interrumpe el proceso. Por ejemplo, si el temporizador interrumpe el proceso cada x = 10 ms, entonces el tamaño de la ventana de ejecución del proceso debe ser un múltiplo de 10 y ser 10.20 o x * 10.
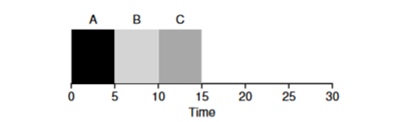
Veamos un ejemplo: las tareas de ABV llegan simultáneamente al sistema y cada una de ellas quiere trabajar durante 5 segundos. El algoritmo SJF completará cada tarea hasta el final antes de comenzar otra. Por el contrario, el algoritmo RR con la ventana de inicio = 1s realizará las tareas de la siguiente manera (Fig. 4.3):
(SJF nuevamente (malo para el tiempo de respuesta)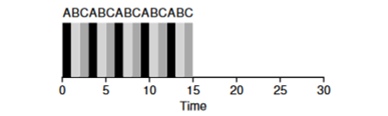 (Round Robin (Bueno para el tiempo de respuesta)
(Round Robin (Bueno para el tiempo de respuesta)El tiempo de respuesta promedio para el algoritmo es RR (0 + 1 + 2) / 3 = 1, mientras que para SJF (0 + 5 + 10) / 3 = 5.
Es lógico suponer que la ventana de tiempo es un parámetro muy importante para RR, cuanto más pequeño es, mayor es el tiempo de respuesta. Sin embargo, no puede hacerlo demasiado pequeño, porque el tiempo para cambiar el contexto también jugará un papel en el rendimiento general. Por lo tanto, el arquitecto del sistema operativo establece el tiempo de la ventana de ejecución y depende de las tareas que se planean ejecutar en él. Cambiar el contexto no es la única operación de servicio que gasta tiempo: el programa en ejecución funciona con mucho más, por ejemplo, varios cachés, y cada vez que es necesario guardar y restaurar este entorno, lo que también puede llevar mucho tiempo.
RR es un gran planificador si solo fuera una métrica de tiempo de respuesta. Pero, ¿cómo se comportará la métrica del tiempo de respuesta de la tarea con este algoritmo? Considere el ejemplo anterior, cuando el tiempo de operación A, B, C = 5s y llegue al mismo tiempo. La tarea A finalizará a las 13, B a las 14, C a las 15s y el tiempo de respuesta promedio será de 14s. Por lo tanto, RR es el peor algoritmo para las métricas de rotación.
En términos más generales, cualquier algoritmo como RR es honesto, divide el tiempo dedicado a la CPU por igual entre todos los procesos. Y así, estas métricas constantemente entran en conflicto entre sí.
Por lo tanto, tenemos varios algoritmos opuestos y, al mismo tiempo, quedan varias suposiciones: que se conoce el tiempo de la tarea y que la tarea solo usa la CPU.
Mezclar con E / S
En primer lugar, eliminamos la suposición 4 de que el proceso solo usa la CPU, por supuesto, esto no es así, y los procesos pueden recurrir a otro equipo.
En el momento en que un proceso solicita una operación de E / S, el proceso pasa a un estado bloqueado, esperando que se complete la E / S. Si se envía E / S al disco duro, dicha operación puede demorar varios ms o más, y el procesador estará inactivo en ese momento. En este momento, el planificador puede hacerse cargo del procesador por cualquier otro proceso. La siguiente decisión que tendrá que tomar el planificador es cuando el proceso complete su E / S. Cuando esto sucede, se producirá una interrupción y el sistema operativo pondrá el proceso de llamada de E / S en el estado listo.
Considere un ejemplo de varias tareas. Cada uno de ellos necesita 50 ms de tiempo de procesador. Sin embargo, el primero accederá a E / S cada 10 ms (que también se ejecutará durante 10 ms). Y el proceso B simplemente usa un procesador de 50 ms sin E / S.
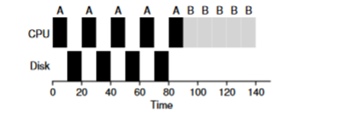
En este ejemplo, usaremos el planificador STCF. ¿Cómo se comporta el planificador si ejecuta un proceso como A en él? Él procederá de la siguiente manera: primero procesará completamente A y luego procesará B.

El enfoque tradicional para resolver este problema es interpretar cada subtarea de 10 ms del proceso A como una tarea separada. Por lo tanto, al comenzar con el algoritmo STJF, la elección entre una tarea de 50 ms y una tarea de 10 ms es obvia. Luego, cuando se complete la subtarea A, se iniciarán el proceso B y la E / S. Una vez completada la E / S, será habitual iniciar nuevamente el proceso A de 10 ms en lugar del proceso B. Por lo tanto, es posible realizar una superposición cuando la CPU es utilizada por otro proceso mientras el primero está esperando E / S. Y como resultado, el sistema se utiliza mejor: en el momento en que los procesos interactivos están esperando E / S, se pueden ejecutar otros procesos en el procesador.
Oracle ya no existe
Ahora tratemos de deshacernos de la suposición de que se conoce el momento de la tarea. Esta es generalmente la suposición peor y más poco realista de toda la lista. De hecho, en los sistemas operativos estándar promedio, el sistema operativo en sí mismo generalmente sabe muy poco sobre el tiempo que lleva completar las tareas, entonces, ¿cómo puede construir un programador sin saber cuánto tiempo llevará la tarea? ¿Quizás podríamos usar algunos de los principios de RR para resolver este problema?
Resumen
Examinamos las ideas básicas de planificación de tareas y revisamos 2 familias de planificadores. El primero comienza la tarea más corta al principio y, por lo tanto, aumenta el tiempo de respuesta, el segundo se divide entre todas las tareas por igual, aumentando el tiempo de respuesta. Ambos algoritmos son malos donde otros algoritmos familiares son buenos. También observamos cómo el uso paralelo de la CPU y la E / S puede mejorar el rendimiento, pero no resolvió el problema con la clarividencia del sistema operativo. Y en la próxima lección, consideraremos un planificador que mira el pasado cercano y trata de predecir el futuro. Y se llama cola de comentarios de varios niveles.