Le sugiero que se familiarice con la transcripción del informe de Alexander Sigachev de Inventos "El proceso de desarrollo y prueba con Docker + Gitlab CI"
Aquellos que recién comienzan a implementar el proceso de desarrollo y prueba basado en Docker + Gitlab CI a menudo hacen preguntas básicas. Por donde empezar ¿Cómo organizarlo? ¿Cómo hacer la prueba?
Este informe es bueno para informarle de manera estructurada sobre el proceso de desarrollo y prueba utilizando Docker y Gitlab CI. Informe 2017 en sí. Creo que de este informe puede extraer los conceptos básicos, la metodología, la idea y la experiencia de uso.
A quién le importa, por favor, debajo del gato.
Me llamo Alexander Sigachev. Yo trabajo para Inventos. Le contaré sobre mi experiencia en el uso de Docker y cómo la estamos implementando gradualmente en proyectos en la empresa.
Tema: Proceso de desarrollo utilizando Docker y Gitlab CI.
Esta es mi segunda charla sobre Docker. En el momento del primer informe, utilizamos Docker solo en Desarrollo en máquinas de desarrollo. El número de empleados que usaron Docker fue de aproximadamente 2-3 personas. Poco a poco, se ganó experiencia y avanzamos un poco más. Enlace a nuestro primer informe .
¿Qué habrá en este informe? Compartiremos nuestra experiencia sobre qué rastrillo recolectamos, qué problemas resolvimos. No en todas partes era hermoso, pero se le permitió seguir adelante.
Nuestro lema es: dockerizar todo lo que alcanzan nuestras manos.
¿Qué problemas resolvemos?
Cuando una empresa tiene varios equipos, el programador es un recurso compartido. Hay etapas en las que un programador se retira de un proyecto y se entrega por algún tiempo a otro proyecto.
Para que el programador pueda profundizar rápidamente en él, necesita descargar el código fuente del proyecto y lanzar el entorno lo antes posible, lo que le permitirá avanzar más en la solución de los problemas de este proyecto.
Por lo general, si comienza desde cero, la documentación del proyecto no es suficiente. Solo los veteranos tienen información sobre cómo configurar. Los empleados configuran independientemente su lugar de trabajo en uno o dos días. Para acelerar esto, usamos Docker.
La siguiente razón es la estandarización de la configuración en Desarrollo. En mi experiencia, los desarrolladores siempre toman la iniciativa. En cada quinto caso, se ingresa un dominio personalizado, por ejemplo, vasya.dev. Cerca está la vecina Petya, cuyo dominio es petya.dev. Están desarrollando un sitio web o algún componente del sistema utilizando este nombre de dominio.
Cuando el sistema crece y estos nombres de dominio comienzan a caer en la configuración, entonces hay un conflicto de entornos de desarrollo y la ruta del sitio se reescribe.
Lo mismo sucede con la configuración de la base de datos. Alguien no se molesta con la seguridad y trabaja con una contraseña de root vacía. Alguien en la etapa de instalación MySQL exigió una contraseña y la contraseña resultó ser una 123. A menudo sucede que la configuración de la base de datos cambia constantemente dependiendo del compromiso del desarrollador. Alguien corrigió, alguien no corrigió la configuración. Hubo trucos cuando .gitignore algún tipo de configuración de prueba en .gitignore y cada desarrollador tenía que instalar una base de datos. Esto complica el proceso de inicio. Entre otras cosas, debe recordar acerca de la base de datos. Se debe inicializar la base de datos, se debe registrar una contraseña, se debe registrar un usuario, se debe crear una placa, etc.
Otro problema son las diferentes versiones de las bibliotecas. A menudo sucede que un desarrollador trabaja con diferentes proyectos. Hay un proyecto Legacy que comenzó hace cinco años (desde 2017 - nota. Ed.). Al principio, comenzamos con MySQL 5.5. También hay proyectos modernos en los que estamos tratando de introducir versiones más modernas de MySQL, por ejemplo 5.7 o más antiguas (en 2017 - nota. Ed.)
Cualquiera que trabaje con MySQL sabe que estas bibliotecas están obteniendo dependencias. Es bastante problemático correr 2 bases juntas. Como mínimo, es problemático para los clientes antiguos conectarse a la nueva base de datos. Esto a su vez causa varios problemas.
El siguiente problema es cuando el desarrollador trabaja en la máquina local, usa recursos locales, archivos locales, RAM local. Toda la interacción a la hora de desarrollar la solución al problema se lleva a cabo en el marco del hecho de que funciona en una máquina. Un ejemplo es cuando tenemos un servidor de back-end en Production 3, y el desarrollador guarda los archivos en el directorio raíz y desde allí nginx toma los archivos para responder a la solicitud. Cuando dicho código cae en Producción, resulta que el archivo está presente en uno de los 3 servidores.
Ahora se está desarrollando la dirección de los microservicios. Cuando dividimos nuestras aplicaciones grandes en algunos componentes pequeños que interactúan entre sí. Esto le permite seleccionar tecnología para una pila de tareas específica. También le permite compartir el trabajo y el área de responsabilidad entre los desarrolladores.
El desarrollador de Frondend, que se desarrolla en JS, prácticamente no afecta a Backend. El desarrollador de back-end, a su vez, desarrolla, en nuestro caso, Ruby on Rails y no interfiere con Frondend. La interacción se realiza utilizando la API.
Como beneficio adicional, con Docker pudimos utilizar recursos en la puesta en escena. Cada proyecto, debido a su especificidad, requería ciertas configuraciones. Físicamente, era necesario seleccionar un servidor virtual y configurarlos por separado, o compartir algún tipo de entorno variable, y los proyectos podrían influirse entre sí según la versión de las bibliotecas.

Herramientas Que utilizamos
- Directamente Docker en sí. Dockerfile describe las dependencias de una aplicación.
- Docker-compose es un paquete que reúne algunas de nuestras aplicaciones Docker.
- GitLab lo usamos para almacenar el código fuente.
- Utilizamos GitLab-CI para la integración del sistema.

El informe consta de dos partes.
La primera parte hablará sobre cómo ejecutar Docker en máquinas de desarrollo.
La segunda parte hablará sobre cómo interactuar con GitLab, cómo ejecutamos pruebas y cómo implementamos Staging.
