Si se enseñaran las carreteras en la escuela, el libro de texto sobre este tema tendría esa tarea. “La red social N tiene 2,000 servidores, en los cuales 150,000 archivos de 900 MB cada código PHP y un clúster provisional para 50 máquinas. El código se implementa 2 veces al día en los servidores, el código se actualiza cada pocos minutos en el clúster provisional, y hay "revisiones" adicionales: pequeños conjuntos de archivos que se distribuyen de forma alternada en todos o en la parte seleccionada de los servidores, sin esperar el cálculo completo. Pregunta: ¿se consideran tales condiciones de alta carga y cómo implementarlas? Escriba al menos 5 opciones de implementación ". Solo podemos soñar con el libro de problemas hyload, pero ya sabemos que
Yuri Nasretdinov (
youROCK ) definitivamente resolvería este problema y obtendría los "cinco".
Yuri no se detuvo en una solución simple, sino que también hizo un informe en el que reveló el concepto del concepto de "implementación de código", habló de soluciones clásicas y alternativas para implementaciones PHP a gran escala, analizó su rendimiento y presentó el sistema de implementación MDK.
El concepto de "código de implementación"
En inglés, el término "despliegue" significa poner a las tropas en alerta, y en ruso a veces decimos "llene el código en la batalla", lo que significa lo mismo. Usted toma el código en el ya compilado o en el original, si es PHP, lo descarga en los servidores que sirven al tráfico del usuario y luego, por arte de magia, cambia la carga de una versión del código a otra. Todo esto está incluido en el concepto de "implementación de código".
El proceso de implementación generalmente consta de varias etapas.
- Obtener el código del repositorio de la forma que desee: clonar, buscar, pagar.
- Montaje - construcción . Para el código PHP, puede faltar la fase de compilación. En nuestro caso, esto es, por regla general, la generación automática de archivos de traducción, la carga de archivos estáticos a CDN y algunas otras operaciones.
- Entrega a servidores finales : implementación.
Después de ensamblar todo, comienza la fase de implementación inmediata: el
código se
vierte en los servidores de producción . Es sobre esta fase que se discutirá
Badoo .
Antiguo sistema de despliegue en Badoo
Si tiene un archivo con una imagen del sistema de archivos, ¿cómo montarlo? En Linux, debe crear
un dispositivo de bucle intermedio , adjuntarle un archivo y, después de eso, ya puede montar este dispositivo de bloque.
Un dispositivo de bucle es una muleta que Linux necesita para montar una imagen del sistema de archivos. Hay sistemas operativos en los que no se requiere esta muleta.

¿Cómo utiliza el proceso de implementación los archivos, que también llamamos "bucles" por simplicidad? Hay un directorio en el que se encuentran el código fuente y el contenido generado automáticamente. Tomamos una imagen vacía del sistema de archivos; ahora es EXT2 y antes utilizamos ReiserFS. Montamos una imagen vacía del sistema de archivos en un directorio temporal, copiamos todo el contenido allí. Si no necesitamos algo para entrar en producción, entonces no estamos copiando todo. Después de eso, desmonte el dispositivo y obtenga la imagen del sistema de archivos en el que se encuentran los archivos necesarios. A continuación,
archivamos la imagen y la cargamos en todos los servidores , allí la descomprimimos y la montamos.
Otras soluciones existentes
Primero, agradezcamos a
Richard Stallman : sin su licencia, la mayoría de las utilidades que utilizamos no hubieran existido.

Convencionalmente dividí los métodos de implementación de código PHP en 4 categorías.
- Basado en el sistema de control de versiones : svn up, git pull, hg up.
- Basado en la utilidad rsync : a un nuevo directorio o "en la parte superior".
- Implemente un archivo , sin importar qué: phar, hhbc, loop.
- La forma especial que sugirió Rasmus Lerdorf es rsync, 2 directorios y realpath_root .
Cada método tiene ventajas y desventajas, por lo que los abandonamos. Considere estos 4 métodos con más detalle.
Implementación basada en el sistema de control de versiones svn up
Elegí SVN no por casualidad; de acuerdo con mis observaciones, de esta forma el despliegue existe precisamente en el caso de SVN. El sistema es bastante
liviano , le permite implementarlo de manera
rápida y fácil : simplemente ejecute svn up y listo.
Pero este método tiene una gran desventaja: si lo hace, y en el proceso de actualización del código fuente, cuando nuevas solicitudes provengan del repositorio, verán el estado del sistema de archivos que no existía en el repositorio. Tendrá parte de los archivos nuevos y parte de los antiguos; este es un
método de implementación no atómico que no es adecuado para cargas elevadas, sino solo para proyectos pequeños. A pesar de esto, conozco proyectos que todavía se implementan de esta manera, y hasta ahora todo funciona para ellos.
Implementación basada en la utilidad rsync
Hay dos opciones sobre cómo hacer esto: cargar archivos usando la utilidad directamente al servidor y cargar "en la parte superior" - actualizar.
