La historia de VKontakte está en Wikipedia, según contó el propio Pavel. Parece que todos ya la conocen. Pavel
habló sobre el interior, la arquitectura y el diseño del sitio en HighLoad ++
en 2010 . Desde entonces, se han filtrado muchos servidores, por lo que actualizaremos la información: diseccionamos, sacamos el interior, pesamos: observamos el dispositivo VK desde un punto de vista técnico.
 Alexey Akulovich
Alexey Akulovich (
AterCattus ) es un desarrollador de back-end en el equipo de VKontakte. La transcripción de este informe es una respuesta colectiva a las preguntas frecuentes sobre el funcionamiento de la plataforma, la infraestructura, los servidores y la interacción entre ellos, pero no sobre el desarrollo, es decir,
sobre el hardware . Por separado: sobre las bases de datos y lo que VK tiene en su lugar, sobre la recopilación de registros y el seguimiento de todo el proyecto en su conjunto. Detalles debajo del corte.
Durante más de cuatro años he estado haciendo todo tipo de tareas relacionadas con el backend.
- Descarga, almacenamiento, procesamiento, distribución de medios: video, transmisión en vivo, audio, fotos, documentos.
- Infraestructura, plataforma, monitoreo de desarrolladores, registros, cachés regionales, CDN, protocolo RPC patentado.
- Integración con servicios externos: envío de correos, análisis de enlaces externos, fuente RSS.
- Ayuda a tus colegas en varios temas, para las respuestas a las que tienes que sumergirte en un código desconocido.
Durante este tiempo, participé en muchos componentes del sitio. Quiero compartir esta experiencia
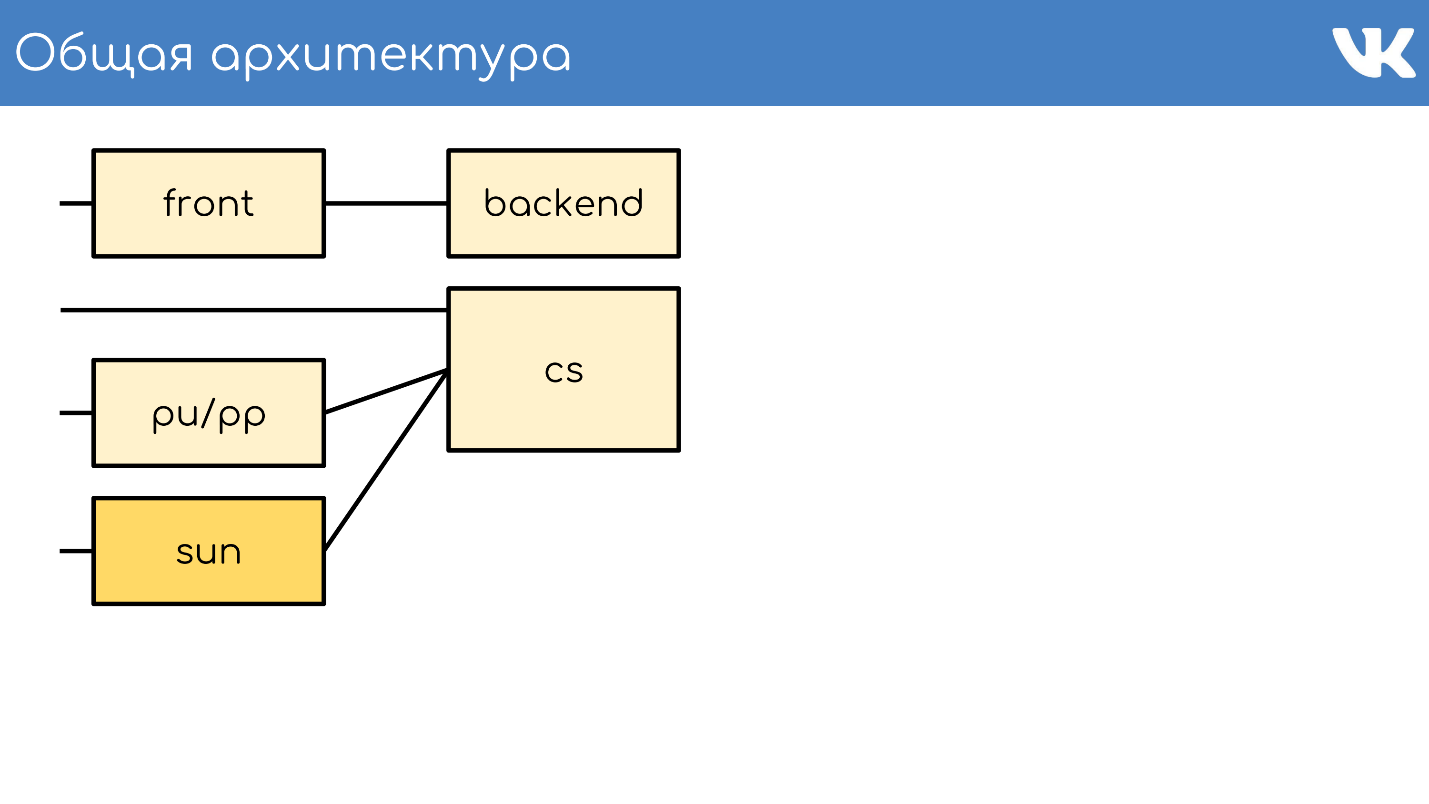
Arquitectura general
Todo, como de costumbre, comienza con un servidor o un grupo de servidores que aceptan solicitudes.
Servidor frontal
El servidor frontal acepta solicitudes a través de HTTPS, RTMP y WSS.
HTTPS son solicitudes de las versiones web principal y móvil del sitio: vk.com y m.vk.com, y otros clientes oficiales y no oficiales de nuestra API: clientes móviles, mensajería instantánea. Tenemos una recepción de tráfico
RTMP para transmisiones en vivo con servidores frontales separados y conexiones
WSS para Streaming API.
Para HTTPS y WSS,
nginx está instalado en los servidores. Para las transmisiones RTMP, recientemente cambiamos a nuestra propia solución
kive , pero está más allá del alcance del informe. Para la tolerancia a fallas, estos servidores anuncian direcciones IP compartidas y actúan como grupos para que, en caso de problemas en uno de los servidores, no se pierdan las solicitudes de los usuarios. Para HTTPS y WSS, estos mismos servidores encriptan el tráfico para tomar parte de la carga de la CPU en sí mismos.
Además, no hablaremos sobre WSS y RTMP, sino solo sobre solicitudes HTTPS estándar, que generalmente están asociadas con un proyecto web.
Backend
Detrás del frente suelen estar los servidores de fondo. Manejan las solicitudes que el servidor frontal recibe de los clientes.
Estos son
servidores kPHP que ejecutan el demonio HTTP porque HTTPS ya está descifrado. kPHP es un servidor que funciona de acuerdo con el
modelo prefork : inicia el proceso maestro, un grupo de procesos secundarios, les pasa sockets de escucha y procesan sus solicitudes. Al mismo tiempo, los procesos no se reinician entre cada solicitud del usuario, sino que simplemente restablecen su estado al estado inicial de valor cero: solicitud por solicitud, en lugar de reiniciar.
Compartir la carga
Todos nuestros backends no son un gran grupo de máquinas que pueden manejar cualquier solicitud. Los
dividimos en grupos separados : general, móvil, api, video, puesta en escena ... El problema en un grupo separado de máquinas no afectará a todos los demás. En caso de problemas con el video, el usuario que está escuchando música ni siquiera sabe acerca de los problemas. A qué backend enviar la solicitud se resuelve nginx en la parte delantera de la configuración.
Recolección de métricas y reequilibrio
Para comprender cuántos automóviles necesita en cada grupo,
no confiamos en QPS . Los backends son diferentes, tienen solicitudes diferentes, cada solicitud tiene una complejidad de cálculo QPS diferente. Por lo tanto, utilizamos el
concepto de carga en el servidor como un todo, en la CPU y el rendimiento .
Tenemos miles de tales servidores. El grupo kPHP se ejecuta en cada servidor físico para utilizar todos los núcleos (porque kPHP es de un solo subproceso).
Servidor de contenido
CS o Content Server es almacenamiento . CS es un servidor que almacena archivos y también procesa archivos cargados, todo tipo de tareas en segundo plano sincrónicas que la interfaz web principal le plantea.
Tenemos decenas de miles de servidores físicos que almacenan archivos. A los usuarios les encanta subir archivos, y nos encanta almacenarlos y compartirlos. Algunos de estos servidores están cerrados por servidores especiales pu / pp.
pu / pp
Si abrió la pestaña de red en VK, vio pu / pp.

