Hola Mi nombre es Ibadov Ilkin, soy estudiante de la Universidad Federal de los Urales.
En este artículo quiero hablar sobre mi experiencia con la solución automatizada para el captcha de Google: "reCAPTCHA". Me gustaría advertir al lector de antemano que al momento de escribir el artículo, el prototipo no funciona tan eficientemente como podría parecer desde el título, sin embargo, el resultado demuestra que el enfoque implementado es capaz de resolver el problema.
Probablemente todos en su vida se hayan encontrado con un captcha: ingrese el texto de una imagen, resuelva una expresión simple o una ecuación compleja, elija automóviles, hidrantes, cruces peatonales ... Es necesario proteger los recursos de los sistemas automatizados y desempeña un papel importante en la seguridad: el captcha protege contra los ataques DDoS , registros y publicaciones automáticas, análisis, evita la selección de spam y contraseña para las cuentas.
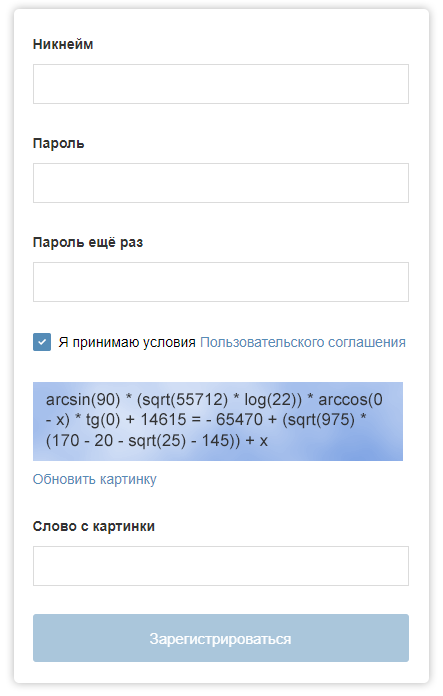 El formulario de registro en "Habré" podría estar con tal captcha.
El formulario de registro en "Habré" podría estar con tal captcha.Con el desarrollo de tecnologías de aprendizaje automático, el rendimiento de captcha puede estar en riesgo. En este artículo, describo los puntos clave de un programa que puede resolver el problema de seleccionar manualmente las imágenes en Google reCAPTCHA (afortunadamente, no siempre hasta ahora).
Para atravesar captcha, es necesario resolver problemas tales como: determinar la clase de captcha requerida, detectar y clasificar objetos, detectar celdas de captcha, simular actividades humanas para resolver captcha (movimiento del cursor, clic).
Para buscar objetos en una imagen, se utilizan redes neuronales entrenadas que se pueden descargar a una computadora y reconocer objetos en imágenes o videos. Pero para resolver el captcha, simplemente detectar objetos no es suficiente: debe determinar la posición de las celdas y descubrir qué celdas desea seleccionar (o no seleccionar celdas en absoluto). Para esto, se utilizan herramientas de visión por computadora: en este trabajo, esta es la famosa
biblioteca OpenCV .
Para encontrar objetos en la imagen, en primer lugar, se requiere la imagen misma. Obtengo una captura de pantalla de una parte de la pantalla usando el módulo
PyAutoGUI con dimensiones suficientes para detectar objetos. En el resto de la pantalla, visualizo ventanas para depurar y monitorear los procesos del programa.
Detección de objetos
La detección y clasificación de objetos es lo que hace la red neuronal. La biblioteca que nos permite trabajar con redes neuronales se llama "
Tensorflow " (desarrollado por Google). Hoy en día,
hay muchos modelos entrenados diferentes para su elección
en diferentes datos , lo que significa que todos pueden devolver un resultado de detección diferente: algunos modelos detectarán mejor los objetos y otros peores.
En este documento, estoy usando el modelo ssd_mobilenet_v1_coco. El modelo seleccionado fue entrenado en el conjunto de datos
COCO , que destaca 90 clases diferentes (desde personas y automóviles hasta cepillos de dientes y peines). Ahora hay otros modelos que se entrenan con los mismos datos, pero con diferentes parámetros. Además, este modelo tiene parámetros óptimos de rendimiento y precisión, lo cual es importante para una computadora de escritorio. La fuente dice que el tiempo de procesamiento para un cuadro de 300 x 300 píxeles es de 30 milisegundos. En el "Nvidia GeForce GTX TITAN X".
El resultado de la red neuronal es un conjunto de matrices:
- con una lista de clases de objetos detectados (sus identificadores);
- con una lista de clasificaciones de objetos detectados (en porcentaje);
- con una lista de coordenadas de objetos detectados ("cajas").
