
tl; dr:
- El aprendizaje automático busca patrones en los datos. Pero la inteligencia artificial puede ser "sesgada", es decir, encontrar los patrones incorrectos. Por ejemplo, un sistema de detección de cáncer de piel a partir de fotografías puede prestar especial atención a las imágenes tomadas en el consultorio de un médico. El aprendizaje automático no sabe cómo hacerlo : sus algoritmos solo revelan patrones en números, y si los datos no son representativos, también lo será el resultado de su procesamiento. Y atrapar tales errores puede ser difícil debido a la mecánica del aprendizaje automático.
- El área problemática más obvia y aterradora es la diversidad humana. Hay muchas razones por las cuales los datos sobre las personas pueden perder su objetividad incluso en la etapa de recopilación. Pero no debe pensar que este problema solo afecta a las personas: surgen exactamente las mismas dificultades cuando se trata de encontrar una inundación en un almacén o una turbina de gas averiada. Algunos sistemas pueden tener sesgos con respecto al color de la piel, otros estarán sesgados contra los sensores de Siemens.
- Tales problemas no son nuevos para el aprendizaje automático, y están lejos de ser únicos para él. Se hacen suposiciones incorrectas en cualquier estructura compleja, y siempre es difícil entender por qué se tomó una decisión. Es necesario abordar esto de una manera compleja: crear herramientas y procesos para la verificación, y educar a los usuarios para que no sigan ciegamente las recomendaciones de la IA. El aprendizaje automático realmente hace algunas cosas mucho mejor que nosotros, pero los perros, por ejemplo, son mucho más efectivos que las personas para detectar drogas, lo que no es una razón para presentarlos como testigos y dictar oraciones basadas en sus testimonios. Y, por cierto, los perros son mucho más inteligentes que cualquier sistema de aprendizaje automático.
El aprendizaje automático hoy es una de las tendencias tecnológicas fundamentales más importantes. Esta es una de las principales formas en que la tecnología cambiará el mundo que nos rodea en la próxima década. Algunos aspectos de estos cambios son preocupantes. Por ejemplo, el impacto potencial del aprendizaje automático en el mercado laboral, o su uso con fines poco éticos (por ejemplo, regímenes autoritarios). Hay otro problema al que se dedica esta publicación: el sesgo de la inteligencia artificial .
Esta es una historia difícil.

Google AI puede encontrar gatos. Esta noticia de 2012 fue entonces algo especial.
¿Qué es el sesgo de IA?
"Datos en bruto" es tanto un oxímoron como una mala idea; Los datos deben prepararse bien y con cuidado. —Jeffrey Boker
En algún lugar antes de 2013, para crear un sistema que, por ejemplo, reconozca a los gatos en las fotografías, tenía que describir los pasos lógicos. Cómo encontrar esquinas en una imagen, reconocer ojos, analizar texturas para detectar la presencia de pieles, contar las patas, etc. Luego, reúna todos los componentes y descubra que todo esto realmente no funciona. Algo así como un caballo mecánico: en teoría se puede hacer, pero en la práctica es demasiado complicado de describir. A la salida tiene cientos (o incluso miles) de reglas escritas a mano. Y ni un solo modelo de trabajo.
Con el advenimiento del aprendizaje automático, dejamos de usar reglas "manuales" para reconocer un objeto. En cambio, tomamos mil muestras del "uno", X, mil muestras del "otro", Y, y forzamos a la computadora a construir un modelo basado en su análisis estadístico. Luego le damos a este modelo algunos datos de muestra, y determina con cierta precisión si se ajusta a uno de los conjuntos. El aprendizaje automático genera un modelo basado en datos, no con la ayuda de la persona que lo escribe. Los resultados son impresionantes, especialmente en el campo del reconocimiento de imágenes y patrones, y es por eso que toda la industria tecnológica ahora se está moviendo hacia el aprendizaje automático (ML).
Pero no tan simple. En el mundo real, sus miles de ejemplos de X o Y también contienen A, B, J, L, O, R e incluso L. Se pueden distribuir de manera desigual, y algunos de ellos se pueden encontrar con tanta frecuencia que el sistema les prestará más atención que a los objetos que te interesan.
