
Hola Quiero hablar en lenguaje sencillo sobre la mecánica de la aparición del robo dentro de las máquinas virtuales y sobre algunos artefactos no evidentes que pudimos descubrir durante su investigación, en los que tuve que sumergirme como asesor técnico de la plataforma en la nube
Mail.ru Cloud Solutions . La plataforma se ejecuta en KVM.
El tiempo de robo de la CPU es el tiempo durante el cual la máquina virtual no recibe recursos del procesador para su ejecución. Este tiempo solo se considera en los sistemas operativos invitados en entornos de virtualización. Las razones por las que van estos recursos muy asignados, como en la vida, son muy vagas. Pero decidimos resolverlo, incluso establecer una serie completa de experimentos. No es que ahora sepamos todo sobre el robo, pero le diremos algo interesante en este momento.
1. ¿Qué es robar?
Por lo tanto, robar es una métrica que indica una falta de tiempo de procesador para los procesos dentro de una máquina virtual. Como se describe
en el parche del kernel KVM , robar es el tiempo durante el cual el hipervisor ejecuta otros procesos en el sistema operativo host, aunque ha puesto en cola el proceso de la máquina virtual para su ejecución. Es decir, el robo se considera la diferencia entre el momento en que el proceso está listo para ejecutarse y el momento en que se asigna el tiempo de proceso al procesador.
El núcleo del núcleo recibe el robo métrico del hipervisor. Al mismo tiempo, el hipervisor no especifica exactamente qué otros procesos realiza, simplemente "mientras estoy ocupado, no puedo darle tiempo". En KVM, se ha agregado soporte para contar robos en
parches . Aquí hay dos puntos clave:
- La máquina virtual aprende sobre el robo del hipervisor. Es decir, desde el punto de vista de las pérdidas, para los procesos en la máquina virtual en sí, es una medición indirecta que puede estar sujeta a varias distorsiones.
- El hipervisor no comparte información con la máquina virtual sobre lo que está haciendo con los demás; lo principal es que no le dedica tiempo. Debido a esto, la máquina virtual en sí misma no puede detectar distorsiones en el índice de robo, lo que podría estimarse por la naturaleza de los procesos competitivos.
2. Lo que afecta el robo
2.1. Robo de cálculo
De hecho, el robo se considera aproximadamente lo mismo que el tiempo normal de utilización de la CPU. No hay mucha información sobre cómo se considera la eliminación. Probablemente porque la mayoría considera esta pregunta obvia. Pero también hay dificultades aquí. Para familiarizarse con este proceso, puede leer el
artículo de Brendann Gregg : aprenderá sobre un montón de matices en el cálculo de la utilización y sobre situaciones en las que este cálculo será erróneo por las siguientes razones:
- Sobrecalentamiento del procesador, durante el cual se omiten los ciclos de reloj.
- Active / desactive el turbo boost, como resultado de lo cual cambia la frecuencia del reloj del procesador.
- Un cambio en la duración de un tiempo cuántico que ocurre cuando se usan tecnologías de ahorro de energía del procesador como SpeedStep.
- El problema de calcular el promedio: una estimación de la utilización en un minuto al 80% puede ocultar una explosión a corto plazo en el 100%.
- El bloqueo cíclico (bloqueo de giro) conduce al hecho de que el procesador se elimina, pero el proceso del usuario no ve progreso en su ejecución. Como resultado, la utilización estimada del procesador por el proceso será del cien por ciento, aunque el proceso no consumirá físicamente el tiempo del procesador.
No encontré un artículo que describiera un cálculo similar para robar (si lo sabe, comparta en los comentarios). Pero, a juzgar por la fuente, el mecanismo de cálculo es el mismo que para la eliminación. Es solo que se agrega otro contador al kernel, directamente para el proceso KVM (proceso de máquina virtual), que cuenta el tiempo que el proceso KVM está en el estado de espera del tiempo de procesador. El contador toma información sobre el procesador de su especificación y observa si el proceso virtual ha utilizado todos sus tics. Si eso es todo, entonces creemos que el procesador solo participó en el proceso de la máquina virtual. De lo contrario, informamos que el procesador estaba haciendo otra cosa, apareció robar.
El proceso de conteo de robos está sujeto a los mismos problemas que el conteo de reciclaje regular. No quiere decir que tales problemas aparezcan con frecuencia, pero parecen desalentadores.