Los índices de los elementos en estos conjuntos se corresponden entre sí, es decir: el tercer elemento en el conjunto de clases de objetos corresponde al tercer elemento en el conjunto de "cajas" de los objetos detectados y el tercer elemento en el conjunto de clasificaciones de objetos.
 El modelo seleccionado le permite detectar objetos de 90 clases en tiempo real.
El modelo seleccionado le permite detectar objetos de 90 clases en tiempo real.Detección celular
"OpenCV" nos brinda la capacidad de operar con entidades llamadas "
circuitos ": Solo pueden ser detectados por la función "findContours ()" de la biblioteca "OpenCV". Es necesario enviar una imagen binaria a la entrada de dicha función, que puede obtenerse
mediante la función de transformación de umbral :
_retval, binImage = cv2.threshold(image,254,255,cv2.THRESH_BINARY) contours = cv2.findContours(binImage, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
Una vez establecidos los valores extremos de los parámetros de la función de transformación de umbral, también eliminamos varios tipos de ruido. Además, para minimizar la cantidad de elementos pequeños innecesarios y ruido, se pueden aplicar
transformaciones morfológicas : funciones de erosión (compresión) y acumulación (expansión). Estas funciones también son parte de OpenCV. Después de las transformaciones, se seleccionan los contornos cuyo número de vértices es cuatro (habiendo realizado previamente la función de
aproximación en los contornos).
