
Las tecnologías y modelos para nuestro futuro sistema de visión por computadora se crearon y mejoraron gradualmente en varios proyectos de nuestra compañía, en Mail, Cloud y Search. Madurado como buen queso o coñac. Una vez que nos dimos cuenta de que nuestras redes neuronales mostraban excelentes resultados de reconocimiento, y decidimos unirlas en un solo producto b2b, Visión, que ahora usamos nosotros mismos y ofrecemos para usarlo.
Hoy en día, nuestra tecnología de visión por computadora en la plataforma Mail.Ru Cloud Solutions funciona con éxito y resuelve problemas prácticos muy complejos. Se basa en una serie de redes neuronales que están capacitadas en nuestros conjuntos de datos y se especializan en resolver problemas aplicados. Todos los servicios están girando en las capacidades de nuestro servidor. Puede integrar la API pública de Vision en sus aplicaciones, a través de la cual todas las características del servicio están disponibles. La API es rápida: gracias a las GPU del servidor, el tiempo de respuesta promedio dentro de nuestra red es de 100 ms.
Ven debajo del corte, hay una historia detallada y muchos ejemplos de Visión.
Como ejemplo de un servicio en el que nosotros mismos utilizamos las tecnologías de reconocimiento facial mencionadas anteriormente, podemos citar
Eventos . Uno de sus componentes son los soportes de fotos Vision, que instalamos en varias conferencias. Si sube a un puesto de fotos de este tipo, tome una foto con la cámara incorporada e ingrese su correo, el sistema encontrará inmediatamente entre la variedad de fotos aquellas de las cuales los fotógrafos de conferencias regulares lo han capturado y, si lo desea, le enviará las fotos encontradas por correo. Y no se trata de retratos en escena: Vision lo reconoce incluso en el fondo en la multitud de visitantes. Por supuesto, no son reconocidos por los soportes de fotos, solo son tabletas en hermosos posavasos que simplemente fotografían a los invitados en sus cámaras incorporadas y transmiten información a los servidores, donde tiene lugar toda la magia del reconocimiento. Y hemos observado repetidamente cuán sorprendente es la efectividad de la tecnología incluso entre los especialistas en reconocimiento de imágenes. A continuación hablaremos de algunos ejemplos.
1. Nuestro modelo de reconocimiento facial
1.1. Red neuronal y velocidad de procesamiento
Para el reconocimiento, utilizamos una modificación del modelo de red neuronal ResNet 101. La agrupación promedio al final se reemplaza por una capa completamente conectada, similar a como se hizo en ArcFace. Sin embargo, el tamaño de las representaciones vectoriales es 128, no 512. Nuestro conjunto de entrenamiento contiene alrededor de 10 millones de fotos de 273,593 personas.
El modelo funciona muy rápido gracias a una arquitectura de configuración de servidor cuidadosamente seleccionada y computación GPU. Se necesitan 100 ms para obtener una respuesta de la API en nuestras redes internas; esto incluye la detección de rostros (detección de rostros en la foto), el reconocimiento y la devolución del PersonID en la respuesta de la API. Con grandes volúmenes de datos entrantes (fotos y videos), llevará mucho más tiempo transferir datos al servicio y recibir una respuesta.
1.2. Estimación de la eficiencia del modelo.
Pero determinar la eficiencia de las redes neuronales es una tarea muy mixta. La calidad de su trabajo depende de en qué conjuntos de datos se entrenaron los modelos y si fueron optimizados para trabajar con datos específicos.
Comenzamos a evaluar la precisión de nuestro modelo con la popular prueba de verificación LFW, pero es demasiado pequeña y simple. Después de alcanzar el 99.8% de precisión, ya no es útil. Hay una buena competencia para evaluar los modelos de reconocimiento: Megaface en él alcanzamos gradualmente el 82% rango 1. La prueba de Megaface consta de un millón de fotos, distractores, y el modelo debería poder distinguir bien varios miles de fotos de celebridades del conjunto de datos Facescrub de los distractores. Sin embargo, después de borrar la prueba de errores de Megaface, descubrimos que en la versión limpia alcanzamos una precisión del 98% de rango 1 (las fotos de celebridades generalmente son bastante específicas). Por lo tanto, crearon una prueba de identificación separada, similar a Megaface, pero con fotos de personas "comunes". Mejoró aún más la precisión de reconocimiento en sus conjuntos de datos y siguió adelante. Además, utilizamos la prueba de calidad de agrupamiento, que consta de varios miles de fotografías; Simula el marcado de caras en la nube del usuario. En este caso, los grupos son grupos de individuos similares, un grupo para cada persona reconocible. Verificamos la calidad del trabajo en grupos reales (verdadero).
Por supuesto, cualquier modelo tiene errores de reconocimiento. Pero tales situaciones a menudo se resuelven ajustando los umbrales para condiciones específicas (para todas las conferencias usamos los mismos umbrales, y, por ejemplo, para los SCA tenemos que aumentar significativamente los umbrales para que haya menos falsos positivos). La gran mayoría de los asistentes a la conferencia fueron reconocidos por nuestros soportes de fotos Vision correctamente. A veces alguien miraba la vista previa recortada y decía: "Tu sistema estaba mal, no soy yo". Luego abrimos toda la fotografía, y resultó que este visitante realmente estaba en la fotografía, solo que no la tomaron, pero alguien más, solo un hombre apareció accidentalmente en el fondo en la zona borrosa. Además, la red neuronal a menudo reconoce correctamente incluso cuando una parte de la cara no es visible, o una persona está de perfil, o incluso media cara. El sistema puede reconocer a una persona, incluso si la persona cayó en el campo de la distorsión óptica, por ejemplo, al disparar con una lente gran angular.
1.3. Ejemplos de pruebas en situaciones difíciles
A continuación se presentan ejemplos del funcionamiento de nuestra red neuronal. En la entrada, se envían fotos, que debe marcar con PersonID, un identificador único para la persona. Si dos o más imágenes tienen el mismo identificador, entonces, según los modelos, estas fotos muestran a una persona.
Inmediatamente, notamos que durante las pruebas tenemos acceso a varios parámetros y umbrales de modelos que podemos configurar para lograr un resultado particular. La API pública está optimizada para la máxima precisión en casos comunes.
Comencemos con lo más simple, con reconocimiento facial en la cara.

