
Con los años, Netcracker ha sido un proveedor de productos para operadores de telecomunicaciones y, al mismo tiempo, actúa como integrador de toda la gama de software del operador. En este trabajo, la tarea surge inevitablemente de sincronizar y coordinar una gran cantidad de versiones de productos y soluciones, en diferentes combinaciones, de diferentes desarrolladores y con diferentes funcionalidades. Muchos operadores evitan deliberadamente la dependencia de un proveedor al crear un zoológico de productos de diferentes proveedores, de modo que en un escenario bastante complejo pueden involucrarse hasta un par de docenas de sistemas y procesos dispares.
Para aclarar de qué se trata, imagine que una vez por semana necesita implementar un proceso utilizando un conjunto de diferentes herramientas y tecnologías: procedimientos PL / SQL, scripts de bash, scripts de Perl, lanzamiento de aplicaciones individuales y acceso a procesos de daemon. Todo esto se debe a la heterogeneidad del panorama de TI del operador. Al mismo tiempo, para cada procedimiento habrá sus propios parámetros de inicio, control de salida, así como un conjunto de posibles errores que afectan la ejecución posterior del script. Cada lanzamiento de este tipo se convierte en una tarea seria que requiere varias horas o días de trabajo de ingenieros de TI altamente calificados: su capacitación puede demorar hasta tres años antes de que se pueda entregar a un operador de telecomunicaciones productivo con decenas de millones de usuarios.
Está claro que estas tareas deben automatizarse. Por lo tanto, decidimos tomar lo mejor de la Orquesta BPMN, el planificador de procesos, el sistema de monitoreo y enriquecer este conjunto con la capacidad de analizar registros y errores. Por supuesto, los mejores representantes de su tipo fueron considerados para cada tipo de sistema. Pero no se encontraron esencias coincidentes para los detalles de la industria. Por lo tanto, hágalo usted mismo.
Brevemente sobre lo que estamos haciendo: los procedimientos heterogéneos se agrupan en "tareas" con un conjunto típico de interfaces y propiedades; una determinada secuencia de tareas forma un "proceso" (por ejemplo, un proceso de facturación de cargos por servicios de comunicación). Además, de acuerdo con un cronograma o de forma manual, cada proceso comienza su secuencia de procedimientos con los parámetros necesarios, supervisa la ejecución, evalúa los resultados de las tareas anidadas y toma una decisión sobre la elección de los escenarios. La relación entre las tareas dentro del proceso se basa en la lógica BPMN estándar, mientras que en el servidor de administración establecimos la capacidad de detener manualmente el proceso, pausarlo, salir del escenario actual y guardar los datos que ya se han procesado. La gestión de procesos se implementa a través de una interfaz web con monitoreo en tiempo real, con evaluación de anomalías, monitoreo de SLA específicos para cada proceso.
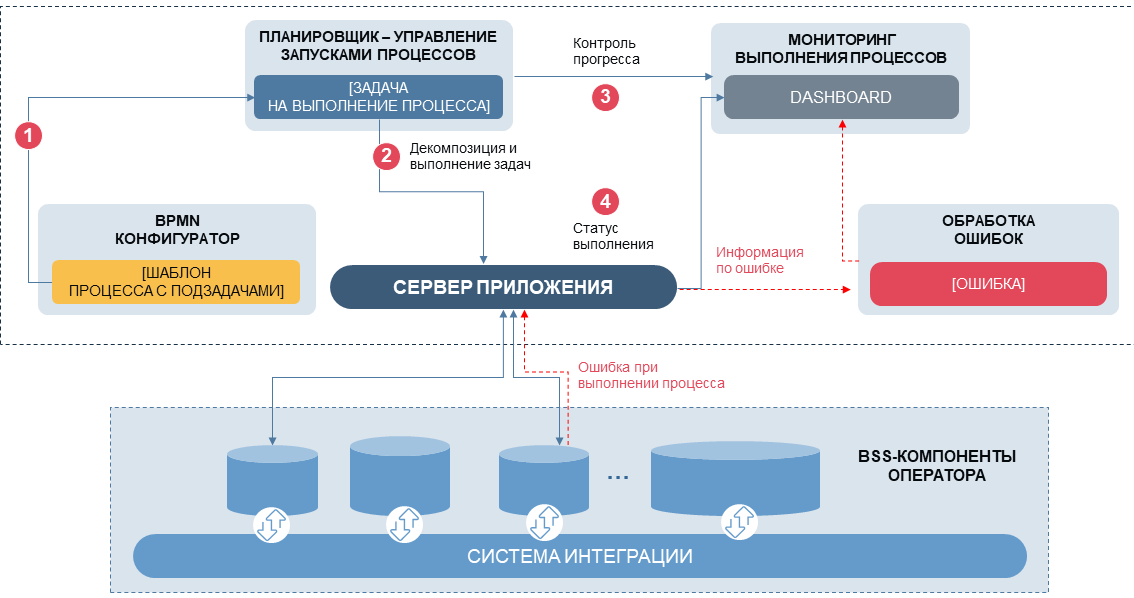