2.2. Tipos de virtualización en KVM
En términos generales, hay tres tipos de virtualización, y todos ellos son compatibles con KVM. El tipo de virtualización puede determinar el mecanismo por el cual ocurre el robo.
Broadcast En este caso, la operación del sistema operativo de la máquina virtual con los dispositivos físicos del hipervisor ocurre aproximadamente de esta manera:
- El sistema operativo invitado envía un comando a su dispositivo invitado.
- El controlador del dispositivo invitado acepta el comando, genera una solicitud para el BIOS del dispositivo y lo envía al hipervisor.
- El proceso del hipervisor traduce un comando en un comando para un dispositivo físico, lo que lo hace, entre otras cosas, más seguro.
- El controlador del dispositivo físico acepta el comando modificado y lo envía al propio dispositivo físico.
- Los resultados de la ejecución del comando vuelven por el mismo camino.
La ventaja de la traducción es que le permite emular cualquier dispositivo y no requiere una preparación especial del núcleo del sistema operativo. Pero hay que pagarlo, antes que nada, con rapidez.
Virtualización de hardware . En este caso, el dispositivo a nivel de hardware comprende los comandos del sistema operativo. Esta es la mejor y más rápida forma. Pero, desafortunadamente, no es compatible con todos los dispositivos físicos, hipervisores y sistemas operativos invitados. Actualmente, los principales dispositivos que admiten la virtualización de hardware son los procesadores.
Paravirtualización (paravirtualización) . La versión más común de virtualización de dispositivos en KVM y, en general, el modo de virtualización más común para sistemas operativos invitados. Su peculiaridad es que funciona con algunos subsistemas del hipervisor (por ejemplo, con una red o pila de discos) o la asignación de páginas de memoria se realiza utilizando la API del hipervisor, sin traducir comandos de bajo nivel. La desventaja de este método de virtualización es la necesidad de modificar el núcleo del sistema operativo invitado para que pueda interactuar con el hipervisor utilizando esta API. Pero generalmente esto se resuelve instalando controladores especiales en el sistema operativo invitado. En KVM, esta API se llama
virtio API .
Con la paravirtualización, en comparación con la traducción, la ruta al dispositivo físico se reduce significativamente al enviar comandos directamente desde la máquina virtual al proceso del hipervisor host. Esto le permite acelerar la ejecución de todas las instrucciones dentro de la máquina virtual. En KVM, la API virtio es responsable de esto, que funciona solo para ciertos dispositivos, como una red o un adaptador de disco. Es por eso que los controladores virtio se colocan dentro de máquinas virtuales.
La otra cara de esta aceleración es que no todos los procesos que se ejecutan dentro de una máquina virtual permanecen dentro de ella. Esto crea algunos efectos especiales que pueden provocar la aparición de robos. Recomiendo comenzar un estudio detallado de este problema con
una API para E / S virtual: virtio .
2.3. Derramamiento justo
La virtualización en un hipervisor es, de hecho, un proceso ordinario que obedece las leyes de sheduling (asignación de recursos entre procesos) en el kernel de Linux, por lo que lo consideraremos con más detalle.
Linux usa el llamado CFS, Completely Fair Scheduler, que se ha convertido en el distribuidor predeterminado desde el kernel 2.6.23. Para comprender este algoritmo, puede leer la arquitectura o las fuentes del kernel de Linux. La esencia del CFS es la distribución del tiempo del procesador entre procesos, dependiendo de la duración de su ejecución. Cuanto más tiempo de procesador requiere el proceso, menos tiempo recibe. Esto garantiza la ejecución "honesta" de todos los procesos, de modo que un proceso no ocupe constantemente todos los procesadores, y también se puedan ejecutar otros procesos.
A veces este paradigma conduce a artefactos interesantes. Los usuarios de Linux de toda la vida probablemente recordarán el desvanecimiento de un editor de texto de escritorio normal mientras ejecutan aplicaciones exigentes tipo compilador. Esto sucedió porque las tareas de las aplicaciones de escritorio que no requieren muchos recursos compitieron con tareas que consumen recursos activamente, como un compilador. CFS considera que esto es deshonesto, por lo que detiene periódicamente el editor de texto y permite que el procesador procese las tareas del compilador. Esto se corrigió utilizando el mecanismo
sched_autogroup , pero
quedaron muchas otras características de la distribución del tiempo de CPU entre tareas. En realidad, esta historia no trata sobre qué tan mal están las cosas en el SFC, sino un intento de llamar la atención sobre el hecho de que una distribución "honesta" del tiempo del procesador no es la tarea más trivial.
