Hola Habr! Les presento la traducción del artículo
"Modelo de subprocesos de enviado" de Matt Klein.
Este artículo me pareció lo suficientemente interesante, y dado que Envoy se usa con mayor frecuencia como parte de "istio" o simplemente como "controlador de ingreso" kubernetes, por lo tanto, la mayoría de las personas no tienen la misma interacción directa con él como, por ejemplo, con las instalaciones típicas de Nginx o Haproxy. Sin embargo, si algo se rompe, sería bueno entender cómo funciona desde adentro. Traté de traducir la mayor cantidad de texto posible al ruso, incluyendo palabras especiales, para aquellos que son dolorosos de ver esto, dejé los originales entre paréntesis. Bienvenido a cat.
La documentación técnica de bajo nivel en la base del código Envoy es actualmente bastante escasa. Para solucionar esto, planeo hacer una serie de artículos de blog sobre los diversos subsistemas de Envoy. Dado que este es el primer artículo, hágame saber lo que piensa y lo que podría interesarle en los siguientes artículos.
Una de las preguntas técnicas más comunes que recibo sobre Envoy es una solicitud de una descripción de bajo nivel del modelo de subprocesos utilizado. En esta publicación, describiré cómo Envoy asigna conexiones a subprocesos, así como una descripción del sistema Thread Local Storage, que se usa internamente para hacer que el código sea más paralelo y de alto rendimiento.
Resumen de subprocesos
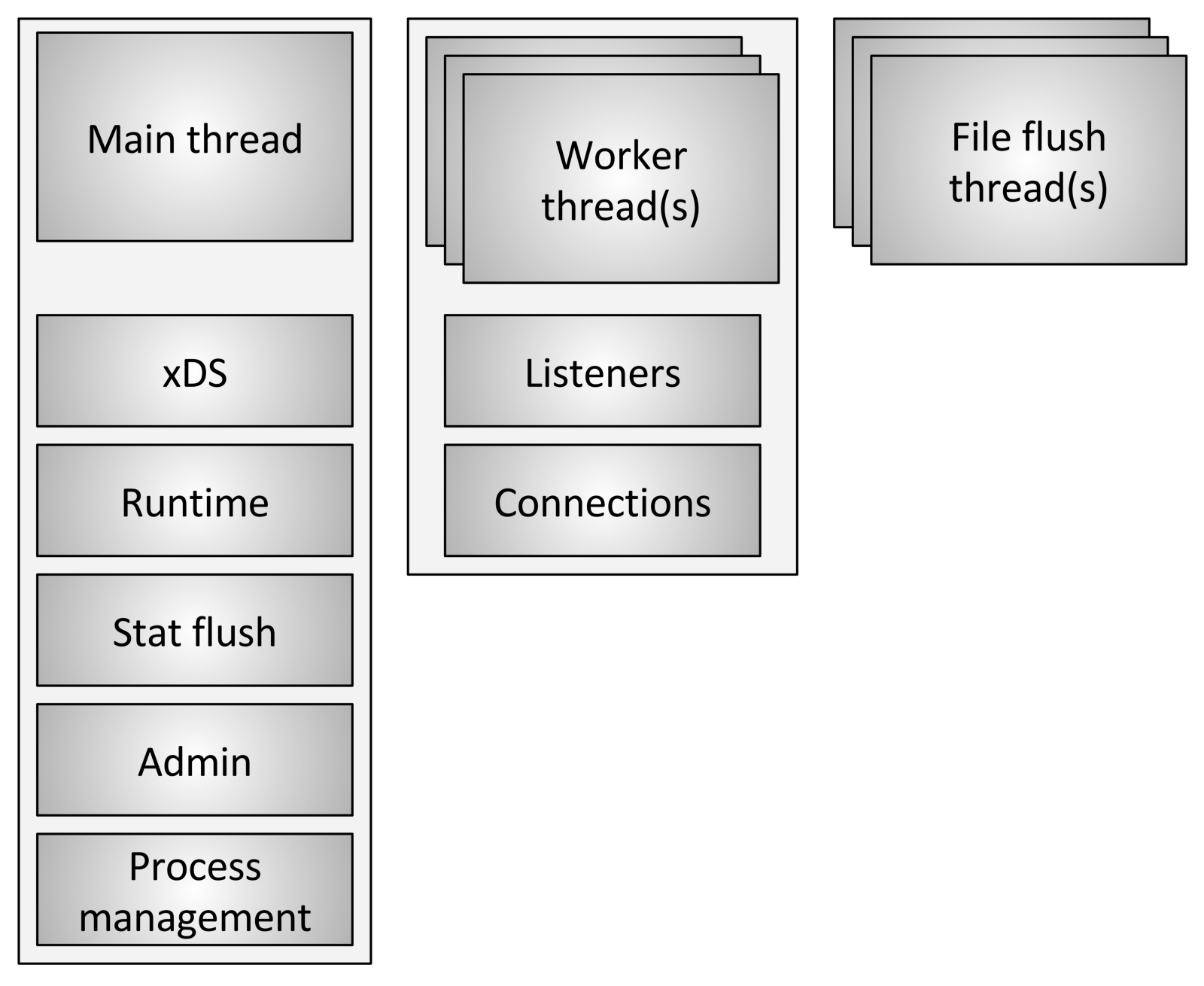 Envoy utiliza tres tipos diferentes de transmisiones:
Envoy utiliza tres tipos diferentes de transmisiones:- Principal: este subproceso controla el inicio y el final del proceso, todo el procesamiento de la API XDS (xDiscovery Service), incluido DNS, comprobación de estado, administración general de clúster y servicio (tiempo de ejecución), restablecimiento de estadísticas, administración y administración general procesos: señales de Linux, reinicio en caliente, etc. Todo lo que sucede en este hilo es asíncrono y no bloquea. En general, el hilo principal coordina todos los procesos críticos de funcionalidad, que no requieren una gran cantidad de CPU para completarse. Esto permite que la mayoría del código de control se escriba como si fuera un subproceso único.