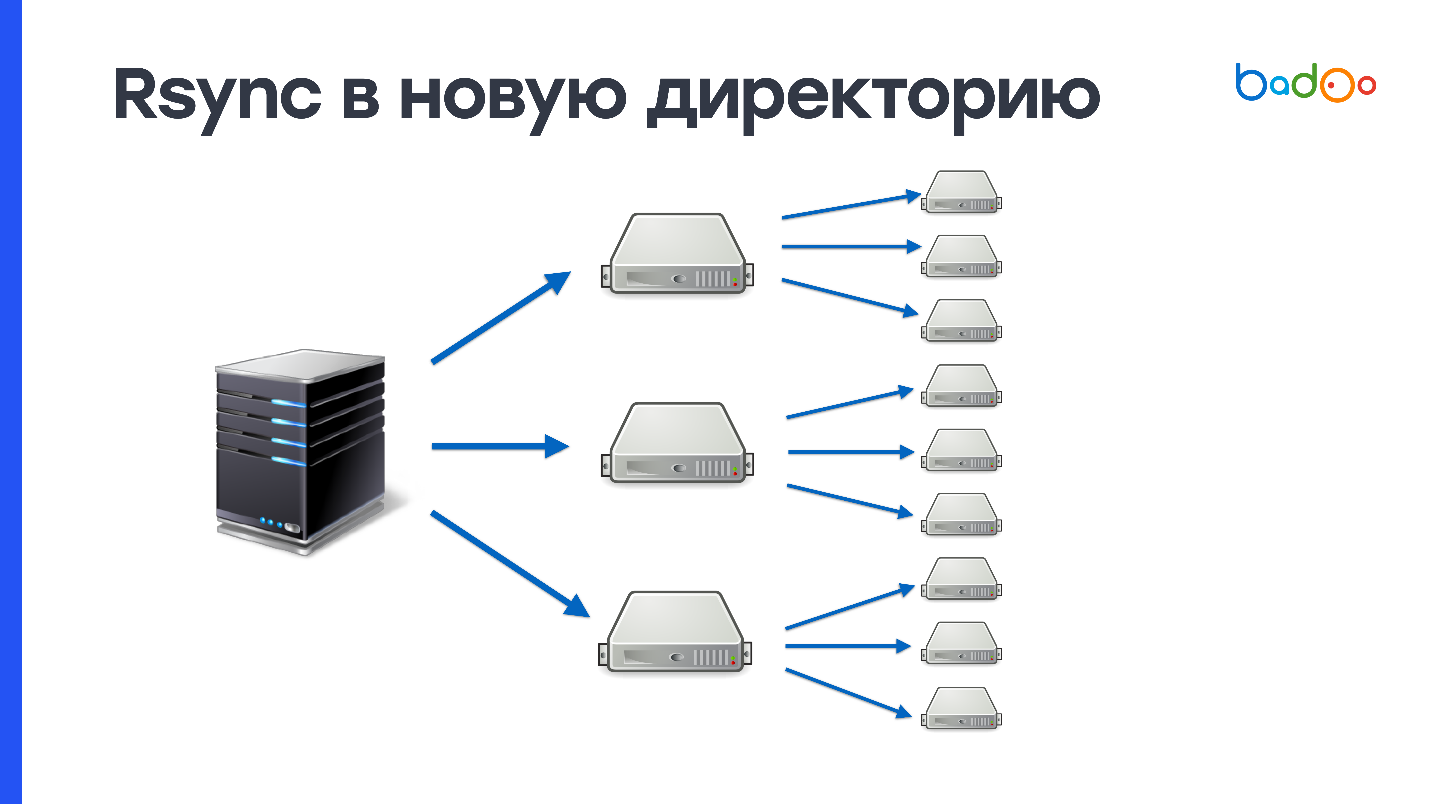
rsync a un nuevo directorio
Dado que primero vierte completamente todo el código en un directorio que aún no existe en el servidor, y solo luego cambia el tráfico, este método es
atómico : nadie ve un estado intermedio. En nuestro caso, la creación de 150,000 archivos y la eliminación del directorio anterior, que también tiene 150,000 archivos, crea una
gran carga en el subsistema de disco . Usamos discos duros muy activamente, y el servidor en algún lugar por un minuto no se siente muy bien después de tal operación. Como tenemos 2000 servidores, es necesario completar 900 MB 2000 veces.
Este esquema se puede mejorar si primero carga a un cierto número de servidores intermedios, por ejemplo, 50, y luego los agrega al resto. Esto resuelve posibles problemas con la red, pero el problema de crear y eliminar una gran cantidad de archivos no desaparece en ningún lado.
rsync en la parte superior
Si usó rsync, entonces sabe que esta utilidad no solo puede llenar directorios completos, sino también actualizar los existentes. Enviar solo cambios es una ventaja, pero como cargamos los cambios en el mismo directorio donde servimos el código de batalla, también habrá algún tipo de estado intermedio, esto es un menos.
Enviar cambios funciona así. Rsync crea listas de archivos en el lado del servidor desde el que se realiza la implementación y en el lado de recepción. Después de eso, cuenta las estadísticas de todos los archivos y envía la lista completa al lado receptor. En el servidor del que procede la implementación, se considera la diferencia entre estos valores y se determina qué archivos deben enviarse.
En nuestras condiciones, este proceso requiere aproximadamente
3 MB de tráfico y 1 segundo de tiempo de procesador . Parece que esto no es mucho, pero tenemos 2.000 servidores, y todo resulta al menos un minuto de tiempo de procesador. Este no es un método tan rápido, pero definitivamente es mejor que enviar todo a través de rsync. Queda por resolver de alguna manera el problema de la atomicidad y será casi perfecto.
Implementar un archivo
Cualquiera que sea el archivo que cargue, es relativamente sencillo hacerlo utilizando BitTorrent o la utilidad UFTP. Un archivo es más fácil de descomprimir, se puede reemplazar atómicamente en Unix, y es fácil verificar la integridad del archivo generado en el servidor de compilación y entregado a las máquinas de destino calculando las cantidades MD5 o SHA-1 del archivo (en el caso de rsync, no sabe qué hay en los servidores de destino )
Para los discos duros, la grabación secuencial es una gran ventaja: un archivo de 900 MB se escribirá en un disco duro desocupado en aproximadamente 10 segundos. Pero aún necesita grabar estos mismos 900 MB y transferirlos a través de la red.
Digresión lírica sobre UFTP
Esta utilidad de código abierto se creó originalmente para transferir archivos a través de una red con largas demoras, por ejemplo, a través de una red basada en satélites. Pero UFTP resultó ser adecuado para cargar archivos a una gran cantidad de máquinas, ya que funciona utilizando el protocolo UDP basado en Multicast. Se crea una dirección de multidifusión, todas las máquinas que desean recibir el archivo se suscriben y los conmutadores proporcionan la entrega de copias de paquetes a cada máquina. Entonces cambiamos la carga de transmitir datos a la red. Si su red puede manejar esto, entonces este método funciona mucho mejor que BitTorrent.
