Si utiliza la base de datos de series temporales (series de tiempo db,
wiki ) como el repositorio principal de un sitio con estadísticas, en lugar de resolver el problema, puede tener mucho dolor de cabeza. Estoy trabajando en un proyecto en el que se utiliza dicha base y, a veces, InfluxDB, que se discutirá, trajo sorpresas inesperadas por completo.
Descargo de responsabilidad : estos problemas son para InfluxDB 1.7.4.
¿Por qué series de tiempo?
El proyecto consiste en rastrear transacciones en varias cadenas de bloques y mostrar estadísticas. Específicamente, observamos la emisión y la quema de monedas estables (
wiki ). En función de estas transacciones, debe crear gráficos y mostrar tablas dinámicas.
Al analizar las transacciones, surgió la idea: utilizar la base de datos de series de tiempo InfluxDB como almacenamiento principal. Las transacciones son puntos en el tiempo y se ajustan bien al modelo de series de tiempo.
Además, las funciones de agregación parecían muy convenientes: son ideales para procesar gráficos con un período prolongado. El usuario necesita un gráfico para el año, y la base de datos contiene un conjunto de datos con un marco de tiempo de cinco minutos. No tiene sentido enviarle cien mil puntos, a excepción de un procesamiento prolongado, no caben en la pantalla. Puede escribir su propia implementación para aumentar el plazo o utilizar las funciones de agregación integradas en Influx. Con su ayuda, puede agrupar datos por día y enviar los 365 puntos deseados.
Fue un poco vergonzoso que, por lo general, esas bases de datos se utilizan para recopilar métricas. Servidores de monitoreo, dispositivos iot, todos desde los cuales millones de puntos de la forma "vierten": [<hora> - <valor métrico>]. Pero si la base de datos funciona bien con un gran flujo de datos, ¿por qué una pequeña cantidad puede causar problemas? Con esto en mente, tomaron InfluxDB para trabajar.
¿Qué más es conveniente en InfluxDB?
Además de las funciones de agregación mencionadas, hay otra gran cosa:
consultas continuas (
doc ). Este es un programador integrado en la base de datos que puede procesar datos en un horario. Por ejemplo, puede agrupar todos los registros de un día cada 24 horas, calcular el promedio y escribir un nuevo punto en otra tabla sin escribir sus propias bicicletas.
También hay
políticas de retención (
doc ), que configuran la eliminación de datos después de un período. Es útil cuando, por ejemplo, necesita almacenar la carga en la CPU durante una semana con mediciones una vez por segundo, pero a una distancia de un par de meses esta precisión no es necesaria. En esta situación, puede hacer esto:
- crear una consulta continua para agregar datos en otra tabla;
- Para la primera tabla, defina una política para eliminar métricas que sean anteriores a esa semana.
Y Influx reducirá de forma independiente el tamaño de los datos y eliminará innecesariamente.
Acerca de los datos almacenados
No se almacenan muchos datos: alrededor de 70 mil transacciones y otro millón de puntos con información de mercado. Agregar nuevas entradas: no más de 3000 puntos por día. También hay métricas en el sitio, pero hay pocos datos y sobre la política de retención se almacenan durante no más de un mes.
Los problemas
Durante el desarrollo y las pruebas posteriores del servicio, surgieron más y más problemas críticos durante la operación de InfluxDB.
1. Eliminación de datos.
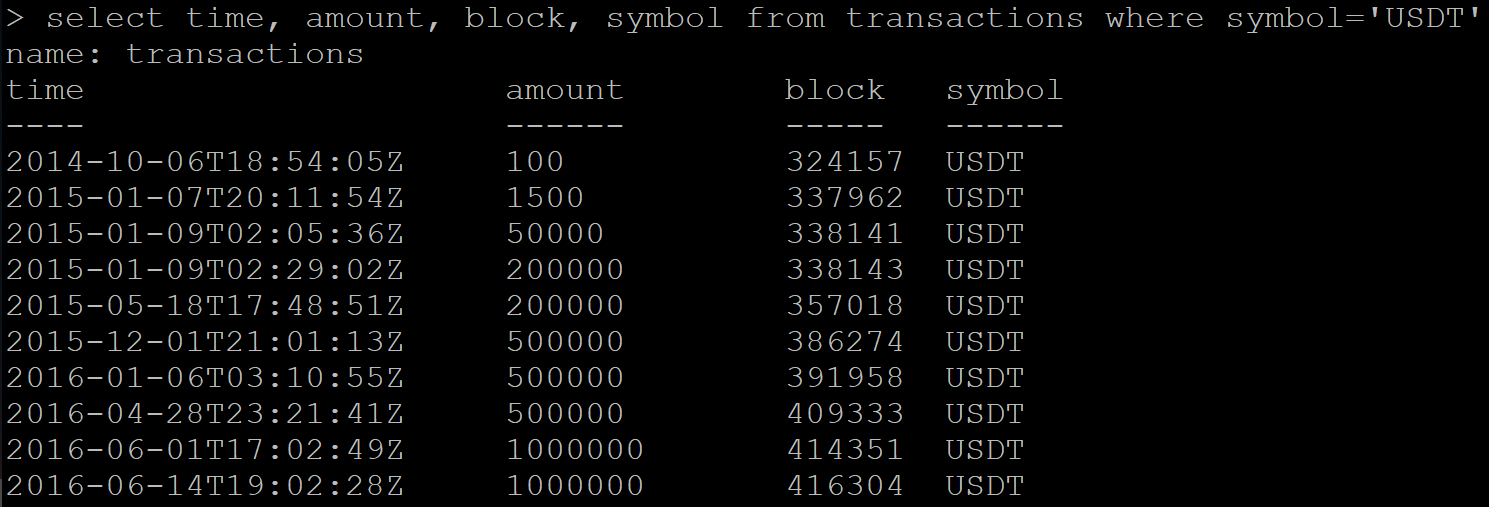
Hay una serie de datos con transacciones:
SELECT time, amount, block, symbol FROM transactions WHERE symbol='USDT'
Resultado:
Envío un comando para eliminar datos:
DELETE FROM transactions WHERE symbol='USDT'
A continuación, solicito recibir datos ya eliminados. Y Influx, en lugar de una respuesta vacía, devuelve parte de los datos que deberían eliminarse.