¿Qué significa esto en la práctica? Mi ejemplo favorito es cuando los sistemas de reconocimiento de imágenes miran una colina cubierta de hierba y dicen "ovejas" . Es comprensible por qué: la mayoría de las fotos de ejemplo de las "ovejas" fueron tomadas en los prados donde viven, y en estas imágenes la hierba ocupa mucho más espacio que las pequeñas esponjas blancas, y es la hierba del sistema la que se considera más importante.
Hay ejemplos más serios. De reciente - un proyecto para detectar el cáncer de piel en fotografías. Resultó que los dermatólogos a menudo fotografían la alineación junto con las manifestaciones del cáncer de piel para fijar el tamaño de las formaciones. En ejemplos de fotografías de piel sana, no hay reglas. Para el sistema de IA, tales reglas (más precisamente, los píxeles que definimos como una "regla") se han convertido en una de las diferencias entre conjuntos de ejemplos, y a veces más importante que una pequeña erupción cutánea. Entonces, un sistema diseñado para identificar el cáncer de piel, a veces en lugar de reconocer la línea.
El punto clave aquí es que el sistema no tiene una comprensión semántica de lo que está mirando. Observamos un conjunto de píxeles y vemos una oveja, una piel o reglas en ellos, y el sistema, solo una línea numérica. Ella no ve el espacio tridimensional, no ve ni objetos, ni texturas, ni ovejas. Ella solo ve patrones en los datos.
La dificultad para diagnosticar tales problemas es que la red neuronal (el modelo generado por su sistema de aprendizaje automático) consta de miles de cientos de miles de nodos. No hay una manera fácil de mirar un modelo y ver cómo toma una decisión. La presencia de dicho método significaría que el proceso es lo suficientemente simple como para describir todas las reglas manualmente, sin utilizar el aprendizaje automático. A la gente le preocupa que el aprendizaje automático se haya convertido en una especie de caja negra. (Explicaré un poco más tarde por qué esta comparación sigue siendo demasiado).
En términos generales, este es el problema del sesgo de la inteligencia artificial o el aprendizaje automático: un sistema para encontrar patrones en los datos puede encontrar patrones incorrectos, pero es posible que no lo note. Esta es una característica fundamental de la tecnología, y es obvia para todos los que trabajan con ella en la comunidad científica y en las grandes empresas de tecnología. Pero sus consecuencias son complejas, y también lo son nuestras posibles soluciones a estas consecuencias.
Hablemos primero de las consecuencias.

La IA puede hacer una elección implícita a favor de ciertas categorías de personas, en función de una gran cantidad de señales discretas
Escenarios de sesgo de IA
Lo más obvio y aterrador es que este problema puede manifestarse cuando se trata de la diversidad humana. Recientemente , se ha corrido el rumor de que Amazon ha intentado construir un sistema de aprendizaje automático para la selección inicial de los candidatos para el trabajo. Como hay más hombres entre los trabajadores de Amazon, los ejemplos de "contratación exitosa" también son más frecuentes que los hombres, y hubo más hombres en la selección de currículums propuestos por el sistema. Amazon se dio cuenta de esto y no lanzó el sistema en producción.
Lo más importante en este ejemplo es que se rumorea que el sistema ha favorecido a los candidatos masculinos, a pesar de que el género no figuraba en el currículum. El sistema vio otros patrones en ejemplos de "contratación exitosa": por ejemplo, las mujeres pueden usar palabras especiales para describir logros o tener pasatiempos especiales. Por supuesto, el sistema no sabía qué era "hockey", ni quiénes son "personas", ni qué era "éxito"; simplemente realizó un análisis estadístico del texto. Pero los patrones que vio probablemente habrían pasado desapercibidos para la persona, y algunos de ellos (por ejemplo, el hecho de que personas de diferentes sexos describan el éxito de manera diferente), probablemente sería difícil para nosotros verlos, incluso mirarlos.
