Hola Habr!
Le recordamos que después del libro sobre
Kafka lanzamos un trabajo igualmente interesante sobre la biblioteca
API de Kafka Streams .

Hasta ahora, la comunidad solo comprende los límites de esta poderosa herramienta. Por lo tanto, recientemente se ha publicado un artículo, cuya traducción queremos presentarle. Según su propia experiencia, el autor explica cómo hacer un almacén de datos distribuido a partir de Kafka Streams. Que tengas una buena lectura!
La biblioteca de Apache
Kafka Streams en todo el mundo se utiliza en la empresa para el procesamiento de transmisión distribuida sobre Apache Kafka. Uno de los aspectos subestimados de este marco es que le permite almacenar un estado local basado en el procesamiento de transmisión.
En este artículo, le diré cómo nuestra empresa ha utilizado con éxito esta oportunidad para desarrollar un producto para la seguridad de las aplicaciones en la nube. Usando Kafka Streams, creamos microservicios de servicios compartidos, cada uno de los cuales sirve como una fuente de información confiable y altamente tolerante a fallas sobre el estado de los objetos en el sistema. Para nosotros, este es un paso adelante tanto en términos de confiabilidad como de facilidad de soporte.
Si está interesado en un enfoque alternativo que le permita utilizar una única base de datos central para respaldar el estado formal de sus objetos, lea, será interesante ...
Por qué pensamos que era hora de cambiar nuestros enfoques para trabajar con un estado compartidoNecesitábamos mantener el estado de varios objetos según los informes de los agentes (por ejemplo: ¿se atacó el sitio?) Antes de cambiar a Kafka Streams, a menudo confiamos en una única base de datos central (+ API de servicio) para administrar nuestro estado. Este enfoque tiene sus inconvenientes: en
situaciones de uso intensivo de datos, el soporte para la coherencia y la sincronización se convierte en un verdadero desafío. La base de datos puede convertirse en un cuello de botella, o puede estar en
condiciones de carrera y sufrir imprevisibilidad.
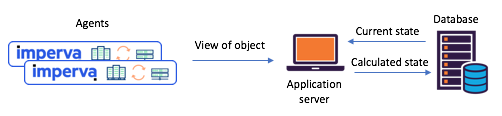 Figura 1: Un escenario típico de estado dividido encontrado antes de la transición a
Figura 1: Un escenario típico de estado dividido encontrado antes de la transición a
Kafka y Kafka Streams: los agentes comunican sus envíos a través de API, el estado actualizado se calcula a través de una base de datos centralConozca las transmisiones de Kafka: ahora es fácil crear microservicios de estado compartidoHace aproximadamente un año, decidimos revisar a fondo nuestros escenarios de estado compartido para hacer frente a tales problemas. Inmediatamente decidimos probar Kafka Streams: sabemos cuán escalable, altamente accesible y tolerante a fallas, cuán rica es su funcionalidad de transmisión (transformaciones, incluidas las con estado). Justo lo que necesitábamos, sin mencionar lo maduro y confiable que era el sistema de mensajería en Kafka.
Cada uno de los microservicios que preservan el estado que creamos se creó sobre la base de la instancia de Kafka Streams con una topología bastante simple. Consistía en 1) una fuente 2) un procesador con un almacenamiento permanente de claves y valores 3) drenaje:
 Figura 2: La topología predeterminada de nuestras instancias de transmisión para microservicios con estado. Tenga en cuenta que también hay un repositorio que contiene metadatos de planificación.
Figura 2: La topología predeterminada de nuestras instancias de transmisión para microservicios con estado. Tenga en cuenta que también hay un repositorio que contiene metadatos de planificación.Con este nuevo enfoque, los agentes redactan mensajes que se envían al tema original y los consumidores, por ejemplo, un servicio de notificación por correo, aceptan el estado compartido calculado a través del stock (tema de salida).
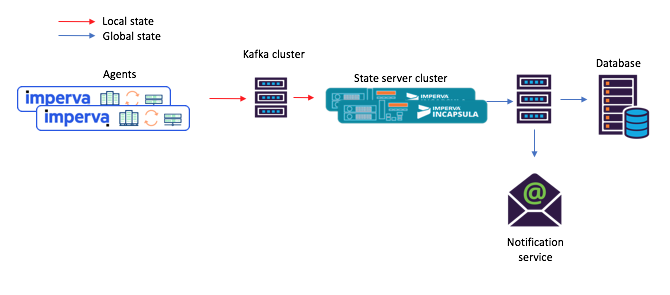 Figura 3: un nuevo ejemplo de un flujo de tareas para un escenario con microservicios compartidos: 1) el agente genera un mensaje que llega al tema original de Kafka; 2) un microservicio con un estado compartido (usando Kafka Streams) lo procesa y escribe el estado calculado en el tema final de Kafka; después de lo cual 3) los consumidores aceptan el nuevo estado¡Hola, este repositorio integrado de claves y valores es realmente muy útil!
