La primera parte del artículo sobre los conceptos básicos de PNL se puede leer
aquí . Hoy hablaremos sobre una de las tareas de PNL más populares: el reconocimiento de entidades con nombre (NER), y analizaremos en detalle la arquitectura de las soluciones a este problema.
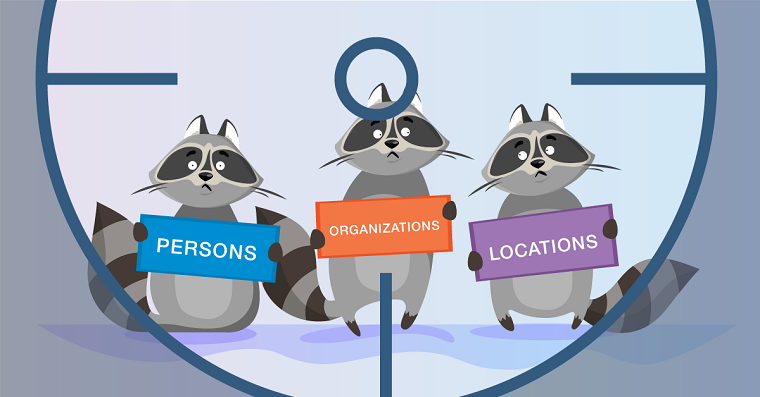
La tarea de NER es resaltar tramos de entidades en el texto (el lapso es un fragmento continuo de texto). Supongamos que hay un texto de noticias y queremos resaltar las entidades que contiene (algunos conjuntos preestablecidos, por ejemplo, personas, ubicaciones, organizaciones, fechas, etc.). La tarea del NER es comprender que la parte del texto "
1 de enero de 1997 " es la fecha, "
Kofi Annan " es la persona y "
ONU " es la organización.
¿Qué son las entidades nombradas? En el primer escenario clásico, que se formuló en la conferencia
MUC-6 en 1995, se trata de personas, ubicaciones y organizaciones. Desde entonces, han aparecido varios paquetes disponibles, cada uno de los cuales tiene su propio conjunto de entidades con nombre. Por lo general, se agregan nuevos tipos de entidad a personas, ubicaciones y organizaciones. Los más comunes son los numéricos (fechas, montos monetarios), así como las entidades misceláneas (de varios - otras entidades con nombre; un ejemplo es iPhone 6).
¿Por qué necesitas resolver el problema NER?
Es fácil entender que, incluso si somos capaces de identificar personas, ubicaciones y organizaciones en el texto, es poco probable que esto genere un gran interés entre los clientes. Aunque alguna aplicación práctica, por supuesto, tiene el problema en el entorno clásico.
Uno de los escenarios en los que aún puede ser necesaria una solución al problema en la formulación clásica es la estructuración de datos no estructurados. Supongamos que tiene algún tipo de texto (o un conjunto de textos), y los datos de este deben ingresarse en una base de datos (tabla). Las entidades con nombre clásico pueden corresponder a filas de dicha tabla o servir como contenido de algunas celdas. En consecuencia, para completar correctamente la tabla, primero debe seleccionar en el texto los datos que ingresará (generalmente después de esto hay otro paso: identificar las entidades en el texto, cuando entendemos que la
ONU y
las Naciones Unidas se extienden "Consulte la misma organización; sin embargo, la tarea de identificación o vinculación de la entidad es otra tarea, y no hablaremos de ello en detalle en esta publicación).
Sin embargo, hay varias razones por las cuales NER es una de las tareas de PNL más populares.
Primero, extraer entidades nombradas es un paso hacia la "comprensión" del texto. Esto puede tener un valor independiente y ayudar a resolver mejor otras tareas de PNL.
Entonces, si sabemos dónde se resaltan las entidades en el texto, entonces podemos encontrar fragmentos del texto que son importantes para alguna tarea. Por ejemplo, podemos seleccionar solo aquellos párrafos donde se encuentran entidades de cierto tipo, y luego trabajar solo con ellos.