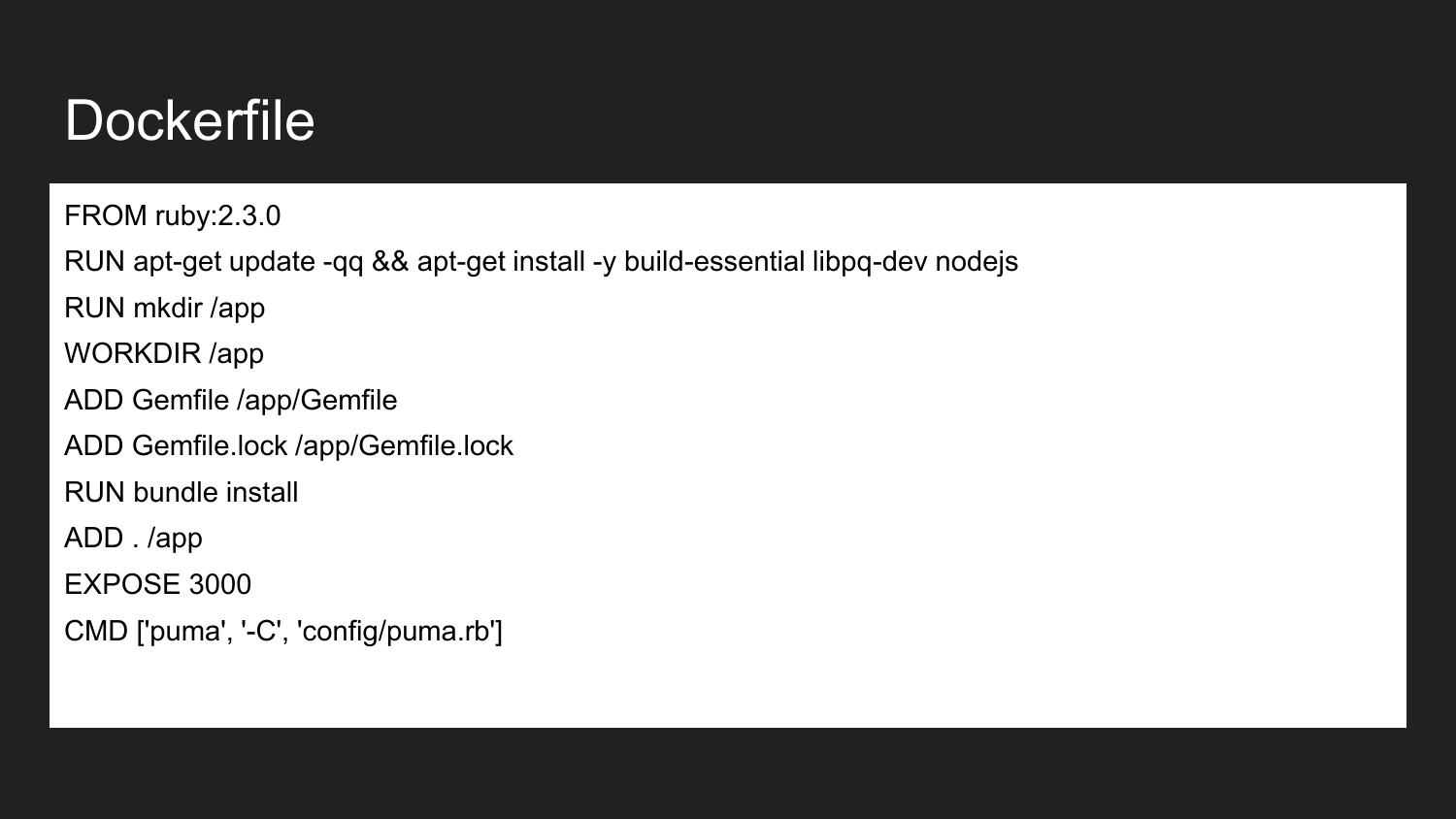
Docker es una tecnología que permite (utilizando un enfoque declarativo) describir los componentes necesarios. Este es un ejemplo de un Dockerfile. Aquí anunciamos que estamos heredando de la imagen oficial de Ruby Docker: 2.3.0. Contiene la versión 2.3 instalada de Ruby. Instalamos las bibliotecas de compilación necesarias y NodeJS. Describimos que creamos el directorio /app . Asigne el directorio de la aplicación al directorio de trabajo. En este directorio colocamos el mínimo Gemfile y Gemfile.lock necesarios. Luego construimos los proyectos que instalan esta imagen de dependencia. Indicamos que el contenedor estará listo para escuchar en el puerto externo 3000. El último comando es el comando que inicia directamente nuestra aplicación. Si ejecutamos el comando de inicio del proyecto, la aplicación intentará ejecutar y ejecutar el comando especificado.

Este es un ejemplo mínimo de un archivo docker-compose. En este caso, mostramos que hay una conexión entre los dos contenedores. Esto es directamente al servicio de base de datos y al servicio web. Nuestras aplicaciones web en la mayoría de los casos requieren algún tipo de base de datos como back-end para almacenar datos. Como usamos MySQL, el ejemplo es con MySQL, pero nada nos impide usar algún tipo de base de datos de amigos (PostgreSQL, Redis).
Tomamos la imagen MySQL 5.7.14 de la fuente oficial con el centro Docker sin cambios. La imagen que es responsable de nuestra aplicación web que recopilamos del directorio actual. Él, durante el primer lanzamiento, recopila una imagen para nosotros. Luego lanza el comando que ejecutamos aquí. Si volvemos, veremos que se ha definido el comando de lanzamiento a través de Puma. Puma es un servicio escrito en Ruby. En el segundo caso, redefinimos. Este comando puede ser arbitrario según nuestras necesidades o tareas.
También describimos lo que necesita para reenviar el puerto en nuestra máquina host del contenedor de 3000 a 3000 puertos. Esto se hace automáticamente usando iptables y su propio mecanismo, que está directamente integrado en Docker.
El desarrollador puede, como antes, aplicar a cualquier dirección IP disponible, por ejemplo, 127.0.0.1 dirección IP local o externa de la máquina.
La última línea dice que el contenedor web depende del contenedor db. Cuando llamamos al lanzamiento del contenedor web, docker-compose iniciará la base de datos por nosotros. Ya al comienzo de la base de datos (de hecho, ¡después de iniciar el contenedor! Esto no garantiza la disponibilidad de la base de datos), lanzaremos una aplicación, nuestro backend.
Esto le permite evitar errores cuando la base de datos no se genera y le permite ahorrar recursos cuando detenemos el contenedor de la base de datos, liberando los recursos para otros proyectos.

Lo que nos da el uso de la base de datos de dockerización en el proyecto. Todos los desarrolladores arreglamos la versión de MySQL. Esto le permite evitar algunos errores que pueden ocurrir cuando hay una divergencia de versiones, cuando la sintaxis, la configuración y la configuración predeterminada cambian. Esto le permite especificar un nombre de host común para la base de datos, inicio de sesión, contraseña. Nos alejamos de los nombres de zoológicos y conflictos en los archivos de configuración que eran anteriores.
Podemos usar una configuración más óptima para el entorno de Desarrollo, que será diferente de la predeterminada. MySQL está configurado de forma predeterminada en máquinas débiles y su rendimiento inmediato es muy bajo.

Docker le permite utilizar el intérprete Python, Ruby, NodeJS, PHP de la versión deseada. Nos libramos de la necesidad de utilizar algún tipo de administrador de versiones. Anteriormente, Ruby usaba el paquete rpm, que permitía cambiar la versión según el proyecto. Esto también permite que el contenedor Docker migre suavemente el código y lo versione junto con las dependencias. No tenemos problemas para entender la versión del intérprete y el código. Para actualizar la versión, baje el contenedor anterior y suba el nuevo contenedor. Si algo salió mal, podemos bajar el nuevo contenedor, levantar el viejo contenedor.
Después de ensamblar la imagen, los contenedores tanto en Desarrollo como en Producción serán los mismos. Esto es especialmente cierto para grandes instalaciones.
 En Frontend, usamos JavaScipt y NodeJS.
En Frontend, usamos JavaScipt y NodeJS.
Ahora tenemos el último proyecto en ReacJS. El desarrollador ejecutó todo el contenedor y lo desarrolló utilizando la recarga en caliente.
A continuación, se inicia la tarea de ensamblar JavaScipt y el código recopilado en las estadísticas se proporciona a través de recursos de ahorro nginx.