- Trabajador: de forma predeterminada, Envoy crea un subproceso de trabajo para cada subproceso de hardware en el sistema, esto se puede controlar mediante la opción
--concurrency . Cada subproceso de trabajo inicia un bucle de eventos "sin bloqueo", que es responsable de escuchar a cada oyente, al momento de escribir (29 de julio de 2017) no hay fragmentación del oyente, recibiendo nuevos conexiones, creando una instancia de la pila de filtros para conectar y procesando todas las operaciones de E / S durante la vida útil de la conexión. Nuevamente, esto permite que la mayoría del código de procesamiento de la conexión se escriba como si fuera de un solo subproceso. - File flusher: cada archivo que escribe Envoy, principalmente registros de acceso, actualmente tiene una secuencia de bloqueo independiente. Esto se debe al hecho de que la escritura en archivos almacenados en caché por el sistema de archivos, incluso cuando se utiliza
O_NONBLOCK , a veces se puede bloquear (suspiro). Cuando los subprocesos de trabajo necesitan escribir en un archivo, los datos se mueven realmente a un búfer en la memoria, donde eventualmente se transfieren a través del flujo de descarga de archivos . Esta es un área de código donde técnicamente todos los subprocesos de trabajo pueden bloquear el mismo bloqueo al intentar llenar el búfer de memoria.
Manejo de conexión
Como se discutió brevemente arriba, todos los hilos de trabajo escuchan a todos los oyentes sin ninguna segmentación. Por lo tanto, el núcleo se utiliza para enviar correctamente los sockets recibidos a los subprocesos de trabajo. Los núcleos modernos generalmente son muy buenos en esto, usan características como aumentar la prioridad de entrada-salida (IO) para tratar de llenar el hilo con trabajo, antes de comenzar a usar otros hilos que también escuchan en el mismo zócalo, y tampoco usan bloqueo circular (Spinlock) para manejar cada solicitud.
