Hola a todos La biblioteca de redes neuronales se describe en mi último
artículo . Aquí decidí mostrar cómo puede usar la red capacitada de TF (Tensorflow) en su decisión, y si vale la pena.
Debajo del corte, una comparación con la implementación original de TF, una aplicación de demostración para reconocer imágenes, bueno ... conclusiones. A quién le importa, por favor.
Puede averiguar cómo funciona ResNet, por ejemplo,
aquí .
Aquí está la estructura de la red en números:
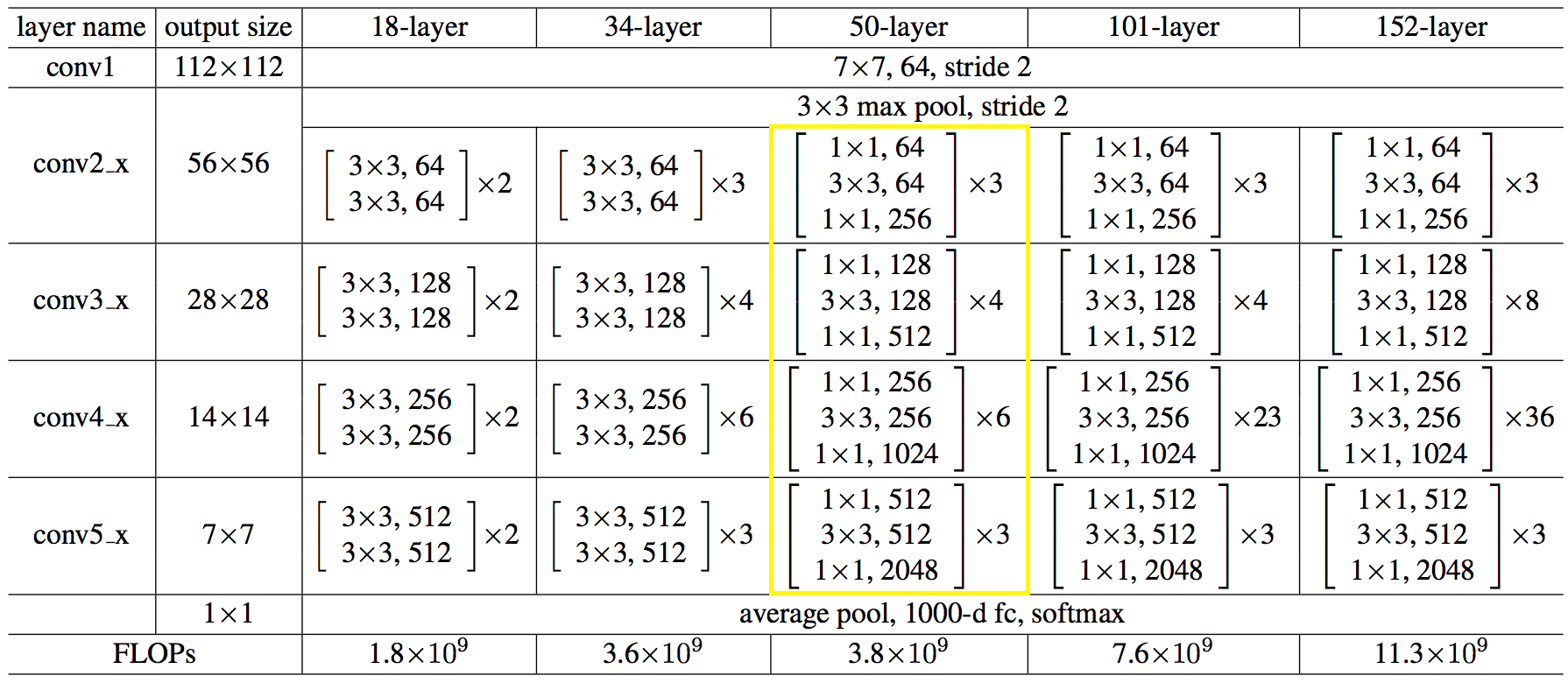
El código resultó no ser más simple ni más complicado que Python.
