Continuamos hablando sobre los proyectos del hackathon de primavera DevDays, en el que participaron estudiantes del programa de maestría
"Ingeniería de Software / Ingeniería de Software" .

Por cierto, queremos invitar a los lectores a unirse al
grupo VK de la magistratura . En él publicaremos las últimas noticias sobre reclutamiento y estudio. El video de la jornada de puertas abiertas también se puede encontrar en el grupo. Te recordamos: el evento se llevará a cabo el 29 de abril, detalles
en el sitio .
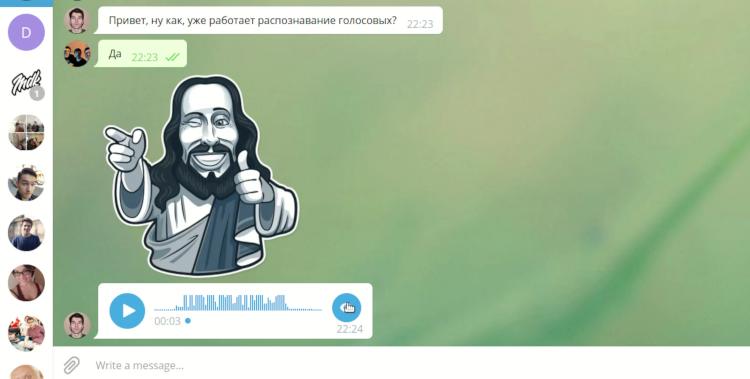
Analizador de mensajes de voz de escritorio Telegram
 El autor de la idea.
El autor de la idea.Khoroshev Artyom
Composición del equipoKhoroshev Artem - gerente de proyecto / desarrollador / QA
Eliseev Anton - Analista de negocios / Especialista en marketing
Kuklina Maria - Diseñadora / desarrolladora de UI
Bakhvalov Pavel - Diseñador de UI / desarrollador / QA
Desde nuestro punto de vista, Telegram es un mensajero moderno y conveniente, y su versión para PC es popular y de código abierto, por lo que es posible modificarlo. El cliente ofrece una funcionalidad bastante rica. Además de los mensajes de texto estándar, contiene llamadas de voz, mensajes de video, mensajes de voz. Y es esto último lo que a veces incomoda a su destinatario. A menudo no hay forma de escuchar un mensaje de voz mientras está en una computadora o computadora portátil. El ruido ambiental, la falta de auriculares pueden interferir o no desea que nadie escuche el contenido del mensaje. Tales problemas casi nunca ocurren si usa telegramas en su teléfono inteligente, porque puede llevarlos a su oído, a diferencia de una computadora portátil o PC. Intentamos resolver este problema.
El objetivo de nuestro proyecto en DevDays era agregar la capacidad de traducir los mensajes de voz recibidos a texto en el cliente de escritorio de Telegram (en adelante, Escritorio de Telegram).
Todos los análogos en este momento son bots a los que puede enviar un mensaje de audio y, a cambio, recibir un mensaje de texto. Esto no es muy conveniente para nosotros: reenviar un mensaje a un bot no es muy conveniente, me gustaría tener una funcionalidad nativa. Además, cualquier bot es un tercero que actúa como intermediario entre la API de reconocimiento de voz y el usuario, y esto es al menos inseguro.
Como se señaló anteriormente, Telegram-Desktop tiene dos ventajas de peso: ligereza y velocidad. Y esto no es una coincidencia, porque está completamente escrito en C ++. Y como decidimos agregar una nueva funcionalidad directamente al cliente, tuvimos que desarrollarla en C ++.

Había 4 personas en nuestro equipo. Inicialmente, dos buscaban una biblioteca adecuada para el reconocimiento de voz, una persona estudió el código fuente de Telegram-desktop, otra estaba implementando la construcción del proyecto
Telegram Desktop . Más tarde, todos estaban ocupados con las correcciones y depuración de la interfaz de usuario.
Parecía que la implementación de la funcionalidad prevista no sería difícil, pero, como siempre, surgieron dificultades.
La solución al problema consistió en dos subtareas independientes: seleccionar los medios apropiados para el reconocimiento de voz e implementar la IU para una nueva funcionalidad.
Al elegir una biblioteca para el reconocimiento de voz, inmediatamente tuvimos que abandonar todas las API fuera de línea, porque los modelos de idiomas ocupan mucho espacio. Pero este es solo un idioma. Quedó claro que tendrías que usar la API en línea. Más tarde resultó que los servicios de reconocimiento de voz de gigantes como Google, Yandex y Microsoft no son gratuitos en absoluto, y tendremos que contentarnos con un período de prueba. Como resultado, se eligió Google Speech-To-Text, ya que le permite obtener un token por usar el servicio, que durará todo un año.