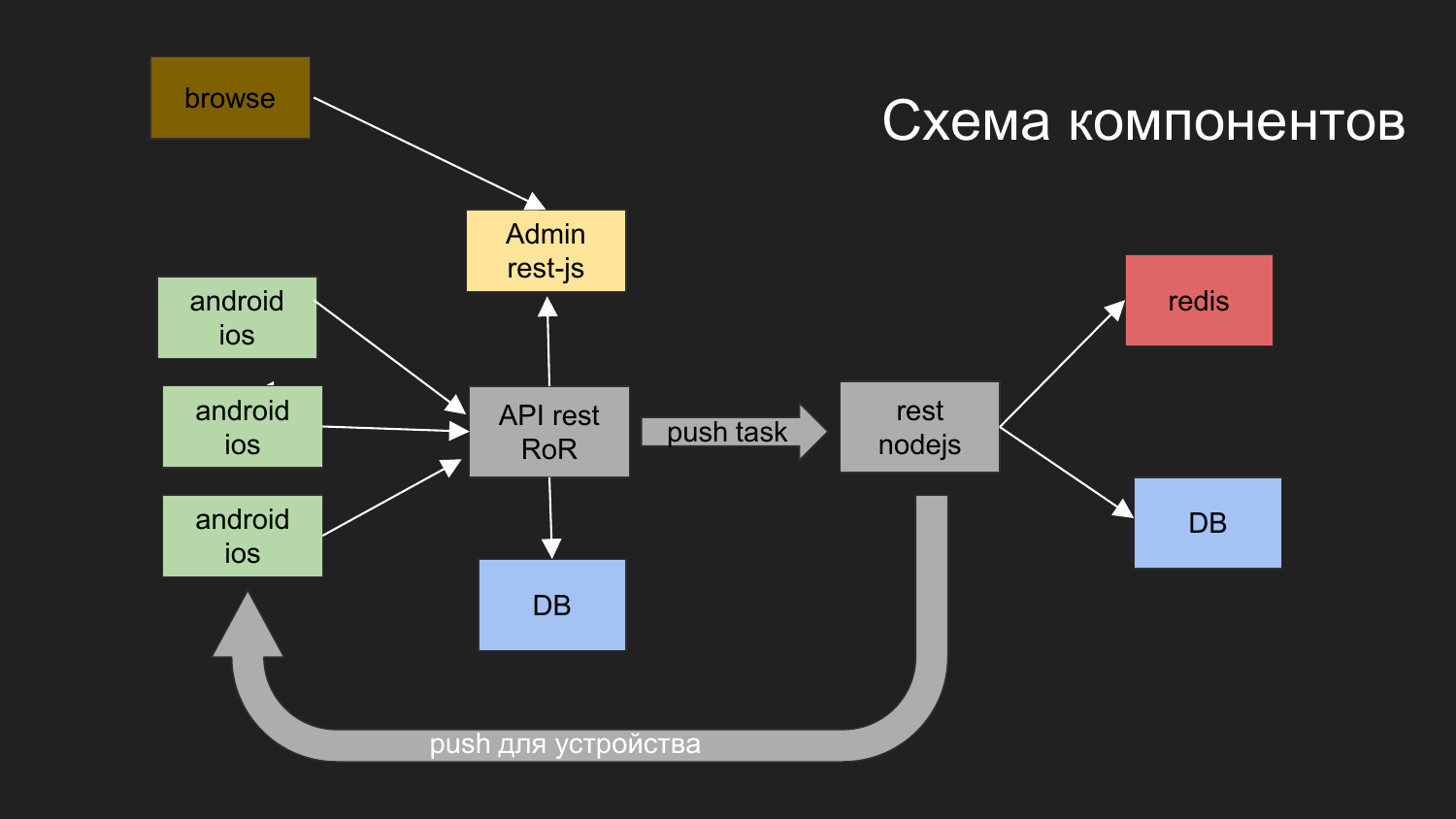
Aquí les di un diagrama de nuestro último proyecto.
¿Qué tareas resolviste? Tenemos la necesidad de construir un sistema con el que interactúen los dispositivos móviles. Obtienen datos. Una de las opciones es enviar notificaciones push a este dispositivo.
¿Qué hemos hecho para esto?
Nos dividimos en componentes de aplicación como: la parte de administración en JS, el backend, que funciona a través de la interfaz REST en Ruby on Rails. El backend interactúa con la base de datos. El resultado que se genera se entrega al cliente. El administrador con el backend y la base de datos interactúa a través de la interfaz REST.
También necesitábamos enviar notificaciones push. Antes de eso, teníamos un proyecto en el que se implementó un mecanismo que se encarga de entregar notificaciones a las plataformas móviles.
Desarrollamos dicho esquema: el operador del navegador interactúa con el panel de administración, el panel de administración interactúa con el backend, la tarea es enviar notificaciones Push.
Las notificaciones push interactúan con otro componente que se implementa en NodeJS.
Se están creando colas y luego el envío de notificaciones sigue su propio mecanismo.
Aquí se dibujan dos bases de datos. Por el momento, con la ayuda de Docker, utilizamos 2 bases de datos independientes, que de ninguna manera están conectadas entre sí. Además, tienen una red virtual común y los datos físicos se almacenan en diferentes directorios en la máquina del desarrollador.
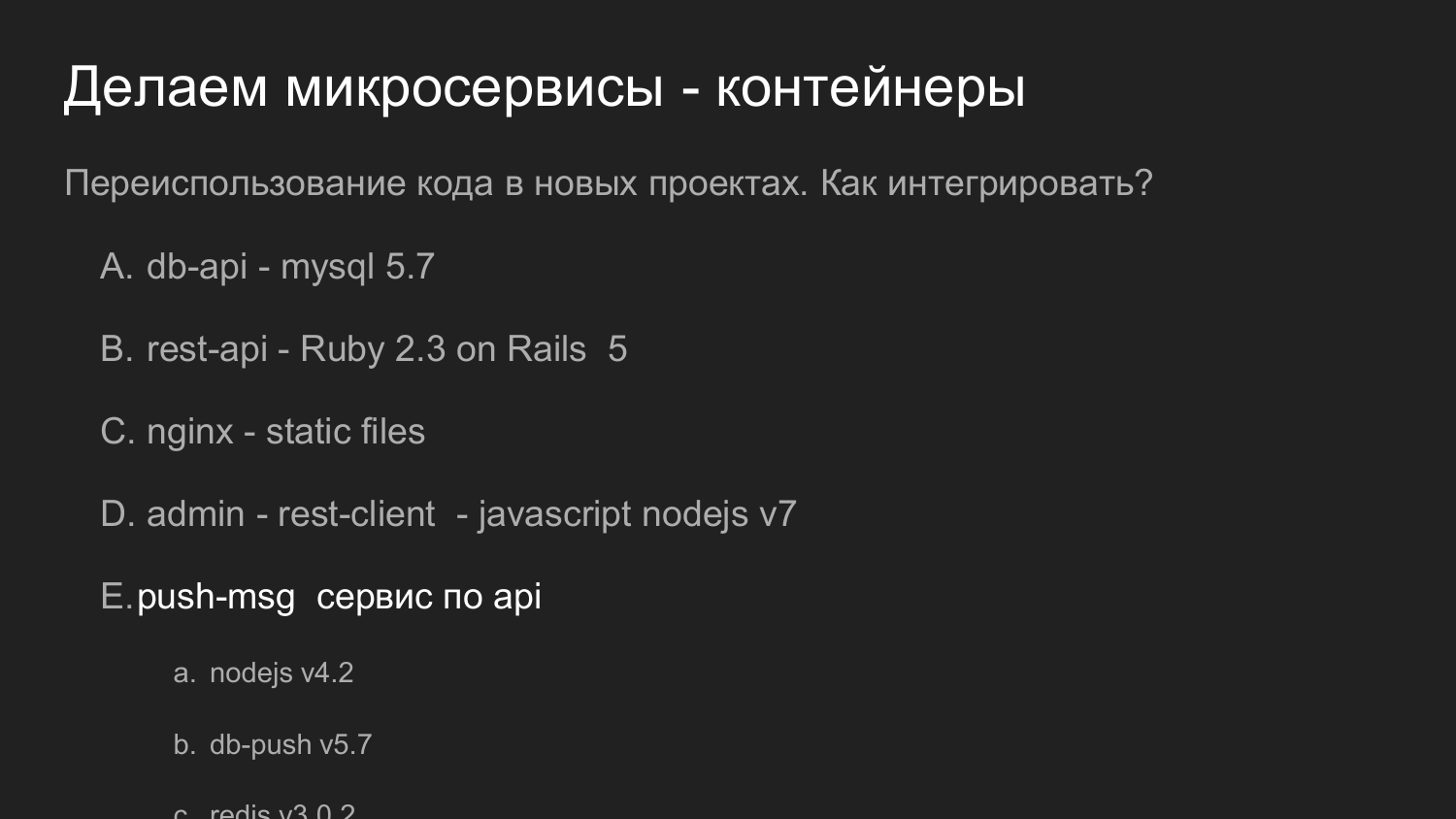
Lo mismo, pero en números. Reutilizar el código es importante aquí.