Código C ++ para crear una red:auto net = sn::Net(); net.addNode("In", sn::Input(), "conv1") .addNode("conv1", sn::Convolution(64, 7, 3, 2, sn::batchNormType::beforeActive, sn::active::none, mode), "pool1_pad") .addNode("pool1_pad", sn::Pooling(3, 2, sn::poolType::max, mode), "res2a_branch1 res2a_branch2a"); convBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, 1, "res2a_branch", "res2b_branch2a res2b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, "res2b_branch", "res2c_branch2a res2c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256}, 3, "res2c_branch", "res3a_branch1 res3a_branch2a", mode); convBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, 2, "res3a_branch", "res3b_branch2a res3b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3b_branch", "res3c_branch2a res3c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3c_branch", "res3d_branch2a res3d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3d_branch", "res4a_branch1 res4a_branch2a", mode); convBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, 2, "res4a_branch", "res4b_branch2a res4b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4b_branch", "res4c_branch2a res4c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4c_branch", "res4d_branch2a res4d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4d_branch", "res4e_branch2a res4e_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4e_branch", "res4f_branch2a res4f_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4f_branch", "res5a_branch1 res5a_branch2a", mode); convBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, 2, "res5a_branch", "res5b_branch2a res5b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5b_branch", "res5c_branch2a res5c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5c_branch", "avg_pool", mode); net.addNode("avg_pool", sn::Pooling(7, 7, sn::poolType::avg, mode), "fc1000") .addNode("fc1000", sn::FullyConnected(1000, sn::active::none, mode), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
→ El código completo está disponible
aquíPuede hacerlo más fácilmente, cargar la arquitectura de red y los pesos de los archivos,
así: string archPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Struct.json", weightPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Weights.dat"; std::ifstream ifs; ifs.open(archPath, std::ifstream::in); if (!ifs.good()){ cout << "error open file : " + archPath << endl; system("pause"); return false; } ifs.seekg(0, ifs.end); size_t length = ifs.tellg(); ifs.seekg(0, ifs.beg); string jnArch; jnArch.resize(length); ifs.read((char*)jnArch.data(), length);
Hizo una solicitud de interés. Puedes descargar
desde aquí . El volumen es grande debido a los pesos de la red. Las fuentes están ahí, puedes usarlas como ejemplo.
La aplicación se creó solo para el artículo, no será compatible, por lo tanto, no se incluyó en el repositorio del proyecto.

Ahora, qué pasó en comparación con TF.
Indicaciones después de una serie de 100 imágenes, en promedio. Máquina: i5-2400, GF1050, Win7, MSVC12.
Los valores de los resultados de reconocimiento coinciden con el 3er carácter.
→
Código de pruebaDe hecho, todo es deplorable, por supuesto.
Para la CPU, decidí no usar MKL-DNN, pensé terminarlo: redistribuí la memoria para lectura secuencial, cargué los registros de vectores al máximo. Quizás fue necesario conducir a la multiplicación de matrices y / o algunos otros hacks. Descansado aquí, al principio era peor, sería más correcto usar MKL de todos modos.
En la GPU, se gasta tiempo copiando la memoria de / a la memoria de la tarjeta de video, y no todas las operaciones se realizan en la GPU.
¿Qué conclusiones se pueden sacar de todo este alboroto?
- No para presumir, sino para usar soluciones probadas bien conocidas, ya se les han ocurrido más o menos. Se sentó en mxnet una vez, y trabajó duro con el uso nativo, más sobre eso a continuación;
- No intente utilizar la interfaz C nativa de los marcos ML. Y úselos en el lenguaje en el que se centraron los desarrolladores, es decir, python.
Una manera fácil de usar la funcionalidad ML desde su idioma es realizar un proceso de servicio en python y enviarle imágenes en el socket, obtiene una división de responsabilidad y la ausencia de código pesado.
Quizás todo. El artículo fue breve, pero las conclusiones, creo, son valiosas y se aplican no solo a ML.
Gracias
PD:
Si alguien tiene el deseo y la fuerza para intentar alcanzar a TF, ¡
bienvenido !)
PS2:
bajó las manos temprano. Tomó un descanso para fumar, lo tomó de nuevo y todo salió bien.
Para la CPU, ayudar a la multiplicación de matrices ayudó, como pensé.
Para la GPU, seleccioné todas las operaciones en una biblioteca separada, de modo que sin copiar a la CPU y viceversa, el único inconveniente de este enfoque fue que tuve que reescribir (duplicar) todos los operadores, aunque algunas cosas eran iguales, pero no los conecté.
En general, así es como ahora:
Es decir, al menos la inferencia resultó incluso más rápida que en TF.
El código de prueba no ha cambiado.