Más aún peor. Un sistema de aprendizaje automático que encuentra muy bien el cáncer en la piel pálida puede funcionar peor con la piel oscura, o viceversa. No necesariamente por sesgo, sino porque probablemente necesite construir un modelo separado para un color de piel diferente, eligiendo otras características. Los sistemas de aprendizaje automático no son intercambiables incluso en un campo tan estrecho como el reconocimiento de imágenes. Debe configurar el sistema, a veces simplemente mediante prueba y error, para notar bien las características de los datos que le interesan, hasta que alcance la precisión deseada. Pero es posible que no note que el sistema en el 98% de los casos es preciso cuando se trabaja con un grupo y solo en el 91% (aunque esto es más preciso que el análisis realizado por una persona) en el otro.
Hasta ahora, he usado principalmente ejemplos sobre las personas y sus características. La discusión sobre este problema se centra principalmente en este tema. Pero es importante entender que el sesgo hacia las personas es solo una parte del problema. Utilizaremos el aprendizaje automático para muchas cosas, y un error de muestreo será relevante para todas ellas. Por otro lado, si trabaja con personas, el sesgo de datos puede no estar relacionado con ellas.
Para comprender esto, volvamos al ejemplo del cáncer de piel y consideremos tres posibilidades hipotéticas de falla del sistema.
- Distribución no homogénea de personas: un número desequilibrado de fotografías de la piel en diferentes tonos, lo que conduce a resultados falsos positivos o falsos negativos asociados con la pigmentación.
- Los datos sobre los que se entrena el sistema contienen una característica de distribución frecuente y heterogénea que no está relacionada con las personas y que no tiene valor diagnóstico: una regla en fotografías de manifestaciones de cáncer de piel o hierba en fotografías de ovejas. En este caso, el resultado será diferente si el sistema encuentra píxeles en la imagen de algo que el ojo humano define como una "regla".
- Los datos contienen una característica de un tercero que una persona no puede ver, incluso si la busca.
¿Qué significa esto? Sabemos a priori que los datos pueden ser presentados de manera diferente por diferentes grupos de personas, y al menos podemos planear buscar tales excepciones. En otras palabras, hay muchas razones sociales para suponer que los datos sobre grupos de personas ya contienen algún sesgo. Si miramos la foto con la regla, veremos esta regla: simplemente la ignoramos antes, sabiendo que no importa y olvidando que el sistema no sabe nada.
Pero, ¿qué pasaría si todas sus fotografías de piel no saludable fueran tomadas en una oficina donde se usan bombillas incandescentes y sanas con luz fluorescente? ¿Qué pasa si, después de terminar de eliminar la piel sana, antes de disparar de manera no saludable, actualizaste el sistema operativo en el teléfono y Apple o Google cambiaron un poco el algoritmo de reducción de ruido? Una persona no puede notar esto, no importa cuánto busque tales características. Pero entonces el sistema de uso de la máquina lo verá y usará de inmediato. Ella no sabe nada.
Si bien hablamos de correlaciones falsas, puede suceder que los datos sean precisos y los resultados sean correctos, pero no desea utilizarlos por razones éticas, legales o administrativas. En algunas jurisdicciones, por ejemplo, no es posible ofrecer a las mujeres un descuento en el seguro, aunque las mujeres pueden estar más seguras al conducir. Podemos imaginar fácilmente un sistema que, al analizar datos históricos, asignará factores de menor riesgo a los nombres femeninos. Ok, eliminemos los nombres de la selección. Pero recuerde el ejemplo con Amazon: el sistema puede determinar el género por otros factores (aunque no sabe qué es el género y qué es una máquina), y no lo notará hasta que el regulador analice retroactivamente las tarifas que ofrece y no le cobre estas bien
Finalmente, a menudo se implica que usaremos tales sistemas solo para proyectos relacionados con las personas y las interacciones sociales. Esto no es asi. Si fabrica turbinas de gas, es probable que desee aplicar el aprendizaje automático a la telemetría transmitida por docenas o cientos de sensores en su producto (audio, video, temperatura y cualquier otro sensor que genere datos que puedan adaptarse fácilmente para crear un modelo de aprendizaje automático) ) Hipotéticamente, puede decir: “Aquí están los datos de mil turbinas averiadas obtenidas antes de su falla, pero aquí están los datos de mil turbinas que no se rompieron. Construya un modelo para decir cuál es la diferencia entre ellos ". Bueno, ahora imagine que los sensores de Siemens cuestan el 75% de las turbinas defectuosas y solo el 12% de las buenas (no hay conexión con fallas). El sistema construirá un modelo para localizar turbinas con sensores Siemens. ¡Uy!