Bueno, eso fue demasiado fácil. Complicamos la tarea, agregamos una barba y un puñado de años.

Alguien dirá que esto no fue demasiado difícil, porque en ambos casos la cara es visible en su totalidad, el algoritmo tiene mucha información sobre la cara. De acuerdo, convierte a Tom Hardy en el perfil. Esta tarea es mucho más complicada, y dedicamos mucho esfuerzo a su solución exitosa mientras mantenemos un bajo nivel de errores: seleccionamos una muestra de entrenamiento, pensamos en la arquitectura de la red neuronal, perfeccionamos las funciones de pérdida y mejoramos el procesamiento preliminar de las fotos.
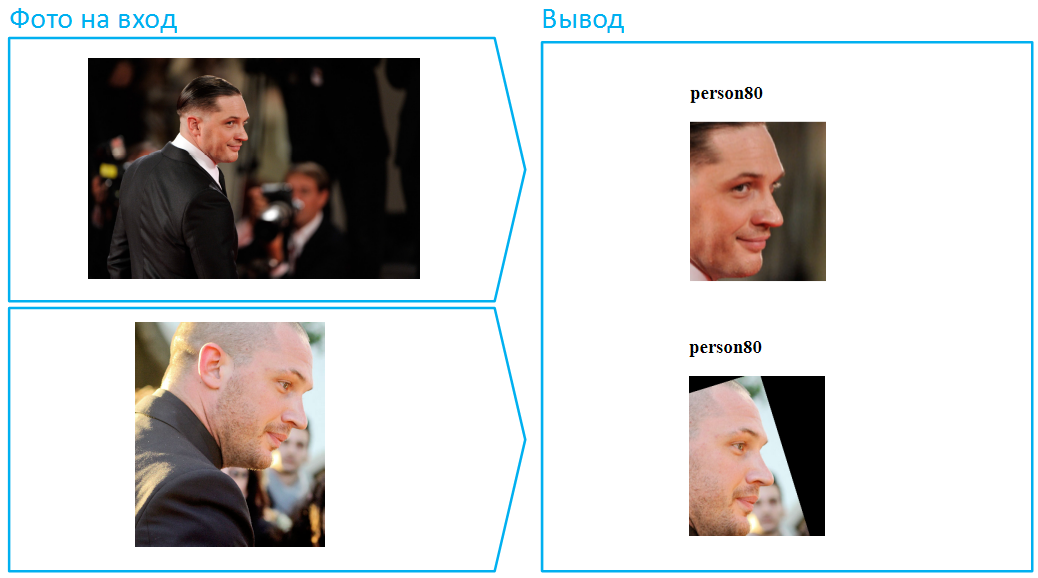
Vamos a ponerle un sombrero:

Por cierto, este es un ejemplo de una situación particularmente difícil, ya que la cara está muy cubierta aquí, y en la imagen inferior también hay una sombra profunda que oculta los ojos. En la vida real, las personas a menudo cambian su apariencia con la ayuda de lentes oscuros. Haz lo mismo con Tom.

Bueno, intentemos subir fotos de diferentes edades, y esta vez vamos a poner experiencia en otro actor. Tomemos un ejemplo mucho más complejo cuando los cambios relacionados con la edad son especialmente pronunciados. La situación no es descabellada, sucede todo el tiempo cuando necesita comparar una fotografía en su pasaporte con la cara del portador. Después de todo, la primera foto está atrapada en el pasaporte cuando el propietario tiene 20 años y 45 personas pueden cambiar mucho:

¿Crees que el especial principal en misiones imposibles no ha cambiado mucho con la edad? Creo que incluso unas pocas personas combinarían las fotos superior e inferior, el niño ha cambiado mucho a lo largo de los años.

Las redes neuronales se enfrentan a cambios en la apariencia con mucha más frecuencia. Por ejemplo, a veces las mujeres pueden cambiar mucho su imagen con la ayuda de los cosméticos:

Ahora vamos a complicar aún más la tarea: dejar que diferentes partes de la cara se cubran con diferentes fotos. En tales casos, el algoritmo no puede comparar las muestras completas. Sin embargo, Vision maneja bien tales situaciones.
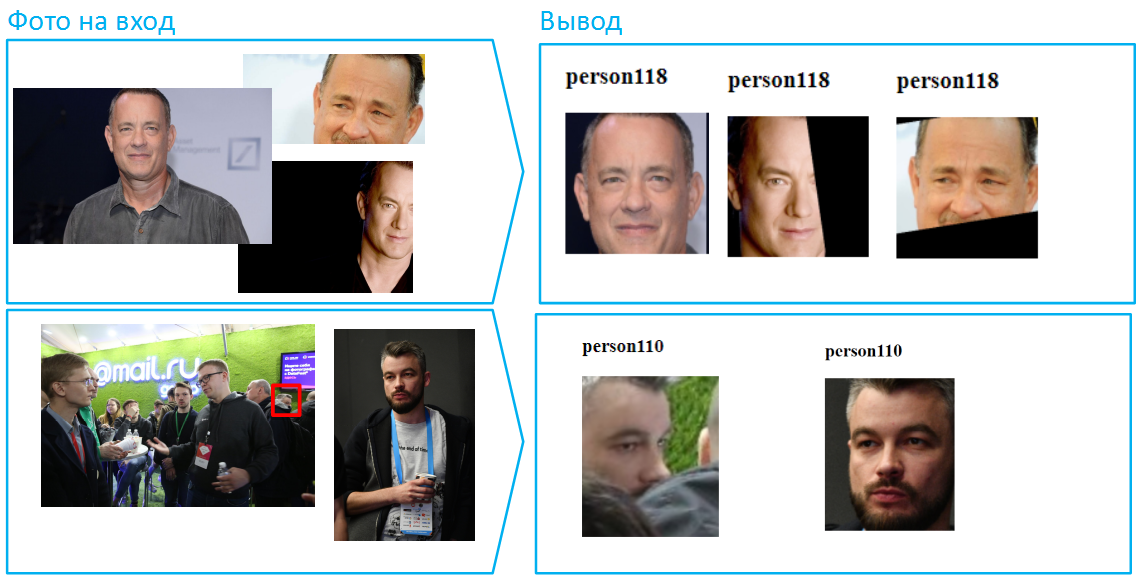
Por cierto, hay muchas caras en las fotografías, por ejemplo, más de 100 personas pueden caber en una imagen común de la sala. Esta es una situación difícil para las redes neuronales, ya que muchas caras se pueden iluminar de manera diferente, alguien fuera de la zona de nitidez. Sin embargo, si la foto se tomó con suficiente resolución y calidad (al menos 75 píxeles por cuadrado que cubre la cara), Vision podrá identificarla y reconocerla.

