Recientemente, en el grupo de reconocimiento ABBYY, estamos utilizando cada vez más las redes neuronales en diversas tareas. Muy bien, se han probado principalmente para tipos complejos de escritura. En publicaciones anteriores, hablamos sobre cómo usamos las redes neuronales para reconocer los scripts japoneses, chinos y coreanos.
 Publicación sobre reconocimiento de caracteres japoneses y chinos Mensaje de reconocimiento de caracteres coreanos
Publicación sobre reconocimiento de caracteres japoneses y chinos Mensaje de reconocimiento de caracteres coreanosEn ambos casos, utilizamos redes neuronales para reemplazar completamente el método de clasificación para un solo símbolo. Todos los enfoques incluían muchas redes diferentes, y algunas de las tareas incluían la necesidad de trabajar adecuadamente en imágenes que no son símbolos. El modelo en estas situaciones debería indicar de alguna manera que no somos un símbolo. Hoy solo hablaremos de por qué esto puede ser necesario en principio, y acerca de los enfoques que se pueden utilizar para lograr el efecto deseado.
Motivación
Cual es el problema ¿Por qué trabajar en imágenes que no son caracteres separados? Parece que puede dividir un fragmento de una cadena en caracteres, clasificarlos a todos y recopilar el resultado de esto, como, por ejemplo, en la imagen a continuación.
Sí, específicamente en este caso, esto realmente se puede hacer. Pero, por desgracia, el mundo real es mucho más complicado, y en la práctica, al reconocer, hay que lidiar con distorsiones geométricas, desenfoques, manchas de café y otras dificultades.
Como resultado, a menudo tiene que trabajar con dichos fragmentos:
Creo que es obvio para todos cuál es el problema. Según dicha imagen de un fragmento, no es tan simple dividirlo sin ambigüedades en símbolos separados para reconocerlos individualmente. Tenemos que presentar un conjunto de hipótesis sobre dónde están los límites entre los personajes y dónde están los personajes. Para esto, utilizamos el llamado gráfico de división lineal (GLD). En la imagen de arriba, este gráfico se muestra en la parte inferior: los segmentos verdes son los arcos del GLD construido, es decir, las hipótesis sobre dónde se encuentran los símbolos individuales.
Por lo tanto, algunas de las imágenes para las que se inicia el módulo de reconocimiento de caracteres individuales no son, de hecho, caracteres individuales, sino errores de segmentación. Y este mismo módulo debería indicar que, frente a él, lo más probable es que no sea un símbolo, devolviendo poca confianza para todas las opciones de reconocimiento. Y si esto no sucede, al final, se puede elegir la opción incorrecta para segmentar este fragmento por símbolos, lo que aumentará en gran medida el número de errores de división lineal.
Además de los errores de segmentación, el modelo también debe ser resistente a la basura a priori de la página. Por ejemplo, aquí también se pueden enviar imágenes para reconocer un solo carácter:
Si simplemente clasifica tales imágenes en caracteres separados, los resultados de la clasificación caerán en los resultados del reconocimiento. Además, de hecho, estas imágenes son simplemente artefactos del algoritmo de binarización, nada debería corresponderles en el resultado final. Entonces, para ellos, también debe ser capaz de devolver una baja confianza en la clasificación.
Todas las imágenes similares: errores de segmentación, basura a priori, etc. en lo sucesivo seremos llamados ejemplos negativos. Las imágenes de símbolos reales se denominarán ejemplos positivos.
El problema del enfoque de red neuronal
Ahora recordemos cómo funciona una red neuronal normal para reconocer caracteres individuales. Por lo general, se trata de algún tipo de capas convolucionales y totalmente conectadas, con la ayuda de las cuales se forma el vector de probabilidades de pertenecer a cada clase en particular a partir de la imagen de entrada.
Además, el número de clases coincide con el tamaño del alfabeto. Durante el entrenamiento de la red neuronal, se sirven imágenes de símbolos reales y se les enseña a devolver una alta probabilidad para la clase de símbolos correcta.
¿Y qué sucederá si una red neuronal se alimenta con errores de segmentación y basura a priori? De hecho, puramente teóricamente, cualquier cosa puede suceder, porque la red no vio esas imágenes en absoluto en el proceso de aprendizaje. Para algunas imágenes, puede ser afortunado, y la red devolverá una baja probabilidad para todas las clases. Pero en algunos casos, la red puede comenzar a buscar entre la basura en la entrada los contornos familiares de un determinado símbolo, por ejemplo, el símbolo "A" y reconocerlo con una probabilidad de 0,99.
En la práctica, cuando trabajamos, por ejemplo, en un modelo de red neuronal para la escritura japonesa y china, el uso de probabilidad cruda de la salida de la red condujo a la aparición de una gran cantidad de errores de segmentación. Y, a pesar del hecho de que el modelo simbólico funcionó muy bien sobre la base de imágenes, no fue posible integrarlo en el algoritmo de reconocimiento completo.
Alguien puede preguntar: ¿por qué exactamente con las redes neuronales surge tal problema? ¿Por qué los clasificadores de atributos no funcionaron de la misma manera, porque también estudiaron sobre la base de imágenes, lo que significa que no hubo ejemplos negativos en el proceso de aprendizaje?
La diferencia fundamental, en mi opinión, está en cómo se distinguen exactamente los signos de las imágenes de símbolos. En el caso del clasificador habitual, una persona misma prescribe cómo extraerlos, guiada por algún conocimiento de su dispositivo. En el caso de una red neuronal, la extracción de características también es una parte entrenada del modelo: están configuradas para que sea posible distinguir los personajes de diferentes clases de la mejor manera. Y en la práctica, resulta que las características descritas por una persona son más resistentes a las imágenes que no son símbolos: es menos probable que sean las mismas que las imágenes de símbolos reales, lo que significa que se les puede devolver un valor de confianza más bajo.
Mejora de la estabilidad del modelo con pérdida central
Porque El problema, según nuestras sospechas, era cómo la red neuronal selecciona los signos. Decidimos intentar mejorar esta parte en particular, es decir, aprender a resaltar algunos signos "buenos". En el aprendizaje profundo, hay una sección separada dedicada a este tema, y se llama "Aprendizaje de representación". Decidimos probar varios enfoques exitosos en esta área. La mayoría de las soluciones fueron propuestas para la formación de representaciones en problemas de reconocimiento facial.
El enfoque descrito en el artículo "
Un enfoque de aprendizaje de características discriminatorias para el reconocimiento facial profundo " parecía bastante bueno. La idea principal de los autores: agregar un término adicional a la función de pérdida, lo que reducirá la distancia euclidiana en el espacio de características entre elementos de la misma clase.
Para varios valores del peso de este término en la función de pérdida general, se pueden obtener varias imágenes en los espacios de atributos:
Esta figura muestra la distribución de los elementos de una muestra de prueba en un espacio de atributos bidimensionales. Se considera el problema de clasificar números escritos a mano (muestra MNIST).
Una de las propiedades importantes que establecieron los autores: un aumento en la capacidad de generalización de las características obtenidas para las personas que no estaban en el conjunto de entrenamiento. Los rostros de algunas personas todavía estaban ubicados cerca, y los rostros de diferentes personas estaban muy separados.
Decidimos comprobar si se conserva una propiedad similar para la selección de personajes. En este caso, se guiaron por la siguiente lógica: si en el espacio de características todos los elementos de la misma clase se agrupan de manera compacta cerca de un punto, entonces es menos probable que los signos de ejemplos negativos se ubiquen cerca del mismo punto. Por lo tanto, como criterio principal para el filtrado, utilizamos la distancia euclidiana al centro estadístico de una clase en particular.
Para probar la hipótesis, realizamos el siguiente experimento: entrenamos modelos para reconocer un pequeño subconjunto de caracteres japoneses de alfabetos silábicos (el llamado kana). Además de la muestra de entrenamiento, también examinamos 3 bases artificiales de ejemplos negativos:
- Pares: un conjunto de pares de caracteres europeos
- Cortes: fragmentos de líneas japonesas cortadas en espacios, no caracteres
- No kana: otros caracteres del alfabeto japonés que no están relacionados con el subconjunto considerado
Queríamos comparar el enfoque clásico con la función de pérdida de entropía cruzada y el enfoque con la pérdida central en su capacidad para filtrar ejemplos negativos. Los criterios de filtrado para ejemplos negativos fueron diferentes. En el caso de la pérdida de entropía cruzada, utilizamos la respuesta de red de la última capa, y en el caso de la pérdida de centro, utilizamos la distancia euclidiana al centro estadístico de la clase en el espacio de atributos. En ambos casos, elegimos el umbral de las estadísticas correspondientes, en el que no se elimina más del 3% de los ejemplos positivos de la muestra de prueba y observamos la proporción de ejemplos negativos de cada base de datos que se elimina en este umbral.

Como puede ver, el enfoque de pérdida de centro realmente hace un mejor trabajo al filtrar ejemplos negativos. Además, en ambos casos, no teníamos imágenes de ejemplos negativos en el proceso de aprendizaje. Esto es realmente muy bueno, porque en el caso general, obtener una base representativa de todos los ejemplos negativos en el problema de OCR no es una tarea fácil.
Aplicamos este enfoque al problema de reconocer los caracteres japoneses (en el segundo nivel de un modelo de dos niveles), y el resultado nos complació: el número de errores de división lineal se redujo significativamente. Aunque los errores permanecieron, ya podrían clasificarse por tipos específicos: ya sea pares de números o jeroglíficos con un símbolo de puntuación atascado. Para estos errores, ya era posible formar una base sintética de ejemplos negativos y usarla en el proceso de aprendizaje. Sobre cómo se puede hacer esto, y se discutirá más a fondo.
Usando la base de ejemplos negativos en el entrenamiento
Si tiene una colección de ejemplos negativos, entonces es una tontería no usarlo en el proceso de aprendizaje. Pero pensemos cómo se puede hacer esto.
Primero, considere el esquema más simple: agrupamos todos los ejemplos negativos en una clase separada y agregamos otra neurona a la capa de salida correspondiente a esta clase. Ahora en la salida tenemos una distribución de probabilidad para la clase
N + 1 . Y enseñamos esto la pérdida de entropía cruzada habitual.
El criterio de que el ejemplo es negativo puede considerarse el valor de la nueva respuesta de red correspondiente. Pero a veces los personajes reales de muy baja calidad pueden clasificarse como ejemplos negativos. ¿Es posible hacer la transición entre ejemplos positivos y negativos más suave?
De hecho, puede intentar no aumentar el número total de resultados, sino simplemente hacer que el modelo, al aprender, devuelva respuestas bajas para todas las clases al aplicar ejemplos negativos a la entrada. Para hacer esto, no podemos agregar explícitamente la salida de
N + 1st al modelo, sino simplemente agregar el valor de
–max de las respuestas para todas las demás clases al elemento
N + 1st . Luego, al aplicar ejemplos negativos a la entrada, la red intentará hacer todo lo posible, lo que significa que la respuesta máxima tratará de hacer lo menos posible.
Exactamente ese esquema lo aplicamos en el primer nivel de un modelo de dos niveles para los japoneses en combinación con el enfoque de pérdida central en el segundo nivel. Por lo tanto, algunos de los ejemplos negativos se filtraron en el primer nivel y otros en el segundo. En combinación, ya hemos logrado obtener una solución que está lista para integrarse en el algoritmo de reconocimiento general.
En general, también se puede preguntar: ¿cómo usar la base de ejemplos negativos en el enfoque con pérdida de centro? Resulta que de alguna manera necesitamos posponer los ejemplos negativos que se encuentran cerca de los centros estadísticos de las clases en el espacio de atributos. ¿Cómo poner esta lógica en la función de pérdida?
Dejar
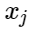
- signos de ejemplos negativos, y
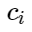
- centros de clases. Entonces podemos considerar la siguiente adición para la función de pérdida:
Aqui
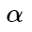
- un cierto espacio permitido entre el centro y los ejemplos negativos, dentro del cual se impone una penalización a los ejemplos negativos.
La combinación de Pérdida central con el aditivo descrito anteriormente, hemos aplicado con éxito, por ejemplo, para algunos clasificadores individuales en la tarea de reconocer los caracteres coreanos.
Conclusiones
En general, todos los enfoques para filtrar los llamados "ejemplos negativos" descritos anteriormente se pueden aplicar a cualquier problema de clasificación cuando se tiene una clase implícitamente altamente desequilibrada en relación con el resto sin una buena base de representantes, que sin embargo debe tenerse en cuenta de alguna manera . OCR es solo una tarea particular en la que este problema es más agudo.
Naturalmente, todos estos problemas surgen solo cuando se utilizan redes neuronales como modelo principal para reconocer caracteres individuales. Cuando se utiliza el reconocimiento de línea de extremo a extremo como un modelo completamente separado, tal problema no surge.
Grupo de Nuevas Tecnologías OCR