Supongamos que recibe una carta, y sería bueno hacer un fragmento solo de esa parte donde hay algo útil, y no solo "
Hola, Ivan Petrovich ". Si puede distinguir entidades con nombre, puede hacer que el fragmento sea inteligente al mostrar esa parte de la carta donde se encuentran las entidades que nos interesan (y no solo mostrar la primera oración de la carta, como se hace a menudo). O simplemente puede resaltar en el texto las partes necesarias de la carta (o, directamente, las entidades que son importantes para nosotros) para la conveniencia de los analistas.
Además, las entidades son colocaciones rígidas y confiables; su selección puede ser importante para muchas tareas. Suponga que tiene un nombre para una entidad con nombre y, sea lo que sea, lo más probable es que sea continua, y todas las acciones con ella deben realizarse como con un solo bloque. Por ejemplo, traduzca el nombre de una entidad al nombre de una entidad. Desea traducir
"Pyaterochka Shop" al francés en una sola pieza, y no dividirlo en varios fragmentos que no están relacionados entre sí. La capacidad de detectar colocaciones también es útil para muchas otras tareas, por ejemplo, para el análisis sintáctico.
Sin resolver el problema NER, es difícil imaginar la solución a muchos problemas de PNL, por ejemplo, resolver el pronombre anáfora o construir sistemas de preguntas y respuestas. El pronombre anáfora nos permite entender a qué elemento del texto se refiere el pronombre. Por ejemplo, queramos analizar el texto "
Encantador galopado en un caballo blanco". La princesa salió corriendo a su encuentro y lo besó ". Si destacamos la esencia de Persona en la palabra "Encanto", entonces la máquina será mucho más fácil de entender que la princesa probablemente no besó al caballo, sino al príncipe de Encanto.
Ahora damos un ejemplo de cómo la asignación de entidades nombradas puede ayudar en la construcción de sistemas de preguntas y respuestas. Si hace la pregunta "
Quién interpretó el papel de Darth Vader en la película" El imperio contraataca " " en su motor de búsqueda favorito ", entonces con una alta probabilidad obtendrá la respuesta correcta. Esto se hace simplemente aislando entidades con nombre: seleccionamos las entidades (película, rol, etc.), entendemos lo que se nos pide y luego buscamos la respuesta en la base de datos.
Probablemente la consideración más importante debido a que la tarea NER es tan popular: la declaración del problema es muy flexible. En otras palabras, nadie nos obliga a seleccionar ubicaciones, personas y organizaciones. Podemos seleccionar cualquier texto continuo que necesitemos que sea algo diferente del resto del texto. Como resultado, puede elegir su propio conjunto de entidades para una tarea práctica específica proveniente del cliente, marcar el cuerpo de textos con este conjunto y capacitar al modelo. Tal escenario es omnipresente, y esto hace que NER sea una de las tareas de PNL más frecuentemente realizadas en la industria.
Daré un par de ejemplos de tales casos de clientes específicos, en cuya solución participé.
Aquí está el primero: le permite tener un conjunto de facturas (transferencias de dinero). Cada factura tiene una descripción de texto, que contiene la información necesaria sobre la transferencia (quién, quién, cuándo, qué y por qué motivo enviado). Por ejemplo, la compañía X transfirió $ 10 a la compañía Y en tal y tal fecha para tal y tal. El texto es bastante formal, pero está escrito en un lenguaje vivo. Los bancos tienen personas especialmente capacitadas que leen este texto y luego ingresan la información contenida en él en una base de datos.
Podemos seleccionar un conjunto de entidades que corresponden a las columnas de la tabla en la base de datos (nombres de compañías, cantidad de transferencia, su fecha, tipo de transferencia, etc.) y aprender cómo seleccionarlas automáticamente. Después de esto, solo queda ingresar las entidades seleccionadas en la tabla, y las personas que previamente leyeron los textos e ingresaron información en la base de datos podrán realizar tareas más importantes y útiles.
