En la primera parte del informe, describimos cómo medimos la calidad de la documentación y la efectividad de su desarrollo. Ahora sumérgete en los detalles de contar las métricas.
Dice Yuri Nikulin, jefe del servicio de desarrollo de documentación técnica.
Para comenzar, definamos qué es el rendimiento. En el sentido clásico, este es el tiempo necesario para producir una unidad de producción o la cantidad de producción producida por unidad de tiempo .
Por ejemplo, esta es la cantidad de teléfonos producidos por mes o la cantidad de tiempo que lleva producir miles de teléfonos. Se plantea la cuestión de cómo medir el trabajo intelectual en el que participa nuestro departamento.
Si aplicamos el enfoque clásico para evaluar la productividad, podemos calcular cuántos documentos, páginas o palabras se escriben por día, semana y mes. Esto ayudará a evaluar el tiempo potencial para producir documentación en el futuro, pero no responderá la pregunta sobre el rendimiento. Después de todo, definitivamente no estamos interesados en evaluar la efectividad de los escritores por la cantidad de palabras escritas por ellos. Por lo tanto, decidimos que deberíamos comenzar con los requisitos para las métricas que planeamos contar.
Hemos identificado varios criterios para seleccionar métricas:
- Transparencia El enfoque para calcular las métricas e interpretar los resultados debe ser claro no solo para nosotros, sino también para los clientes.
- Disponibilidad de datos. Incluyendo datos de cualquier período pasado para presentar hipótesis e intentar confirmarlas con datos históricos.
- Capacidad para automatizar el conteo. Definitivamente no queremos contar métricas a mano.
Como resultado, nos dimos cuenta de que el objeto ideal para calcular las métricas de rendimiento es la tarea en el Rastreador. Cumple con todos los requisitos que establecemos para las métricas.
La fuente de datos para nosotros fue Yandex.Tracker. Es bastante flexible y fácilmente personalizable para nuestras tareas. Ya tiene todos los datos necesarios, porque usamos esta herramienta todos los días. Y el Rastreador también tiene una API, lo que significa que puede utilizar esta información y automatizar procesos.
Entonces teníamos un plan sobre cómo proceder.
Configurar colas y tareas
Debe comenzar eligiendo las colas, la jerarquía de tareas, sus tipos y estados.
Esto fue descrito en detalle por Katya Kunenko en el informe " Herramientas para la preparación de la documentación del usuario ". Hablaremos brevemente sobre las colas y las tareas, que usamos nosotros mismos.
Colas
Tenemos tres líneas, que en esencia reflejan nuestro público objetivo.

Jerarquía de tareas
Nuestras tareas tienen una estructura de dos niveles:
- en el nivel superior, las tareas corresponden a documentos publicados,
- en el nivel inferior, las tareas corresponden al trabajo en el documento.