Puede probar esta utilidad de código abierto en su clúster. A pesar de que funciona a través de UDP, tiene un mecanismo NACK: reconocimiento negativo, que obliga a reenviar los paquetes perdidos en la entrega.
Esta es una forma confiable de implementar .
Opciones de implementación de un solo archivo
tar.gzUna opción que combina las desventajas de ambos enfoques. No solo tiene que escribir 900 MB en el disco de forma secuencial, sino que también debe volver a escribir los mismos 900 MB por lectura aleatoria y crear 150,000 archivos. Este método es aún peor en rendimiento que rsync.
pharPHP admite archivos en formato phar (Archivo PHP), sabe cómo dar sus contenidos e incluir archivos. Pero no todos los proyectos son fáciles de poner en un solo faro: necesita la adaptación del código. Solo porque el código de este archivo no funciona. Además, no puede cambiar un archivo en el archivo (
Yuri del futuro: en teoría, aún puede hacerlo), debe volver a cargar todo el archivo. Además, a pesar del hecho de que los archivos phar funcionan con OPCache, cuando se implementa, el caché debe descartarse, porque de lo contrario habrá basura en OPCache del antiguo archivo phar.
hhbcEste método es nativo de HHVM - HipHop Virtual Machine y es utilizado por Facebook. Esto es algo así como un archivo phar, pero no contiene los códigos fuente, sino el código de bytes compilado de la máquina virtual HHVM: el intérprete PHP de Facebook. Está prohibido cambiar cualquier cosa en este archivo: no puede crear nuevas clases, funciones y algunas otras características dinámicas en este modo están deshabilitadas. Debido a estas limitaciones, la máquina virtual puede usar optimizaciones adicionales. Según Facebook, esto puede aumentar hasta un 30% la velocidad de ejecución del código. Esta es probablemente una buena opción para ellos. También es imposible cambiar un archivo aquí (
Yuri del futuro: en realidad es posible, porque es una base sqlite ). Si desea cambiar una línea, debe volver a hacer todo el archivo nuevamente.
Para este método, está
prohibido utilizar eval e include dinámico. Esto es así, pero no del todo. Se puede usar Eval, pero si no crea nuevas clases o funciones, y la inclusión no se puede hacer desde directorios que están fuera de este archivo.
bucleEsta es nuestra versión anterior, y tiene dos grandes ventajas. Primero, parece un directorio regular
. Monta el bucle y, para el código, no importa: funciona con archivos, tanto en el entorno de desarrollo como en el entorno de producción. El segundo bucle puede montarse en modo de lectura y escritura, y cambiar un archivo, si aún necesita cambiar algo urgentemente para la producción.
Pero loop tiene contras. Primero, funciona de manera extraña con Docker. Hablaré de esto un poco más tarde.
En segundo lugar, si usa el enlace simbólico en el último bucle como document_root, tendrá problemas con OPCache. No es muy bueno tener un enlace simbólico en la ruta y comienza a confundir qué versiones de los archivos usar. Por lo tanto, OPCache debe reiniciarse cuando se implementa.
Otro problema es que
se requieren privilegios de superusuario para montar sistemas de archivos. Y no debe olvidarse de montarlos al inicio / reinicio de la máquina, porque de lo contrario habrá un directorio vacío en lugar de código.
Problemas con la ventana acoplable
Si crea un contenedor acoplable y arroja dentro de él una carpeta en la que se montan "bucles" u otros dispositivos de bloque, surgen dos problemas a la vez: los nuevos puntos de montaje no caen en el contenedor acoplable y esos "bucles" que estaban en el momento de la creación Un contenedor acoplable
no se puede desmontar porque está ocupado por un contenedor acoplable.
Naturalmente, esto generalmente es incompatible con la implementación, porque la cantidad de dispositivos de bucle es limitada y no está claro cómo el nuevo código debe caer en el contenedor.
Intentamos hacer cosas extrañas, por ejemplo, generar un
servidor NFS local o montar un directorio usando SSHFS, pero por alguna razón esto no se arraigó con nosotros. Como resultado, en cron, registramos rsync desde el último "bucle" en el directorio actual, y ejecutó el comando una vez por minuto:
rsync /var/loop/<N>/ /var/www/
Aquí
/var/www/ es el directorio que se promociona al contenedor. Pero en las máquinas que tienen contenedores acoplables, no necesitamos ejecutar scripts PHP a menudo, por lo que rsync no era atómico, lo que nos convenía. Pero aún así, este método es muy malo, por supuesto. Me gustaría hacer un sistema de implementación que funcione bien con Docker.
rsync, 2 directorios y realpath_root
Este método fue propuesto por Rasmus Lerdorf, el autor de PHP, y él sabe cómo implementarlo.
¿Cómo hacer un despliegue atómico y de alguna de las formas de las que hablé? Tome el enlace simbólico y regístrelo como document_root. En cada momento, el enlace simbólico apunta a uno de los dos directorios y convierte rsync en un directorio vecino, es decir, al que el código no apunta.