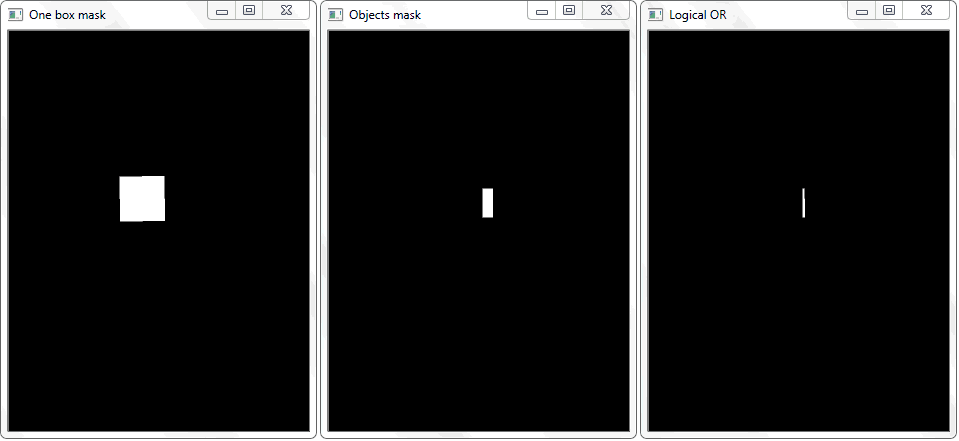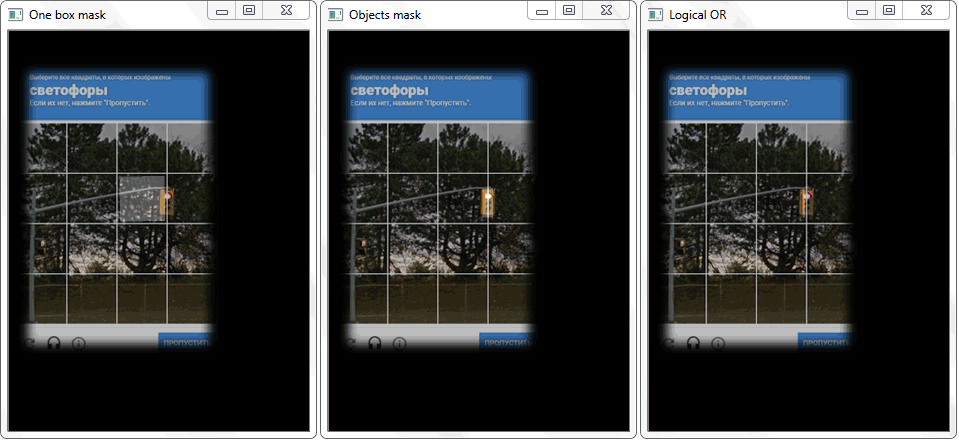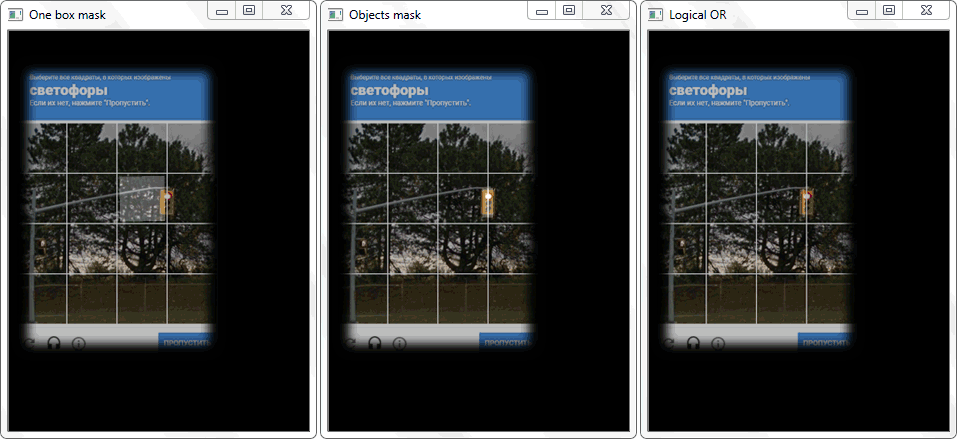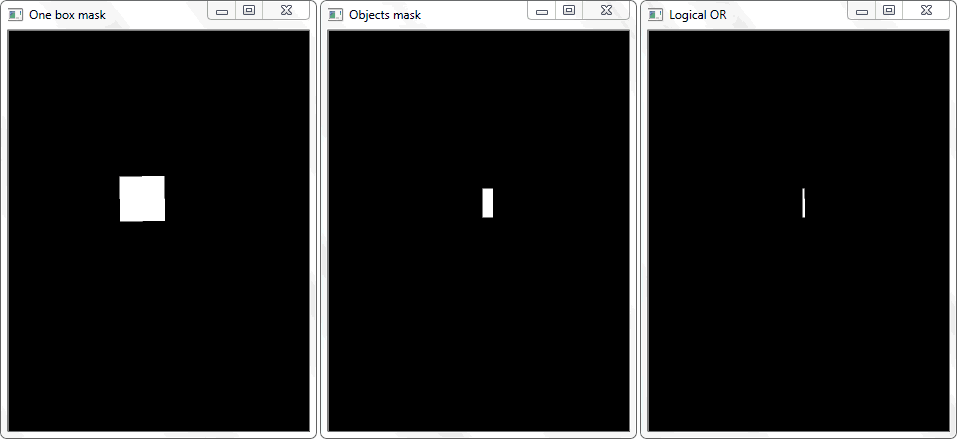
 En la primera ventana, el resultado de la transformación del umbral. El segundo es un ejemplo de transformación morfológica. En la tercera ventana, las celdas y la tapa de captcha ya están seleccionadas: resaltadas en color mediante programación.
En la primera ventana, el resultado de la transformación del umbral. El segundo es un ejemplo de transformación morfológica. En la tercera ventana, las celdas y la tapa de captcha ya están seleccionadas: resaltadas en color mediante programación.Después de todas las transformaciones, los contornos que no son celdas todavía caen en la matriz final con celdas. Para filtrar ruidos innecesarios, selecciono de acuerdo con los valores de la longitud (perímetro) y el área de los contornos.
Se reveló experimentalmente que los valores de los circuitos de interés se encuentran en el rango de 360 a 900 unidades. Este valor se selecciona en la pantalla con una diagonal de 15,6 pulgadas y una resolución de 1366 x 768 píxeles. Además, los valores indicados de los contornos se pueden calcular según el tamaño de la pantalla del usuario, pero no existe dicho enlace en el prototipo que se está creando.
La principal ventaja del enfoque elegido para detectar celdas es que no nos importa cómo se verá la cuadrícula y cuántas celdas se mostrarán en la página de captcha: 8, 9 o 16.