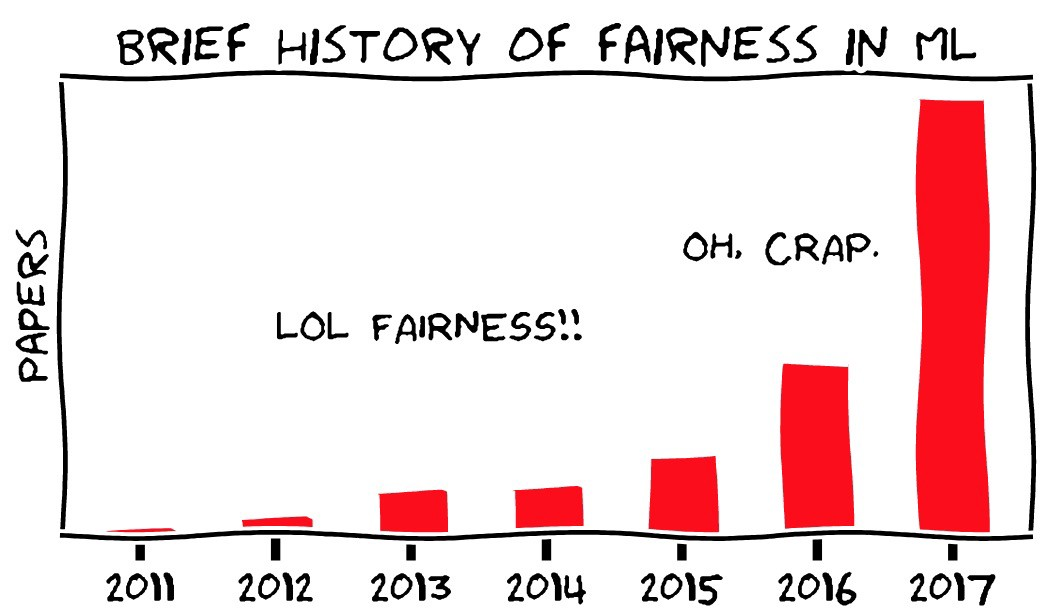
Foto - Moritz Hardt, UC Berkeley
Gestión de sesgos de IA
¿Qué podemos hacer al respecto? Puede abordar el problema desde tres lados:
- Rigidez metodológica en la recopilación y gestión de datos para la capacitación del sistema.
- Herramientas técnicas para analizar y diagnosticar el comportamiento del modelo.
- Capacitación, educación y precaución en la introducción del aprendizaje automático en los productos.
Hay una broma en el libro de Moliere "El comerciante en la nobleza": a un hombre le dijeron que la literatura está dividida en prosa y poesía, y admira con admiración que habló en prosa toda su vida sin saberlo. Probablemente, los estadísticos de alguna manera se sienten así hoy: sin darse cuenta, dedicaron sus carreras a la inteligencia artificial y al error de muestreo. Para buscar un error de muestreo y preocuparse por él no es un problema nuevo, solo necesitamos abordar sistemáticamente su solución. Como se mencionó anteriormente, en algunos casos es realmente más fácil hacerlo estudiando los problemas asociados con los datos de las personas. A priori suponemos que podemos tener ideas preconcebidas sobre diferentes grupos de personas, pero nos resulta difícil imaginar un prejuicio sobre los sensores de Siemens.
Lo nuevo en todo esto, por supuesto, es que las personas ya no participan directamente en el análisis estadístico. Lo llevan a cabo máquinas que crean grandes modelos complejos que son difíciles de entender. La cuestión de la transparencia es uno de los principales aspectos del problema de sesgo. Tememos que el sistema no solo esté sesgado, sino que no haya forma de detectar su sesgo, y que el aprendizaje automático sea diferente de otras formas de automatización, que se supone que consisten en pasos lógicos claros que se pueden verificar.