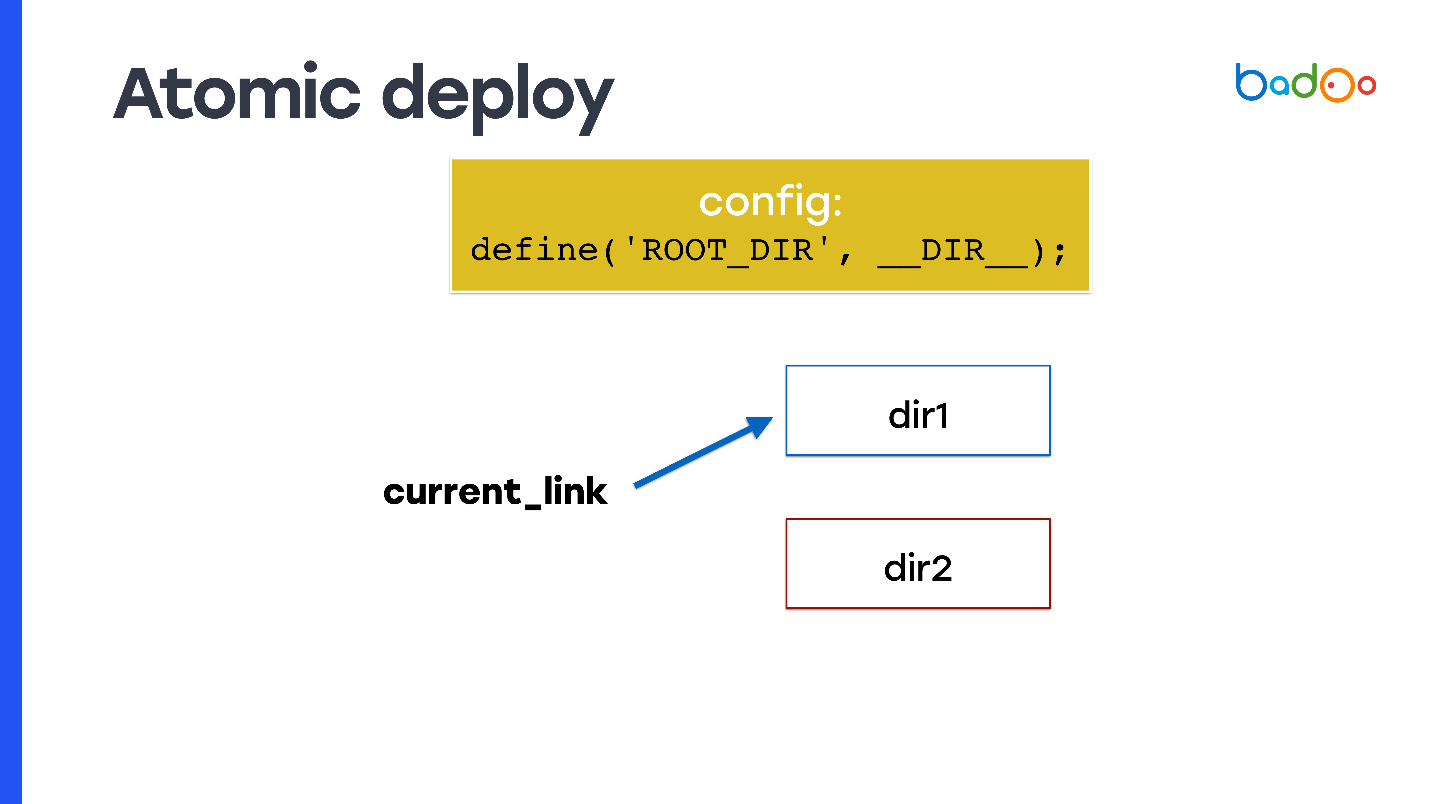
Pero surge el problema: el código PHP no sabe en qué directorios se lanzó. Por lo tanto, debe usar, por ejemplo, una variable que escribirá en algún lugar al principio de la configuración: fijará desde qué directorio se ejecutó el código y desde qué archivos nuevos deben incluirse. En una diapositiva, se llama
ROOT_DIR .
Use esta constante cuando acceda a todos los archivos dentro del código que usa en producción. Entonces obtiene la propiedad de atomicidad: las solicitudes que vienen antes de cambiar el enlace simbólico continúan incluyendo archivos del directorio anterior en el que no cambió nada, y las solicitudes nuevas que vinieron después del cambio de enlace simbólico comienzan a funcionar desde el nuevo directorio y se atienden nuevo código

Pero esto debe escribirse en el código. No todos los proyectos están listos para esto.
Estilo rasmus
Rasmus sugiere en lugar de modificar manualmente el código y crear constantes para modificar ligeramente Apache o usar nginx.
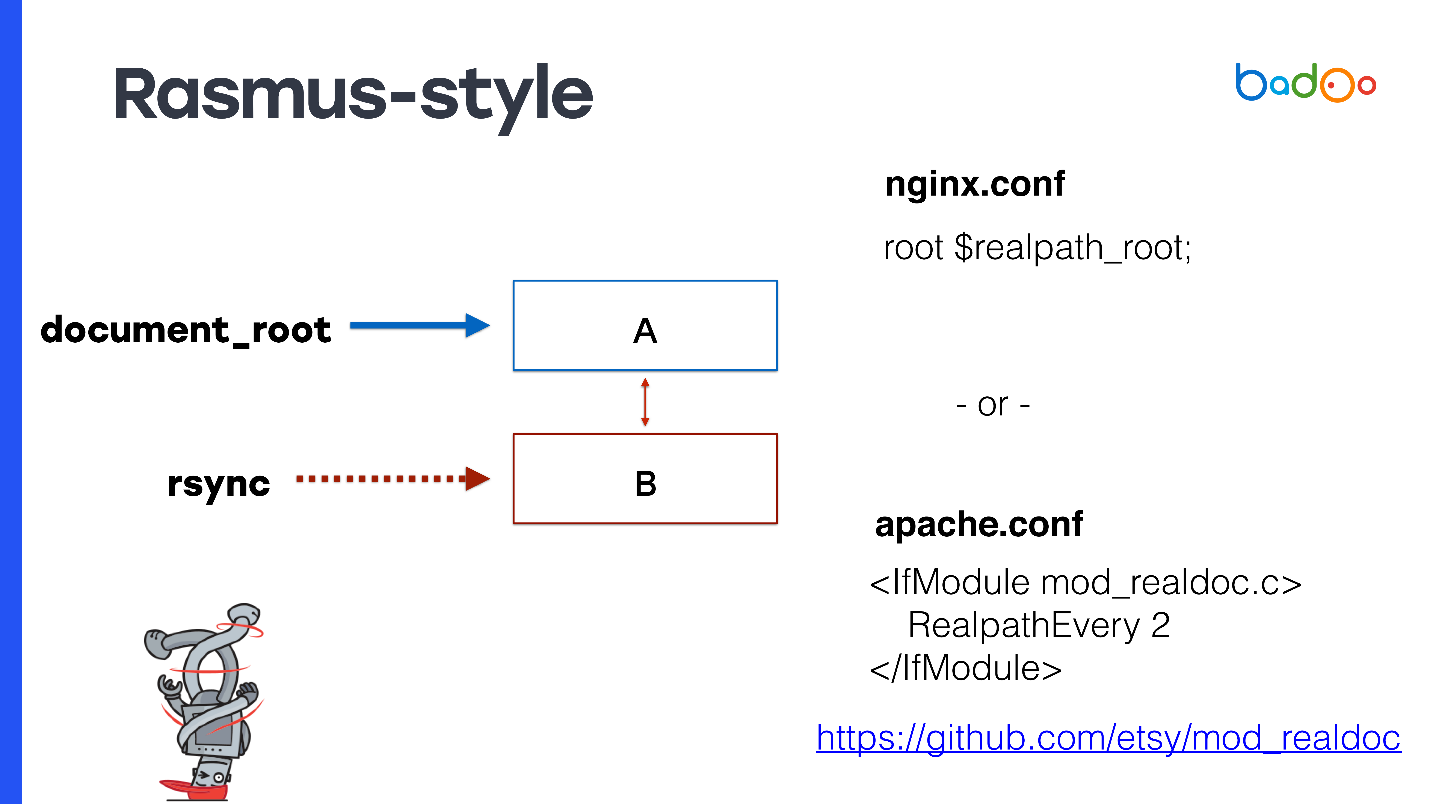
Para document_root, especifique el enlace simbólico a la última versión. Si tiene nginx, puede registrar
root $realpath_root , para Apache necesitará un módulo separado con la configuración que se puede ver en la diapositiva. Funciona así: cuando llega una solicitud, nginx o Apache de vez en cuando consideran realpath () de la ruta, la guardan de los enlaces simbólicos y pasan esta ruta como document_root. En este caso, document_root siempre apuntará a un directorio normal sin enlaces simbólicos, y es posible que su código PHP no tenga que pensar desde qué directorio se llama.
Este método tiene ventajas interesantes: las rutas reales llegan a OPCache PHP, no contienen enlaces simbólicos. Incluso el primer archivo al que llegó la solicitud ya estará lleno, y no habrá problemas con OPCache. Como se usa document_root, esto funciona con cualquier proyecto PHP. No necesitas adaptar nada.
No requiere la recarga de fpm, no es necesario restablecer OPCache durante la implementación, razón por la cual el servidor del procesador está muy ocupado, ya que debe analizar todos los archivos nuevamente. En mi experimento, restablecer OPCache en aproximadamente medio minuto aumentó el consumo del procesador en un factor de 2–3. Sería bueno reutilizarlo y este método le permite hacerlo.
Ahora los contras. Como no reutiliza OPCache y tiene 2 directorios, debe almacenar una copia del archivo en la memoria para cada directorio; en OPCache, se requiere 2 veces más memoria.
Hay otra limitación que puede parecer extraña:
no se puede implementar más de una vez cada max_execution_time . De lo contrario, se producirá el mismo problema, porque mientras rsync va a uno de los directorios, las solicitudes de este aún pueden procesarse.
Si usa Apache por alguna razón, entonces necesita un
módulo de terceros que Rasmus también escribió.