Si anteriormente hablamos sobre la reutilización de código en forma de bibliotecas, en este ejemplo, nuestro servicio, que responde a notificaciones push, se reutiliza como un servidor completo. Proporciona una API. Y ya con nuestro nuevo desarrollo interactúa con él.
En ese momento, utilizamos la versión 4 de NodeJS. Ahora (en 2017 - nota. Ed.) En desarrollos recientes utilizamos la versión 7 de NodeJS. No hay problema en nuevos componentes para atraer nuevas versiones de bibliotecas.
Si es necesario, puede refactorizar y actualizar la versión NodeJS del servicio de notificación Push.
Y si podemos mantener la compatibilidad de la API, podemos reemplazarla con otros proyectos que se utilizaron anteriormente.

¿Qué necesitas para agregar Docker? Agregue un Dockerfile a nuestro repositorio que describa las dependencias necesarias. En este ejemplo, los componentes se desglosan por lógica. Este es un conjunto mínimo de desarrolladores de back-end.
Al crear un nuevo proyecto, cree un Dockerfile, describa el ecosistema deseado (Python, Ruby, NodeJS). Docker-compose describe la dependencia necesaria: la base de datos. Describimos que necesitamos una base de datos de tal o cual versión, para almacenar los datos allí en algún lugar.
Usamos un tercer contenedor separado con nginx para representar estático. Puedes subir fotos. Backend los coloca en un volumen preparado previamente, que también se monta en un contenedor con nginx, que proporciona estática.
Para almacenar la configuración nginx, mysql, agregamos la carpeta Docker, en la que almacenamos las configuraciones necesarias. Cuando un desarrollador crea un repositorio git clone en su máquina, ya tiene un proyecto listo para el desarrollo local. La pregunta no surge sobre qué puerto o qué configuraciones aplicar.

Además, tenemos varios componentes: admin, inform-API, notificaciones push.
Para ejecutarlo todo, creamos otro repositorio llamado dockerized-app. Actualmente, utilizamos varios repositorios para cada componente. Simplemente difieren lógicamente: en GitLab parece una carpeta, y en la máquina del desarrollador, una carpeta para un proyecto específico. Un nivel a continuación son los componentes que se combinarán.
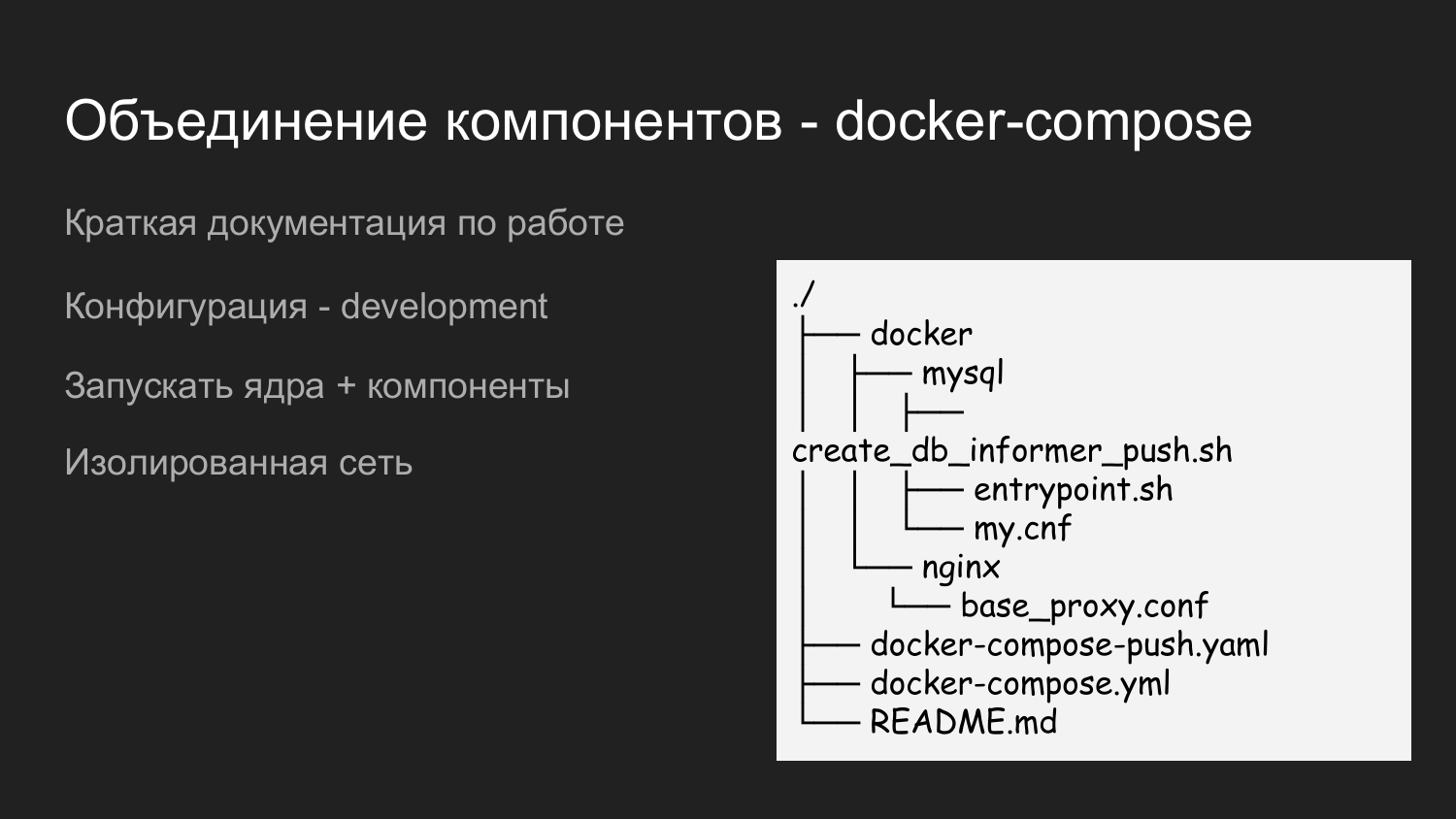
Este es un ejemplo de los contenidos de la aplicación dockerized. También traemos el catálogo de Docker aquí, en el que completamos las configuraciones necesarias para las interacciones de todos los componentes. Hay README.md, que describe brevemente cómo iniciar un proyecto.
Aquí usamos dos archivos docker-compose. Esto se hace para poder ejecutar en pasos. Cuando un desarrollador trabaja con el kernel, no necesita notificaciones Push, luego simplemente lanza el archivo de compilación de acoplador y, en consecuencia, se guarda el recurso.