Hay dos problemas aquí. Sin embargo, quizás podamos realizar una auditoría de los sistemas de aprendizaje automático. Y la auditoría de cualquier otro sistema en realidad no es nada más fácil.
En primer lugar, una de las áreas de la investigación moderna en el campo del aprendizaje automático es la búsqueda de métodos sobre cómo identificar la funcionalidad importante de los sistemas de aprendizaje automático. Al mismo tiempo, el aprendizaje automático (en su estado actual) es un campo de ciencia completamente nuevo que está cambiando rápidamente, por lo que no debe pensar que las cosas imposibles hoy en día no pueden volverse muy reales. El proyecto OpenAI es un ejemplo interesante de esto.
En segundo lugar, la idea de que es posible verificar y comprender el proceso de toma de decisiones en los sistemas u organizaciones existentes es buena en teoría, pero más o menos en la práctica. Comprender cómo se toman las decisiones en una organización grande está lejos de ser fácil. Incluso si hay un proceso formal de toma de decisiones allí, no refleja cómo las personas realmente interactúan, y de hecho a menudo no tienen un enfoque lógico sistemático para tomar sus decisiones. Como dijo mi colega Vijay Pande , las personas también son cajas negras .
Tome mil personas en varias empresas e instituciones superpuestas, y el problema se volverá aún más complicado. Sabemos después del hecho de que el transbordador espacial estaba destinado a desmoronarse cuando regresaron, y algunas personas dentro de la NASA tenían información que les daba razones para pensar que algo malo podría pasar, pero el sistema en su conjunto no lo sabía. La NASA incluso acaba de pasar una auditoría similar, ya que perdió el transbordador anterior y, sin embargo, perdió otra, por una razón muy similar. Es fácil decir que las organizaciones y las personas siguen reglas lógicas claras que se pueden verificar, comprender y cambiar, pero la experiencia demuestra lo contrario. Este es el " error de la Comisión de Planificación del Estado ".
A menudo comparo el aprendizaje automático con las bases de datos, especialmente las relacionales, una nueva tecnología fundamental que ha cambiado las capacidades de la informática y el mundo que la rodea, que se ha convertido en parte de todo lo que usamos constantemente sin darnos cuenta. Las bases de datos también tienen problemas y tienen una propiedad similar: el sistema puede construirse sobre suposiciones incorrectas o sobre datos incorrectos, pero será difícil de notar y las personas que usan el sistema harán lo que les diga sin hacer preguntas. Hay un montón de viejos chistes sobre los trabajadores de impuestos que una vez deletrearon mal tu nombre, y convencerlos de que corrijan el error es mucho más difícil que cambiar el nombre. Esto puede pensarse de diferentes maneras, pero no está claro cuál es la mejor manera: ¿qué tal un problema técnico en SQL, o un error en el lanzamiento de Oracle, o sobre el fracaso de las instituciones burocráticas? ¿Qué tan difícil es encontrar un error en el proceso que condujo al hecho de que el sistema no tiene una característica como la corrección de errores tipográficos? ¿Podría entenderse esto antes de que la gente comenzara a quejarse?
Aún más fácil es este problema ilustrado por historias cuando los conductores, debido a datos obsoletos en el navegador, van a los ríos. Ok, los mapas deben actualizarse constantemente. Pero, ¿de cuánto es la culpa de TomTom por el hecho de que su automóvil vuela al mar?
Digo esto al hecho de que sí, el sesgo del aprendizaje automático creará problemas. Pero estos problemas serán similares a los que encontramos en el pasado, y pueden notarse y resolverse (o no) aproximadamente tan bien como lo hicimos en el pasado. En consecuencia, es improbable que un escenario en el que el sesgo de IA sea perjudicial para los principales investigadores que trabajan en una gran organización. , - - , , . “ ” , , , , . . , . .
Conclusión
, , — , .
, « » . , — . HAL9000 Skynet — -, . Pero no , , , . , , … . . , , , - . , — , , .
, — , — . , , .
, , « — , » . , « ». , , , . , . , — , , , . , , .
Traducción: Diana Letskaya .
Edición: Alexey Ivanov .
Comunidad: @PonchikNews .