Rasmus dice que el sistema es bueno y se lo recomiendo a usted también. Para el 99% de los proyectos, es adecuado, tanto para proyectos nuevos como para proyectos existentes. Pero, por supuesto, no somos así y decidimos escribir nuestra propia decisión.
Nuevo sistema - MDK
Básicamente, nuestros requisitos no son diferentes de los requisitos para la mayoría de los proyectos web. Solo queremos una
implementación rápida en la preparación y producción,
bajo consumo de recursos , reutilización de OPCache y rápida reversión.
Pero hay dos requisitos más que pueden diferir del resto. En primer lugar, es la capacidad de
aplicar parches atómicamente . Nos referimos a los parches como cambios en uno o varios archivos que gobiernan algo en la producción. Queremos hacerlo rápido. En principio, el sistema que ofrece Rasmus está haciendo frente a la tarea de parche.
También tenemos
scripts de CLI que pueden ejecutarse durante varias horas , y aún deberían funcionar con una versión coherente del código. En este caso, las soluciones anteriores, desafortunadamente, no nos convienen o debemos tener muchos directorios.
Posibles soluciones:
- bucle xN (-staging, -docker, -opcache);
- rsync xN (-producción, -opcache xN);
- SVN xN (-producción, -opcache xN).
Aquí N es el número de cálculos que ocurren en unas pocas horas. Podemos tener docenas de ellos, lo que significa la necesidad de gastar una gran cantidad de espacio para copias adicionales del código.
Por lo tanto, se nos ocurrió un nuevo sistema y lo llamamos
MDK. Es sinónimo de
Multiversion Deployment Kit , una herramienta de implementación de múltiples versiones. Lo hicimos en base a los siguientes supuestos.
Tomamos la arquitectura de almacenamiento en árbol de Git. Necesitamos tener una versión coherente del código en el que funciona el script, es decir, necesitamos instantáneas. Las instantáneas son compatibles con LVM, pero allí son implementadas de manera ineficiente por sistemas de archivos experimentales como Btrfs y Git. Tomamos la implementación de instantáneas de Git.
Renombrado todos los archivos de file.php a file.php. <Versión>. Dado que todos los archivos que tenemos simplemente se almacenan en el disco, si queremos almacenar varias versiones del mismo archivo, debemos agregar un sufijo con la versión.
Me encanta Go, así que para la velocidad escribí un sistema en Go.Cómo funciona el kit de implementación multiversion
Tomamos la idea de las instantáneas de Git. Lo simplifiqué un poco y te cuento cómo se implementa en MDK.
Hay dos tipos de archivos en MDK. El primero son las
cartas. Las siguientes imágenes están marcadas en verde y corresponden a los directorios en el repositorio. El segundo tipo es
directamente los archivos, que se encuentran en el mismo lugar de siempre, pero con un sufijo en forma de versión de archivo. Los archivos y mapas se versionan en función de su contenido, en nuestro caso simplemente MD5.
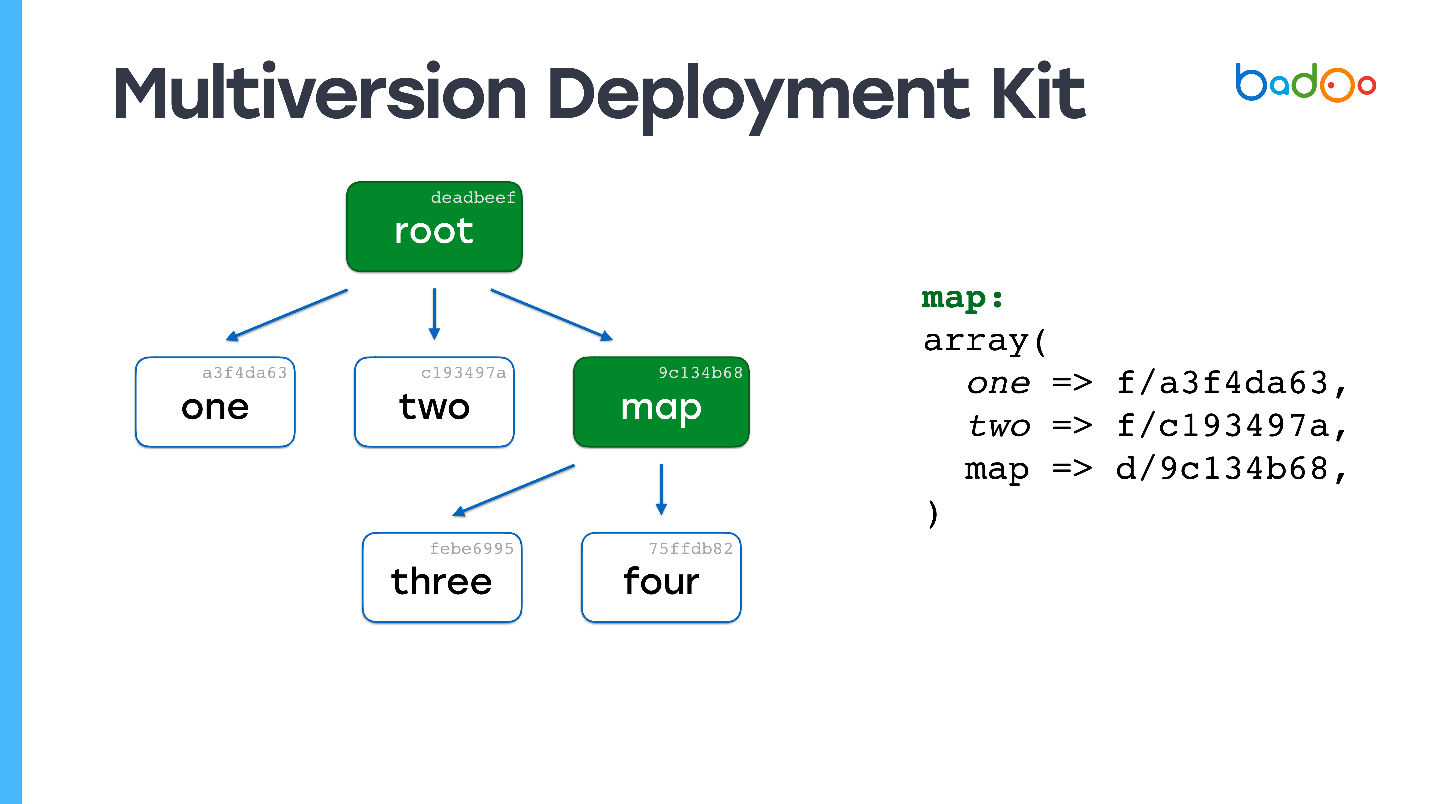
Supongamos que tenemos una jerarquía de archivos en la que el
mapa raíz se refiere a ciertas versiones de archivos de otros mapas y, a su vez, se refieren a otros archivos y mapas, y corrigen ciertas versiones. Queremos cambiar algún tipo de archivo.

Tal vez ya haya visto una imagen similar: cambiamos el archivo en el segundo nivel de anidación, y en el mapa correspondiente - mapa *, se actualiza la versión del archivo tres *, se modifica su contenido, se cambia la versión - y la versión también cambia en el mapa raíz. Si cambiamos algo, siempre obtenemos un nuevo mapa raíz, pero todos los archivos que no cambiamos se reutilizan.
Los enlaces permanecen en los mismos archivos que estaban. Esta es la idea principal de crear instantáneas de cualquier manera, por ejemplo, en
ZFS se implementa aproximadamente de la misma manera.
Cómo se encuentra MDK en un disco

Tenemos en el disco:
enlace simbólico al último mapa raíz : el código que se servirá desde la web, varias versiones de mapas raíz, varios archivos, posiblemente con diferentes versiones, y en los subdirectorios hay mapas para los directorios correspondientes.
Preveo la pregunta: "
¿Y cómo procesa esto la solicitud web? ¿A qué archivos llegará el código de usuario? "
Sí, te engañé, también hay archivos sin versiones, porque si recibes una solicitud de index.php y no la tienes en el directorio, el sitio no funcionará.

Todos los archivos PHP tienen archivos, que llamamos
stubs , porque contienen dos líneas: requieren del archivo en el que se declara la función que sabe cómo trabajar con estas tarjetas, y requieren de la versión deseada del archivo.
<?php require_once "mdk.inc"; require mdk_resolve_path("a.php");
Esto se hace así, y no se vincula a la última versión, ya que si excluye
b.php del archivo
a.php sin una versión, entonces dado que require_once está escrito, el sistema recordará desde qué tarjeta raíz comenzó, lo usará y Obtenga una versión consistente de los archivos.
Para el resto de los archivos, solo tenemos un enlace simbólico a la última versión.
Cómo implementar usando MDK
El modelo es muy similar al git push.
- Enviar el contenido del mapa raíz.
- En el lado receptor, observamos qué archivos faltan. Dado que la versión del archivo está determinada por el contenido, no necesitamos descargarlo por segunda vez ( Yuri del futuro: excepto en el caso en que choca un MD5 acortado, que todavía sucedió una vez en producción ).
- Solicitar el archivo faltante.
- Pasamos al segundo punto y más adelante en un círculo.
Ejemplo
Supongamos que hay un archivo llamado "uno" en el servidor. Envíele un mapa raíz.

En el mapa raíz, las flechas punteadas indican enlaces a archivos que no tenemos. Conocemos sus nombres y versiones porque están en el mapa. Los solicitamos al servidor. El servidor envía, y resulta que uno de los archivos también es una tarjeta.
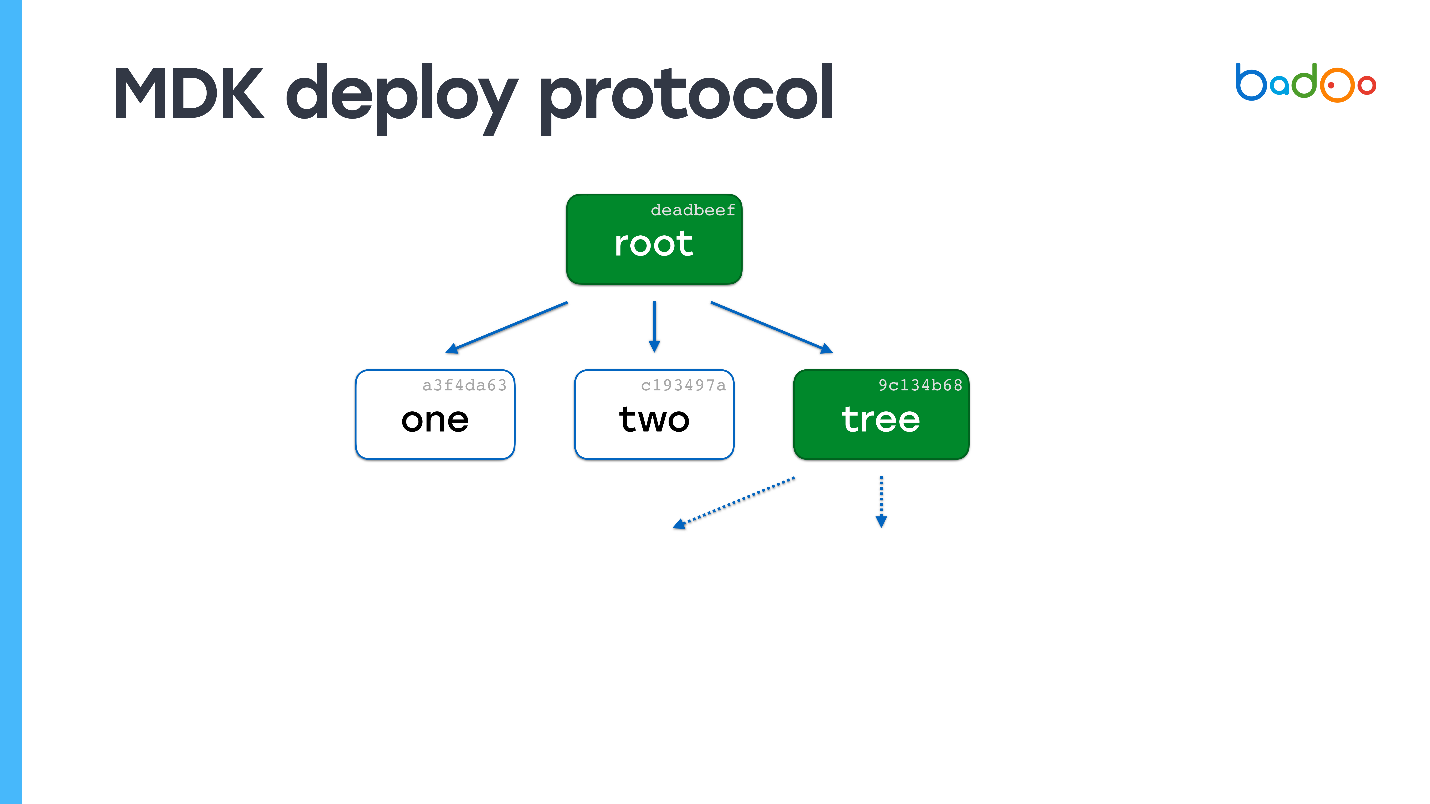
Buscamos, no tenemos un solo archivo en absoluto. Nuevamente solicitamos los archivos que faltan. El servidor los envía. No quedan más tarjetas: el proceso de implementación se ha completado.