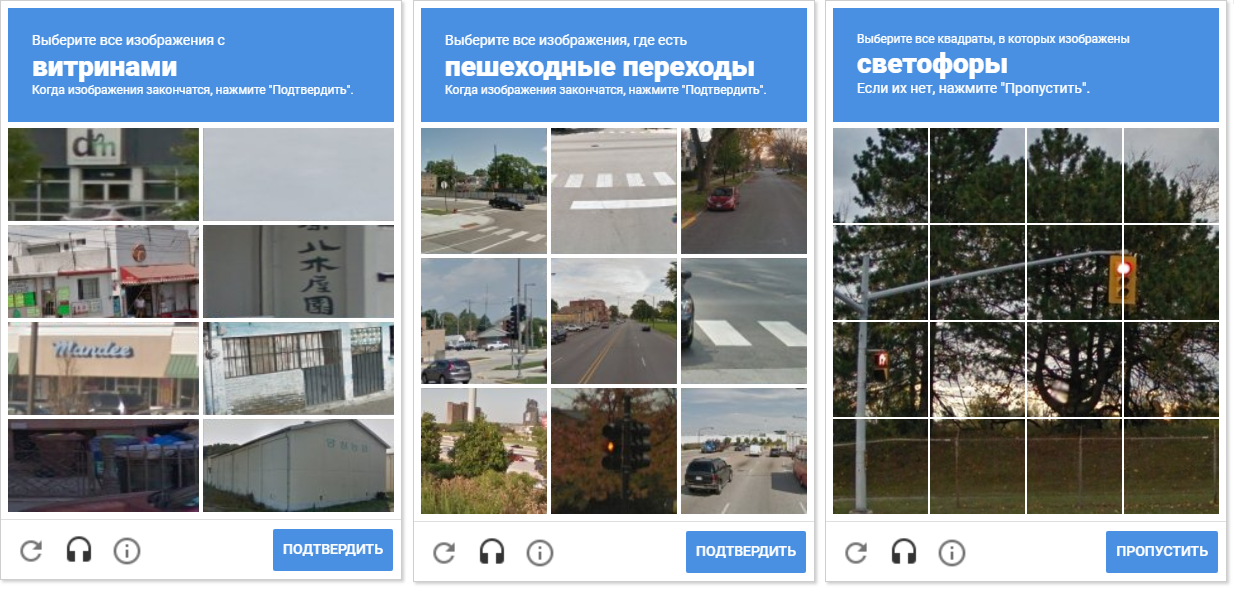 La imagen muestra una variedad de redes de captcha. Tenga en cuenta que la distancia entre las celdas es diferente. Separar las células entre sí permite la compresión morfológica.
La imagen muestra una variedad de redes de captcha. Tenga en cuenta que la distancia entre las celdas es diferente. Separar las células entre sí permite la compresión morfológica.Una ventaja adicional de detectar contornos es que OpenCV nos permite detectar sus centros (los necesitamos para determinar las coordenadas de movimiento y el clic del mouse).
Seleccionar celdas para seleccionar
Con una matriz con contornos limpios de celdas CAPTCHA sin circuitos de ruido innecesarios, podemos recorrer cada celda CAPTCHA ("circuito" en la terminología "OpenCV") y verificar el hecho de que se cruza con la "caja" detectada del objeto recibido de la red neuronal.
Para establecer este hecho, se utilizó la transferencia de la "caja" detectada a un circuito similar a las células. Pero este enfoque resultó ser incorrecto, porque el caso cuando el objeto se encuentra dentro de la celda no se considera una intersección. Naturalmente, tales células no se destacaron en el captcha.
El problema se resolvió redibujando el contorno de cada celda (con relleno blanco) en una hoja negra. De manera similar, se obtuvo una imagen binaria de un marco con un objeto. Surge la pregunta: ¿cómo establecer ahora el hecho de la intersección de la celda con el marco sombreado del objeto? En cada iteración de una matriz con celdas, se realiza una operación de disyunción (lógica o) en dos imágenes binarias. Como resultado, obtenemos una nueva imagen binaria en la que se resaltarán las áreas intersectadas. Es decir, si hay tales áreas, entonces la celda y el marco del objeto se cruzan. Programáticamente, tal verificación se puede hacer usando el
método "
.any () ": devolverá "Verdadero" si la matriz tiene al menos un elemento igual a uno o "Falso" si no hay unidades.
 La función "any ()" para la imagen "OR lógico" en este caso devolverá verdadero y establecerá así el hecho de la intersección de la celda con el área del marco del objeto detectado.
La función "any ()" para la imagen "OR lógico" en este caso devolverá verdadero y establecerá así el hecho de la intersección de la celda con el área del marco del objeto detectado.Gestión
El control del cursor en "Python" está disponible gracias al módulo "win32api" (sin embargo, más tarde resultó que el "PyAutoGUI" ya importado en el proyecto también sabe cómo hacerlo). Al presionar y soltar el botón izquierdo del mouse, así como al mover el cursor a las coordenadas deseadas, se realizan las funciones correspondientes del módulo win32api. Pero en el prototipo, estaban envueltos en funciones definidas por el usuario para proporcionar una observación visual del movimiento del cursor. Esto afecta negativamente el rendimiento y se implementó únicamente para demostración.