Ahora nuestro "administrador de procesos" puede trabajar en modo semiautomático, pero prácticamente no reduce la carga sobre los ingenieros de TI: cuando dos o más sistemas complejos interactúan, la variabilidad de las anomalías en los procesos aumenta muchas veces y los esfuerzos principales se dedican al manejo de errores. Por lo tanto, en la siguiente etapa, tuvimos que tomar una decisión:
- ¿Cómo queremos automatizar el manejo de errores?
- ¿Cómo corregir escenarios basados en análisis de anomalías?
- En general, ¿cuánto debería intervenir una persona en el funcionamiento de dicho sistema, en qué volúmenes y en qué lugares?
Observo una vez más que todo esto debe hacerse en tiempo real en la productividad del sistema de misión crítica que atiende a decenas y cientos de miles de transacciones por segundo. Y aquí tuvimos que resolver el problema de encontrar y solucionar problemas (la llamada resolución de problemas) en las condiciones:
- actualizaciones periódicas en procesos
- desarrollo de base portadora
- cambios en el conjunto de servicios de telecomunicaciones
Sí, y otra condición importante que debemos cumplir es no dañar. O hablando el idioma de los documentos oficiales, para reducir el tiempo y los costos laborales en la operación de los sistemas de TI de un proveedor de telecomunicaciones.
Surgió la pregunta: en qué proporción se deben mezclar el manejo automático de errores y la participación de expertos en dicha solución de problemas. A continuación, hablemos sobre las opciones.
AI
Dado que vivimos en la era del bombo eterno, decidimos hacer del desarrollo una base de inteligencia artificial, para que este intelecto reconozca errores y anomalías, prediga fallas y las corrija de inmediato. Las grandes empresas y las nuevas empresas ya están creando tales e incluso implementando soluciones similares. El alcance principal de su aplicación: operaciones para construir, mantener y soportar infraestructura de TI. Esto se llama AIOps: operaciones de inteligencia artificial (para TI), y la palabra de moda más popular es NoOps, es decir, operaciones de TI totalmente automatizadas.
Aprender el sistema no será fácil, porque el conjunto de datos históricos es limitado, es costoso hacer una copia exacta del producto, y los ejemplos de enseñanza (aprendizaje activo) son demasiado largos y, en nuestro caso, inexactos. Puede probar el método de agregación bootstrap: para simular un conjunto finito de secuencias de comandos para casos conocidos y sospechosos y crear un árbol de decisión basado en él, por ejemplo, Árbol de clasificación y regresión, pero este también es un método bastante costoso. Pero si hacemos todo esto, haremos que el programa piense por nosotros y ahorremos un montón de recursos útiles (que, traducidos de gerenciales a humanos, significa "despedir a los administradores de sistemas más molestos").
Contras:
- Debido a la complejidad de los sistemas y su interacción, es prácticamente imposible crear y entrenar una cierta versión "en caja" de dicha solución para todas las situaciones posibles. Para cada nuevo proyecto, este será su propio "curso de capacitación" separado, con el reconocimiento de errores específicos, anomalías y formas apropiadas de resolverlos.