El segundo problema que encontramos está asociado con algunos de los inconvenientes de C ++: el zoológico de varias bibliotecas en ausencia de un repositorio centralizado. Sucedió que Telegram Desktop depende de muchas otras bibliotecas de versiones específicas. El repositorio oficial tiene
instrucciones para construir el proyecto. Y también una gran cantidad de problemas abiertos sobre problemas de compilación, por ejemplo,
una y
dos veces . Todos los problemas se debieron al hecho de que el script de compilación fue escrito para Ubuntu 14.04, y para construir un telegrama con éxito en Ubuntu 18.04, tuve que hacer cambios.
Telegram Desktop tomará bastante tiempo: en una computadora portátil con un Intel Core i5-7200U, el ensamblaje completo (indicador -j 4) con todas las dependencias demora aproximadamente tres horas. De estos, se tarda unos 30 minutos en vincular el cliente en sí (más tarde resultó que en la configuración de depuración, la vinculación lleva unos 10 minutos), pero el paso de vinculación debe repetirse cada vez que se realizan cambios.
A pesar de los problemas, logramos implementar nuestra idea, así como actualizar el
script de compilación para Ubuntu 18.04. La demostración del trabajo se puede ver
aquí . También aplicamos varias animaciones. Aparece un botón cerca de todos los mensajes de voz, lo que le permite traducir el mensaje a texto. Cuando hace clic con el botón derecho, puede especificar opcionalmente el idioma que se utilizará para la traducción. El cliente está disponible para descargar a
través del enlace .
Repositorio.En nuestra opinión, obtuvimos una buena funcionalidad de Prueba de concepto que sería conveniente para muchos usuarios. Esperamos verlo en futuras versiones de Telegram Desktop.
Soporte de lenguaje natural ampliado en IntelliJ IDEA
 El autor de la idea.
El autor de la idea.Tanques Vladislav
Composición del equipoTanks Vladislav (jefe de equipo, trabajando con LanguageTool e IntelliJ IDEA)
Sokolov Nikita (trabajando con LanguageTool y creando UI)
Hvorov Alexander (trabajando con LanguageTool y optimizando el rendimiento)
Sadovnikov Alexander (soporte para analizar códigos y lenguajes de marcado)
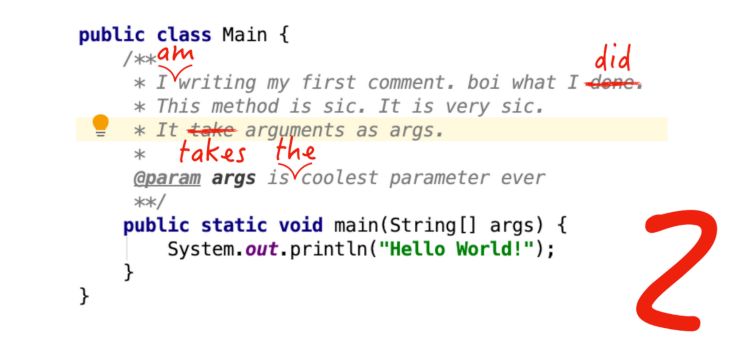
Desarrollamos un complemento para IntelliJ IDEA que verifica varios textos (comentarios y documentación, líneas literales en código, texto formateado en Markdown o marcado XML) para fidelidad gramatical, ortográfica y estilística (en inglés, esto se llama corrección de pruebas).
La idea del proyecto era expandir el corrector ortográfico estándar IntelliJ IDEA a la escala de Grammarly, para hacer una especie de Grammarly dentro de IDE.
Puede ver lo que sucedió
haciendo clic en el enlace .
Bueno, a continuación hablaremos más sobre las capacidades del complemento, así como sobre las dificultades que surgieron durante su creación.
MotivaciónExisten muchos productos diseñados para escribir textos en lenguajes naturales, pero la documentación y los comentarios sobre el código se escriben con mayor frecuencia en entornos de desarrollo. Al mismo tiempo, los IDE hacen un gran trabajo al encontrar errores al escribir código, pero están mal adaptados para textos en lenguajes naturales. Debido a esto, es muy fácil cometer errores de gramática, puntuación o estilo, y el entorno de desarrollo no los señalará. Es muy importante cometer un error al escribir la interfaz de usuario, ya que esto afectará no solo la comprensión del código, sino también los usuarios de la aplicación desarrollada.