Durante el proceso de desarrollo, surgió la idea de elegir celdas en un orden aleatorio. Es posible que esto no tenga sentido práctico (por razones obvias, Google no nos da comentarios y descripciones de los mecanismos de operación de captcha), pero mover el cursor a través de las celdas de una manera caótica parece más divertido.
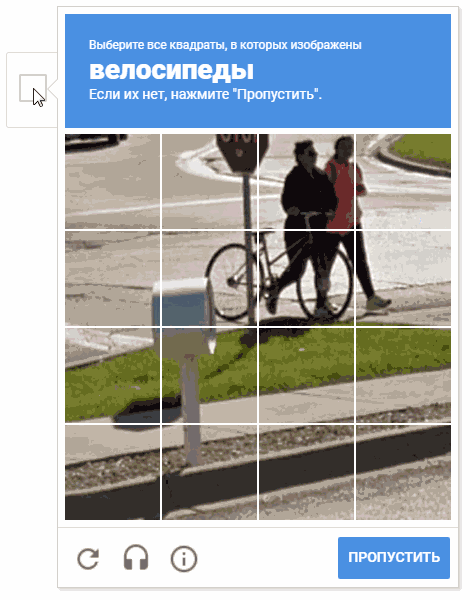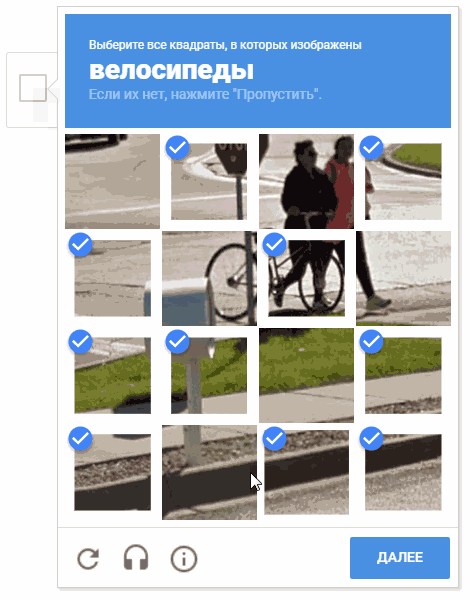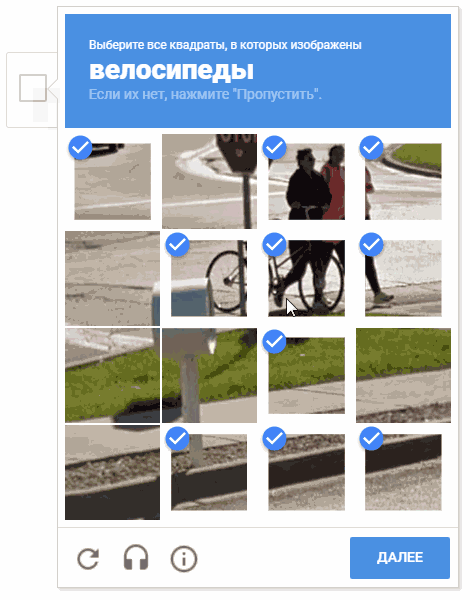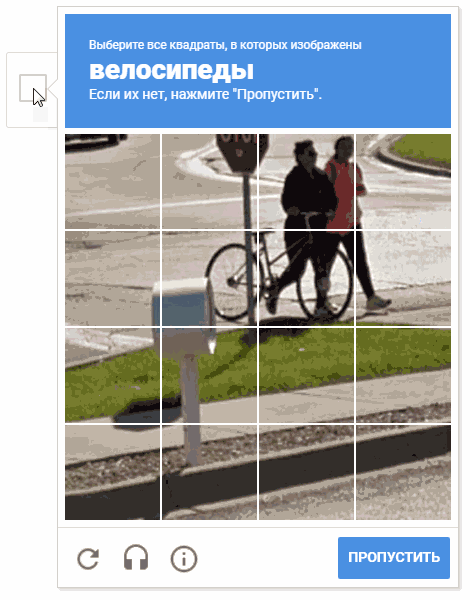 En la animación, el resultado es "random.shuffle (boxesForSelect)".