Otro punto importante en el programador es la preferencia. Esto es necesario para impulsar el proceso de snickering desde el procesador y dejar que otros trabajen. El proceso de exilio se llama cambio de contexto, cambio de contexto del procesador. En este caso, se guarda todo el contexto de la tarea: el estado de la pila, los registros, etc., después de lo cual el proceso pasa a esperar, y otro toma su lugar. Esta es una operación costosa para el sistema operativo, y rara vez se usa, pero de hecho no tiene nada de malo. El cambio frecuente de contexto puede indicar un problema en el sistema operativo, pero generalmente continúa de forma continua y no indica nada en particular.
Se necesita una historia tan larga para explicar un hecho: cuantos más recursos de procesador intente consumir un programador honesto de Linux, más rápido se detendrá para que otros procesos también puedan funcionar. Si esto es correcto o no es un problema complejo, que se resuelve de manera diferente bajo diferentes cargas. En Windows, hasta hace poco, el programador se enfocaba en el procesamiento prioritario de las aplicaciones de escritorio, por lo que los procesos en segundo plano podrían bloquearse. Sun Solaris tenía cinco clases diferentes de shedulers. Cuando comenzaron la virtualización, agregaron el sexto
programador de reparto justo , porque los cinco anteriores trabajaron con la virtualización de Zonas de Solaris de manera inadecuada. Recomiendo comenzar un estudio detallado de este problema con libros como
Solaris Internals: Solaris 10 y OpenSolaris Kernel Architecture o
Understanding the Linux Kernel .
2.4. ¿Cómo controlar el robo?
Monitorear el robo dentro de una máquina virtual, como cualquier otra métrica del procesador, es simple: puede usar cualquier medio para eliminar las métricas del procesador. Lo principal es que la máquina virtual está en Linux. Por alguna razón, Windows no proporciona dicha información a sus usuarios. :(
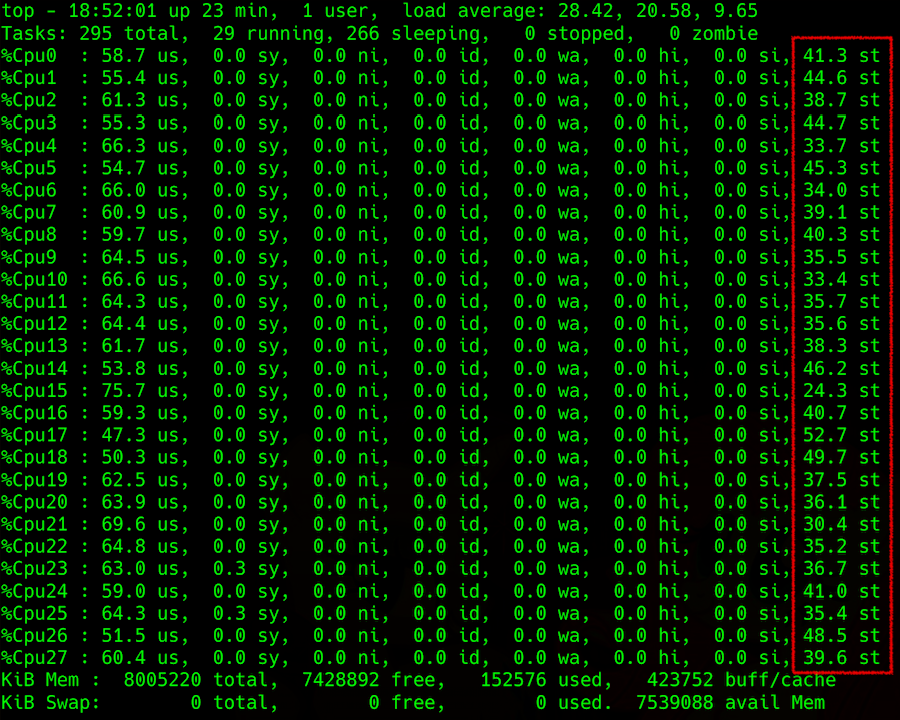 La salida del comando superior: detalles de carga del procesador, en la columna de la derecha - robar
La salida del comando superior: detalles de carga del procesador, en la columna de la derecha - robarLa dificultad surge cuando se trata de obtener esta información del hipervisor. Puede intentar predecir el robo en la máquina host, por ejemplo, mediante el parámetro Carga promedio (LA): el valor promedio del número de procesos que esperan en la cola para la ejecución. La metodología para calcular este parámetro no es simple, pero en general, si LA, normalizada por el número de subprocesos del procesador, es mayor que 1, esto indica que el servidor Linux está algo sobrecargado.
¿Qué están esperando todos estos procesos? La respuesta obvia es el procesador. Pero la respuesta no es del todo correcta, porque a veces el procesador es gratuito y LA se da vuelta. Recuerde
cómo se cae NFS y cómo crece LA . Puede ser aproximadamente lo mismo con un disco y con otros dispositivos de entrada / salida. Pero, de hecho, los procesos pueden esperar el final de cualquier bloqueo, tanto físico, asociado con un dispositivo de E / S, como lógico, como un mutex. Esto también incluye bloqueos a nivel de hardware (la misma respuesta del disco) o lógica (las llamadas primitivas de bloqueo, que incluye un conjunto de entidades, mutex adaptativo y spin, semáforos, variables de condición, bloqueos rw, bloqueos ipc ...).
Otra característica de LA es que se considera como el valor promedio para el sistema operativo. Por ejemplo, 100 procesos compiten por un archivo, y luego LA = 50. Parece que un valor tan grande sugiere que el sistema operativo es malo. Pero para otro código escrito torcidamente, este puede ser un estado normal, a pesar del hecho de que es malo solo para él, y otros procesos en el sistema operativo no sufren.
Debido a este promedio (y no menos de un minuto), determinar algo mediante el indicador AL no es la tarea más agradecida, con resultados muy inciertos en casos específicos. Si intenta resolverlo, descubrirá que solo los casos más simples se describen en los artículos de Wikipedia y otros recursos disponibles, sin una explicación profunda del proceso. Envío a todos los interesados, nuevamente,
aquí, a Brendann Gregg , más adelante en los enlaces. Para quien la pereza en inglés es una
traducción de su popular artículo sobre Los Ángeles .
3. Efectos especiales
Ahora analicemos los principales casos de robo que encontramos. Te diré cómo se siguen de lo anterior y cómo se relacionan con los indicadores en el hipervisor.
Reciclaje El más simple y frecuente: el hipervisor se reutiliza. De hecho, hay muchas máquinas virtuales en ejecución, un gran consumo de procesador dentro de ellas, mucha competencia, la utilización de LA es más de 1 (normalizada por hilos de procesador). Dentro de todos los virtualoks todo se ralentiza. El robo transmitido desde el hipervisor también está creciendo, es necesario redistribuir la carga o apagar a alguien. En general, todo es lógico y comprensible.
Paravirtualización versus instancias individuales . Hay una sola máquina virtual en el hipervisor, consume una pequeña parte de ella, pero genera una gran carga en la entrada / salida, por ejemplo, en un disco. Y desde algún lugar aparece un pequeño robo, hasta un 10% (como lo demuestran varios experimentos).
El caso es interesante. El robo aparece aquí solo por bloqueos en el nivel de los conductores paravirtualizados. Se crea una interrupción dentro de la máquina virtual, procesada por el controlador, y va al hipervisor. Debido al procesamiento de interrupción en el hipervisor para la máquina virtual, parece una solicitud enviada, está lista para su ejecución y esperando al procesador, pero no le dan tiempo al procesador. Virtualka piensa que esta vez es robado.
Esto sucede cuando se envía el búfer, va al espacio del kernel del hipervisor y comenzamos a esperarlo. Aunque, desde el punto de vista de virtualka, debería regresar de inmediato. Por lo tanto, de acuerdo con el algoritmo de cálculo de robo, esta vez se considera robado. Lo más probable es que en esta situación pueda haber otros mecanismos (por ejemplo, procesar algunas otras llamadas del sistema), pero no deberían ser muy diferentes.
Sheduler contra virtualoks muy cargados . Cuando una máquina virtual sufre de robo más que otras, está conectada precisamente con el programador. Cuanto más fuerte sea el proceso que cargue el procesador, más rápido lo expulsará el programador, para que los demás también puedan trabajar. Si la máquina virtual consume un poco, casi no ve robo: su proceso honestamente se sentó y esperó, es necesario darle más tiempo. Si la máquina virtual produce la carga máxima en todos sus núcleos, a menudo es expulsada del procesador e intenta no dar mucho tiempo.