Uno de los entornos de desarrollo más populares y desarrollados es IntelliJ IDEA, así como IDE basados en la plataforma IntelliJ. La plataforma IntelliJ ya tiene un corrector ortográfico incorporado, sin embargo, no guarda ni siquiera los errores gramaticales más simples. Decidimos integrar uno de los populares sistemas de análisis de lenguaje natural en IntelliJ IDEA.
Implementación
No nos propusimos la tarea de crear nuestro propio sistema para verificar textos, por lo que aprovechamos la solución existente. La opción más adecuada era
LanguageTool . La licencia nos permitió usarlo libremente para nuestros fines: es gratuito, está escrito en Java y se presenta en código abierto. Además, admite 25 idiomas y se ha desarrollado durante más de quince años. A pesar de su apertura, LanguageTool es un serio competidor de las soluciones de verificación de texto de pago, y el hecho de que pueda trabajar localmente es, literalmente, su característica principal.
El código del complemento está en el
repositorio en GitHub . Todo el proyecto fue escrito en Kotlin con una pequeña adición de Java para la interfaz de usuario. Durante el hackathon, logró implementar soporte para Markdown, JavaDoc, HTML y Texto sin formato. Después del hackathon, una gran actualización agregó soporte para XML, literales de cadena en Java, Kotlin y Python, así como la corrección ortográfica.
DificultadesMuy rápidamente, nos dimos cuenta de que si alimentamos todo el texto cada vez para la verificación de LanguageTool, entonces la interfaz IDEA se colgará en textos más o menos serios, ya que la inspección en sí misma bloquea el flujo de la interfaz de usuario. El problema se resolvió comprobando el `ProgressManager.checkCancelled`: esta función arroja una excepción si IDEA considera que la inspección debe cancelarse.
Esto eliminó por completo los bloqueos, pero es imposible usarlo: el texto ha sido procesado durante mucho tiempo. Además, en nuestro caso, la mayoría de las veces una parte muy pequeña del texto cambia y quiero de alguna manera almacenar en caché los resultados. Eso es lo que hicimos. Para no verificar todo cada vez, separamos determinísticamente el texto en pedazos y verificamos solo aquellos que cambiaron. Como los textos pueden ser grandes y no querían cargar el caché, no almacenamos los textos en sí, sino sus hashes. Esto permitió que el complemento funcionara sin problemas incluso en archivos grandes.
LanguageTool admite más de 25 idiomas, pero casi ningún usuario los necesita a todos. Quería dar la oportunidad de descargar bibliotecas para un idioma específico a pedido (si lo marca una marca en la interfaz de usuario). Incluso implementamos esto, pero resultó demasiado complicado y poco confiable. En particular, tuvimos que cargar LanguageTool con un nuevo conjunto de idiomas como un cargador de clases separado y luego inicializarlo cuidadosamente. Al mismo tiempo, todas las bibliotecas estaban en el repositorio de usuario .m2, y en cada inicio tuvimos que verificar su integridad. Al final, decidimos que si los usuarios tenían problemas con el tamaño del complemento, proporcionaríamos un complemento separado para varios de los idiomas más populares.
Después de hackathonEl hackatón terminó, pero el trabajo en el complemento continuó con una composición más estrecha. Quería admitir líneas, comentarios e incluso construcciones de lenguaje, como nombres de variables y clases. Actualmente, esto solo es compatible con Java, Kotlin y Python, pero esperamos que esta lista crezca. Solucionamos muchos errores pequeños y nos volvimos más compatibles con el corrector ortográfico incorporado Idea. Además, han aparecido soporte XML y corrección ortográfica. Todo esto se puede encontrar en la segunda versión que publicamos recientemente.
Que sigueTal complemento puede ser útil no solo para desarrolladores, sino también para escritores técnicos (a menudo trabajando, por ejemplo, con XML en el IDE). Todos los días tienen que trabajar con el lenguaje natural, sin tener un asistente en forma de consejos del editor sobre posibles errores. Nuestro complemento proporciona tales sugerencias y lo hace con un alto grado de precisión.
Planeamos desarrollar el complemento agregando nuevos idiomas y explorando el enfoque general para organizar la validación de texto. En un futuro cercano, la implementación de perfiles de estilo (conjuntos de reglas que definen la guía de estilo para el texto, por ejemplo, "no escriba, por ejemplo, pero escriba el formulario completo"), expanda el diccionario y mejore la interfaz de usuario (en particular, queremos darle al usuario la capacidad de no solo ignorar la palabra, sino agregar él en el diccionario, indicando parte del discurso).