En la animación, el resultado es "random.shuffle (boxesForSelect)".Reconocimiento de texto
Para combinar todos los desarrollos disponibles en un solo conjunto, se requiere un enlace más: una unidad de reconocimiento para la clase requerida del captcha. Ya sabemos cómo reconocer y distinguir diferentes objetos en la imagen, podemos hacer clic en celdas arbitrarias de captcha, pero no sabemos en qué celdas hacer clic. Una de las formas de resolver este problema es reconocer el texto del encabezado captcha. En primer lugar, intenté implementar el reconocimiento de texto utilizando la herramienta de reconocimiento óptico de caracteres "
Tesseract-OCR ".
En las últimas versiones, es posible instalar paquetes de idiomas directamente en la ventana del instalador (anteriormente esto se hacía manualmente). Después de instalar e importar Tesseract-OCR en mi proyecto, traté de reconocer el texto del encabezado captcha.
El resultado, desafortunadamente, no me impresionó en absoluto. Decidí que el texto en el encabezado se resaltaba en negrita y se fusionaba por una razón, así que traté de aplicar varias transformaciones a la imagen: operaciones de binarización, estrechamiento, expansión, desenfoque, distorsión y cambio de tamaño. Desafortunadamente, esto no dio un buen resultado: en el mejor de los casos, solo se determinó una parte de las letras de la clase, y cuando el resultado fue satisfactorio, apliqué las mismas transformaciones, pero para otras mayúsculas (con texto diferente), y el resultado resultó ser malo nuevamente.
 El reconocimiento de los límites de Tesseract-OCR generalmente condujo a resultados insatisfactorios.
El reconocimiento de los límites de Tesseract-OCR generalmente condujo a resultados insatisfactorios.Es imposible decir inequívocamente que "Tesseract-OCR" no reconoce bien el texto, esto no es así: la herramienta hace frente a otras imágenes (no captcha caps) mucho mejor.
Decidí utilizar un servicio de terceros que ofrecía una API para trabajar con él de forma gratuita (se requiere el registro y la recepción de una clave para una dirección de correo electrónico). El servicio tiene un límite de 500 reconocimientos por día, pero durante todo el período de desarrollo no he encontrado ningún problema con limitaciones. Por el contrario: envié la imagen original del encabezado al servicio (sin aplicar absolutamente ninguna transformación) y el resultado me impresionó gratamente.
Las palabras del servicio se devolvieron prácticamente sin errores (por lo general, incluso las escritas en letra pequeña). Además, regresaron en un formato muy conveniente, dividido por línea con caracteres de salto de línea. En todas las imágenes, solo estaba interesado en la segunda línea, así que accedí directamente a ella. Esto no podía sino alegrarme, ya que ese formato me liberó de la necesidad de preparar una línea: no tuve que cortar el principio o el final de todo el texto, hacer "recortes", reemplazos, trabajar con expresiones regulares y realizar otras operaciones en la línea, con el objetivo de resaltar una palabra (¡y a veces dos!): ¡un buen bono!
text = serviceResponse['ParsedResults'][0]['ParsedText']
Un servicio que reconoció texto casi nunca cometió un error con el nombre de la clase, pero aun así decidí dejar parte del nombre de la clase para un posible error. Esto es opcional, pero noté que "Tesseract-OCR" en algunos casos reconoció incorrectamente el final de una palabra que comienza desde el medio. Además, este enfoque elimina el error de la aplicación en el caso de un nombre de clase largo o un nombre de dos palabras (en este caso, el servicio no devolverá 3, sino 4 líneas, y no puedo encontrar el nombre completo de la clase en la segunda línea).
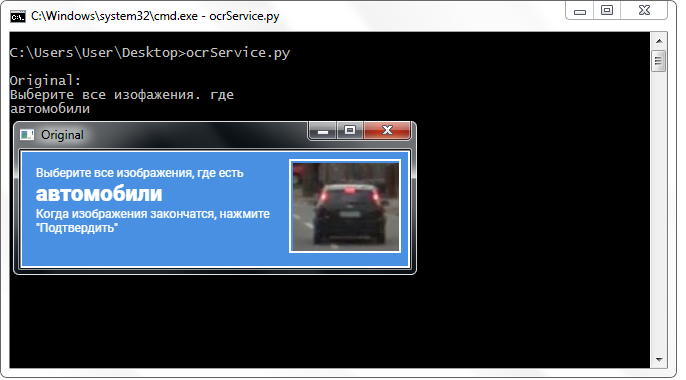 Un servicio de terceros reconoce bien el nombre de la clase sin ninguna transformación sobre la imagen.