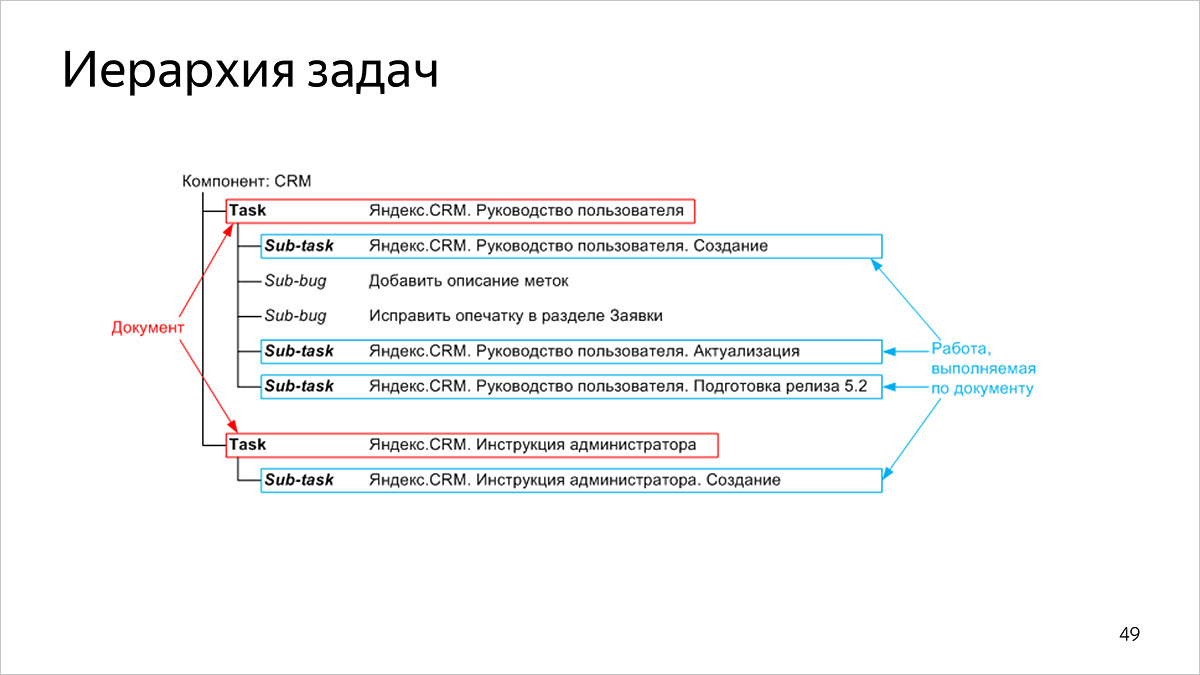
Tipos y estados de tareas
Los tipos y estados de las tareas no solo nos permiten clasificar los tipos de trabajo y su estado actual, sino que también consideran nuestras métricas con secciones.
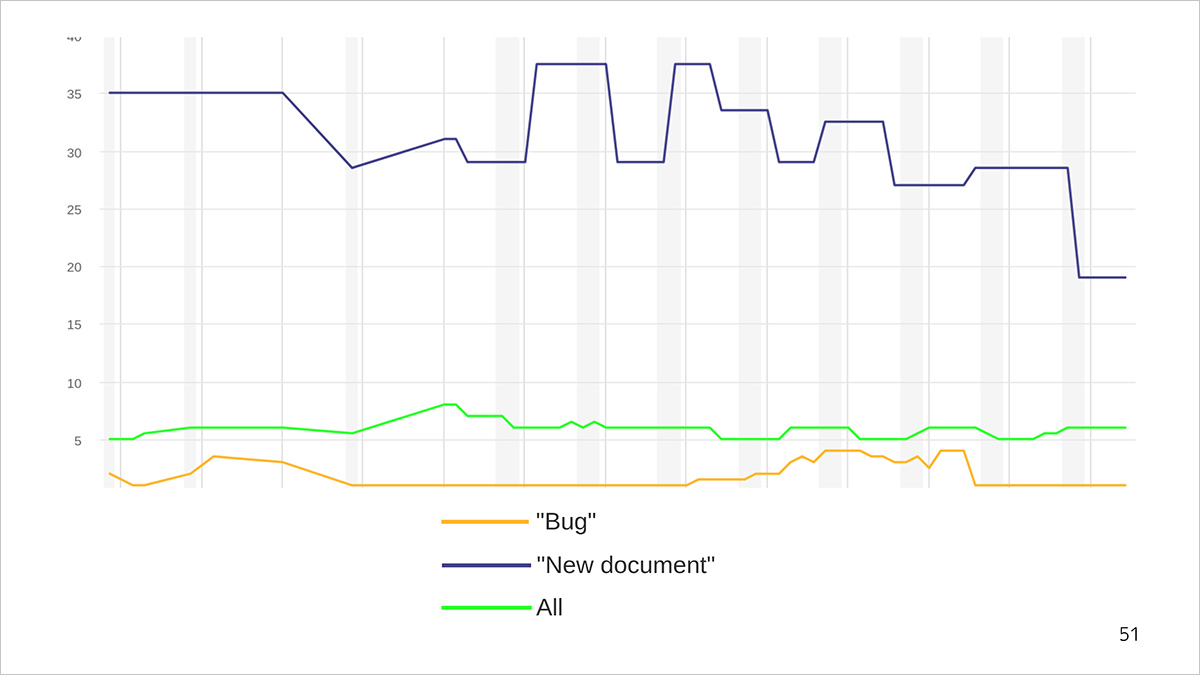
Cronología para completar tareas. La línea azul es el tiempo de producción promedio del documento, el naranja es el tiempo para corregir el error, el verde es el tiempo promedio para completar tareas de todo tipo.