Si existe la necesidad de integración con notificaciones push, se inician docker-compose.yaml y docker-compose-push.yaml.
Como docker-compose.yaml y docker-compose-push.yaml están en la carpeta, se crea automáticamente una única red virtual.
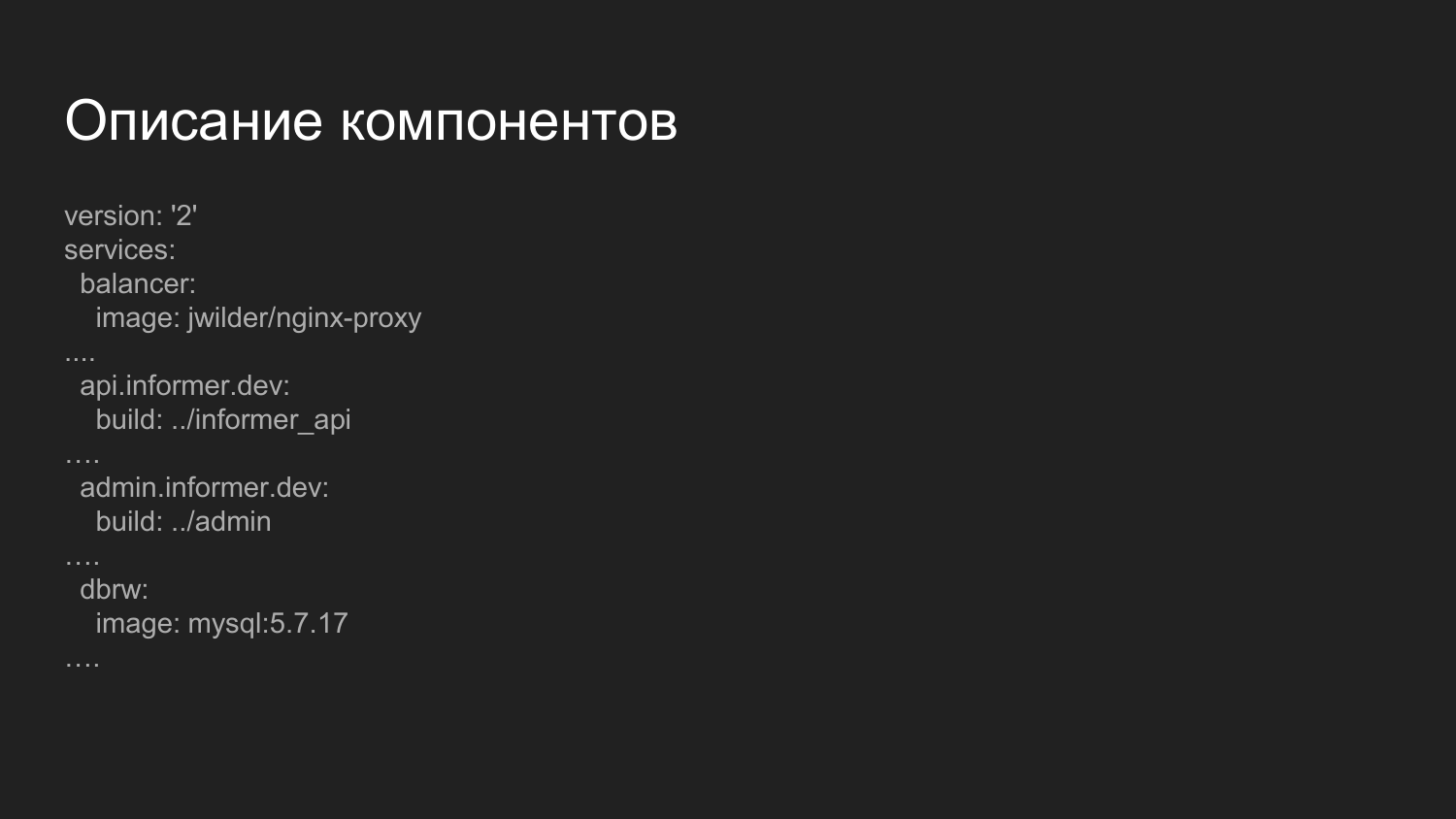
Descripción de los componentes. Este es un archivo más avanzado que se encarga de recopilar componentes. ¿Qué es notable aquí? Aquí presentamos el componente equilibrador.
Esta es una imagen Docker preparada en la que se inicia nginx y una aplicación que escucha el socket Docker. Dinámico, a medida que los contenedores se encienden y apagan, la configuración de nginx se volverá a generar. Distribuimos el manejo de componentes por nombres de dominio de tercer nivel.
Para el entorno de desarrollo, utilizamos el dominio .dev - api.informer.dev. Las aplicaciones con el dominio .dev están disponibles en la máquina del desarrollador local.
Luego, las configuraciones se transfieren a cada proyecto y todos los proyectos se lanzan juntos al mismo tiempo.
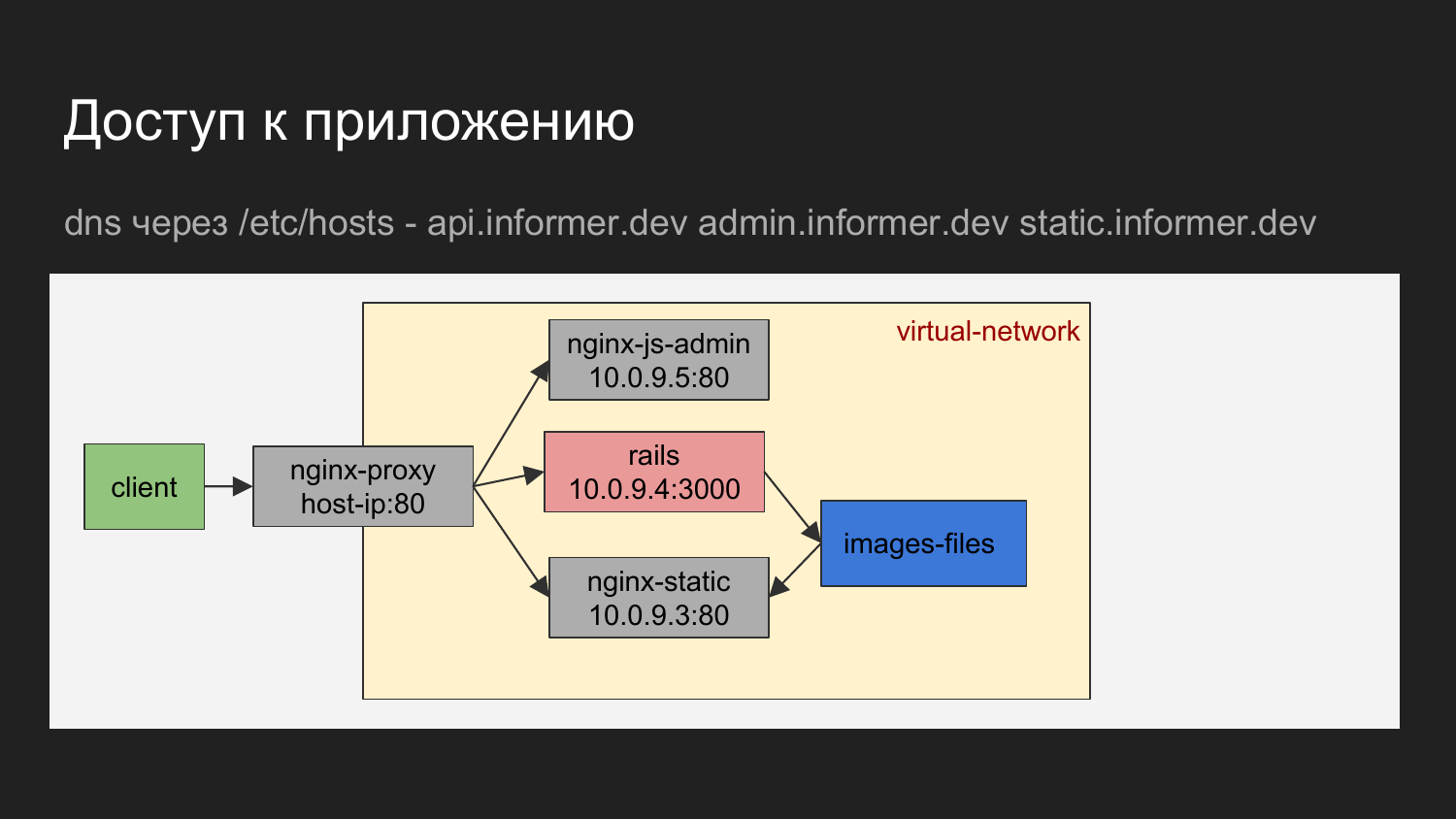
Si se representa gráficamente, resulta que el cliente es nuestro navegador o alguna herramienta con la que realizamos solicitudes para el equilibrador.
El equilibrador de nombre de dominio determina a qué contenedor acceder.
Puede ser nginx, lo que le da al área de administración de JS. Puede ser nginx, que proporciona la API o los archivos estáticos que se proporcionan a nginx en forma de carga de imágenes.
El diagrama muestra que los contenedores están conectados por una red virtual y están ocultos detrás del proxy.
En la máquina del desarrollador, puede recurrir al contenedor conociendo IP, pero básicamente no lo usamos. La necesidad de tratamiento directo prácticamente no surge.

¿Qué ejemplo buscar para dockerizar la aplicación? En mi opinión, un buen ejemplo es la imagen oficial de Docker para MySQL.
Es bastante complicado Hay muchas versiones Pero su funcionalidad le permite cubrir muchas necesidades que puedan surgir en el proceso de desarrollo posterior. Si pasa tiempo y descubre cómo interactúa todo esto, creo que no tendrá problemas en la auto implementación.
En hub.docker.com, generalmente hay enlaces a github.com, que proporcionan datos sin procesar directamente desde los cuales puede ensamblar la imagen usted mismo.
Además en este repositorio está el script docker-endpoint.sh, que es responsable de la inicialización inicial y del procesamiento posterior del lanzamiento de la aplicación.
También en este ejemplo existe la posibilidad de configuración utilizando variables de entorno. Al definir la variable de entorno al iniciar un solo contenedor o mediante docker-compose, podemos decir que necesitamos establecer una contraseña vacía para docker en root en MySQL o lo que queramos.
Hay una opción para crear una contraseña aleatoria. Decimos que necesitamos un usuario, necesitamos establecer una contraseña para el usuario y necesitamos crear una base de datos.
En nuestros proyectos, unificamos ligeramente el Dockerfile, que es responsable de la inicialización. Allí, corregimos nuestras necesidades para hacer solo una extensión de los derechos de usuario que usa la aplicación. Esto permitió en el futuro simplemente crear una base de datos desde la consola de la aplicación. Las aplicaciones de Ruby tienen un comando para crear, modificar y eliminar bases de datos.

Este es un ejemplo de cómo se ve una versión particular de MySQL en github.com. Puede abrir el dockerfile y ver cómo se lleva a cabo la instalación allí.
Script docker-endpoint.sh responsable del punto de entrada. Durante la inicialización inicial, se requieren algunos pasos de preparación y todas estas acciones se llevan a cabo solo en el script de inicialización.

Pasamos a la segunda parte.
Para almacenar el código fuente, cambiamos a gitlab. Este es un sistema bastante potente que tiene una interfaz visual.
Uno de los componentes de Gitlab es Gitlab CI. Le permite describir los comandos de seguimiento que posteriormente se utilizarán para organizar un sistema de entrega de código o ejecutar pruebas automáticas.
Informe sobre Gitlab CI 2 https://goo.gl/uohKjI , un informe del club Ruby Russia, bastante detallado y tal vez le interese.

Ahora consideraremos lo que se requiere para activar Gitlab CI. Para iniciar Gitlab CI, es suficiente que coloquemos el archivo .gitlab-ci.yml en la raíz del proyecto.
Aquí describimos que queremos realizar una secuencia de estados como prueba, implementación.
Ejecutamos scripts que llaman directamente a docker-compose el ensamblaje de nuestra aplicación. Este es un ejemplo de solo un backend.
A continuación, decimos que es necesario realizar migraciones para cambiar la base de datos y ejecutar pruebas.
Si las secuencias de comandos se ejecutan correctamente y no devuelven un código de error, entonces el sistema pasa a la segunda etapa de la implementación.
La fase de implementación se implementa actualmente para la preparación. No organizamos un reinicio sin problemas.
Extinguimos por la fuerza todos los contenedores, y luego levantamos todos los contenedores nuevamente, recogidos en la primera etapa durante las pruebas.
Lo estamos ejecutando para el entorno variable actual de migración de base de datos, que fueron escritos por los desarrolladores.
Hay una nota que aplica esto solo a la rama maestra.
Al cambiar otras ramas no se ejecuta.
Es posible organizar despliegues en sucursales.
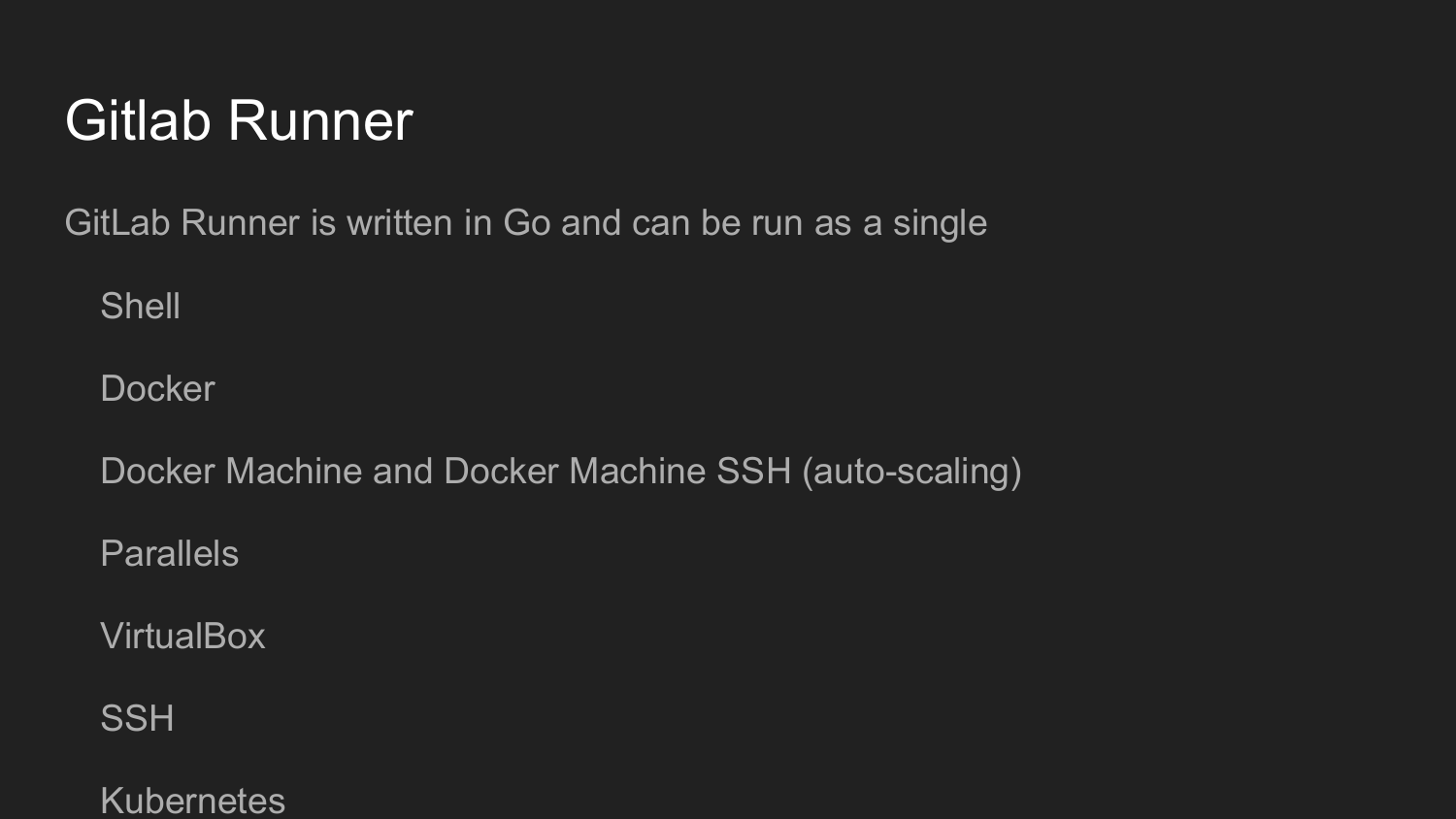
Para organizar aún más esto, necesitamos instalar Gitlab Runner.