- No diseñamos una solución masiva, sino interna, para un número limitado de implementaciones (porque hay muy pocos operadores de esta escala en el mundo). Puede resultar fácilmente para que sea más económico ofrecer a nuestros clientes la subcontratación "humana" adecuada para resolver estos problemas.
- Quizás es más probable que nuestros clientes soporten los costos de nuevos ingenieros altamente calificados que los riesgos de transferir el soporte del producto a la inteligencia artificial. Para decirlo suavemente, esto puede generar algunas preocupaciones.
No soy yo, mi cerebro
Como no se puede prescindir de la intervención humana, seguimos el camino tradicional. Recuerde, una vez que pensamos que "una máquina debería funcionar, y una persona debería pensar". Reformulamos esto: "el programa debería resolver problemas conocidos y el ingeniero debería resolver incógnitas".
Creamos un sistema algorítmico organizado en el concepto de aprendizaje reforzado, pero con una lógica clara. La capacitación del sistema se lleva a cabo en un volumen estrecho y controlado, las reglas se almacenan de forma transparente, se pueden editar, expandir, especificar, deshabilitar, etc. Tal desarrollo no es mucho más complicado que la simple "semiautomatización". Todavía se necesita un ingeniero calificado para la operación, pero sus recursos se utilizan únicamente para identificar y resolver nuevos problemas. Si nos adherimos firmemente al principio "una persona no debe resolver problemas conocidos", podemos suponer que después de un tiempo el suministro de problemas desconocidos comenzará a agotarse, y la funcionalidad del sistema desarrollado se acercará a la IA para este campo de aplicación en particular.
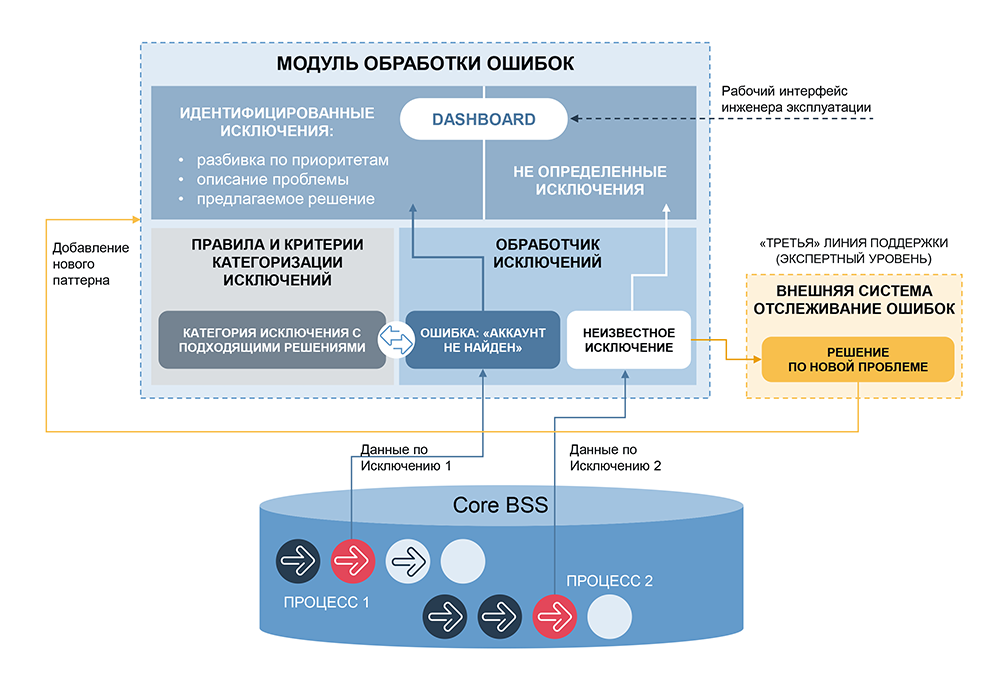
La parte más importante de dicho sistema es la categorización, reidentificación de anomalías. Nuestra compañía ya tiene un sistema similar: Order Tracker, que se utiliza para monitorear los procesos comerciales de un operador móvil que administra pedidos. Order Tracker analiza cientos de eventos por segundo, identifica anomalías tanto en filas separadas como en combinaciones de eventos, permite al usuario agruparlos, establecer valores máximos y mínimos, determinar errores de diferentes niveles de gravedad y proponer acciones para resolver problemas. El sistema ha estado funcionando durante mucho tiempo, muchos rastrillos ya se han completado con éxito, por lo que lo tomamos como una herramienta para la categorización.