Contaremos un ejemplo de un gráfico. Por ejemplo, un error se corrige entre 1 y 5 días, y se tarda 30-40 en escribir un nuevo documento. Al mismo tiempo, escribimos nuevos documentos con menos frecuencia de la que complementamos los antiguos o corrigimos errores. Por lo tanto, el tiempo de ejecución promedio de una tarea de cualquier tipo (línea verde) es demasiado largo para errores y demasiado corto para documentos nuevos. Con su ayuda, obtenemos solo una idea promedio de la velocidad de resolución de problemas.
Dado que consideramos las métricas para optimizar los procesos, debemos analizar sectores más precisos: por ejemplo, cuánto tiempo resolvemos el problema de "error" o "documento nuevo". Y se puede ver el promedio de todos los tipos para seguir la tendencia general.
Usamos ese conjunto de tipos de tareas.
Hay más estados que tipos, porque el flujo de trabajo requiere esto.
Es más fácil trabajar con tipos y estados si no son ambiguos y no hay demasiados. De lo contrario, los artistas pueden confundirse.
Cómo considerar las métricas de rendimiento
En la última parte, dijimos que realizamos un estudio y seleccionamos 20 métricas de documentación de 136. Seis de ellas son métricas de rendimiento.

Hay dos aspectos para contar las métricas.
- Contando métricas en rodajas. Arriba, dijimos qué es y por qué es importante para nosotros.
- Contando valores promediados.
El enfoque clásico de calcular valores promediados es resumir todos los indicadores y dividirlos por su número. Este enfoque no siempre funciona bien porque tiene en cuenta los casos degenerados. Por ejemplo, sabemos que la mayoría de los errores los corregimos en un día. Pero hay casos degenerados, por ejemplo, un boleto se pierde o un empleado renuncia, y luego lleva más tiempo solucionarlo. Supongamos que tenemos seis errores para el período bajo revisión. Decidimos cinco en un día y uno en 115. Resulta que la corrección de error promedio es de 20 días. Pero esta cifra no refleja la realidad: casi siempre corregimos los errores del día, y un boleto largo afecta significativamente este indicador.
En tales casos, el percentil viene al rescate. Este es el valor máximo (en nuestro caso, métricas), que se ajusta al porcentaje especificado de objetos. Por ejemplo, el percentil 80 es un valor que no excede el 80% de los objetos en la muestra. En nuestro caso, dicho valor sería un valor de 1, ya que el 83% de los objetos no lo exceden.
Aquí aparece el tercer plano: el tiempo durante el cual contamos las métricas. Casi todas nuestras métricas cuentan en 30 días.

Consideramos las métricas con cortes de la siguiente manera:
- primero todas las líneas juntas,
- luego cortamos por turnos
- luego detallamos: hacemos un corte en las colas con un corte para todo tipo de tareas.
Cada sección posterior de la métrica refina la anterior. El valor promedio para todas las colas, tipos y estados de tareas da una idea generalizada. Luego consideramos el valor de las colas individuales para comprender cómo están las cosas con la documentación técnica, del usuario o interna. En el último nivel más detallado, estamos trabajando en una línea "cola + tipo y estado".
Además, diremos cómo consideramos las métricas de rendimiento.
Cantidad de tareas cerradas

Como consideramos: de acuerdo con la cantidad de tareas que están cerradas en el intervalo [hace 31 días; ayer]
El número de tareas realizadas en el trabajo.
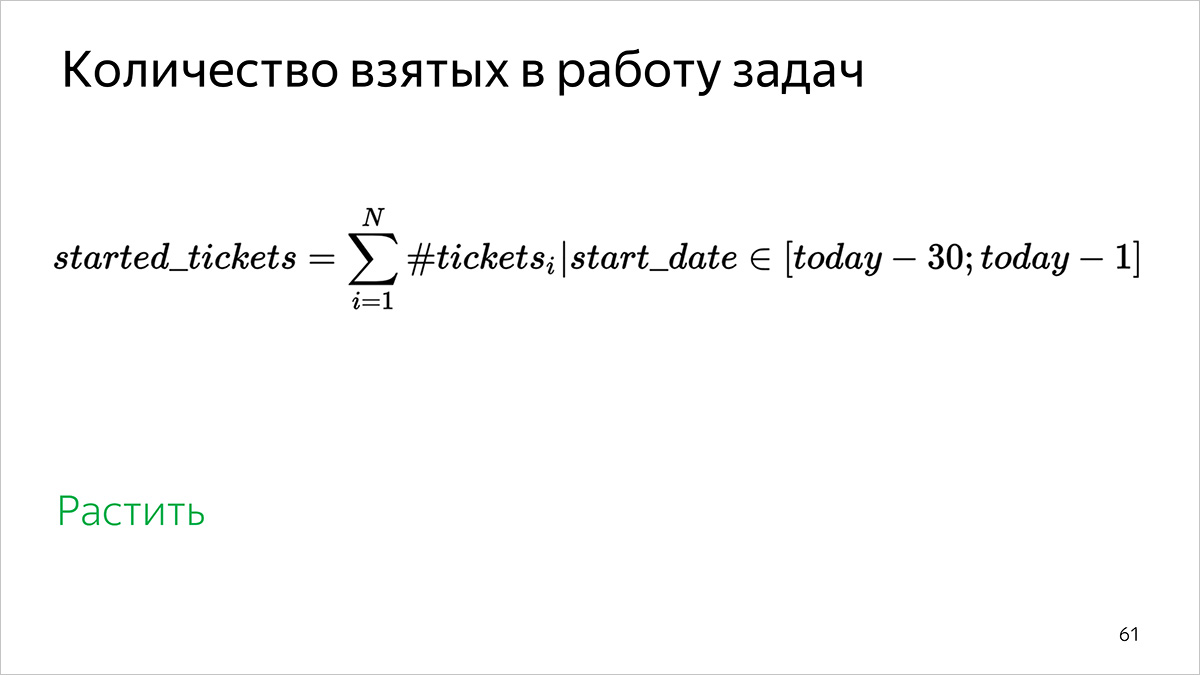
Como consideramos: de acuerdo con el número de tareas para las cuales el comienzo del trabajo se encuentra en el intervalo [hace 31 días; ayer]
El número de días antes de contratar

Como consideramos:
- Para cada tarea que se llevó a trabajar en el período de tiempo especificado (fecha de inicio en el Rastreador en el intervalo [hace 31 días; ayer]), consideramos el número de días completos transcurridos entre la declaración (fecha de creación del campo) y el inicio de la tarea (fecha de inicio del campo) .
- Resumimos todos los valores obtenidos en el primer paso.
- Dividimos la cantidad recibida por el número de tareas para las cuales hicimos el primer artículo.
Para los percentiles, se omite el elemento 3, los valores se ordenan en orden ascendente y se selecciona el valor que corresponde al percentil dado.
Número de días para completar
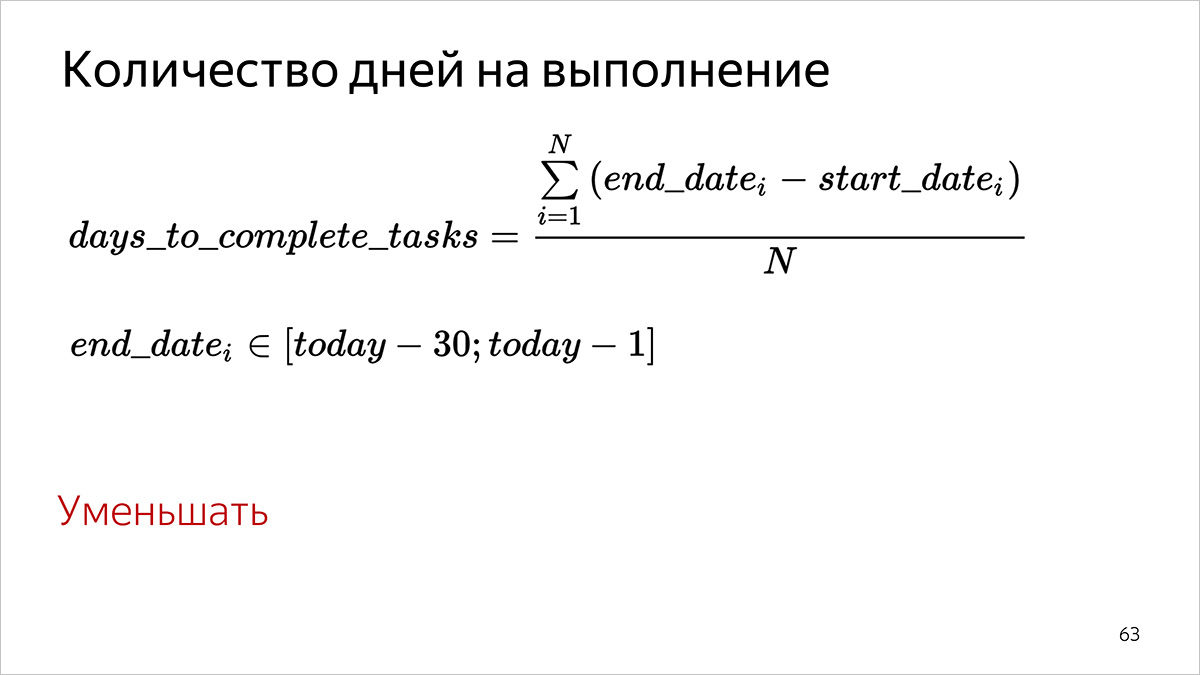
Como lo consideramos.
- Para cada tarea que se completó en el período de tiempo especificado (fecha de finalización en el Rastreador en el intervalo [hace 31 días; ayer]), consideramos el número de días completos transcurridos entre el inicio del trabajo (fecha de inicio del campo) y la tarea (fecha de finalización del campo).
- Resumimos todos los valores obtenidos en el primer paso.
- Dividimos la cantidad recibida por el número de tareas para las cuales hicimos el primer artículo.
Para los percentiles, se omite el elemento 3, los valores se ordenan en orden ascendente y se selecciona el valor que corresponde al percentil dado.
El número de tareas sin reacción más de 14 días.

Como creemos: por la cantidad de tareas en las que no pasó nada durante más de 14 días. Está determinado por el campo actualizado en el Rastreador: el valor del campo debe ser menor que "ayer - 14 días".
Deuda técnica

Como lo consideramos: por la cantidad de tareas para las cuales se establece el estado de Backlog en el Rastreador.
Implementación técnica de cálculo de métricas de desempeño
En el nivel superior, el sistema de conteo métrico consta de los siguientes componentes y enlaces de información.
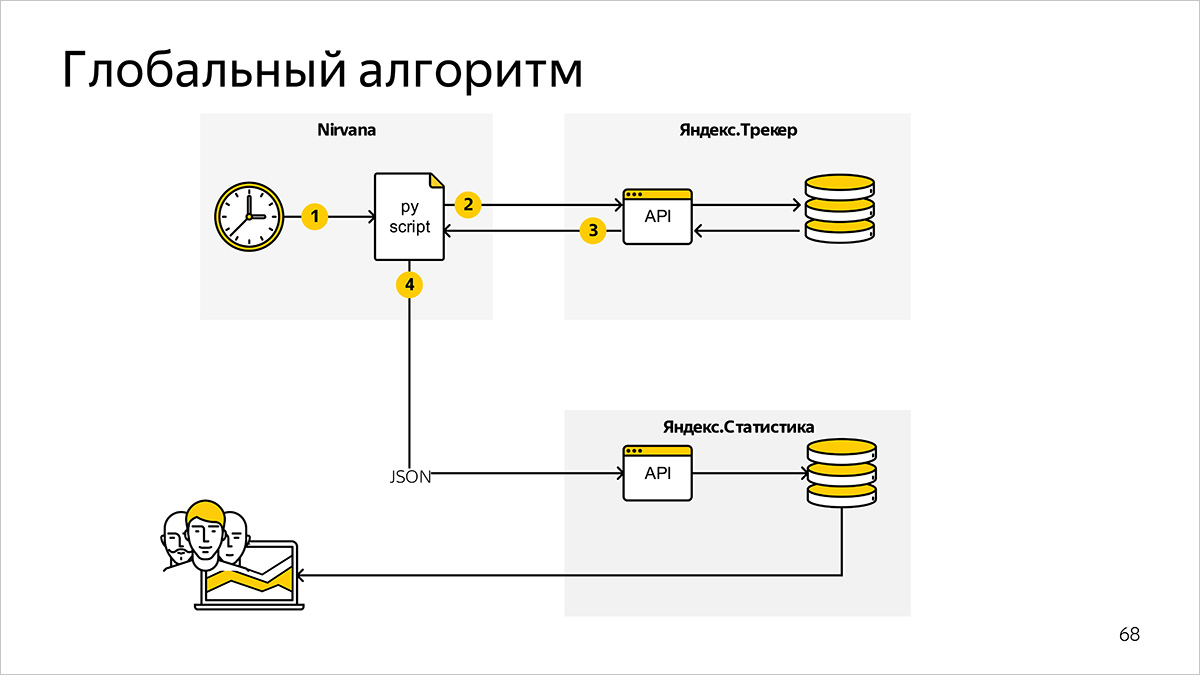
Programa de conteo métrico programado
Utilizamos Nirvana , una plataforma informática universal. Describe formalmente el orden en que se inician los procesos. Junto con el planificador interno (planificador) Nirvana nos reemplaza con un conjunto de scripts bash y cron.
Un programa escrito en Python se ejecuta regularmente y solicita los datos necesarios para calcular las métricas.
Sistema de configuración de tareas
Los datos para calcular las métricas en nuestro caso se almacenan en Yandex.Tracker. Como interfaz para los datos, utilizamos la API de Python Yandex.Tracker: este es un contenedor en la API HTTP, que permite recibir información de forma más rápida y fácil en estructuras de datos adecuadas para su posterior procesamiento.
Puede elegir un sistema conveniente con una API adecuada, por ejemplo, Jira.
Sistema de preparación de gráficos
Después de calcular las métricas basadas en los datos de Yandex.Tracker, nuestro programa genera archivos JSON y los transfiere al servicio interno Yandex.Statistics para dibujar gráficos.
Puede usar algún tipo de biblioteca JS que pueda construir gráficos. Una descripción general de algunas soluciones similares se encuentra en Habré:
15 mejores bibliotecas de JavaScript
En la siguiente parte, describiremos cómo consideramos las métricas de calidad de la documentación del usuario.