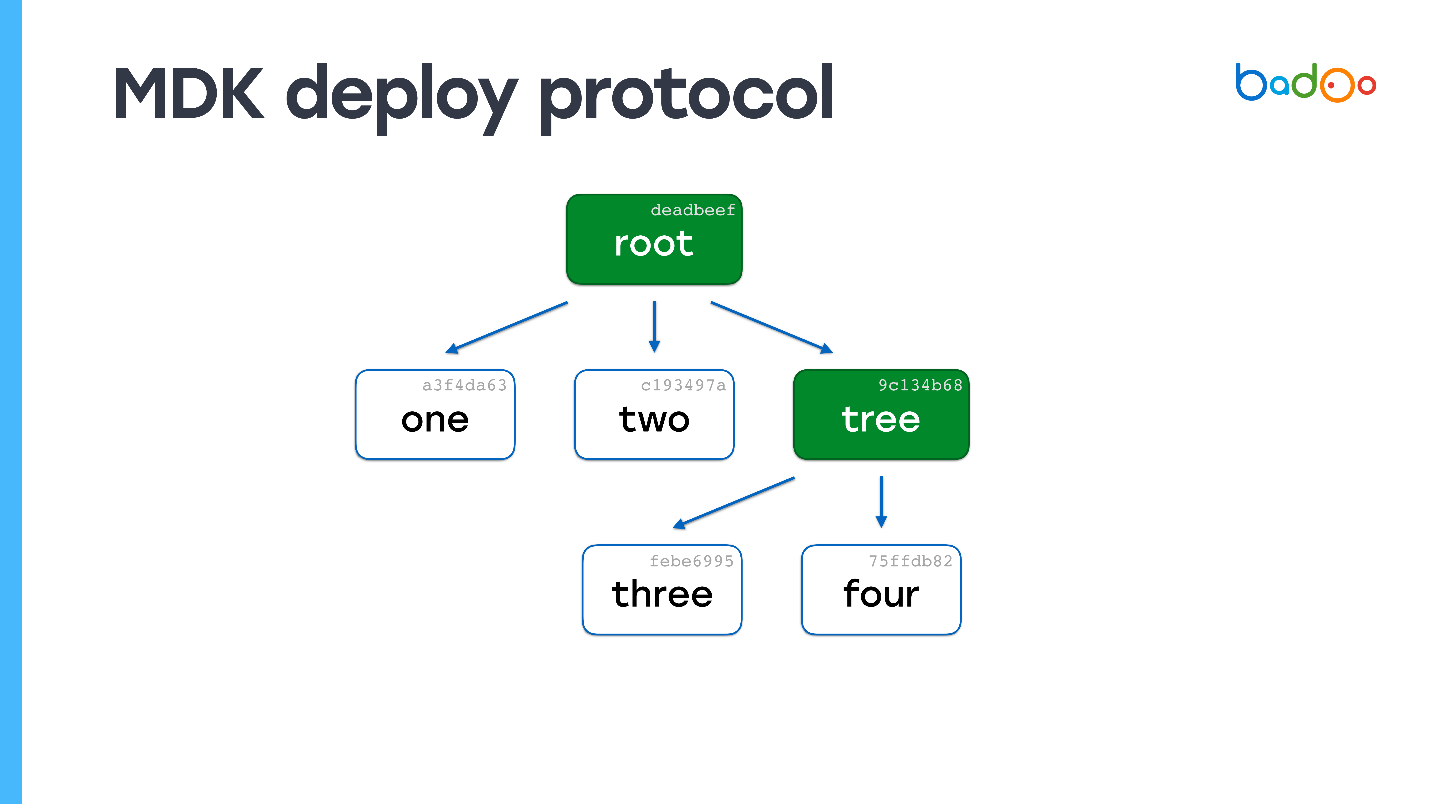
Puede adivinar fácilmente qué sucederá si los archivos son 150,000, pero uno ha cambiado. Veremos en el mapa raíz que falta un mapa, vamos por el nivel de anidamiento y obtengamos un archivo. En términos de complejidad computacional, el proceso casi no es diferente de copiar archivos directamente, pero al mismo tiempo, se conserva la consistencia y las instantáneas del código.
MDK no tiene inconvenientes :) Le permite
implementar cambios pequeños de forma rápida y atómica , y los
scripts funcionan durante días , porque podemos dejar todos los archivos que se implementaron en una semana. Ocuparán una cantidad de espacio bastante adecuada. También puede reutilizar OPCache, y la CPU no come casi nada.
El monitoreo es bastante difícil, pero posible . Todos los archivos están versionados por contenido, y puede escribir cron, que revisará todos los archivos y verificará el nombre y el contenido. También puede verificar que el mapa raíz se refiere a todos los archivos, que no hay enlaces rotos en él. Además, durante la implementación se verifica la integridad.
Puede
revertir fácilmente los cambios , porque todas las tarjetas antiguas están en su lugar. Podemos lanzar la tarjeta, todo estará allí de inmediato.
Para mí, además del hecho de que
MDK está escrito en Go significa que funciona rápidamente.
Te engañé de nuevo, todavía hay contras. Para que el proyecto funcione con el sistema,
se requiere una modificación significativa del código, pero es más simple de lo que parece a primera vista.
El sistema es muy complejo , no recomendaría implementarlo si no tiene requisitos como Badoo. Además, de todos modos, tarde o temprano el lugar termina, por lo que
se requiere el recolector de basura .
Escribimos utilidades especiales para editar archivos: reales, no stubs, por ejemplo, mdk-vim. Usted especifica el archivo, encuentra la versión deseada y la edita.
MDK en números
Tenemos 50 servidores en preparación, en los que implementamos durante 3-5 s
. En comparación con todo excepto rsync, es muy rápido. En
producción , implementamos unos
2 minutos , parches pequeños:
5-10 s .
Si por alguna razón ha perdido la carpeta completa con el código en todos los servidores (lo que nunca debería suceder :)), el
proceso de carga completa demora aproximadamente 40 minutos . Nos sucedió una vez, aunque de noche con un mínimo de tráfico. Por lo tanto, nadie resultó herido. El segundo archivo estuvo en un par de servidores durante 5 minutos, por lo que no vale la pena mencionarlo.
El sistema no está en código abierto, pero si está interesado, escriba los comentarios; puede ser presentado (
Yuri del futuro: el sistema todavía no está en código abierto en el momento de escribir este artículo ).
Conclusión
Escucha a Rasmus, no está mintiendo . En mi opinión, su método rsync junto con realpath_root es el mejor, aunque los bucles también funcionan bastante bien.
Piensa con la cabeza : mira exactamente lo que necesita tu proyecto y no intentes crear una nave espacial donde haya suficiente "maíz". Pero si aún tiene requisitos similares, entonces un sistema similar a MDK le conviene.
Decidimos volver a este tema, que se discutió en HighLoad ++ y, tal vez, no recibió la debida atención, porque era solo uno de los muchos ladrillos para lograr un alto rendimiento. Pero ahora tenemos una conferencia profesional independiente de PHP Rusia dedicada completamente a PHP. Y aquí realmente salimos al máximo. Hablaremos a fondo sobre el rendimiento , los estándares y las herramientas , mucho sobre eso, incluida la refactorización .
Suscríbase al canal Telegram con actualizaciones del programa de la conferencia y nos vemos el 17 de mayo.