¿Qué es pu / pp? Si cerramos un servidor tras otro, existen dos opciones para cargar y descargar un archivo a un servidor que se cerró:
directamente a través de
http://cs100500.userapi.com/path o a
través de un servidor intermedio :
http://pu.vk.com/c100500/path .
Pu es el nombre histórico para subir fotos y pp es proxy de fotos . Es decir, un servidor para subir fotos y otro para dar. Ahora no solo se cargan las fotos, sino que se ha conservado el nombre.
Estos servidores
finalizan las sesiones HTTPS para eliminar la carga del procesador del almacenamiento. Además, dado que los archivos de usuario se procesan en estos servidores, cuanto menos información confidencial se almacene en estas máquinas, mejor. Por ejemplo, claves de cifrado HTTPS.
Dado que las otras máquinas cierran las máquinas, podemos darnos el lujo de no darles IP externas "blancas" y
darles "grises" . Así que ahorramos en el grupo de IP y garantizamos proteger las máquinas del acceso desde el exterior, simplemente no hay IP para acceder.
Tolerancia a fallos a través de IP compartida . En términos de tolerancia a fallas, el esquema funciona de la misma manera: varios servidores físicos tienen una IP física común, y el trozo de hierro frente a ellos elige dónde enviar la solicitud. Más adelante hablaré sobre otras opciones.
El punto controvertido es que, en este caso, el
cliente tiene menos conexiones . Si hay la misma IP en varias máquinas, con el mismo host: pu.vk.com o pp.vk.com, el navegador del cliente tiene un límite en la cantidad de solicitudes simultáneas a un host. Pero durante el ubicuo HTTP / 2, creo que este ya no es el caso.
El inconveniente obvio del esquema es que debe
bombear todo el tráfico que va al almacenamiento a través de otro servidor. Como bombeamos tráfico a través de automóviles, todavía no podemos bombear tráfico pesado de la misma manera, por ejemplo, video. Lo transferimos directamente, una conexión directa separada para repositorios individuales específicamente para video. Transmitimos contenido más ligero a través de un proxy.
No hace mucho tiempo, tenemos una versión mejorada de proxy. Ahora te diré en qué se diferencian de los normales y por qué es necesario.
Sol
En septiembre de 2017, Oracle, que anteriormente había comprado Sun,
despidió a una gran cantidad de empleados de Sun. Podemos decir que en este momento la empresa dejó de existir. Al elegir un nombre para el nuevo sistema, nuestros administradores decidieron rendir homenaje y respeto a esta empresa, y nombraron el nuevo sistema Sun. Entre nosotros, lo llamamos simplemente "sol".
Pp tuvo algunos problemas.
Una IP por grupo es un caché ineficiente . Varios servidores físicos tienen una dirección IP común, y no hay forma de controlar a qué servidor llegará la solicitud. Por lo tanto, si diferentes usuarios vienen para el mismo archivo, entonces si hay una memoria caché en estos servidores, el archivo se instala en la memoria caché de cada servidor. Este es un esquema muy ineficiente, pero no se pudo hacer nada.
Como resultado,
no podemos compartir el contenido , porque no podemos seleccionar un servidor específico para este grupo; tienen una IP común. Además, por algunas razones internas,
no tuvimos la oportunidad de colocar dichos servidores en las regiones . Se quedaron solo en San Petersburgo.
Con los soles, cambiamos el sistema de selección. Ahora tenemos
enrutamiento anycast :
enrutamiento dinámico, anycast, self-check daemon. Cada servidor tiene su propia IP individual, pero al mismo tiempo una subred común. Todo está configurado de tal manera que, en caso de pérdida de un servidor, el tráfico se distribuye automáticamente a otros servidores del mismo grupo. Ahora es posible seleccionar un servidor específico,
no hay almacenamiento en caché excesivo y la confiabilidad no se ve afectada.
Soporte de peso . Ahora podemos permitirnos poner autos de diferentes capacidades según sea necesario, y también en caso de problemas temporales, cambiar el peso de los "soles" que trabajan para reducir la carga sobre ellos para que "descansen" y vuelvan a trabajar.
Fragmentación por ID de contenido . Lo curioso de los fragmentos es que usualmente compartimos contenido para que diferentes usuarios sigan el mismo archivo a través del mismo "sol" para que tengan un caché común.
Recientemente lanzamos la aplicación Clover. Este es un cuestionario de transmisión en vivo en línea donde el presentador hace preguntas y los usuarios responden en tiempo real eligiendo opciones. La aplicación tiene un chat donde los usuarios pueden inundar.
Más de 100 mil personas pueden conectarse simultáneamente a la transmisión. Todos escriben mensajes que se envían a todos los participantes, junto con el mensaje viene otro avatar. Si 100 mil personas vienen por un avatar en un "sol", entonces a veces puede rodar sobre una nube.
Con el fin de resistir las ráfagas de solicitudes del mismo archivo, es para algún tipo de contenido que incluimos un esquema tonto que distribuye los archivos a través de todos los "soles" disponibles en la región.
Sol adentro
Proxy inverso a nginx, caché en RAM o discos rápidos Optane / NVMe. Ejemplo:
http://sun4-2.userapi.com/c100500/path : enlace al "sol", que se encuentra en la cuarta región, el segundo grupo de servidores. Cierra el archivo de ruta, que se encuentra físicamente en el servidor 100500.
Caché
Agregamos un nodo más a nuestro esquema arquitectónico: el entorno de almacenamiento en caché.

A continuación se muestra el diseño de
cachés regionales , hay alrededor de 20 de ellos. Estos son los lugares donde se ubican exactamente los cachés y los "soles", que pueden almacenar tráfico a través de ellos.