Una vez que se acepta una conexión en un subproceso de trabajo, nunca abandona este subproceso. Todo el procesamiento posterior de la conexión se procesa completamente en el subproceso de trabajo, incluido cualquier comportamiento de reenvío.
Esto tiene varias consecuencias importantes:- Todos los grupos de conexiones en Envoy están en un flujo de trabajo. Por lo tanto, aunque los grupos de conexiones HTTP / 2 solo hacen una conexión a cada host ascendente a la vez, si hay cuatro subprocesos de trabajo, habrá cuatro conexiones HTTP / 2 al host ascendente en un estado estable.
- La razón por la que Envoy funciona de esta manera es porque al almacenar todo en un flujo de trabajo, casi todo el código puede escribirse sin bloqueo y como si fuera un subproceso único. Este diseño facilita la escritura de una gran cantidad de código y se escala increíblemente bien para una cantidad casi ilimitada de flujos de trabajo.
- Sin embargo, una de las principales conclusiones es que, desde el punto de vista del conjunto de memoria y la eficiencia de la conexión, en realidad es muy importante configurar el parámetro
--concurrency . Tener más subprocesos de trabajo de los necesarios conducirá a la pérdida de memoria, creando más conexiones inactivas y disminuyendo la velocidad de acceso al grupo de conexiones. En Lyft, nuestros contenedores de sidecar de mensajería funcionan con una concurrencia muy baja, por lo que el rendimiento es más o menos equivalente a los servicios en los que se encuentran. Ejecutamos Envoy como un proxy de borde (borde) solo con la máxima concurrencia.
¿Qué significa sin bloqueo?
El término "sin bloqueo" se ha utilizado hasta ahora varias veces para analizar cómo funcionan los hilos principales y de trabajo. Todo el código está escrito siempre que nada esté bloqueado. Sin embargo, esto no es del todo cierto (¿qué no es del todo cierto?).
Envoy utiliza varios bloqueos de proceso largos:- Como ya se mencionó, al escribir registros de acceso, todos los subprocesos de trabajo obtienen el mismo bloqueo antes de llenar el búfer de registro en la memoria. El tiempo de retención del bloqueo debe ser muy bajo, pero es posible que este bloqueo se vea desafiado con una alta concurrencia y un alto rendimiento.
- Envoy utiliza un sistema muy sofisticado para procesar estadísticas que es local a la secuencia. Este será el tema de una publicación separada. Sin embargo, mencionaré brevemente que, como parte del procesamiento local de estadísticas de flujo, a veces se requiere obtener un bloqueo para el "almacén de estadísticas" central. Esta cerradura nunca debería ser necesaria.
- El hilo principal periódicamente necesita coordinación con todos los flujos de trabajo. Esto se hace "publicando" desde el hilo principal a los hilos de trabajo y, a veces, desde los hilos de trabajo de vuelta al hilo principal. Para el envío, se requiere el bloqueo para que el mensaje publicado se pueda poner en cola para entrega posterior. Estas cerraduras nunca deben estar sujetas a una competencia seria, pero aún pueden ser bloqueadas técnicamente.
- Cuando Envoy escribe un registro en la secuencia de errores del sistema (error estándar), recibe un bloqueo en todo el proceso. En general, el registro local de Envoy se considera terrible en términos de rendimiento, por lo que no se presta mucha atención a mejorarlo.
- Hay varios otros bloqueos aleatorios, pero ninguno de ellos es crítico para el rendimiento y nunca se debe disputar.
Hilo de almacenamiento local
Debido a la forma en que Envoy separa las responsabilidades del hilo principal de las tareas del flujo de trabajo, existe el requisito de que se pueda realizar un procesamiento complejo en el hilo principal y luego proporcionar a cada flujo de trabajo un alto grado de concurrencia. Esta sección describe el sistema Envoy Thread Local Storage (TLS) en un nivel alto. En la siguiente sección, describiré cómo se usa para administrar el clúster.