La peculiaridad de informar fotografías e imágenes de cámaras de vigilancia es que las personas a menudo están borrosas porque estaban fuera del campo de nitidez o se movían en ese momento:

Además, la intensidad de la iluminación puede variar mucho de una imagen a otra. Esto también a menudo se convierte en un obstáculo, muchos algoritmos tienen una gran dificultad para procesar correctamente imágenes que son demasiado oscuras y claras, sin mencionar la comparación exacta. Permítame recordarle que para lograr ese resultado, debe establecer umbrales de cierta manera, esta posibilidad aún no está disponible públicamente. Para todos los clientes, utilizamos la misma red neuronal, tiene umbrales adecuados para la mayoría de las tareas prácticas.

Recientemente, lanzamos una nueva versión del modelo que reconoce las caras asiáticas con alta precisión. Anteriormente, este era un gran problema, que incluso se llamaba "racismo de aprendizaje automático" (o "redes neuronales"). Las redes neuronales europeas y americanas reconocieron bien los rostros europeos, y las cosas fueron mucho peores con los mongoloides y los negroides. Probablemente en la misma China, la situación era exactamente lo contrario. Se trata de conjuntos de datos de capacitación que reflejan los tipos dominantes de personas en un país en particular. Sin embargo, la situación está cambiando, hoy este problema está lejos de ser tan grave. La visión no tiene ninguna dificultad con representantes de diferentes razas.

El reconocimiento facial es solo una de las muchas aplicaciones de nuestra tecnología. Se puede enseñar a Vision a reconocer cualquier cosa. Por ejemplo, números de automóviles, incluso en condiciones difíciles para algoritmos: en ángulos agudos, números sucios y difíciles de leer.

2. Casos de uso práctico
2.1. Control de acceso físico: cuando dos van en el mismo pase
Con la ayuda de Vision, es posible implementar sistemas de contabilidad para la llegada y salida de los empleados. Un sistema tradicional basado en pases electrónicos tiene inconvenientes obvios, por ejemplo, puede pasar por dos insignias juntas. Si el sistema de control de acceso (ACS) se complementa con Vision, honestamente registrará quién entró y cuándo.
2.2. Seguimiento de tiempo
Este caso de uso para Vision está estrechamente relacionado con el anterior. Si complementamos el sistema de control de acceso con nuestro servicio de reconocimiento facial, será capaz de notar no solo violaciones del control de acceso, sino también registrar la estadía real de los empleados en el edificio o en las instalaciones. En otras palabras, Vision ayudará a considerar honestamente quién y cuánto vino a trabajar y se fue con ella, y quién incluso se saltó, incluso si sus colegas lo cubrieron frente a sus superiores.
2.3. Análisis de video: seguimiento de personas y seguridad
Al rastrear a las personas que usan Vision, puede evaluar con precisión la permeabilidad real de las áreas comerciales, estaciones de tren, cruces, calles y muchos otros lugares públicos. Nuestro seguimiento también puede ser de gran ayuda para controlar el acceso, por ejemplo, a un almacén u otras oficinas importantes. Y, por supuesto, rastrear personas y rostros ayuda a resolver problemas de seguridad. ¿Atrapó a alguien robando de su tienda? Agréguelo al PersonID, que devolvió Vision, en la lista negra de su software de análisis de video, y la próxima vez que el sistema alertará inmediatamente a la seguridad si este tipo aparece nuevamente.
2.4. En el comercio
Las empresas minoristas y de servicios diversos están interesadas en el reconocimiento de colas. Con Vision, puede reconocer que no se trata de una multitud aleatoria de personas, sino más bien una cola, y determinar su longitud. Y luego el sistema informa a las personas responsables sobre la cola para comprender la situación: o bien esto es una afluencia de visitantes y se debe llamar a empleados adicionales, o alguien está hackeando sus responsabilidades laborales.
Otra tarea interesante es la separación de los empleados de la empresa en la sala de los visitantes. Por lo general, el sistema aprende a separar objetos en ciertas prendas (código de vestimenta) o con alguna característica distintiva (bufanda de firma, insignia en el cofre, etc.). Esto ayuda a evaluar con mayor precisión la asistencia (para que los empleados solos no "terminen" las estadísticas de las personas en el pasillo).
Mediante el reconocimiento facial, puede evaluar su audiencia: cuál es la lealtad de los visitantes, es decir, cuántas personas regresan a su institución y con qué frecuencia. Calcule cuántos visitantes únicos vienen a usted en un mes. Para optimizar los costos de atraer y retener, puede averiguar el cambio de asistencia según el día de la semana e incluso la hora del día.
Los franquiciadores y las compañías de la red pueden solicitar una evaluación de la calidad de la marca de varios puntos de venta minorista a partir de fotografías: la presencia de logotipos, letreros, carteles, pancartas, etc.
2.5. En el transporte
Otro ejemplo de seguridad a través de la analítica de video es la identificación de elementos que quedan en los pasillos de aeropuertos o estaciones de trenes. La visión puede ser entrenada para reconocer objetos de cientos de clases: muebles, bolsos, maletas, sombrillas, varios tipos de ropa, botellas, etc. Si su sistema de análisis de video detecta un objeto sin propietario y lo reconoce usando Vision, envía una señal al servicio de seguridad. Una tarea similar está relacionada con la detección automática de situaciones no estándar en lugares públicos: alguien se enfermó, o alguien fumó en el lugar equivocado, o la persona se cayó sobre los rieles, y así sucesivamente: todos estos patrones del sistema de análisis de video pueden reconocer a través de API Vision.
2.6. Flujo de trabajo
Otra aplicación futura interesante de Vision que estamos desarrollando actualmente es el reconocimiento de documentos y su análisis automático en bases de datos. En lugar de ingresar manualmente (o peor aún, ingresar) series interminables, números, fechas de emisión, números de cuenta, detalles bancarios, fechas y lugares de nacimiento y muchos otros datos formalizados, puede escanear documentos y enviarlos automáticamente a través de un canal seguro a través de la API en la nube, donde el sistema estará sobre la marcha, estos documentos serán reconocidos, analizados y devolverán una respuesta con los datos en el formato deseado para la entrada automática en la base de datos. Hoy Vision ya sabe cómo clasificar documentos (incluso en PDF): distingue pasaportes, SNILS, TIN, certificados de nacimiento, certificados de matrimonio y otros.
Por supuesto, en todas estas situaciones, la red neuronal no es capaz de manejar de forma inmediata. En cada caso, se construye un nuevo modelo para un cliente en particular, se tienen en cuenta muchos factores, matices y requisitos, se seleccionan los conjuntos de datos, se repiten los ajustes de las pruebas de capacitación.
3. esquema de trabajo API
La “puerta de entrada” de Vision para los usuarios es la API REST. En la entrada, puede tomar fotos, archivos de video y transmisiones desde cámaras de red (transmisiones RTSP).
Para usar Vision, debe
registrarse en Mail.ru Cloud Solutions y obtener tokens de acceso (client_id + client_secret). La autenticación del usuario se realiza utilizando el protocolo OAuth. Los datos de origen en los cuerpos de las solicitudes POST se envían a la API. Y en respuesta, el cliente recibe el resultado de reconocimiento de la API en formato JSON, y la respuesta está estructurada: contiene información sobre los objetos encontrados y sus coordenadas.