Un servicio de terceros reconoce bien el nombre de la clase sin ninguna transformación sobre la imagen.Fusión
Obtener texto del encabezado no es suficiente. Debe compararse con los identificadores de las clases de modelos disponibles, porque en la matriz de clases la red neuronal devuelve exactamente el identificador de clase, y no su nombre, como puede parecer. Al entrenar el modelo, como regla, se crea un archivo en el que se comparan los nombres de clase y sus identificadores (también conocido como "mapa de etiquetas"). Decidí hacerlo más fácil y especificar los identificadores de clase manualmente, ya que captcha todavía requiere clases en ruso (por cierto, esto se puede cambiar):
if "" in query:
Todo lo descrito anteriormente se reproduce en el ciclo principal del programa: se determinan los marcos del objeto, la celda, sus intersecciones, el cursor se mueve y hace clic. Cuando se detecta un encabezado, se realiza el reconocimiento de texto. Si la red neuronal no puede detectar la clase requerida, se realiza un desplazamiento arbitrario de la imagen hasta 5 veces (es decir, se cambia la entrada a la red neuronal), y si la detección aún no ocurre, entonces se hace clic en el botón "Saltar / Confirmar" (su posición se detecta de manera similar detectar células y tapas).
Si a menudo resuelve el captcha, puede observar la imagen cuando la celda seleccionada desaparece, y una nueva aparece lenta y lentamente en su lugar. Dado que el prototipo está programado para ir instantáneamente a la página siguiente después de seleccionar todas las celdas, decidí hacer pausas de 3 segundos para excluir hacer clic en el botón "Siguiente" sin detectar objetos en la celda que aparece lentamente.
El artículo no estaría completo si no contuviera una descripción de lo más importante: una marca de verificación para pasar con éxito el captcha. Decidí que una simple
comparación de plantillas podría hacer esto. Vale la pena señalar que la coincidencia de patrones está lejos de ser la mejor manera de detectar objetos. Por ejemplo, tuve que establecer la sensibilidad de detección en "0.01" para que la función dejara de ver ticks en todo, pero lo vi cuando realmente hay un tick. Del mismo modo, actué con una casilla de verificación vacía que cumple con el usuario y desde la cual se inicia el captcha (no hubo problemas de sensibilidad).
Resultado
El resultado de todas las acciones descritas fue una aplicación, cuyo rendimiento probé en el "
Tostador ":
Vale la pena reconocer que el video no se filmó en el primer intento, ya que a menudo me enfrento a la necesidad de elegir clases que no estén en el modelo (por ejemplo, pasos de peatones, escaleras o escaparates).
"Google reCAPTCHA" devuelve un cierto valor al sitio, mostrando cómo "Usted es un robot", y los administradores del sitio, a su vez, pueden establecer un umbral para pasar este valor. Es posible que se haya establecido un umbral de captcha relativamente bajo en el tostador. Esto explica el paso bastante fácil del captcha por el programa, a pesar del hecho de que se equivocó dos veces, al no ver el semáforo de la primera página y la boca de incendios de la cuarta página del captcha.
Además de la Tostadora, se realizaron experimentos en la
página de demostración oficial de
reCAPTCHA . Como resultado, se notó que después de múltiples detecciones erróneas (y no detecciones), obtener un captcha se vuelve extremadamente difícil incluso para una persona: se requieren nuevas clases (como tractores y palmeras), las células sin objetos aparecen en las muestras (colores casi monótonos) y el número de páginas aumenta dramáticamente, para pasar
Esto fue especialmente notable cuando decidí intentar hacer clic en celdas aleatorias en caso de no detección de objetos (debido a su ausencia en el modelo). Por lo tanto, podemos decir con certeza que los clics aleatorios no conducirán a una solución al problema. Para deshacernos de tal "bloqueo" por parte del examinador, volvimos a conectar la conexión a Internet y borramos los datos del navegador, porque se hizo imposible pasar esa prueba, ¡era casi interminable!
 Si dudas de tu humanidad, tal resultado es posible.
Si dudas de tu humanidad, tal resultado es posible.Desarrollo
Si el artículo y la aplicación despiertan el interés del lector, con mucho gusto continuaré su implementación, pruebas y la descripción adicional en forma más detallada.
Se trata de encontrar clases que no sean parte de la red actual, esto mejorará en gran medida la eficiencia de la aplicación. En este momento, existe una necesidad urgente de reconocer al menos clases tales como: pasos de peatones, escaparates y chimeneas. Te diré cómo volver a entrenar al modelo. Durante el desarrollo, hice una breve lista de las clases más comunes:
- pasos de peatones;
- bocas de incendio;
- escaparates
- chimeneas
- carros
- Autobuses
- semáforos;
- bicicletas
- medios de transporte;
- escaleras
- signos
Se puede mejorar la calidad de la detección de objetos mediante el uso de varios modelos al mismo tiempo: esto puede degradar el rendimiento, pero aumentar la precisión.