Intento eliminar toda la tabla:
DROP MEASUREMENT transactions
Compruebo la eliminación de la tabla:
SHOW MEASUREMENTS
No veo la tabla en la lista, pero una nueva solicitud de datos aún devuelve el mismo conjunto de transacciones.
El problema se me ocurrió solo una vez, ya que el caso de eliminación es un caso aislado. Pero este comportamiento de la base de datos claramente no encaja en el marco del trabajo "correcto". Más tarde, en github, encontré un
boleto abierto hace casi un año sobre este tema.
Como resultado, la eliminación y posterior restauración de toda la base de datos ayudó.
2. Números en coma flotante
Los cálculos matemáticos que utilizan las funciones integradas en InfluxDB dan errores de precisión. No es que fuera algo inusual, pero desagradable.
En mi caso, los datos tienen un componente financiero y me gustaría procesarlos con alta precisión. Debido a esto, los planes para abandonar consultas continuas.
3. Las consultas continuas no se pueden adaptar a diferentes zonas horarias.
El servicio tiene una tabla con estadísticas diarias sobre transacciones. Para cada día, debe agrupar todas las transacciones para este día. Pero el día para cada usuario comenzará en un momento diferente, por lo tanto, el conjunto de transacciones es diferente. UTC tiene
37 opciones de turno para las cuales necesita agregar datos.
Al agrupar por tiempo en InfluxDB, también puede especificar un turno, por ejemplo, para la hora de Moscú (UTC + 3):
SELECT MEAN("supply") FROM transactions GROUP BY symbol, time(1d, 3h) fill(previous)
Pero el resultado de la consulta será incorrecto. Por alguna razón, los datos agrupados por día comenzarán a partir de 1677 (InfluxDB respalda oficialmente el período de este año):
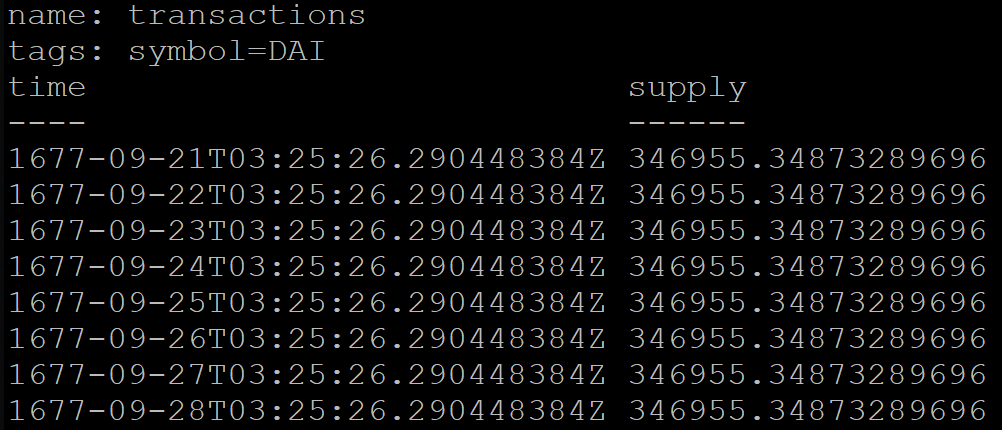
Para evitar este problema, el servicio se transfirió temporalmente a UTC + 0.
4. Rendimiento
Hay muchos puntos de referencia en Internet con comparaciones de InfluxDB y otras bases de datos. A primera vista, parecían materiales de marketing, pero ahora creo que hay algo de verdad en ellos.