Esto es el almacenamiento en caché de contenido multimedia, los datos del usuario no se almacenan aquí, solo música, videos y fotos.
Para determinar la región del usuario,
recopilamos los prefijos de red BGP anunciados en las regiones . En el caso de la reserva, todavía tenemos el análisis de la base de geoip, si no pudimos encontrar IP por prefijos.
Por IP del usuario, determinamos la región . En el código, podemos ver una o más regiones del usuario, esos puntos a los que está geográficamente más cercano.
Como funciona
Consideramos la popularidad de los archivos por región . Hay un número de caché regional donde se encuentra el usuario y un identificador de archivo: tomamos este par e incrementamos la calificación para cada descarga.
Al mismo tiempo, los demonios (servicios en las regiones) de vez en cuando acuden a la API y dicen: "Tengo tal y tal caché, dame una lista de los archivos más populares en mi región que aún no tengo". La API proporciona un montón de archivos ordenados por clasificación, el demonio los bombea, los lleva a las regiones y les da archivos desde allí. Esta es una diferencia fundamental entre pu / pp y Sun de las memorias caché: entregan el archivo de forma inmediata, incluso si el archivo no existe en el caché, y el caché primero descarga el archivo en sí mismo y luego comienza a regalarlo.
Al mismo tiempo, acercamos el
contenido a los usuarios y difuminamos la carga de la red. Por ejemplo, solo desde el caché de Moscú distribuimos más de 1 Tbit / s durante las horas ocupadas.
Pero hay problemas: los
servidores de caché no son de goma . Para contenido súper popular, a veces no hay suficiente red en un servidor separado. Tenemos servidores de caché de 40-50 Gbit / s, pero hay contenido que obstruye completamente dicho canal. Nos esforzamos por realizar el almacenamiento de más de una copia de archivos populares en la región. Espero que nos demos cuenta antes de fin de año.
Examinamos la arquitectura general.
- Servidores frontales que aceptan solicitudes.
- Backends que manejan solicitudes.
- Bóvedas que están cerradas por dos tipos de servidores proxy.
- Cachés regionales.
¿Qué le falta a este esquema? Por supuesto, las bases de datos en las que almacenamos datos.
Bases de datos o motores
Los llamamos no bases de datos, sino motores de motores, porque en el sentido generalmente aceptado prácticamente no tenemos bases de datos.
 Esta es una medida necesaria
Esta es una medida necesaria . Sucedió porque en 2008-2009, cuando VK tuvo un crecimiento explosivo en popularidad, el proyecto funcionó completamente en MySQL y Memcache, y hubo problemas. A MySQL le gustaba caer y arruinar los archivos, después de lo cual no aumentó, y Memcache gradualmente se degradó en rendimiento, y tuvo que reiniciarse.
Resulta que en el proyecto que estaba ganando popularidad había un almacenamiento persistente que corrompía los datos y un caché que se ralentizaba. En tales condiciones, es difícil desarrollar un proyecto en crecimiento. Se decidió intentar reescribir las cosas críticas en las que se basaba el proyecto en sus propias bicicletas.
La solución fue exitosa . La capacidad de hacer esto era, como era una necesidad urgente, porque otros métodos de escalado no existían en ese momento. No había un montón de bases, NoSQL aún no existía, solo existían MySQL, Memcache, PostrgreSQL, y eso es todo.
Operación universal . El desarrollo fue liderado por nuestro equipo de desarrolladores C, y todo se hizo de la misma manera. Independientemente del motor, en todas partes había aproximadamente el mismo formato de los archivos escritos en el disco, los mismos parámetros de inicio, las señales se procesaron de la misma manera y se comportaron de la misma manera en caso de situaciones y problemas extremos. Con el crecimiento de los motores, es conveniente para los administradores operar el sistema: no hay zoológico que deba mantenerse y aprender a operar cada nueva base de terceros nuevamente, lo que permitió aumentar su número de manera rápida y conveniente.
Tipos de motores
El equipo ha escrito bastantes motores. Aquí hay algunos de ellos: amigo, sugerencias, imagen, ipdb, cartas, listas, registros, memcached, meowdb, noticias, nostradamus, fotos, listas de reproducción, pmemcached, sandbox, búsqueda, almacenamiento, me gusta, tareas, ...
Para cada tarea que requiere una estructura de datos específica o procesa solicitudes atípicas, el equipo C escribe un nuevo motor. Por qué no
Tenemos un motor de
memoria caché separado, que es similar al habitual, pero con un montón de cosas buenas, y que no se ralentiza. No es ClickHouse, pero también funciona. Hay
pmemcached por separado: es un
memcached persistente que puede almacenar datos también en el disco, y más de lo que ingresa en la RAM para no perder datos al reiniciar. Hay varios motores para tareas individuales: colas, listas, conjuntos: todo lo que requiere nuestro proyecto.
Racimos
Desde el punto de vista del código, no hay necesidad de imaginar motores o bases de datos como ciertos procesos, entidades o instancias. El código funciona específicamente con grupos, con grupos de motores,
un tipo por grupo . Digamos que hay un clúster de memoria caché: es solo un grupo de máquinas.
El código no necesita conocer la ubicación física, el tamaño y la cantidad de servidores. Él va al grupo por algún identificador.
Para que esto funcione, debe agregar otra entidad, que se encuentra entre el código y los motores:
proxy .
Proxy RPC
Proxy: un
bus de conexión , que ejecuta casi todo el sitio. Al mismo tiempo,
no tenemos descubrimiento de servicio ; en su lugar, hay una configuración de este proxy, que conoce la ubicación de todos los clústeres y todos los fragmentos de este clúster. Esto lo hacen los administradores.
Los programadores generalmente no les importa cuánto, dónde y cuánto cuesta, simplemente van al clúster. Esto nos permite mucho. Al recibir la solicitud, el proxy redirige la solicitud, sabiendo dónde, determina esto.