Como ya se describió, el subproceso principal procesa casi todas las funciones de administración y la funcionalidad del plano de control en el proceso Envoy. El plano de control está un poco sobrecargado aquí, pero si lo mira dentro del proceso Envoy y lo compara con el reenvío que realizan los subprocesos de trabajo, esto parece apropiado. Como regla general, el proceso del subproceso principal hace algo de trabajo y luego necesita actualizar cada subproceso de trabajo de acuerdo con el resultado de este trabajo,
mientras que el subproceso de trabajo no necesita establecer un bloqueo en cada acceso .
El sistema Enviado TLS (Thread local storage) funciona de la siguiente manera:- El código que se ejecuta en el subproceso principal puede asignar una ranura TLS para todo el proceso. Aunque esto se abstrae, en la práctica es un índice en un vector que proporciona acceso O (1).
- La transmisión principal puede establecer datos arbitrarios en su ranura. Cuando se hace esto, los datos se publican en cada flujo de trabajo como un evento de bucle de evento regular.
- Los subprocesos de los trabajadores pueden leer desde su ranura TLS y recuperar los datos de subprocesos locales disponibles allí.
Aunque este es un paradigma muy simple e increíblemente poderoso, es muy similar al concepto de bloqueo de RCU (Read-Copy-Update). En esencia, los flujos de trabajo nunca ven ningún cambio de datos en las ranuras TLS en tiempo de ejecución. El cambio solo ocurre durante el período de descanso entre eventos de trabajo.
Envoy usa esto de dos maneras diferentes:- Al almacenar diversos datos en cada flujo de trabajo, el acceso a estos datos se realiza sin ningún bloqueo.
- Al almacenar un puntero global a datos globales en modo de solo lectura en cada subproceso de trabajo. Por lo tanto, cada subproceso de trabajo tiene un contador de referencia de datos, que no se puede reducir durante la ejecución del trabajo. Solo cuando todos los trabajadores se calmen y carguen nuevos datos compartidos, se destruirán los datos antiguos. Es idéntico a la RCU.
Subprocesos de actualización de clúster