Esta utilidad está escrita en Golang. Es un archivo único, como es habitual en el mundo de Golang, que no requiere ninguna dependencia.
Al inicio, registramos el Gitlab Runner.
Obtenemos la clave en la interfaz web de Gitlab.
Luego llamamos al comando init en la línea de comando.
Configure Gitlab Runner en modo de diálogo (Shell, Docker, VirtualBox, SSH)
El código en Gitlab Runner se ejecutará en cada confirmación, dependiendo de la configuración .gitlab-ci.yml.
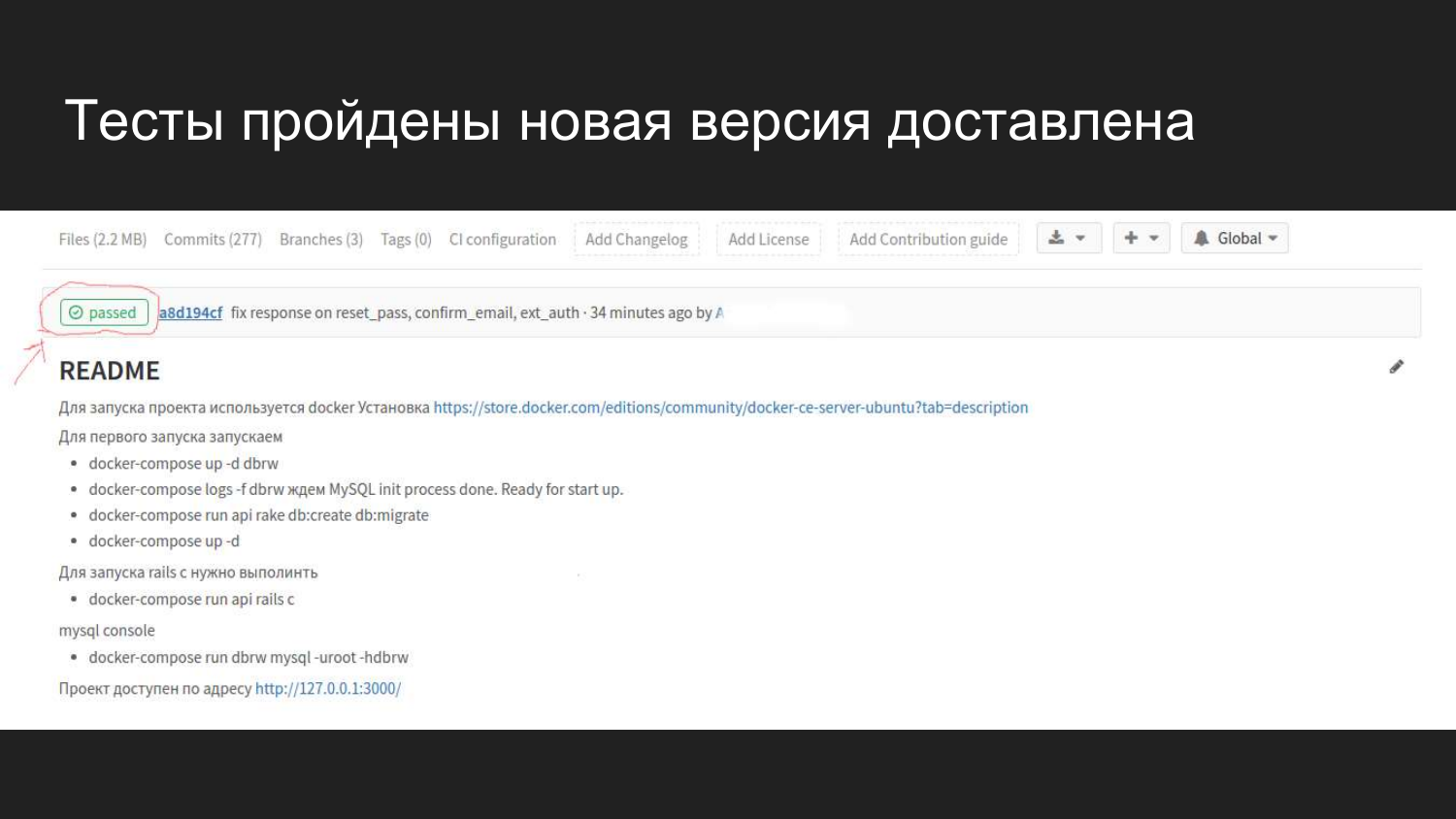
Cómo se ve visualmente en Gitlab en una interfaz web. Después de conectar GItlab CI, aparece un indicador que muestra el estado actual de la compilación.
Vemos que se realizó una confirmación hace 4 minutos, que pasó todas las pruebas y no causó ningún problema.