Al mismo tiempo, el proxy es un punto de protección contra fallas en el servicio. Si algún motor se ralentiza o falla, el proxy lo entiende y, en consecuencia, responde al lado del cliente. Esto le permite eliminar el tiempo de espera: el código no espera a que el motor responda, pero comprende que no funciona y debe comportarse de manera diferente. El código debe estar preparado para el hecho de que las bases de datos no siempre funcionan.
Implementaciones específicas
A veces todavía queremos tener algún tipo de solución personalizada como motor. Al mismo tiempo, se decidió no utilizar nuestro proxy rpc listo para usar, creado específicamente para nuestros motores, sino crear un proxy separado para la tarea.
Para MySQL, que todavía tenemos en algunos lugares, usamos db-proxy y para ClickHouse -
Kittenhouse .
Esto funciona en general así. Hay un servidor, kPHP, Go, Python se están ejecutando en él, en general, cualquier código que pueda seguir nuestro protocolo RPC. El código va localmente al proxy RPC: en cada servidor donde hay código, se inicia su propio proxy local. Previa solicitud, el representante entiende a dónde ir.
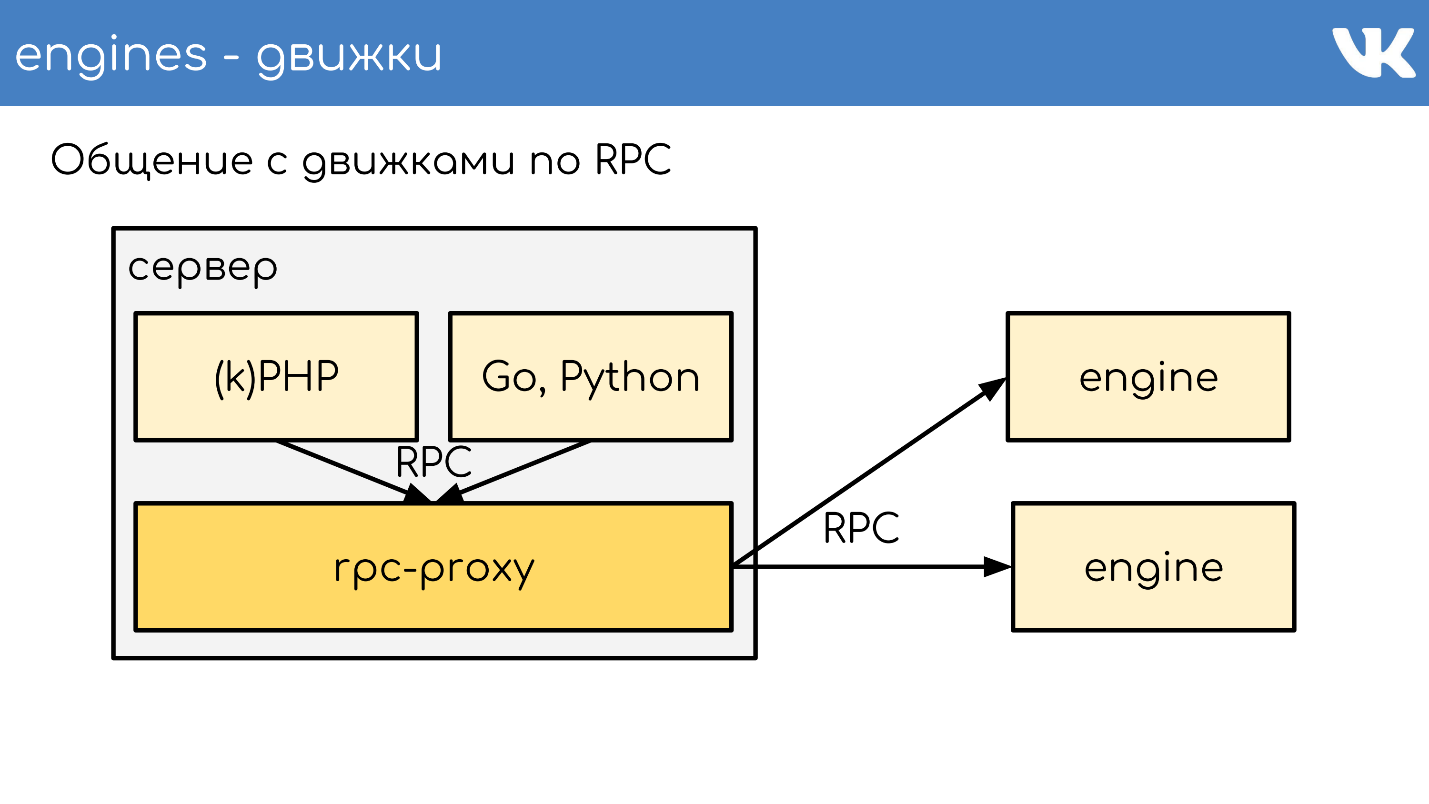
Si un motor quiere ir a otro, incluso si es un vecino, pasa por un proxy, porque el vecino puede estar en un centro de datos diferente. El motor no debe estar vinculado a conocer la ubicación de otra cosa que no sea sí mismo: tenemos esta solución estándar. Pero, por supuesto, hay excepciones :)
Un ejemplo de un esquema TL según el cual funcionan todos los motores.
memcache.not_found = memcache.Value; memcache.strvalue value:string flags:int = memcache.Value; memcache.addOrIncr key:string flags:int delay:int value:long = memcache.Value; tasks.task fields_mask:# flags:int tag:%(Vector int) data:string id:fields_mask.0?long retries:fields_mask.1?int scheduled_time:fields_mask.2?int deadline:fields_mask.3?int = tasks.Task; tasks.addTask type_name:string queue_id:%(Vector int) task:%tasks.Task = Long;
Este es un protocolo binario, cuyo análogo más cercano es
protobuf. El esquema describe de antemano campos opcionales, tipos complejos: extensiones de escalares incorporados y consultas. Todo funciona de acuerdo con este protocolo.
RPC sobre TL sobre TCP / UDP ... UDP?
Tenemos un protocolo RPC para consultar el motor, que se ejecuta sobre el esquema TL. Todo esto funciona sobre la conexión TCP / UDP. TCP: está claro por qué a menudo se nos pregunta sobre UDP.
UDP ayuda a
evitar el problema de una gran cantidad de conexiones entre servidores . Si hay un proxy RPC en cada servidor y, en general, puede ir a cualquier motor, entonces obtienes decenas de miles de conexiones TCP al servidor. Hay una carga, pero es inútil. En el caso de UDP, esto no es un problema.
Sin protocolo de enlace TCP redundante . Este es un problema típico: cuando surge un nuevo motor o un nuevo servidor, se establecen muchas conexiones TCP a la vez. Para solicitudes pequeñas y livianas, por ejemplo, carga útil UDP, toda la comunicación entre el código y el motor son
dos paquetes UDP: uno vuela en una dirección y el otro en la otra. Un viaje de ida y vuelta, y el código recibió una respuesta del motor sin un apretón de manos.
Sí, todo funciona solo
con un porcentaje muy pequeño de pérdida de paquetes . El protocolo tiene soporte para retransmisiones, tiempos de espera, pero si perdemos mucho, obtenemos prácticamente TCP, que no es rentable. A través de los océanos, no conduzca UDP.
Tenemos miles de estos servidores, y el mismo esquema existe: se coloca un paquete de motores en cada servidor físico. Básicamente, tienen un solo subproceso para funcionar lo más rápido posible sin bloqueo, y se trituran como soluciones de un solo subproceso. Al mismo tiempo, no tenemos nada más confiable que estos motores, y se presta mucha atención al almacenamiento persistente de datos.
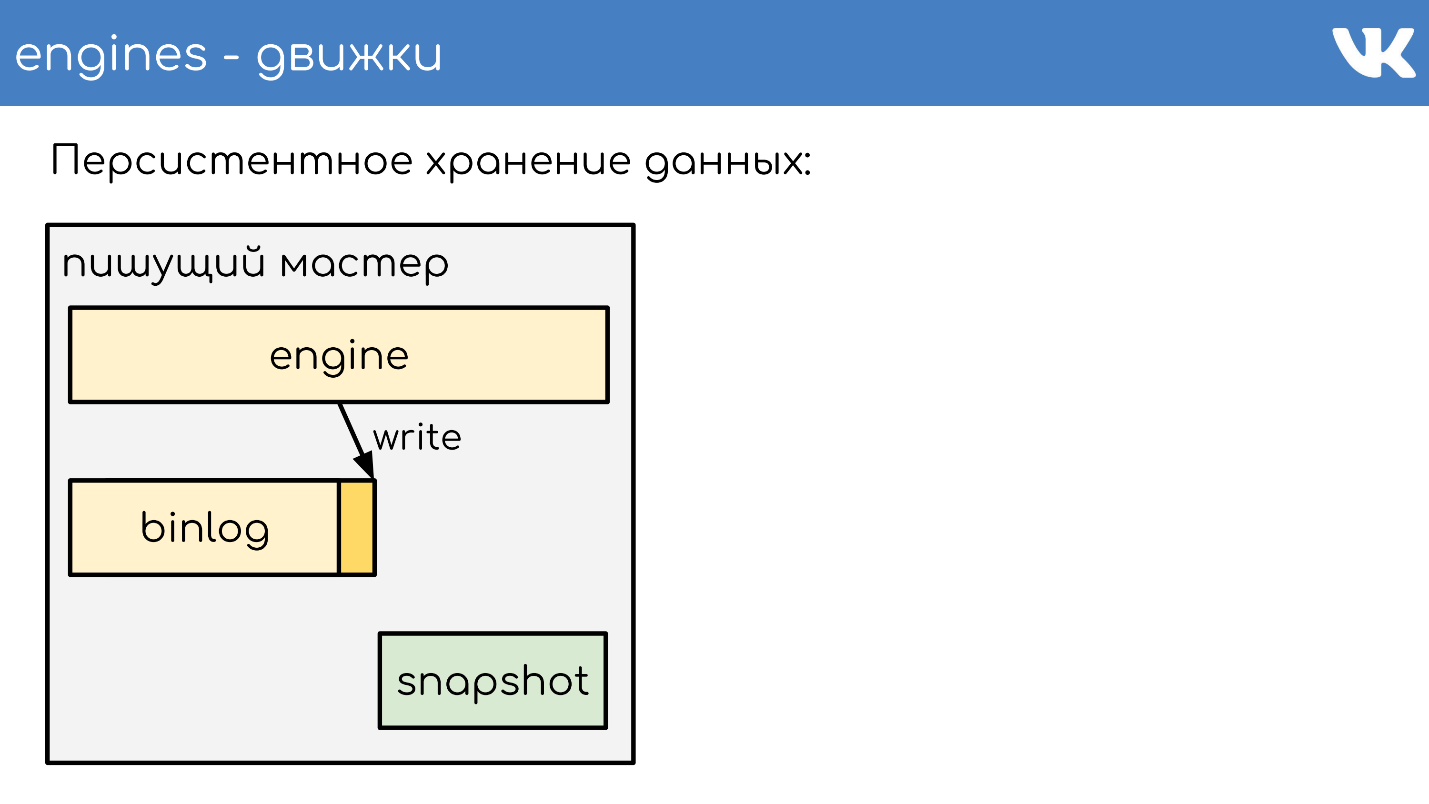
Almacenamiento de datos persistente
Los motores escriben binlogs . Un binlog es un archivo al final del cual se agrega un evento para cambiar un estado o datos. En diferentes soluciones se le llama de manera diferente: registro binario,
WAL ,
AOF , pero el principio es uno.
Para que el motor no vuelva a leer todo el binlog durante un reinicio durante muchos años, los motores escriben
instantáneas: el estado actual . Si es necesario, primero leen y luego leen el binlog. Todos los binlogs están escritos en el mismo formato binario, de acuerdo con el esquema TL, para que los administradores puedan administrarlos por igual con sus herramientas. No hay tal necesidad de instantáneas. Hay un encabezado general que indica de quién es la instantánea, la magia del motor y qué cuerpo no es importante para nadie. Este es el problema del motor que grabó la instantánea.
Describiré brevemente el principio del trabajo. Hay un servidor en el que se está ejecutando el motor. Abre un nuevo binlog vacío para grabar, escribe un evento de cambio en él.