Otra forma de mejorar la calidad de detección de objetos es cambiar la entrada de imagen a la red neuronal: en el video, puede ver que cuando no se detectan objetos, realizo un cambio de imagen arbitrario varias veces (dentro de 10 píxeles horizontal y verticalmente), y a menudo esta operación le permite ver objetos que anteriormente estaban No fueron detectados.
Un aumento en la imagen de un cuadrado pequeño a uno grande (hasta 300 x 300 píxeles) también conduce a la detección de objetos no detectados.
 No se encontraron objetos a la izquierda: cuadrado original con 100 píxeles de lado. A la derecha, se detecta un bus: un cuadrado ampliado de hasta 300 x 300 píxeles.
No se encontraron objetos a la izquierda: cuadrado original con 100 píxeles de lado. A la derecha, se detecta un bus: un cuadrado ampliado de hasta 300 x 300 píxeles.Otra transformación interesante es la eliminación de la cuadrícula blanca sobre la imagen usando las herramientas de OpenCV: es posible que la boca de incendios no se haya detectado en el video por este motivo (esta clase está presente en la red neuronal).
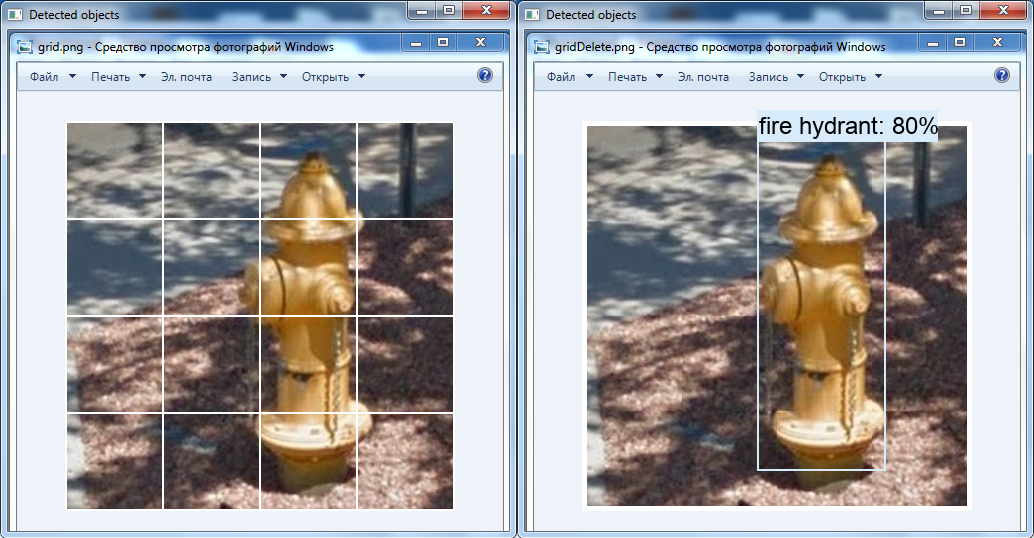 A la izquierda está la imagen original, y a la derecha está la imagen que se modificó en el editor de gráficos: la cuadrícula se elimina, las celdas se mueven entre sí.
A la izquierda está la imagen original, y a la derecha está la imagen que se modificó en el editor de gráficos: la cuadrícula se elimina, las celdas se mueven entre sí.Resumen
Con este artículo, quería decirle que el captcha probablemente no sea la mejor protección contra los bots, y es muy posible que en el futuro cercano se necesiten nuevos medios de protección contra los sistemas automatizados.
El prototipo desarrollado, incluso estando en un estado inacabado, demuestra que con las clases requeridas en el modelo de red neuronal y aplicando transformaciones sobre las imágenes, es posible lograr la automatización de un proceso que no debe automatizarse.
Además, me gustaría llamar la atención de Google sobre el hecho de que, además del método para eludir el captcha descrito en este artículo, también hay
otra forma de transcribir una muestra de audio. En mi opinión, ahora es necesario tomar medidas relacionadas con la mejora de la calidad de los productos de software y algoritmos contra robots.
Por el contenido y la esencia del material, puede parecer que no me gusta Google y, en particular, reCAPTCHA, pero esto está lejos de ser el caso, y si hay una próxima implementación, le diré por qué.
Desarrollado y demostrado para mejorar la educación y mejorar los métodos destinados a garantizar la seguridad de la información.
Gracias por su atencion