Ahora era necesario automatizar la solución de problemas. A diferencia de la gestión de pedidos, donde a menudo se requiere la intervención del operador (por ejemplo, cuando necesita involucrar al departamento de finanzas, servicio al cliente, etc.), tenemos la oportunidad de resolver automáticamente una parte importante de los incidentes y existe una herramienta preparada para diseñar estas soluciones: secuencias de comandos de bloques prefabricados, que puede complementarse, la lógica expandida, incluye verificaciones adicionales y se asocia con cada categoría reconocida de errores.
¿Qué podría salir mal?
Eso es todo!
El sistema de monitoreo de pedidos generalmente no requiere toma de decisiones y corrección en tiempo real, y cualquier anomalía afecta a un número limitado de clientes, de uno a varios cientos. Estamos tratando de introducir el manejo automático de errores en procesos que afectan a cientos de miles y millones de suscriptores y requieren una solución en tiempo real o en unas pocas horas. Este es un gran riesgo para cualquier operador con el que trabajemos y, por lo tanto, para nosotros, para nuestra reputación.
Tuvimos que aumentar significativamente la flexibilidad de los scripts, implementar un sistema de control de versiones, agregar la entidad "instancia de script", es decir, para cada script ahora puede crear muchas subclases con ciertas combinaciones de parámetros, umbrales, verificaciones adicionales, etc. Tuve que aumentar la flexibilidad de muchas tareas mediante la introducción de controles adicionales de los parámetros de entrada y salida.
Otra dirección de desarrollo es aumentar la granularidad de las categorías de eventos analizados y crear metacategorías, es decir combinaciones de diferentes eventos definidos por el categorizador. Agregamos una estimación de la secuencia de anomalías y la coincidencia de diferentes anomalías en el tiempo. El sistema se volvió cada vez más complicado, pero aún conservaba una lógica clara: para cualquier par "categoría de anomalías - escenario seleccionado", las relaciones causales aún se conservan.
Para muchas combinaciones, ya hemos obtenido resultados confiables y confiables y los hemos lanzado de manera productiva. Los errores, cuya búsqueda y corrección anteriormente llevaban horas, ahora se resuelven en modo automático. Para otros tipos de anomalías, seguimos probando: en algún lugar de los datos de prueba, en algún lugar en el modo de verificación manual y confirmación del escenario seleccionado.
Y luego resultó ...
Recientemente nos dimos cuenta de que obtuvimos un resultado de estos trabajos que no esperábamos al principio: una herramienta altamente efectiva para la ingeniería inversa de las soluciones de otras personas, incluidas aquellas para las que no tenemos el apoyo de los desarrolladores, ni siquiera una documentación clara. Sin darse cuenta, se llevó a cabo el llamado "descubrimiento de procesos de negocio". Aprendimos en la práctica a analizar la lógica de las aplicaciones, identificar errores internos y problemas de integración con otros sistemas. Ahora no solo podemos orquestar las aplicaciones de otras personas, podemos desarrollar soluciones para ellas, mejorar la integración y lo más valioso es ofrecer nuestros productos para reemplazar el legado existente.
En la siguiente etapa, queremos intentar implementar nuestra solución en forma de un producto integral para pruebas de integración, que detectará automáticamente errores y anomalías, aprenderá sobre la marcha, proporcionará herramientas para la corrección sintomática y para buscar y analizar problemas en la lógica de la aplicación. Esta solución no tendrá menos eficiencia que los modernos AIOps y NoOps, mientras conservamos la lógica de decisión transparente y manejable. Entonces, si en un par de años te encuentras con una solución de Netcracker en el mercado, ten en cuenta que todo comenzó con scripts de bash ...