El segundo caso de usuario es este: necesita analizar cartas con pedidos de tiendas en línea. Para hacer esto, debe conocer el número de pedido (para que todas las letras relacionadas con este pedido puedan marcarse o colocarse en una carpeta separada), así como otra información útil: el nombre de la tienda, la lista de productos que se ordenaron, el monto del cheque, etc. Todo esto - números de pedido, nombres de tiendas, etc. - pueden considerarse entidades con nombre, y también es fácil aprender a distinguirlas utilizando los métodos que ahora analizaremos.
Si NER es tan útil, ¿por qué no se usa en todas partes?
¿Por qué la tarea NER no siempre se resuelve y los clientes comerciales todavía están dispuestos a pagar el dinero más pequeño por su solución? Parecería que todo es simple: comprender qué texto resaltar y resaltarlo.
Pero en la vida, no todo es tan fácil, surgen varias dificultades.
La complejidad clásica que nos impide vivir en la resolución de una variedad de problemas de PNL es todo tipo de ambigüedades en el lenguaje. Por ejemplo, palabras polisemánticas y homónimos (ver ejemplos en la
parte 1 ). Existe un tipo separado de homonimia que está directamente relacionado con la tarea NER: entidades completamente diferentes se pueden llamar la misma palabra. Por ejemplo, tengamos la palabra "
Washington ". Que es esto Persona, ciudad, estado, nombre de la tienda, nombre del perro, objeto, ¿algo más? Para resaltar esta sección del texto como una entidad específica, se debe tener mucho en cuenta: el contexto local (de qué se trataba el texto anterior), el contexto global (conocimiento sobre el mundo). Una persona tiene todo esto en cuenta, pero no es fácil enseñarle a una máquina a hacer esto.
La segunda dificultad es técnica, pero no la subestimes. No importa cómo defina la esencia, lo más probable es que haya algunos casos límite y difíciles: cuando necesita resaltar la esencia, cuando no necesita qué incluir en el tramo de la entidad y qué no, etc. (por supuesto, si nuestra esencia es no es algo ligeramente variable, como un correo electrónico; sin embargo, generalmente puede distinguir tales entidades triviales por métodos triviales: escriba una expresión regular y no piense en ningún tipo de aprendizaje automático).
Supongamos, por ejemplo, que queremos resaltar los nombres de las tiendas.
En el texto "La
tienda de detectores de metales profesionales le da la bienvenida ", es casi seguro que queremos incluir la palabra "tienda" en nuestra esencia, esto es claramente parte del nombre.
Otro ejemplo es "
Te da la bienvenida Volkhonka Prestige, tu tienda de marca favorita a precios asequibles ". Probablemente, la palabra "tienda" no debe incluirse en la anotación; esto claramente no es parte del nombre, sino simplemente su descripción. Además, si incluye esta palabra en el nombre, también debe incluir las palabras "- su favorito", y esto, tal vez, no quiero hacer nada.
El tercer ejemplo:
"La tienda de mascotas de Nemo te escribe "
. No está claro si la "tienda de mascotas" es parte del nombre o no. En este ejemplo, parece que cualquier elección será adecuada. Sin embargo, es importante que tengamos que hacer esta elección y corregirla en las instrucciones para los marcadores, de modo que en todos los textos tales ejemplos se marquen de manera equitativa (si esto no se hace, el aprendizaje automático inevitablemente comenzará a cometer errores debido a contradicciones en el marcado).
Existen muchos ejemplos de este tipo, y si queremos que el marcado sea consistente, todos ellos deben incluirse en las instrucciones para los marcadores. Incluso si los ejemplos en sí mismos son simples, deben tenerse en cuenta y calcularse, y esto hará que la instrucción sea más grande y más complicada.
Bueno, cuanto más complicadas sean las instrucciones, allí necesitarás marcadores más calificados. Una cosa es que el escriba necesita determinar si la letra es el texto del pedido o no (aunque aquí hay sutilezas y casos límite), y otra cosa es que el escriba necesita leer las instrucciones de 50 páginas, encontrar entidades específicas, entender qué incluir en anotación y qué no.
