Antecedentes
En los últimos años, he participado en una gran cantidad de entrevistas. En cada una de ellas pregunté a los solicitantes sobre el principio de responsabilidad exclusiva (en adelante, SRP). Y la mayoría de la gente no sabe nada sobre el principio. E incluso de aquellos que podían leer la definición, casi nadie podía decir cómo usan este principio en su trabajo. No pudieron decir cómo SRP afecta el código que escriben o la revisión de código de sus colegas. Algunos de ellos también tenían la idea errónea de que SRP, como todo el SÓLIDO, solo es relevante para la programación orientada a objetos. Además, a menudo las personas no podían identificar casos obvios de violación de este principio, simplemente porque el código fue escrito en el estilo recomendado por el conocido marco.
Redux es un excelente ejemplo de un marco cuya directriz viola SRP.
SRP importa
Quiero comenzar con el valor de este principio, con los beneficios que trae. Y también quiero señalar que el principio se aplica no solo a OOP, sino también a la programación procesal, funcional e incluso declarativa. HTML, como representante de este último, puede y también debe descomponerse, especialmente ahora cuando está controlado por marcos de interfaz de usuario como React o Angular. Además, el principio se aplica a otras áreas de ingeniería. Y no solo en ingeniería, había tal expresión en temas militares: "divide y vencerás", que en general es la encarnación del mismo principio. La complejidad mata, divídela en partes y ganarás.
Con respecto a otras áreas de ingeniería, aquí en el centro, había un artículo interesante sobre cómo la aeronave que se estaba desarrollando con motores defectuosos, no cambió a marcha atrás al comando del piloto. El problema fue que malinterpretaron el estado del chasis. En lugar de confiar en los sistemas que controlan el chasis, el controlador del motor lee directamente los sensores, interruptores de límite, etc. ubicados en el chasis. También se mencionó en el artículo que el motor debe someterse a una larga certificación incluso antes de ser puesto en un prototipo de avión. Y la violación de SRP en este caso condujo claramente al hecho de que al cambiar el diseño del chasis, el código en el controlador del motor tenía que modificarse y volver a certificarse. Peor aún, una violación de este principio casi valió la pena el avión y la vida del piloto. Afortunadamente, nuestra programación diaria no amenaza tales consecuencias, sin embargo, aún no debe descuidar los principios de escribir un buen código. Y aquí está el por qué:
- La descomposición del código reduce su complejidad. Por ejemplo, si resolver un problema requiere que escriba un código con una complejidad ciclomática de cuatro, entonces el método responsable de resolver dos de estos problemas al mismo tiempo requerirá un código con complejidad 16. Si se divide en dos métodos, la complejidad total será 8. Por supuesto, esto no siempre es se reduce a la cantidad en contra del trabajo, pero la tendencia será aproximadamente la misma de todos modos.
- Las pruebas unitarias de código descompuesto se simplifican y son más eficientes.
- El código descompuesto crea menos resistencia al cambio. Al hacer cambios, es menos probable que cometa un error.
- El código se está estructurando mejor. Buscar algo en el código dispuesto en archivos y carpetas es mucho más fácil que en una gran tela.
- La separación del código repetitivo de la lógica empresarial lleva al hecho de que la generación de código se puede aplicar en un proyecto.
Y todos estos signos van juntos, estos son signos del mismo código. No tiene que elegir entre, por ejemplo, código bien probado y código bien estructurado.
Las definiciones existentes no funcionan
Una de las definiciones es: "debería haber una sola razón para cambiar el código (clase o función)". El problema con esta definición es que entra en conflicto con el principio Open-Close, el segundo del grupo de principios SOLID. Su definición: "el código debe estar abierto para la extensión y cerrado para el cambio". Una razón para el cambio versus la prohibición total del cambio. Si revelamos con más detalle lo que se quiere decir aquí, resulta que no hay conflicto entre los principios, pero definitivamente hay un conflicto entre las definiciones difusas.
La segunda definición más directa es: "el código debe tener una sola responsabilidad". El problema con esta definición es que es la naturaleza humana generalizar todo.
Por ejemplo, hay una granja que cría pollos, y en ese momento la granja tiene una sola responsabilidad. Y entonces se toma la decisión de criar patos allí también. Instintivamente, llamaremos a esto una granja avícola, en lugar de admitir que ahora hay dos responsabilidades. Agregue ovejas allí, y ahora esta es una granja de mascotas. Entonces queremos cultivar tomates u hongos allí, y encontrar el siguiente nombre aún más generalizado. Lo mismo se aplica a la "única razón" para el cambio. Esta razón puede ser tan generalizada como basta la imaginación.
Otro ejemplo es la clase de administrador de la estación espacial. No hace nada más, solo maneja la estación espacial. ¿Qué le parece esta clase con una responsabilidad?
Y, como mencioné a Redux cuando el solicitante de empleo está familiarizado con esta tecnología, también hago la pregunta: ¿viola un reductor SRP típico?
El reductor, recuerdo, incluye la declaración de cambio, y sucede que crece a decenas o incluso cientos de casos. Y la responsabilidad exclusiva del reductor es administrar las transiciones de estado de su aplicación. Es decir, literalmente, respondieron algunos solicitantes. Y ninguna pista podría mover esta opinión del suelo.
En total, si algún tipo de código parece satisfacer el principio SRP, pero al mismo tiempo huele desagradable, sepa por qué sucede esto. Porque la definición de "código debe tener una responsabilidad" simplemente no funciona.
Definición más apropiada
De prueba y error, tuve una mejor definición:
La responsabilidad del código no debe ser demasiado grandeSí, ahora necesita "medir" la responsabilidad de una clase o función. Y si es demasiado grande, entonces necesita dividir esta gran responsabilidad en varias responsabilidades más pequeñas. Volviendo al ejemplo de la granja, incluso la responsabilidad de criar pollos puede ser demasiado grande y tiene sentido separar de alguna manera a los pollos de engorde de las gallinas ponedoras, por ejemplo.
Pero, ¿cómo medirlo, cómo determinar que la responsabilidad de este código es demasiado grande?
Desafortunadamente, no tengo métodos matemáticamente precisos, solo métodos empíricos. Y, sobre todo, esto viene con experiencia, los desarrolladores novatos no son capaces de descomponer el código, los más avanzados son mejores para poseerlo, aunque no siempre pueden describir por qué lo hacen y cómo recae en teorías como SRP.
- Complejidad ciclomática métrica. Desafortunadamente, hay formas de enmascarar esta métrica, pero si la recopila, existe la posibilidad de que muestre los lugares más vulnerables en su aplicación.
- El tamaño de las funciones y clases. No es necesario leer una función de 800 líneas para comprender que algo está mal.
- Muchas importaciones. Una vez que abrí un archivo en el proyecto de un equipo vecino y vi una pantalla completa de importaciones, presioné la página hacia abajo y nuevamente solo había importaciones en la pantalla. Solo después de la segunda pulsación vi el comienzo del código. Puede decir que todos los IDE modernos pueden ocultar las importaciones bajo el "signo más", pero yo digo que un buen código no necesita ocultar los "olores". Además, necesitaba reutilizar un pequeño fragmento de código y lo eliminé de este archivo a otro, y una cuarta parte o incluso un tercio de las importaciones se movieron detrás de este fragmento. Este código claramente no pertenecía allí.
- Pruebas unitarias. Si aún tiene dificultades para determinar la cantidad de responsabilidad, obligarse a escribir pruebas. Si necesita escribir dos docenas de pruebas sobre el propósito principal de una función, sin contar los casos límite, etc., entonces se necesita descomposición.
- Lo mismo se aplica a demasiados pasos preparatorios al comienzo de la prueba y verificaciones al final. En Internet, por cierto, puede encontrar la declaración utópica de que el llamado Debe haber solo una afirmación en la prueba. Creo que cualquier idea arbitrariamente buena, elevada a lo absoluto, puede volverse absurdamente poco práctica.
- La lógica empresarial no debe depender directamente de herramientas externas. El controlador Oracle, las rutas Express, es deseable separar todo esto de la lógica empresarial y / u ocultarse detrás de las interfaces.
Un par de puntos:
Por supuesto, como ya mencioné, la moneda tiene un reverso, y 800 métodos en una línea pueden no ser mejores que un método en 800 líneas, debe haber un equilibrio en todo.
El segundo: no cubro la cuestión de dónde colocar este o aquel código de acuerdo con su responsabilidad. Por ejemplo, a veces los desarrolladores también tienen dificultades para introducir demasiada lógica en la capa DAL.
En tercer lugar, no propongo ningún límite específico como "no más de 50 líneas por función". Este enfoque implica solo una dirección para el desarrollo de desarrolladores, y quizás equipos. Él trabaja para mí, debe ganar dinero para los demás.
Y finalmente, si pasas por TDD, esto solo seguramente te hará descomponer el código mucho antes de que escribas esas 20 pruebas con 20 afirmaciones cada una.
Separar la lógica empresarial del código repetitivo
Hablando de las reglas del buen código, no puedes prescindir de ejemplos. El primer ejemplo es sobre la separación del código repetitivo.
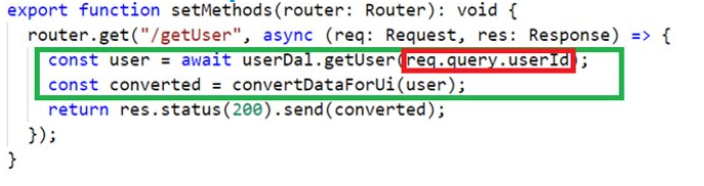
Este ejemplo demuestra cómo se suele escribir el código de fondo. Las personas generalmente escriben lógica inextricablemente con el código que indica los parámetros para el servidor web Express, como URL, método de solicitud, etc.
Marqué la lógica de negocios como el marcador verde y el código rojo intercalado que interactúa con los parámetros de consulta (rojo).
Siempre comparto estas dos responsabilidades de esta manera:

En este ejemplo, toda interacción con Express está en un archivo separado.
A primera vista, puede parecer que el segundo ejemplo no trajo mejoras, había 2 archivos en lugar de uno, aparecieron líneas adicionales, que no habían existido antes: el nombre de la clase y la firma del método. ¿Y entonces qué da esta separación de código? En primer lugar, el "punto de entrada de la aplicación" ya no es Express. Ahora esta es una función de mecanografía regular. O una función de JavaScript, ya sea C #, que escribe WebAPI sobre qué.
Esto, a su vez, le permite realizar varias acciones que no están disponibles en el primer ejemplo. Por ejemplo, puede escribir pruebas de comportamiento sin tener que aumentar Express, sin usar solicitudes http dentro de la prueba. E incluso no hay necesidad de humedecerlo, reemplace el objeto Router con su objeto de "prueba", ahora el código de la aplicación se puede llamar directamente desde la prueba.
Otra característica interesante proporcionada por esta descomposición es que ahora puede escribir un generador de código que analizará userApiService y generará un código que conecta este servicio con Express. En mis futuras publicaciones, planeo indicar lo siguiente: la generación de código no ahorrará tiempo en el proceso de escribir código. Los costos del generador de código no pagarán por el hecho de que ahora no es necesario copiar esta plantilla. La generación de código dará sus frutos por el hecho de que el código que produce no necesita soporte, lo que ahorrará tiempo y, lo más importante, los nervios de los desarrolladores a largo plazo.
Divide y vencerás
Este método de escribir código ha existido durante mucho tiempo, no lo inventé yo mismo. Acabo de llegar a la conclusión de que es muy conveniente al escribir lógica de negocios. Y para esto, se me ocurrió otro ejemplo ficticio, que muestra cómo puedes escribir rápida y fácilmente un código que se descompone inmediatamente y también se documenta por medio de métodos de nomenclatura.
Supongamos que recibe una tarea de un analista de negocios para hacer un método que envíe un informe de empleado a una compañía de seguros. Para hacer esto:
- Los datos deben tomarse de la base de datos.
- Convertir al formato deseado
- Enviar el informe resultante
Dichos requisitos no siempre se escriben explícitamente, a veces dicha secuencia puede estar implícita o aclarada a partir de una conversación con el analista. En el proceso de implementación del método, no se apresure a abrir conexiones a la base de datos o la red, en lugar de eso intente traducir este algoritmo simple al código "tal cual". Algo como esto:
async function sendEmployeeReportToProvider(reportId){ const data = await dal.getEmployeeReportData(reportId); const formatted = reportDataService.prepareEmployeeReport(data); await networkService.sendReport(formatted); }
Con este enfoque, resulta ser un código bastante simple, fácil de leer y probar, aunque creo que este código es trivial y no necesita prueba. Y era la responsabilidad de este método no enviar un informe, su responsabilidad era dividir esta tarea compleja en tres subtareas.
Luego, volvemos a los requisitos y descubrimos que el informe debe consistir en una sección de salario y una sección con horas trabajadas.
function prepareEmployeeReport(reportData){ const salarySection = prepareSalarySection(reportData); const workHoursSection = prepareWorkHoursSection(reportData); return { salarySection, workHoursSection }; }
Y así sucesivamente, continuamos dividiendo la tarea hasta la implementación de pequeños métodos que están cerca de lo trivial.
Interacción con el principio de abrir y cerrar
Al comienzo del artículo dije que las definiciones de los principios de SRP y Open-Close se contradicen entre sí. El primero dice que debe haber una razón para el cambio, el segundo dice que el código debe estar cerrado para el cambio. Y los principios en sí mismos, no solo no se contradicen entre sí, sino que funcionan en sinergia entre sí. Los 5 principios SÓLIDOS están dirigidos a un buen objetivo: decirle al desarrollador qué código es "malo" y cómo cambiarlo para que se vuelva "bueno". La ironía: acabo de reemplazar 5 responsabilidades con una responsabilidad más.
Entonces, además del ejemplo anterior con el envío del informe a la compañía de seguros, imagine que un analista de negocios se nos acerca y dice que ahora necesitamos agregar una segunda funcionalidad al proyecto. Se debe imprimir el mismo informe.
Imagine que hay un desarrollador que cree que SRP "no se trata de descomposición".
En consecuencia, este principio no le indicó la necesidad de descomposición, y se dio cuenta de la primera tarea completa en una función. Después de que le llegó la tarea, combina las dos responsabilidades en una sola, porque tienen mucho en común y generaliza su nombre. Ahora esta responsabilidad se llama "informe de servicio". La implementación de esto se parece a esto:
async function serveEmployeeReportToProvider(reportId, serveMethod){ switch(serveMethod) { case sendToProvider: case print: default: throw; } }
¿Recuerda algún código en su proyecto? Como dije, ambas definiciones directas de SRP no funcionan. No transmiten información al desarrollador de que dicho código no se puede escribir. Y qué código se puede escribir. Todavía había una sola razón para que el desarrollador cambiara este código. Simplemente volvió a llamar a la razón anterior, agregó el interruptor y está tranquilo. Y aquí entra en escena el principio del principio Abrir-Cerrar, que dice directamente que era imposible modificar un archivo existente. Era necesario escribir código para que al agregar una nueva funcionalidad fuera necesario agregar un nuevo archivo y no editar uno existente. Es decir, dicho código es malo desde el punto de vista de dos principios a la vez. Y si el primero no ayudó a verlo, el segundo debería ayudar.
¿Y cómo el método divide y vencerás resuelve el mismo problema?
async function printEmployeeReport(reportId){ const data = await dal.getEmployeeReportData(reportId); const formatted = reportDataService.prepareEmployeeReport(data); await printService.printReport(formatted); }
Añadir una nueva función. A veces los llamo una "función de script" porque no llevan implementaciones, determinan la secuencia de llamar a piezas descompuestas de nuestra responsabilidad. Obviamente, las dos primeras líneas, las dos primeras responsabilidades descompuestas coinciden con las dos primeras líneas de la función implementada previamente. Al igual que los dos primeros pasos de dos tareas descritas por un analista de negocios coinciden.
Por lo tanto, para agregar una nueva funcionalidad al proyecto, agregamos un nuevo método de script y un nuevo servicio de impresión. Los archivos antiguos no fueron cambiados. Es decir, este método de escribir código es bueno desde el punto de vista de dos principios. Y SRP y Open-Close
Alternativa
También quería mencionar una forma alternativa y competitiva de obtener un código bien descompuesto que se parece a esto: primero escribimos el código "en la frente", luego lo refactorizamos usando varias técnicas, por ejemplo, de acuerdo con el libro "Refactorización" de Fowler. Estos métodos me recordaron el enfoque matemático del juego de ajedrez, donde no entiendes exactamente lo que estás haciendo en términos de estrategia, solo calculas el "peso" de tu posición y tratas de maximizarlo haciendo movimientos. No me gustó este enfoque por una pequeña razón: nombrar métodos y variables ya es difícil, y cuando no tienen un valor comercial, se vuelve imposible. Por ejemplo, si estas técnicas sugieren que necesita seleccionar 6 líneas idénticas de aquí y de allá, y luego resaltarlas, ¿cómo debería llamar a este método? someSixIdenticalLines ()?
Quiero hacer una reserva, no creo que este método sea malo, simplemente no pude aprender cómo usarlo.
Total
Al seguir el principio, puede encontrar beneficios.
La definición de "debe haber una responsabilidad" no funciona.
Hay una mejor definición y una serie de características indirectas, las llamadas los olores de código indican la necesidad de descomponerse.
El enfoque de "divide y vencerás" te permite escribir inmediatamente un código bien estructurado y autodocumentado.