Te contaré mi caso.
El servicio proporciona un método API que devuelve estadísticas del último día. Durante los cálculos, el método consulta la base de datos tres veces con las siguientes consultas:
SELECT * FROM coins_info WHERE time <= NOW() GROUP BY symbol ORDER BY time DESC LIMIT 1
SELECT * FROM dominance_info ORDER BY time DESC LIMIT 1
SELECT * FROM transactions WHERE time >= NOW() - 24h ORDER BY time DESC
Explicación
- En la primera consulta, obtenemos los últimos puntos para cada moneda con datos de mercado. Ocho puntos por ocho monedas en mi caso.
- La segunda solicitud recibe uno el punto más nuevo.
- El tercero solicita una lista de transacciones para el último día, puede haber varios cientos.
Aclararé que en InfluxDB, las etiquetas y el tiempo crean automáticamente un índice, lo que acelera las consultas. En la primera consulta, el
símbolo es la etiqueta.
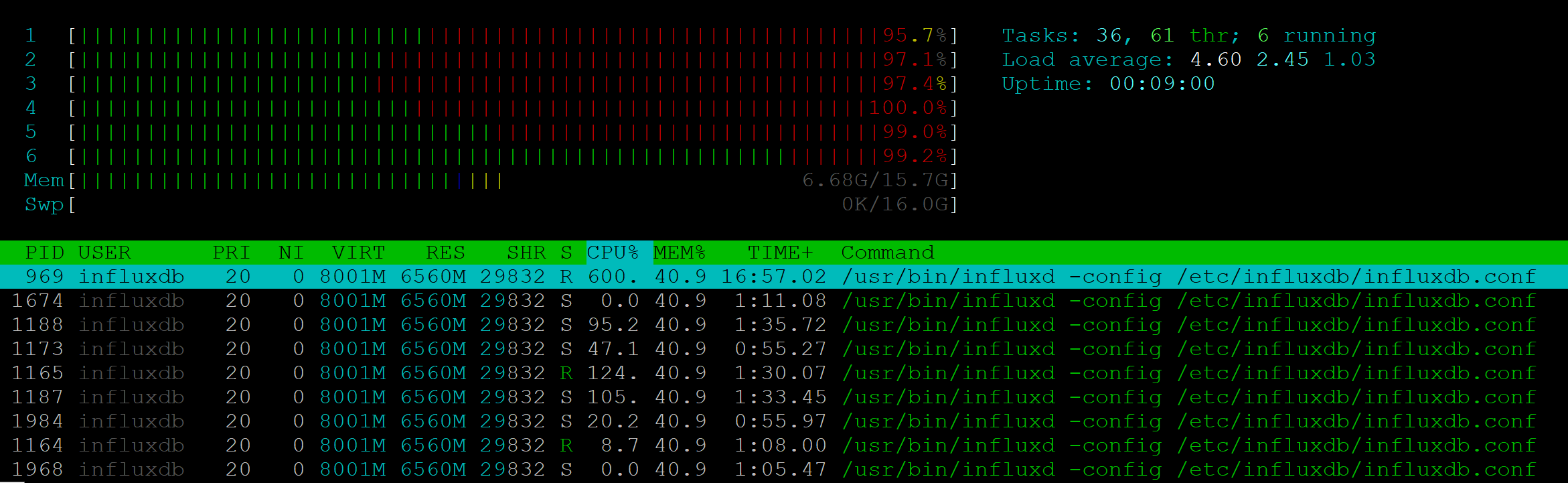
Hice una prueba de esfuerzo para este método API. Para 25 RPS, el servidor mostró una carga completa de seis CPU:
Al mismo tiempo, el proceso NodeJs no dio ninguna carga en absoluto.
La velocidad de ejecución ya se ha degradado en 7-10 RPS: si un cliente puede recibir una respuesta en 200 ms, entonces 10 clientes deben esperar un segundo. 25 RPS: la frontera con la que sufrió la estabilidad, se devolvieron 500 errores a los clientes.
Con tal rendimiento, es imposible usar Influx en nuestro proyecto. Además: en un proyecto en el que necesita demostrar la supervisión a muchos clientes, pueden aparecer problemas similares y el servidor de métricas se sobrecargará.
Conclusión
La conclusión más importante de la experiencia adquirida es que no se puede incorporar una tecnología desconocida al proyecto sin un análisis suficiente. Una simple detección de tickets abiertos en github podría proporcionar información para no tomar InfluxDB como el almacén de datos principal.
InfluxDB debería haber sido adecuado para las tareas de mi proyecto, pero como la práctica lo ha demostrado, esta base de datos no satisface las necesidades y causa muchos problemas.
Ya puede encontrar la versión 2.0.0-beta en el repositorio del proyecto, se espera que en la segunda versión haya mejoras significativas. Mientras tanto, voy a estudiar la documentación de TimescaleDB.