Figura 3: un nuevo ejemplo de un flujo de tareas para un escenario con microservicios compartidos: 1) el agente genera un mensaje que llega al tema original de Kafka; 2) un microservicio con un estado compartido (usando Kafka Streams) lo procesa y escribe el estado calculado en el tema final de Kafka; después de lo cual 3) los consumidores aceptan el nuevo estado¡Hola, este repositorio integrado de claves y valores es realmente muy útil!Como se mencionó anteriormente, nuestra topología de estado compartido contiene un almacén de claves y valores. Encontramos varias opciones para su uso, y dos de ellas se describen a continuación.
Opción n. ° 1: usar el almacén de claves y el almacén de valores para los cálculosNuestro primer repositorio de claves y valores contenía datos auxiliares que necesitábamos para los cálculos. Por ejemplo, en algunos casos, el estado compartido se determinó sobre la base de un principio de "voto mayoritario". En el repositorio era posible mantener todos los últimos informes de agentes sobre el estado de un determinado objeto. Luego, al recibir un nuevo informe de un agente, podríamos guardarlo, extraer informes del resto del agente sobre el estado del mismo objeto del repositorio y repetir el cálculo.
La Figura 4 a continuación muestra cómo abrimos el acceso al almacén de claves y valores al método de procesamiento del procesador, para que luego podamos procesar el nuevo mensaje.
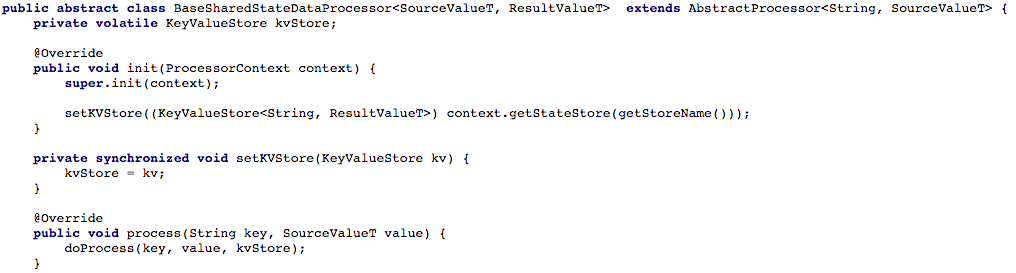 Figura 4: abrimos el acceso al almacenamiento de claves y valores para el método de procesamiento del procesador (después de eso, en cada script que trabaje con un estado compartido, debe implementar el método
Figura 4: abrimos el acceso al almacenamiento de claves y valores para el método de procesamiento del procesador (después de eso, en cada script que trabaje con un estado compartido, debe implementar el método doProcess )Opción # 2: crear una API CRUD encima de Kafka StreamsDespués de ajustar nuestro flujo básico de tareas, comenzamos a intentar escribir una API RESTful CRUD para nuestros microservicios de servicios compartidos. Queríamos poder extraer el estado de algunos o todos los objetos, así como establecer o eliminar el estado del objeto (esto es útil con el soporte del lado del servidor).
Para admitir todas las API de Get State, cada vez que necesitábamos volver a calcular el estado durante el procesamiento, lo colocamos en el repositorio incorporado de claves y valores durante mucho tiempo. En este caso, se vuelve bastante simple implementar dicha API usando una sola instancia de Kafka Streams, como se muestra en la lista a continuación:
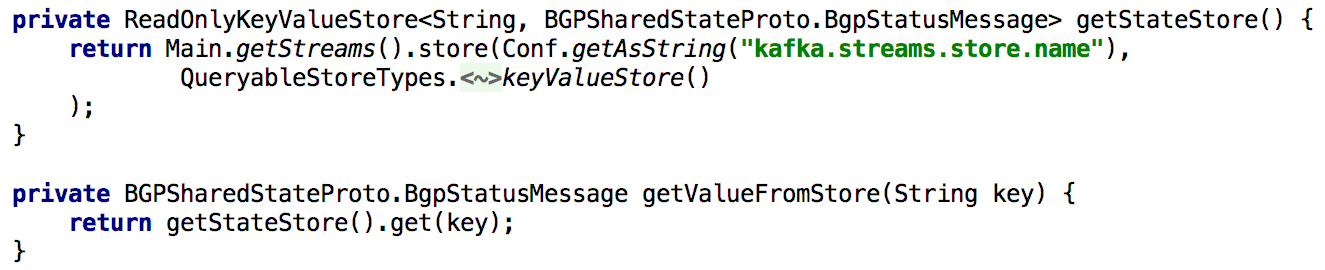 Figura 5: uso del almacenamiento incorporado de claves y valores para obtener el estado precalculado de un objeto
Figura 5: uso del almacenamiento incorporado de claves y valores para obtener el estado precalculado de un objetoActualizar el estado de un objeto a través de la API también es fácil de implementar. En principio, para esto solo necesita crear un productor Kafka, y con su ayuda hacer un registro en el que se haga un nuevo estado. Esto garantiza que todos los mensajes generados a través de la API se procesarán de la misma manera que se reciben de otros productores (por ejemplo, agentes).