Ejemplo de respuesta{ "status":200, "body":{ "objects":[ { "status":0, "name":"file_0" }, { "status":0, "name":"file_2", "persons":[ { "tag":"person9" "coord":[149,60,234,181], "confidence":0.9999, "awesomeness":0.45 }, { "tag":"person10" "coord":[159,70,224,171], "confidence":0.9998, "awesomeness":0.32 } ] } { "status":0, "name":"file_3", "persons":[ { "tag":"person11", "coord":[157,60,232,111], "aliases":["person12", "person13"] "confidence":0.9998, "awesomeness":0.32 } ] }, { "status":0, "name":"file_4", "persons":[ { "tag":"undefined" "coord":[147,50,222,121], "confidence":0.9997, "awesomeness":0.26 } ] } ], "aliases_changed":false }, "htmlencoded":false, "last_modified":0 }
La respuesta tiene un parámetro interesante de genialidad: esta es la "frescura" condicional de la cara en la foto, con ella seleccionamos la mejor toma de la secuencia. Entrenamos a la red neuronal para predecir la probabilidad de que la imagen sea como en las redes sociales. Cuanto mejor es la imagen y más suave es la cara, mayor es la asombro.
Vision API utiliza un concepto como el espacio. Esta es una herramienta para crear diferentes conjuntos de caras. Ejemplos de espacios son listas en blanco y negro, listas de visitantes, empleados, clientes, etc. Para cada token en Vision, puede crear hasta 10 espacios, en cada espacio puede haber hasta 50 mil PersonID, es decir, hasta 500 mil por un token . Además, el número de tokens por cuenta no está limitado.
Hoy, la API admite los siguientes métodos de detección y reconocimiento:
- Reconocer / Establecer: definición y reconocimiento de caras. Asigna automáticamente un PersonID a cada cara única, devuelve el PersonID y las coordenadas de las caras encontradas.
- Eliminar: elimina un PersonID específico de la base de datos de personas.
- Truncar: borrar todo el espacio de PersonID, útil si se usó como prueba y necesita restablecer la base para la producción.
- Detectar: definición de objetos, escenas, placas, atracciones, colas, etc. Devuelve la clase de objetos encontrados y sus coordenadas
- Detectar documentos: detecta tipos específicos de documentos de la Federación Rusa (distingue pasaporte, snls, posada, etc.).
Además, pronto terminaremos de trabajar en métodos para OCR, determinar el sexo, la edad y las emociones, así como resolver tareas de comercialización, es decir, controlar automáticamente la exhibición de productos en las tiendas. Puede encontrar la documentación completa de la API aquí:
https://mcs.mail.ru/help/vision-api4. Conclusión
Ahora, a través de la API pública, puede acceder al reconocimiento facial en fotos y videos, admite la definición de varios objetos, números de automóviles, atracciones, documentos y escenas completas. Escenarios de aplicación - Mar. Ven, prueba nuestro servicio, establece las tareas más difíciles para él. Las primeras 5,000 transacciones son gratis. Puede ser el "ingrediente faltante" para sus proyectos.
El acceso a la API se puede obtener instantáneamente al registrarse y conectarse a
Vision . Todos los usuarios de Habra: un código promocional para transacciones adicionales. ¡Escriba una dirección de correo electrónico personal en la que se registró la cuenta!