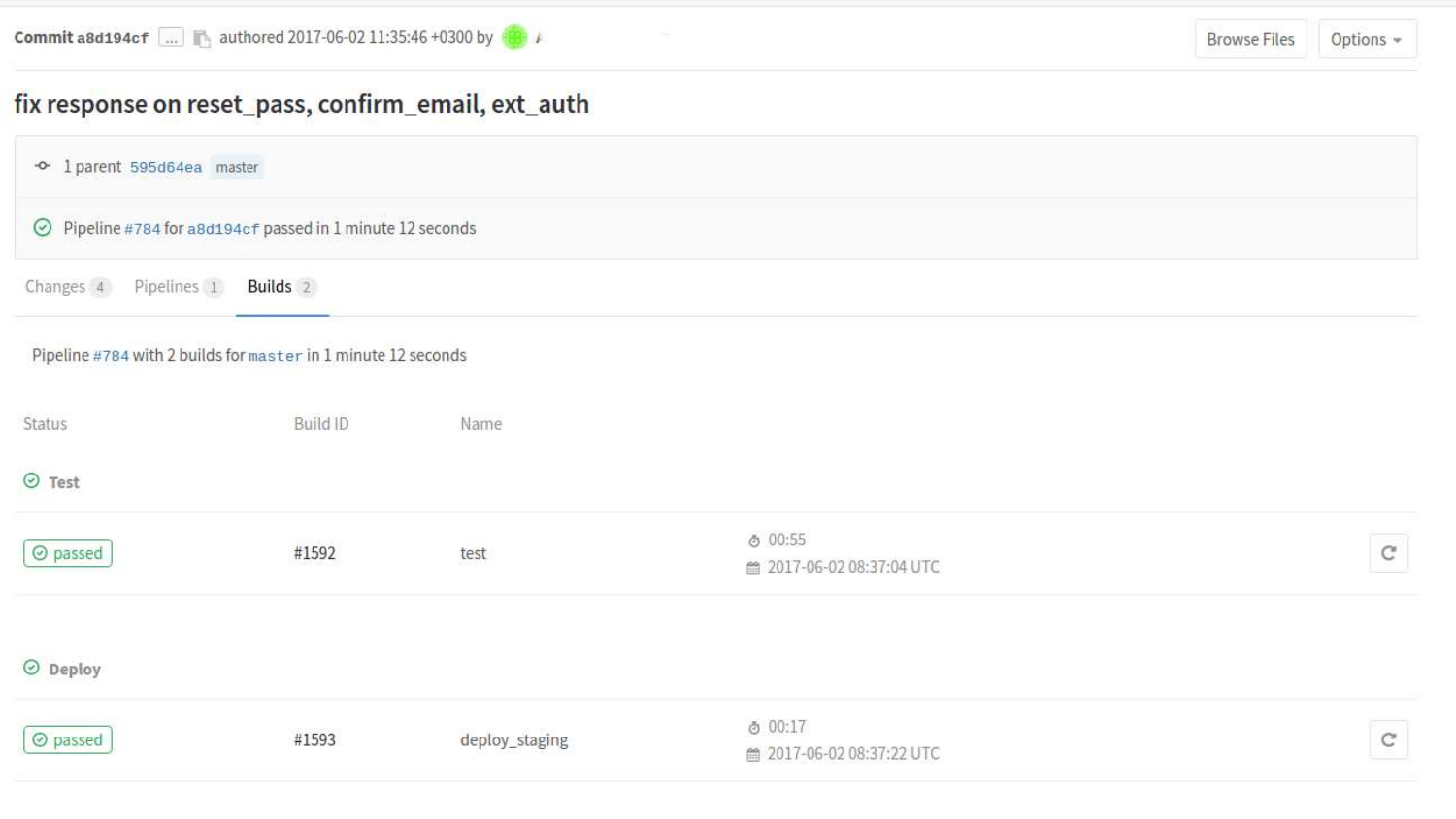
Podemos ver las compilaciones con más detalle. Aquí vemos que dos estados ya han pasado. Estado de prueba y estado de implementación en la preparación.
Si hacemos clic en una compilación específica, habrá una salida de consola de los comandos que se iniciaron en el proceso de acuerdo con .gitlab-ci.yml.
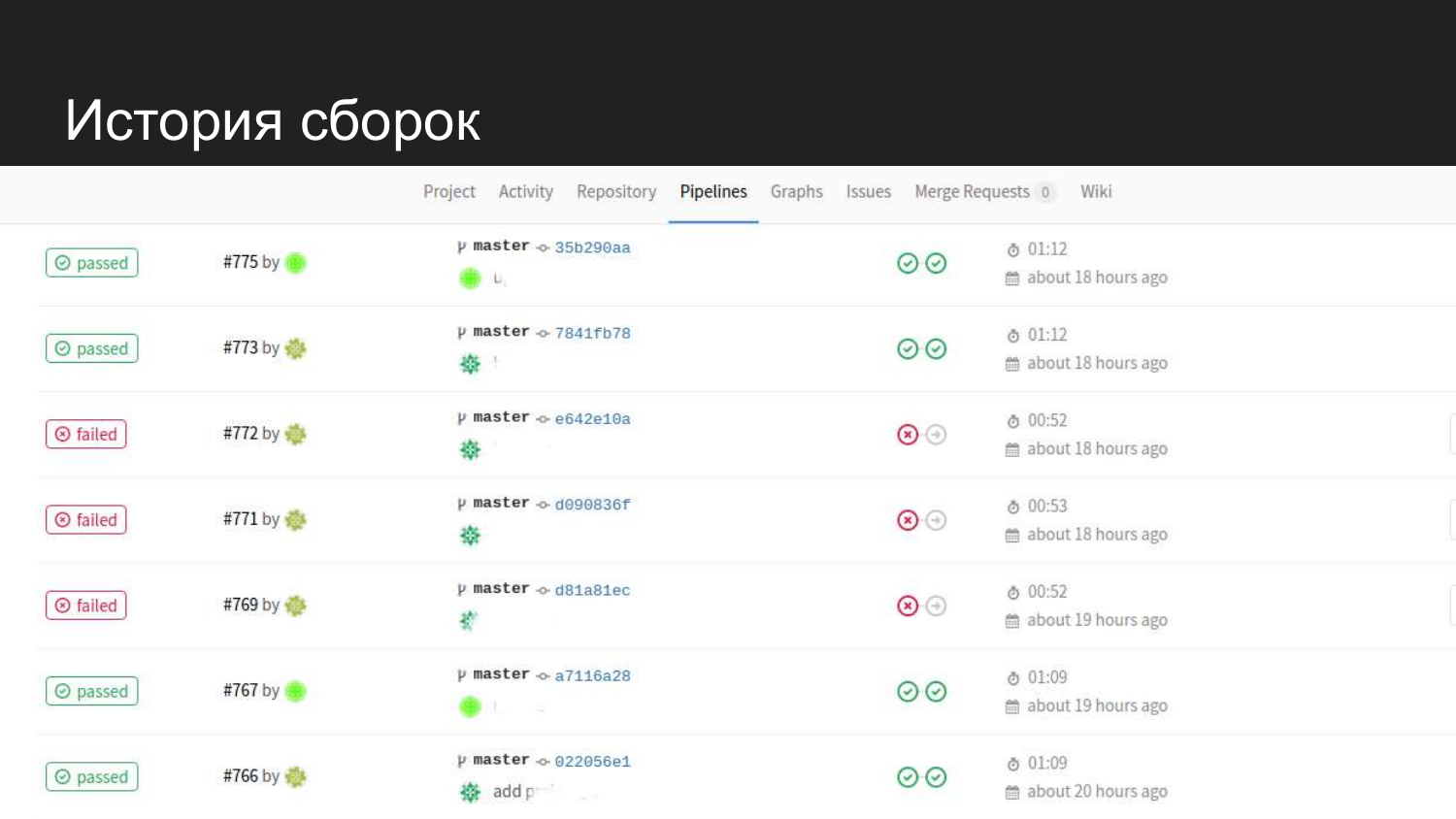
Así es como se ve la historia de nuestro producto. Vemos que hubo intentos exitosos. Cuando se envían pruebas, no continúa con el siguiente paso y el código para la preparación no se actualiza.

¿Qué tareas resolvimos en la puesta en escena cuando presentamos Docker? , , , .
.
Docker-compose .
, Docker . Docker-compose .
, .
— staging .
production 80 443 , WEB.

? Gitlab Runner .
Gitlab Gitlab Runner, - , .
Gitlab Runner, .
nginx-proxy .
, . .
80 , .

? root. root root .
, root , root.
- , , , , .
? , .
, ?
ID (UID) ID (GID).
ID 1000.
Ubuntu. Ubuntu ID 1000.
?
Docker. , . , - , .
, .
.
Docker Docker Swarm, . - Docker Swarm.
. . . web-.