En algún momento, decide tomar una instantánea o recibe una señal. El servidor crea un nuevo archivo, escribe completamente su estado en él, agrega el tamaño actual del binlog - desplazamiento al final del archivo, y continúa escribiendo más. No se crea un nuevo binlog.
En algún momento, cuando el motor se reinicie, habrá un binlog y una instantánea en el disco. El motor lee en una instantánea completa, eleva su estado en cierto punto.

Resta la posición que estaba en el momento en que se creó la instantánea y el tamaño del binlog.
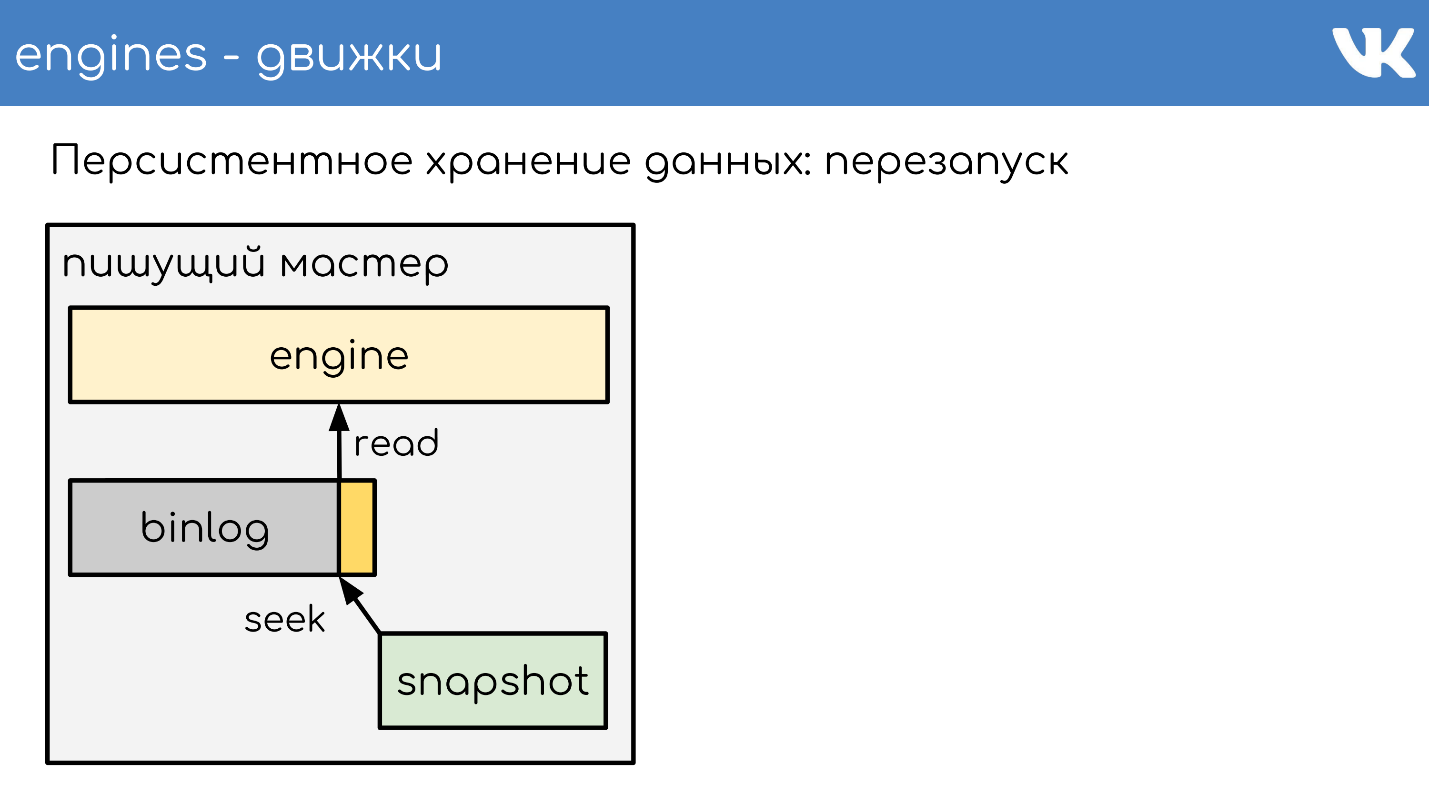
Lee el final del binlog para obtener el estado actual y continúa escribiendo más eventos. Este es un esquema simple, todos nuestros motores funcionan en él.
Replicación de datos
Como resultado, la replicación de datos está
basada en declaraciones : no estamos escribiendo ningún cambio de página en el binlog, sino
solicitudes de cambios . Muy similar a lo que viene a través de la red, solo un poco cambiado.
El mismo esquema se usa no solo para la replicación, sino también
para crear copias de seguridad . Tenemos un motor: un maestro de la escritura que escribe en un binlog. En cualquier otro lugar donde configuren los administradores, la copia de este binlog aumenta, y eso es todo: tenemos una copia de seguridad.

Si necesita una
réplica de lectura para reducir la carga de lectura en la CPU, el motor de lectura simplemente se eleva, que lee el final del binlog y ejecuta estos comandos localmente.
El retraso aquí es muy pequeño, y existe la oportunidad de averiguar cuánto queda la réplica detrás del maestro.
Fragmentación de datos en proxy RPC
¿Cómo funciona el fragmentación? ¿Cómo entiende el proxy a qué fragmento de clúster enviar? El código no dice: "¡Enviar a 15 fragmentos!" - No, hace un proxy.
El esquema más simple es firstint , el primer número en la solicitud.
get(photo100_500) => 100 % N.Este es un ejemplo para un protocolo simple de texto memcached, pero, por supuesto, las solicitudes son complejas y estructuradas. El ejemplo toma el primer número en la consulta y el resto de la división por el tamaño del clúster.
Esto es útil cuando queremos tener la localidad de datos de una entidad. Digamos que 100 es un ID de usuario o grupo, y queremos que todos los datos de una entidad estén en el mismo fragmento para consultas complejas.
Si no nos importa cómo se distribuyen las solicitudes en el clúster, existe otra opción:
dividir el fragmento completo .
hash(photo100_500) => 3539886280 % NTambién obtenemos el hash, el resto de la división y el número del fragmento.
Ambas opciones funcionan solo si estamos preparados para el hecho de que cuando aumentamos el tamaño del clúster, lo dividiremos o lo multiplicaremos por varias veces. Por ejemplo, teníamos 16 fragmentos, nos faltan, queremos más: puede obtener 32 de forma segura sin tiempo de inactividad. Si queremos construir varias veces, habrá un tiempo de inactividad, ya que no será posible aplastar todo cuidadosamente sin pérdida. Estas opciones son útiles, pero no siempre.
Si necesitamos agregar o eliminar un número arbitrario de servidores,
se utiliza un hashing consistente en el anillo a la Ketama . Pero al mismo tiempo, perdemos completamente la localidad de los datos, tenemos que hacer una solicitud de fusión al clúster para que cada pieza devuelva su pequeña respuesta y ya combine las respuestas al proxy.
- . : RPC-proxy , , . , , , . proxy.

. —
memcache .
ring-buffer: prefix.idx = line— , , — . 0 1. memcache — . .
,
Multi Get , , . , - , , , .
logs-engine . , . 600 .
, , 6–7 . , , , ClickHouse .
ClickHouse
, .

, RPC RPC-proxy, , . ClickHouse, :
- - ClickHouse;
- RPC-proxy, ClickHouse, - , , RPC.
— ClickHouse.
ClickHouse,
KittenHouse . KittenHouse ClickHouse — . , HTTP- . , ClickHouse
reverse proxy , , . .

RPC- , , nginx. KittenHouse UDP.

, UDP- . RPC , UDP. .
Monitoreo
: , , . :
.
Netdata ,
Graphite Carbon . ClickHouse, Whisper, . ClickHouse,
Grafana , . , Netdata Grafana .
. , , Counts, UniqueCounts , - .
statlogsCountEvent ( 'stat_name', $key1, $key2, …) statlogsUniqueCount ( 'stat_name', $uid, $key1, $key2, …) statlogsValuetEvent ( 'stat_name', $value, $key1, $key2, …) $stats = statlogsStatData($params)
, , — , Wathdogs.
, 600 1 .
, . — , . , .
,
memcache , .
stats-daemon .
logs-collectors , , .

logs-collectors.
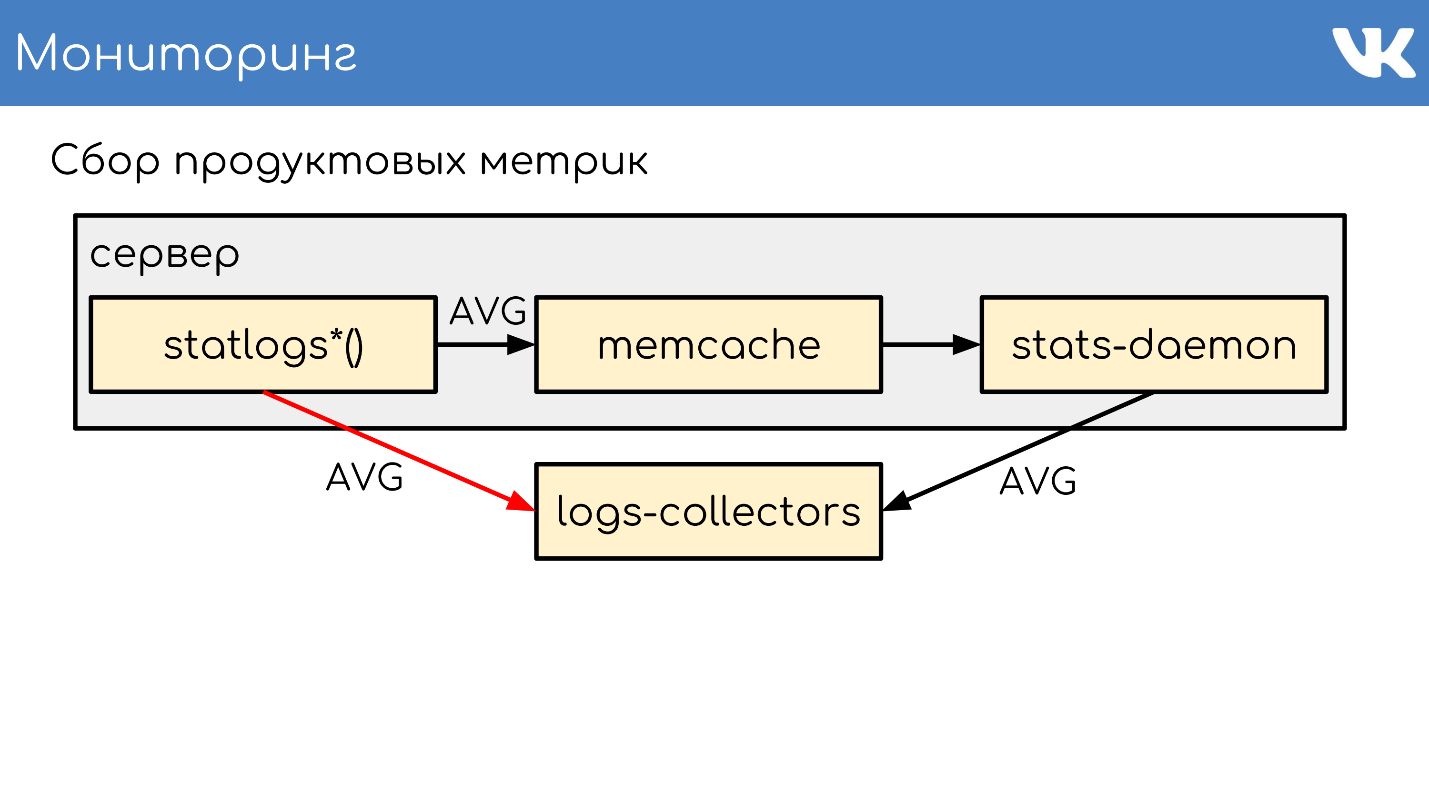
stas-daemom — , collector. , - memcache stats-daemon, , .
logs-collectors
meowDB — , .
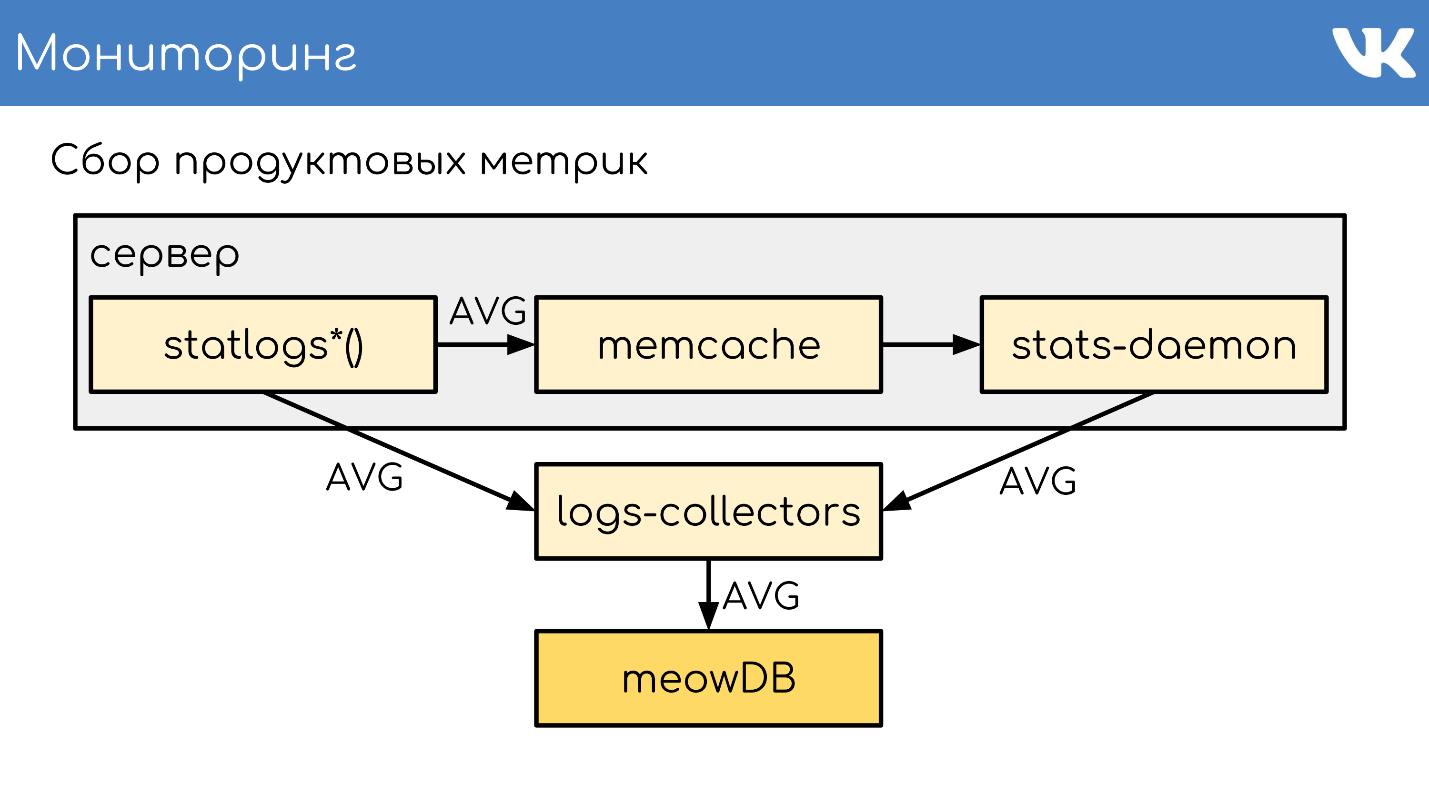
«-SQL» .

2018 , -, ClickHouse. ClickHouse — ?

, KittenHouse.
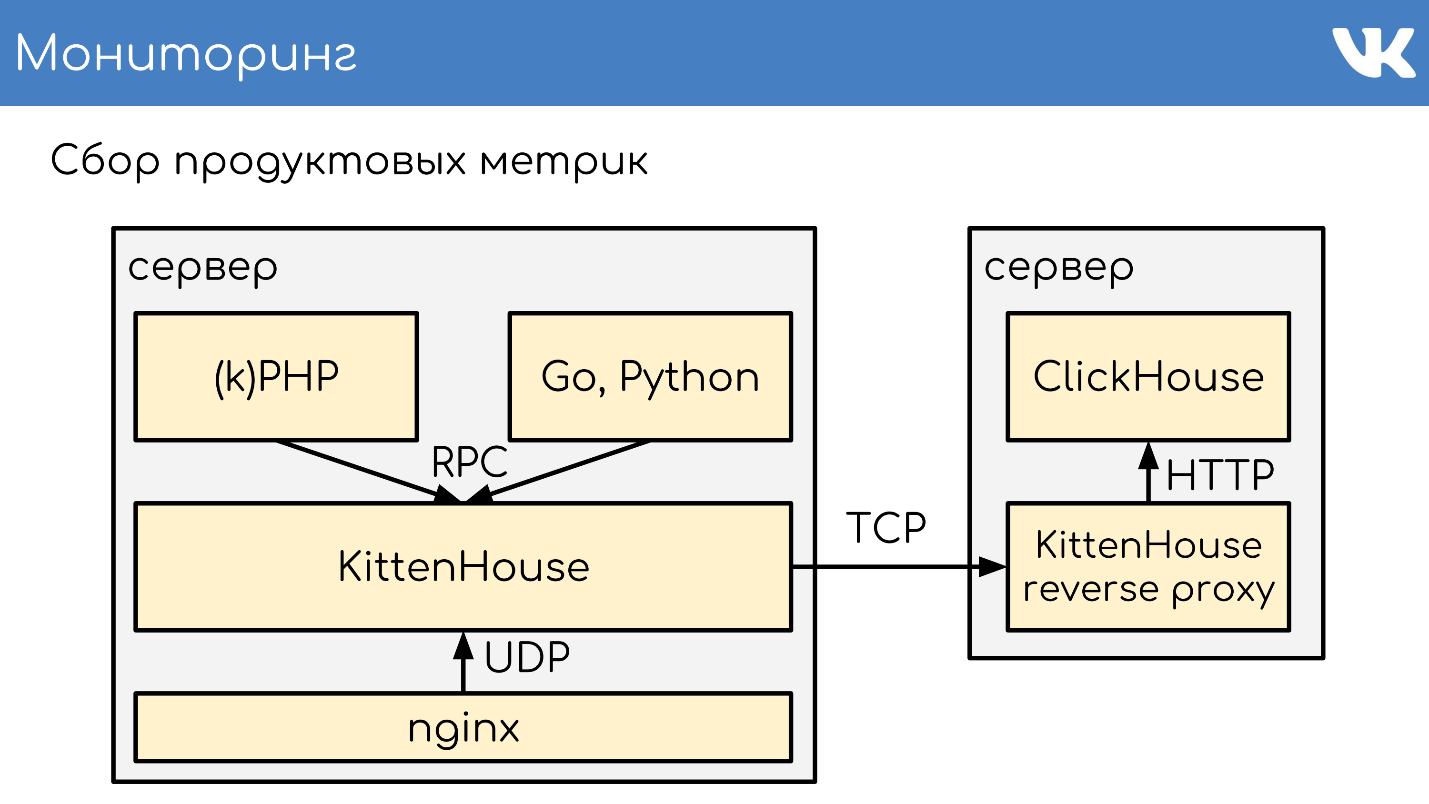 «*House»
«*House» , , UDP. *House inserts, , KittenHouse. ClickHouse, .
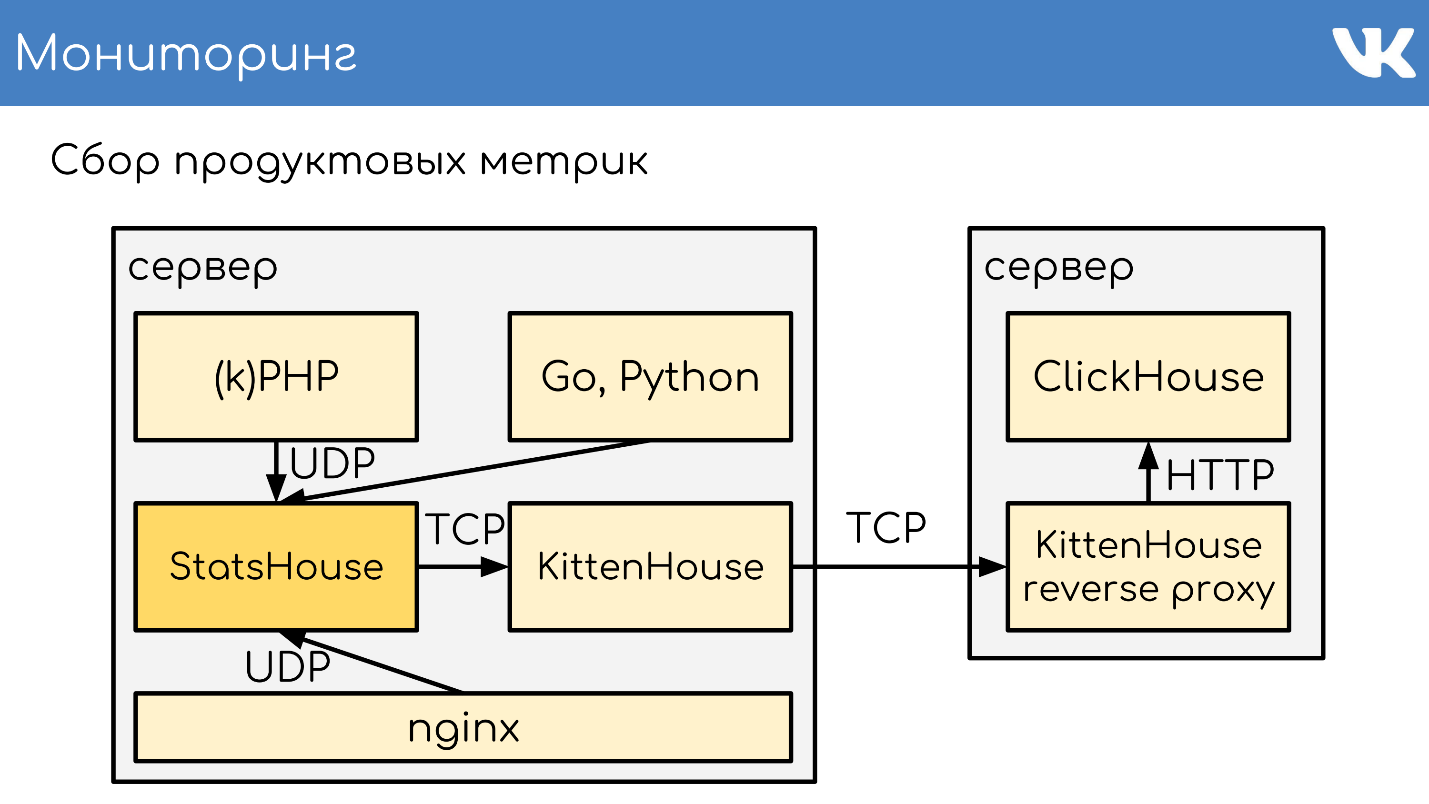
memcache, stats-daemon logs-collectors .

memcache, stats-daemon logs-collectors .
- , StatsHouse.
- StatsHouse KittenHouse UDP-, SQL-inserts, .
- KittenHouse ClickHouse.
- , StatsHouse — ClickHouse SQL.
, , . , , , . .
. , stats-daemons logs-collectors, ClickHouse , , .
, .
PHP.
git :
GitLab TeamCity . -, , — .
, diff — : , , . binlog copyfast, . ,
gossip replication , , — , . . ,
. .
kPHP
git .
HTTP- , diff — . —
binlog copyfast . , .
. copyfast' , binlog , gossip replication , -, .
graceful .
, , :
- git master branch;
- .deb ;
- binlog copyfast;
- ;
- .dep;
- dpkg -i ;
- graceful .
,
.deb ,
dpkg -i . kPHP , — dpkg? . — .
:, PHP Russia 17 PHP-. , , ( PHP!) — , PHP, .