Los marcadores expertos son caros y, por lo general, no funcionan muy rápido. Seguramente gastará el dinero, pero no es un hecho que obtenga el margen de beneficio perfecto, porque si las instrucciones son complejas, incluso una persona calificada puede cometer un error y malinterpretar algo. Para combatir esto, se utiliza el marcado múltiple del mismo texto por diferentes personas, lo que aumenta aún más el precio de marcado y el tiempo para el que está preparado. Evitar este proceso o incluso reducirlo seriamente no funcionará: para aprender, debe tener un conjunto de capacitación de alta calidad de tamaños razonables.
Estas son las dos razones principales por las cuales NER aún no ha conquistado el mundo y por qué los manzanos aún no crecen en Marte.
Cómo entender si el problema NER se ha resuelto de manera de calidad
Le contaré un poco sobre las métricas que las personas usan para evaluar la calidad de su solución al problema NER y sobre los casos estándar.
La métrica principal para nuestra tarea es una estricta medida f. Explica qué es.
Tengamos un marcado de prueba (el resultado del trabajo de nuestro sistema) y un estándar (marcado correcto de los mismos textos). Entonces podemos contar dos métricas: precisión e integridad. La precisión es la fracción de entidades positivas verdaderas (es decir, entidades seleccionadas por nosotros en el texto, que también están presentes en el estándar), en relación con todas las entidades seleccionadas por nuestro sistema. Y la integridad es la fracción de entidades positivas verdaderas con respecto a todas las entidades presentes en el estándar. Un ejemplo de un clasificador muy preciso pero incompleto es un clasificador que selecciona un objeto correcto en el texto y nada más. Un ejemplo de un clasificador muy completo, pero generalmente inexacto, es un clasificador que selecciona una entidad en cualquier segmento del texto (por lo tanto, además de todas las entidades estándar, nuestro clasificador asigna una gran cantidad de basura).
La medida F es la media armónica de precisión e integridad, una métrica estándar.
Como describimos en la sección anterior, crear marcas es costoso. Por lo tanto, no hay muchos edificios accesibles con un marcado.
Existe cierta variedad para el idioma inglés: hay conferencias populares donde las personas compiten para resolver el problema NER (y se crea un marcado para las competiciones). Ejemplos de tales conferencias en las que se crearon sus cuerpos con entidades nombradas son MUC, TAC, CoNLL. Todos estos casos consisten casi exclusivamente en textos de noticias.
El cuerpo principal en el que se evalúa la calidad de la resolución del problema NER es el caso CoNLL 2003 (aquí hay un
enlace al caso en sí , aquí hay
un artículo al respecto ). Hay aproximadamente 300 mil tokens y hasta 10 mil entidades. Ahora los sistemas SOTA (estado del arte, es decir, los mejores resultados en este momento) muestran en este caso una medida f del orden de 0,93.
Para el idioma ruso, todo es mucho peor. Hay un organismo público (
FactRuEval 2016 , aquí hay
un artículo al respecto , aquí hay
un artículo sobre Habré ), y es muy pequeño: solo hay 50 mil tokens. En este caso, el caso es bastante específico. En particular, la esencia bastante controvertida de LocOrg (ubicación en un contexto organizacional) se destaca en el caso, que se confunde con las organizaciones y las ubicaciones, como resultado de lo cual la calidad de la selección de este último es menor de lo que podría ser.
Cómo resolver el problema NER
Reducción del problema de NER al problema de clasificación
A pesar del hecho de que las entidades a menudo son detalladas, la tarea NER generalmente se reduce al problema de clasificación a nivel de token, es decir, cada token pertenece a una de varias clases posibles. Hay varias formas estándar de hacer esto, pero la más común se llama esquema BIOES. El esquema consiste en agregar algún prefijo a la etiqueta de la entidad (por ejemplo, PER para personas u ORG para organizaciones), que indica la posición del token en el lapso de la entidad. Más detalles:
B, desde el comienzo de la palabra, el primer token en el lapso de la entidad, que consta de más de 1 palabra.