En esta sección, describiré cómo se usa TLS (almacenamiento local de subprocesos) para administrar un clúster. La gestión de clústeres incluye el procesamiento de API xDS y / o DNS, así como la comprobación del estado.
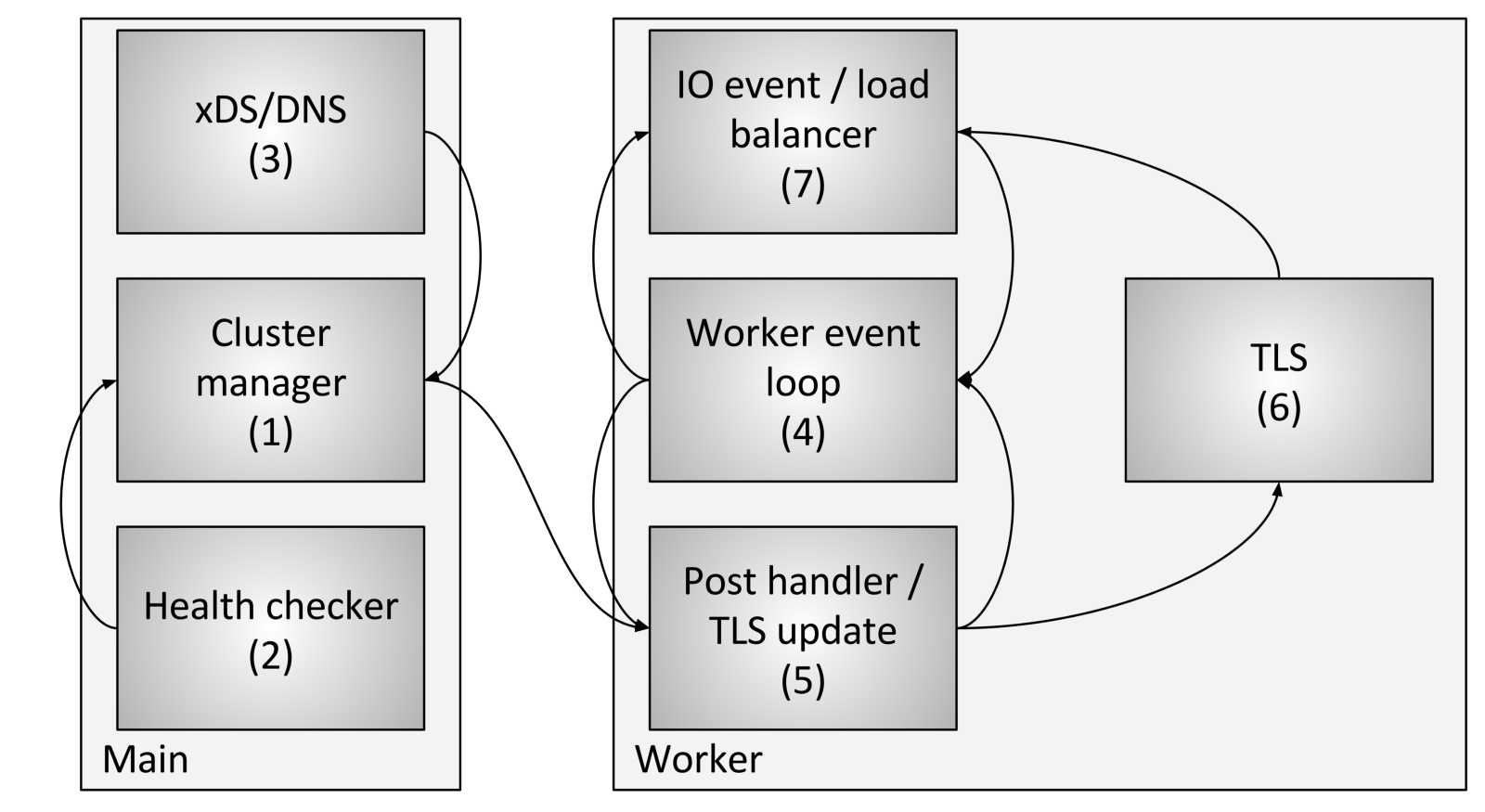 La gestión del flujo de clúster incluye los siguientes componentes y pasos:
La gestión del flujo de clúster incluye los siguientes componentes y pasos:- Cluster Manager es un componente dentro de Envoy que gestiona todas las API conocidas de clúster aguas arriba, CDS (Cluster Discovery Service), SDS (Secret Discovery Service) y EDS (Endpoint Discovery Service), DNS y comprobaciones externas activas salud (control de salud). Es responsable de crear una representación "en última instancia coherente" de cada grupo aguas arriba que incluya los hosts descubiertos, así como el estado de salud.
- El verificador de salud realiza una verificación de salud activa e informa sobre los cambios en el estado de salud al administrador del clúster.
- Se realizan CDS (Cluster Discovery Service) / SDS (Secret Discovery Service) / EDS (Endpoint Discovery Service) / DNS para determinar la membresía del clúster. El cambio de estado se devuelve al administrador del clúster.
- Cada flujo de trabajo ejecuta constantemente un bucle de eventos.
- Cuando el administrador del clúster determina que el estado del clúster ha cambiado, crea una nueva instantánea del clúster de solo lectura y la envía a cada subproceso de trabajo.
- Durante el próximo período de inactividad, el flujo de trabajo actualizará la instantánea en la ranura TLS dedicada.
- Durante un evento de E / S que el host debe determinar para el equilibrio de carga, el equilibrador de carga solicitará una ranura TLS (almacenamiento local de subprocesos) para obtener información del host. No se requieren bloqueos para esto. Tenga en cuenta también que TLS también puede desencadenar eventos durante la actualización, por lo que los equilibradores de carga y otros componentes pueden contar cachés, estructuras de datos, etc. Esto está más allá del alcance de esta publicación, pero se usa en varios lugares del código.