Peor aún, cuando los procesos dentro de la máquina virtual intentan obtener más procesador, porque no pueden hacer frente al procesamiento de datos. Entonces, el sistema operativo en el hipervisor, debido a una optimización honesta, le dará cada vez menos tiempo de procesador. Este proceso tiene lugar como una avalancha, y el robo salta al cielo, aunque otras máquinas virtuales casi no lo notan. Y cuantos más núcleos, peor la máquina cayó bajo la distribución. En resumen, las máquinas virtuales muy cargadas con muchos núcleos son las que más sufren.
Baja LA, pero hay un robo . Si LA es aproximadamente 0.7 (es decir, el hipervisor parece estar subcargado), pero se observa robo dentro de máquinas virtuales individuales:
- La opción descrita anteriormente con paravirtualización. Una máquina virtual puede recibir métricas que apuntan a robar, aunque todo está bien con el hipervisor. Según los resultados de nuestros experimentos, dicha opción de robo no supera el 10% y no debería tener un impacto significativo en el rendimiento de la aplicación dentro de la máquina virtual.
- El parámetro LA se considera incorrectamente. Más precisamente, en cada momento particular se considera cierto, pero cuando se promedia durante un minuto, resulta subestimado. Por ejemplo, si una máquina virtual consume todos sus procesadores durante exactamente medio minuto por tercio del hipervisor, entonces LA por minuto será 0.15 en el hipervisor; cuatro de estas máquinas virtuales que trabajan simultáneamente darán 0.6. Y el hecho de que durante medio minuto en cada uno de ellos hubo un robo salvaje al 25% en Los Ángeles, ya no se puede sacar.
- Nuevamente, debido al planificador que decidió que alguien estaba comiendo demasiado y dejó que este esperara. Mientras tanto, estoy cambiando el contexto, procesando interrupciones y haciendo otras cosas importantes del sistema. Como resultado, algunas máquinas virtuales no ven ningún problema, mientras que otras experimentan una grave degradación del rendimiento.
4. Otras distorsiones
Hay otro millón de razones para distorsionar el retorno honesto del tiempo de procesador en la máquina virtual. Por ejemplo, hypertreading y NUMA agregan complejidad a los cálculos. Confunden completamente la elección del núcleo para ejecutar el proceso, porque el planificador utiliza coeficientes, pesos, que al cambiar de contexto hacen que el cálculo sea aún más difícil.
Hay distorsiones debidas a tecnologías como el turbo boost o, por el contrario, el modo de ahorro de energía, que al calcular la utilización puede aumentar o disminuir artificialmente la frecuencia o incluso el intervalo de tiempo en el servidor. Activar el turbo boost reduce el rendimiento de un subproceso de procesador debido al mayor rendimiento de otro. En este momento, la información sobre la frecuencia actual del procesador no se transmite a la máquina virtual y cree que alguien está atando su tiempo (por ejemplo, solicitó 2 GHz, pero recibió la mitad).
En general, puede haber muchas causas de distorsión. En un sistema particular, puede encontrar algo más. Es mejor comenzar con los libros a los que les di los enlaces anteriores y tomar estadísticas del hipervisor con utilidades como perf, sysdig, systemtap, de las cuales hay
docenas .
5. Conclusiones
- Una cierta cantidad de robo puede ocurrir debido a la paravirtualización, y puede considerarse normal. En Internet escriben que este valor puede ser del 5-10%. Depende de las aplicaciones dentro de la máquina virtual y de qué tipo de carga pone en sus dispositivos físicos. Es importante prestar atención a cómo se sienten las aplicaciones dentro de las máquinas virtuales.
- La relación de la carga en el hipervisor y el robo dentro de la máquina virtual no siempre está interconectada sin ambigüedades, ambas estimaciones de robo pueden ser erróneas en situaciones específicas con diferentes cargas.
- Al programador no le gustan los procesos que piden mucho. Intenta dar menos a los que piden más. Las grandes máquinas virtuales son malvadas.
- Un pequeño robo puede ser la norma sin paravirtualización (teniendo en cuenta la carga dentro de la máquina virtual, las características de la carga de los vecinos, la distribución de la carga entre subprocesos y otros factores).
- Si desea descubrir el robo en un sistema específico, debe investigar varias opciones, recopilar métricas, analizarlas cuidadosamente y pensar en cómo distribuir la carga de manera uniforme. Las desviaciones son posibles de cualquier caso, que debe confirmarse experimentalmente o verse en el depurador del núcleo.