Yo, de las palabras dentro, esto es lo que está en el medio.
E: desde el final de la palabra, este es el último token de la entidad, que consta de más de 1 elemento.
S es soltero. Agregamos este prefijo si la entidad consta de una palabra.
Por lo tanto, agregamos uno de los 4 posibles prefijos a cada tipo de entidad. Si el token no pertenece a ninguna entidad, se marca con una etiqueta especial, generalmente etiquetada como OUT u O.
Damos un ejemplo. Tengamos el texto "
Karl Friedrich Jerome von Munchausen nació en Bodenwerder ". Aquí hay una entidad detallada: la persona "Karl Friedrich Jerome von Münhausen" y una de una palabra: la ubicación "Bodenwerder".
Por lo tanto, BIOES es una forma de mapear proyecciones de tramos o anotaciones al nivel de token.
Está claro que con este marcado podemos establecer inequívocamente los límites de todas las anotaciones de entidad. De hecho, sobre cada token, sabemos si es cierto que una entidad comienza con este token o termina en él, lo que significa si finalizar la anotación de la entidad en un token dado o extenderlo a los siguientes tokens.
La gran mayoría de los investigadores utilizan este método (o sus variaciones con menos etiquetas: BIOE o BIO), pero tiene varios inconvenientes importantes. La principal es que el esquema no permite trabajar con entidades anidadas o que se cruzan. Por ejemplo, la esencia de la "
Universidad Estatal de Moscú lleva el nombre de M.V. Lomonosov ”es una organización. Pero Lomonosov en sí mismo es una persona, y también sería bueno preguntar en el marcado. Usando el método de marcado descrito anteriormente, nunca podemos transmitir estos dos hechos al mismo tiempo (porque solo podemos hacer una marca en un token). En consecuencia, el token "Lomonosov" puede ser parte de la anotación de la organización, o parte de la anotación de la persona, pero nunca ambas al mismo tiempo.
Otro ejemplo de entidades integradas: "
Departamento de Lógica Matemática y Teoría de Algoritmos de la Facultad de Mecánica y Matemáticas de la Universidad Estatal de Moscú ". Aquí, idealmente, me gustaría distinguir 3 organizaciones anidadas, pero el método de marcado anterior le permite seleccionar 3 entidades disjuntas o una entidad que anota el fragmento completo.
Además de la forma estándar de reducir la tarea a la clasificación a nivel de token, también hay un formato de datos estándar en el que es conveniente almacenar el marcado para la tarea NER (así como para muchas otras tareas de PNL). Este formato se llama
CoNLL-U .
La idea principal del formato es esta: almacenamos los datos en forma de una tabla, donde una fila corresponde a un token, y las columnas corresponden a un tipo específico de atributos de token (incluida la palabra en sí, la forma de la palabra). En un sentido estricto, el formato CoNLL-U define qué tipos de características (es decir, columnas) se incluyen en la tabla, un total de 10 tipos de características para cada token. Pero los investigadores generalmente consideran que el formato es más amplio e incluyen los tipos de características que se necesitan para una tarea particular y un método para resolverlo.
A continuación se muestra un ejemplo de datos en un formato tipo CoNLL-U, donde se consideran 6 tipos de atributos: número de la oración actual en el texto, forma de la palabra (es decir, la palabra en sí), lema (forma de la palabra inicial), etiqueta POS (parte del discurso), morfológico características de la palabra y, finalmente, la etiqueta de la entidad asignada en este token.

¿Cómo resolviste el problema NER antes?
Estrictamente hablando, el problema se puede resolver sin aprendizaje automático, con la ayuda de sistemas basados en reglas (en la versión más simple, con la ayuda de expresiones regulares). Esto parece anticuado e ineficaz, sin embargo, debe comprender si su área temática es limitada y está claramente definida y si la entidad, por sí misma, no tiene mucha variabilidad, entonces el problema NER se resuelve utilizando métodos basados en reglas de manera bastante rápida y eficiente.
, (, ), , .
, ( ), . .
, 2000- SOTA . , .
, — . . . , ( ), 1, 0.
, (POS-), ( — , , ), (. . ), (, ), .
, , :
- “ , ”,
- “ ”,
- “ ”,
- “ ” ( , , “iPhone”).
, , - , — .
, – . , , , – , , , – , , , – . , (“” , “” — ), . , , , — ( , NER 2 — ).
, NER, ,
Nadeau and Sekine (2007), A survey of Named Entity Recognition and Classification . , , , ( - , , , HMM, , , , ), .
(summarized pattern ). NLP. , 2018
(word shape) .
NER ?
NLP almost from scratch
El primer intento exitoso de resolver el problema NER utilizando redes neuronales se realizó en 2011 .En el momento de la publicación de este artículo, mostró un resultado SOTA en el paquete CoNLL 2003. Pero debe comprender que la superioridad del modelo en comparación con los sistemas basados en algoritmos clásicos de aprendizaje automático era bastante insignificante. En los próximos años, los métodos basados en ML clásico mostraron resultados comparables a los métodos de redes neuronales.NER , , NLP . , , , , . , NER ( , NLP).
, .
, :
- «» (window based approach),
- (sentence based approach).
– , – , .. , .
: , “
The cat sat on the mat ”.
K (, , , , . .). (, , 1 ). Dejar

— , i- j- .
, sentence based approach , , — , . i i-core, core — , ( , , ).
—
, Lookup Table ( “” ). ,
Es un vector booleano en el que en un lugar cuesta 1, y en otros lugares es 0. Por lo tanto, al multiplicar en
, . .
( i 1 K) – , .
word2vec ( , word2vec, ) , , word2vec ( ).
, ,
en
.
Ahora entenderemos cómo se usan estos signos en el enfoque basado en oraciones (basado en ventanas es ideológicamente más simple). Es importante que lancemos nuestra arquitectura por separado para cada token (es decir, para la oración "El gato se sentó en el tapete", lanzaremos nuestra red 6 veces). Los signos en cada ejecución se recopilan de la misma manera, con la excepción del signo responsable de la posición del token cuya etiqueta estamos tratando de determinar: el token central.: 3-5. , , ( ). m f, m — , (. . ), f — .
, — max pooling (. . ), f. , , , core, (max pooling , , ). “ ” , , core.
Luego, pasamos el vector a través de un perceptrón multicapa con algunas funciones de activación (en el artículo - HardTanh), y como última capa usamos un softmax totalmente conectado de dimensión d, donde d es el número de posibles etiquetas de token.Por lo tanto, la capa convolucional nos permite recopilar la información contenida en la ventana de dimensión del filtro, agrupando - seleccionar la información más característica en la oración (comprimiéndola en un vector), y la capa softmax - nos permite determinar qué etiqueta tiene el token de número central.CharCNN-BLSTM-CRF
CharCNN-BLSTM-CRF, , SOTA 2016-2018 ( 2018 , NLP ; ). NER
Lample et al (2016) Ma & Hovy (2016) .
, NLP,
.
- . . – , – , — : , . . - .
. , , . — . Lookup- , , .
, .
, . — , , ( , ).
CharCNN ( , CharRNN). , - . - (, 20) — . , — , .
, , , , — ( ). - , .
2 .
– ( CharCNN). , sentence based approach .
, (, 3), . max pooling, 1 . .
– (BLSTM BiGRU; ,
). RNN.
, - . - .
BLSTM BiGRU. i- , RNN. ( RNN), ( RNN). - .
NLP, NLP.
, , NER. - , . .
– softmax d, d — . ( ).
, — . BiRNN, , . , I-PER B-PER I-PER.
— CRF (conditional random fields). , (
), , CRF , .
, CharCNN-BLSTM-CRF, SOTA NER 2018 .
. CharCNN f- 1%, CRF — 1-1.5%, ( multi-task learning,
Wu et al (2018) ). BiRNN — , , ,
.
, NER. , , .
,
NLP Advanced Research Group