 Figura 6: Puede establecer el estado de un objeto utilizando el productor KafkaUna complicación menor: Kafka tiene muchas particiones.
Figura 6: Puede establecer el estado de un objeto utilizando el productor KafkaUna complicación menor: Kafka tiene muchas particiones.Luego, queríamos distribuir la carga de procesamiento y mejorar la disponibilidad al proporcionar un clúster de microservicios de servicio compartido para cada escenario. La configuración se nos proporcionó de la manera más simple posible: después de configurar todas las instancias para que funcionaran con la misma ID de aplicación (y con los mismos servidores de arranque), casi todo lo demás se hizo automáticamente. También establecemos que cada tema fuente consistirá en varias particiones, de modo que a cada instancia se le pueda asignar un subconjunto de tales particiones.
También mencionaré que es normal hacer una copia de seguridad de la tienda estatal, de modo que, por ejemplo, en caso de recuperación después de una falla, transfiera esta copia a otra instancia. Para cada tienda de estado en Kafka Streams, se crea un tema replicado con un registro de cambios (en el que se realiza un seguimiento de las actualizaciones locales). Por lo tanto, Kafka asegura constantemente la tienda estatal. Por lo tanto, en caso de falla de una u otra instancia de Kafka Streams, la tienda de estado se puede restaurar rápidamente a otra instancia, donde irán las particiones correspondientes. Nuestras pruebas mostraron que esto se puede hacer en segundos, incluso si hay millones de registros en el repositorio.
Al pasar de un microservicio de servicio compartido a un grupo de microservicios, resulta menos trivial implementar la API Get State. En la nueva situación, el repositorio de estado de cada microservicio contiene solo una parte de la imagen general (aquellos objetos cuyas claves se asignaron a una partición particular). Teníamos que determinar en qué instancia estaba contenido el estado del objeto que necesitábamos, y lo hicimos en función de los metadatos de flujo, como se muestra a continuación:
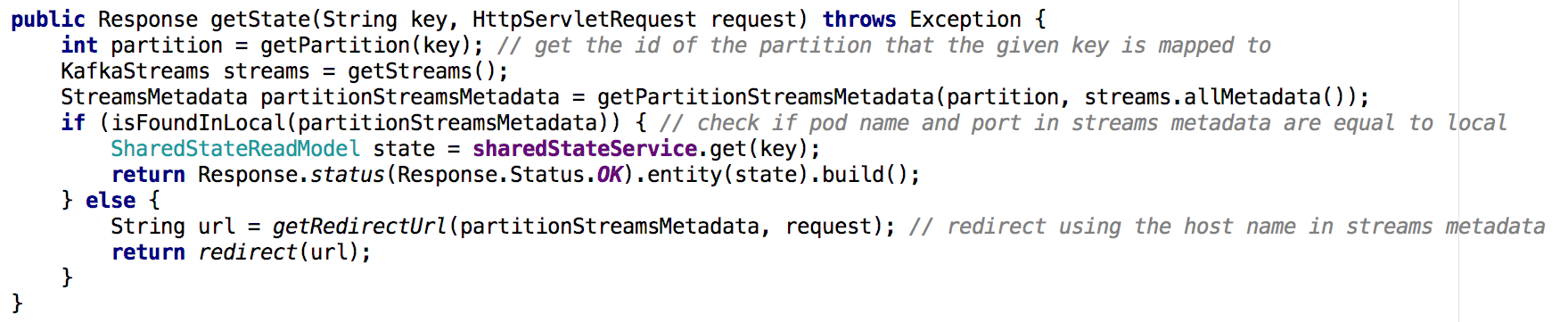 Figura 7: utilizando metadatos de flujo determinamos desde qué instancia solicitar el estado del objeto deseado; Se utilizó un enfoque similar con la API GET ALLResultados clave
Figura 7: utilizando metadatos de flujo determinamos desde qué instancia solicitar el estado del objeto deseado; Se utilizó un enfoque similar con la API GET ALLResultados claveLas tiendas estatales en Kafka Streams pueden, de facto, servir como una base de datos distribuida,
- replicado continuamente en kafka
- Además de dicho sistema, se construye fácilmente la API CRUD
- Procesar múltiples particiones es un poco más complicado
- También es posible agregar uno o más almacenes de estado a la topología de flujo para almacenar datos auxiliares. Esta opción se puede usar para:
- Almacenamiento a largo plazo de datos necesarios para cálculos en el procesamiento de transmisión
- Almacenamiento a largo plazo de datos que pueden ser útiles la próxima vez que se inicialice la instancia de flujo
- mucho mas ...
Gracias a estas y otras ventajas, Kafka Streams es ideal para soportar el estado global en un sistema distribuido como el nuestro. Kafka Streams demostró ser muy confiable en producción (desde el momento de su implementación, prácticamente no perdimos mensajes), ¡y estamos seguros de que esto no se limita a sus capacidades!