Usando el procedimiento anterior, Envoy puede procesar cada solicitud sin ningún bloqueo (aparte de los descritos anteriormente). Además de la complejidad del código TLS en sí, la mayoría del código no necesita comprender cómo funciona el subprocesamiento múltiple, y se puede escribir en modo de subproceso único. Esto facilita la escritura de la mayoría del código, además de un rendimiento superior.
Otros subsistemas que hacen uso de TLS
TLS (Thread local storage) y RCU (Read Copy Update) se usan ampliamente en Envoy.
Ejemplos de uso:- El mecanismo de cambio de funcionalidad durante la ejecución: la lista actual de funcionalidad habilitada se calcula en el hilo principal. Luego, cada flujo de trabajo se proporciona con una instantánea de solo lectura utilizando la semántica de RCU.
- Sustitución de tablas de ruta : para las tablas de ruta proporcionadas por el RDS (Servicio de descubrimiento de ruta), las tablas de ruta se crean en el hilo principal. Posteriormente se proporcionará una instantánea de solo lectura a cada flujo de trabajo utilizando la semántica de RCU (Actualización de lectura de copia). Esto hace que la modificación de las tablas de rutas sea atómicamente eficiente.
- Caché de encabezado HTTP: Resulta que calcular el encabezado HTTP para cada solicitud (cuando se realizan ~ 25K + RPS por núcleo) es bastante costoso. Envoy calcula centralmente el encabezado aproximadamente cada medio segundo y se lo proporciona a cada empleado a través de TLS y RCU.
Hay otros casos, pero los ejemplos anteriores deberían proporcionar una buena comprensión de para qué se utiliza TLS.
Problemas conocidos de rendimiento
Aunque Envoy funciona bastante bien en general, hay algunas áreas bien conocidas que necesitan atención cuando se usan con muy alta concurrencia y ancho de banda:
- Como ya se describió en este artículo, actualmente todos los subprocesos de trabajo están bloqueados cuando escriben en el búfer de memoria del registro de acceso. Con alta concurrencia y alto rendimiento, será necesario empaquetar registros de acceso para cada flujo de trabajo debido a una entrega no ordenada al escribir en el archivo final. Alternativamente, puede crear un registro de acceso separado para cada flujo de trabajo.
- Aunque las estadísticas están muy optimizadas, con una concurrencia y un rendimiento muy altos, es probable que haya una competencia atómica en las estadísticas individuales. La solución a este problema son los contadores por flujo de trabajo con reinicio periódico de los contadores centrales. Esto se discutirá en una publicación posterior.
- La arquitectura existente no funcionará bien si Envoy se implementa en un escenario en el que hay muy pocas conexiones que requieren recursos de procesamiento significativos. No hay garantía de que las comunicaciones se distribuyan de manera uniforme entre los flujos de trabajo. Esto se puede resolver equilibrando las conexiones de trabajo, en las que se realizará la capacidad de intercambiar conexiones entre flujos de trabajo.
Conclusión
El modelo de subprocesos de Envoy está diseñado para proporcionar una programación sencilla y una concurrencia masiva debido al uso potencialmente inútil de memoria y conexiones si no están configuradas correctamente. Este modelo le permite funcionar muy bien con una gran cantidad de hilos y rendimiento.
Como mencioné brevemente en Twitter, un diseño también puede ejecutarse sobre una pila de red completamente funcional en modo de usuario, como el DPDK (Kit de desarrollo de plano de datos), que puede hacer que los servidores regulares procesen millones de solicitudes por segundo con un procesamiento L7 completo. Será muy interesante ver lo que se construirá en los próximos años.
Un último comentario rápido: muchas veces me han preguntado por qué elegimos C ++ para Envoy. La razón, como antes, es que sigue siendo el único lenguaje de nivel industrial ampliamente hablado sobre el cual construir la arquitectura descrita en esta publicación. C ++ definitivamente no es adecuado para todos o incluso para muchos proyectos, pero para ciertos casos de uso sigue siendo la única herramienta para hacer el trabajo (para hacer el trabajo).
Enlaces al código
Enlaces a archivos con interfaces e implementaciones de encabezado discutidos en esta publicación: