Bueno, ya sabemos todo lo que necesitas para programar UDB. Pero una cosa es saber y otra muy distinta poder. Por lo tanto, hoy discutiremos dónde y cómo inspirarnos para mejorar nuestras propias habilidades, dónde adquirir experiencia. Como se puede ver en la
traducción de la documentación , existe un conocimiento seco que no siempre está vinculado a la práctica real (llamé la atención sobre esto en una nota bastante larga, hasta la última traducción hasta la fecha). En realidad, las estadísticas de las vistas de artículos muestran que cada vez menos personas leen traducciones. Incluso hubo una propuesta para interrumpir este ciclo, como poco interesante, pero solo quedaron dos partes, por lo tanto, al final, simplemente se decidió reducir el ritmo de su preparación. En general, la documentación para el controlador es algo necesario, pero no autosuficiente. ¿Dónde más obtener inspiración?

En primer lugar, puedo recomendar el excelente documento
AN82156 Diseño de componentes de PSoC Creator con UDB Datapaths . En él encontrará soluciones típicas, así como varios proyectos estándar. Además, al comienzo del documento, el desarrollo se lleva a cabo utilizando el Editor UDB, y hacia el final, utilizando la Herramienta de configuración de Datapath, es decir, el documento cubre todos los aspectos del desarrollo. Pero desafortunadamente, mirando el precio de un solo chip PSoC, diría que si solo puede resolver los problemas descritos en este documento, el controlador está sobrevalorado. Los PWM y los puertos serie estándar se pueden hacer sin PSoC. Afortunadamente, el rango de tareas de PSoC es mucho más amplio. Por lo tanto, después de terminar de leer AN82156, comenzamos a buscar otras fuentes de inspiración.
La siguiente fuente útil son los ejemplos que vienen con PSoC Creator. Ya me referí a ellos en una nota a una de las partes de la traducción de la documentación de la compañía (puede ver
aquí ). Se almacenan aproximadamente aquí (el disco puede diferir):
E: \ Archivos de programa (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ psoc \ content \ CyComponentLibrary.
Debes buscar archivos * .v, es decir, textos de verilog o * .vhd, ya que la sintaxis del lenguaje VHDL requiere un poco más de descripción, y en este lenguaje a veces puedes encontrar matices interesantes ocultos a los ojos del programador en Verilog. El problema es que estos no son ejemplos, sino soluciones preparadas. Esto es maravilloso, están perfectamente depurados, pero nosotros, los programadores simples, tenemos diferentes objetivos con los programadores de Cypress. Nuestra tarea es hacer algo auxiliar en poco tiempo, después de lo cual comenzamos a usarlo en nuestros proyectos, en los que pasaremos la mayor parte del tiempo. Idealmente debería resolver las tareas que se nos asignaron hoy, y si mañana queremos insertar el mismo código en otro proyecto, donde todo será ligeramente diferente, mañana lo terminaremos en esa situación. Para los desarrolladores de Cypress, el componente es el producto final, por lo que pueden pasar la mayor parte del tiempo en él. Y deben proporcionar para todo-todo-todo. Entonces, cuando vi estos textos, me sentí triste. Son demasiado complejos para alguien que acaba de comenzar a buscar dónde inspirarse para sus primeros desarrollos. Pero como referencias, estos textos son bastante adecuados. Hay muchos diseños valiosos que se necesitan al crear sus propias cosas.
También hay rincones muy interesantes. Por ejemplo, hay, ahora diré en el estilo de "aceite de mantequilla", modelos para modelar (hace mucho tiempo, un maestro severo me desanimó de traducir la simulación de otra manera que no sea "modelar"). Se pueden encontrar en el catálogo.
E: \ Archivos de programa (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim.
El directorio más interesante para el programador en Verilogue es:
E: \ Archivos de programa (x86) \ Cypress \ PSoC Creator \ 4.2 \ PSoC Creator \ warp \ lib \ sim \ presynth \ vlg.
La descripción de los componentes en la documentación es buena. Pero los modelos de comportamiento para todos los componentes estándar se describen aquí. A veces, esto es mejor que la documentación (que está escrita en un lenguaje pesado, además de que se omiten algunos detalles esenciales). Cuando el comportamiento de este o aquel componente no está claro, vale la pena comenzar los intentos de comprenderlo con precisión al ver los archivos de este directorio. Al principio traté de buscar en Google, pero muy a menudo me encontré en los foros encontrados solo razonamiento y sin detalles. Aquí están precisamente los detalles.
Sin embargo, el libro de referencia es maravilloso, pero ¿dónde buscar un libro de texto, de qué aprender? Honestamente, no hay nada especial. No hay muchos buenos ejemplos listos para UDB Editor. Tuve mucha suerte de que cuando de repente decidí jugar con LEDs RGB, me encontré con un hermoso ejemplo bajo el Editor UDB (escribí sobre eso en un
artículo que comenzó todo el ciclo). Pero si trabajas mucho con un motor de búsqueda, todavía habrá ejemplos para la herramienta de configuración de Datapath, por lo que hice el
artículo anterior para que todos entiendan cómo usar esta herramienta. Y aquí se encuentra una página maravillosa en la que se recopilan muchos ejemplos.
En esta página hay desarrollos realizados por desarrolladores externos, pero verificados por Cypress. Es decir, justo lo que necesitamos: también somos desarrolladores externos, pero queremos aprender de algo que se verifica con precisión. Veamos un ejemplo donde encontré esta página: una calculadora de hardware de raíz cuadrada. Los usuarios finales lo incluyen en la ruta de procesamiento de la señal, lanzando un componente al circuito. En este ejemplo, entrenaremos para analizar un código similar, y luego todos podrán comenzar a nadar de forma independiente. Entonces, el ejemplo necesario se puede descargar desde el
enlace .
Lo examinamos Hay ejemplos (que todos considerarán independientemente) y hay bibliotecas ubicadas en el directorio \ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib.
Para cada tipo (entero o punto fijo) y para cada bit, hay una solución. Esto debe tenerse en cuenta. La versatilidad es buena cuando se desarrolla en el Editor UDB, pero cuando se desarrolla utilizando la Herramienta de edición de Datapath, como puede ver, la gente se atormenta de esta manera. No tengas miedo si no puedes hacerlo universalmente (pero si funciona mejor).
En el nivel superior (circuitos), no pararé, estamos estudiando no trabajando con PSoC, sino trabajando con UDB. Veamos una opción de complejidad media: 16 bits, pero entera. Se encuentra en el directorio CJCU_B_Isqrt16_v1_0.
Lo primero que debe hacer es expandir el gráfico de transición del firmware. Sin él, ni siquiera podremos adivinar qué tipo de algoritmo de raíz cuadrada se ha aplicado, ya que Google ofrece una selección de varios algoritmos fundamentalmente diferentes.
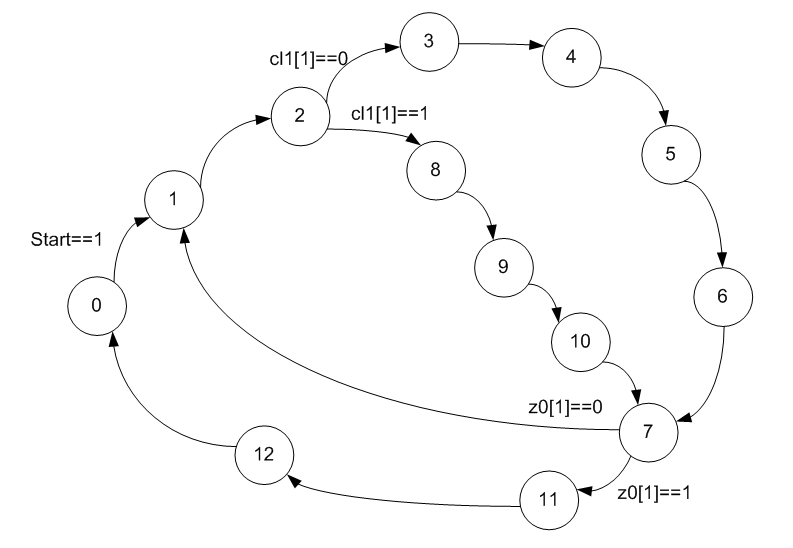
Hasta ahora, nada está claro, pero es predecible. Necesito agregar más información. Nos fijamos en la codificación de estado. Llama la atención que no están codificados en el código binario incremental habitual.

Ya he mencionado este enfoque en mis artículos, pero nunca he podido usarlo en ejemplos específicos. Permítame recordarle que la configuración dinámica de RAM ALU tiene solo tres entradas de dirección. Es decir, ALU puede realizar una de las ocho operaciones. Si el autómata tiene más estados, entonces la regla "cada estado tiene su propia operación" se vuelve imposible. Por lo tanto, se seleccionan estados en los que las operaciones para la ALU son idénticas, tienen tres bits suministrados a la dirección RAM de la configuración dinámica (generalmente de orden inferior), se codifican de la misma manera y el resto de diferentes maneras. Cómo agregar tal solitario ya es un problema del desarrollador. Los desarrolladores del código estudiado doblaron exactamente como se muestra arriba.
Agregue esta información al gráfico, además de colorear los estados que realizan la misma función en ALU en colores similares.
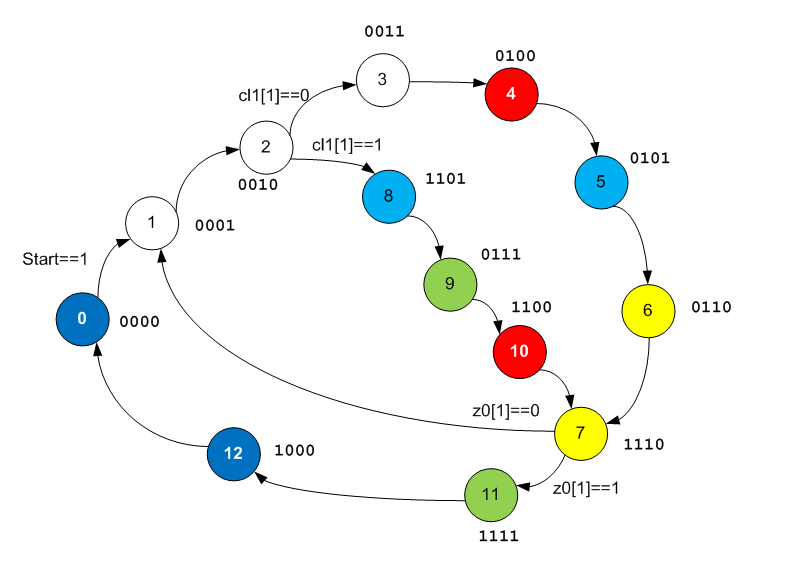
Aún no se han manifestado patrones, pero continuamos abriendo el gráfico. Abrimos Datapath Edit Tool y estudiamos la lógica que ya está en ella.
Tenga en cuenta que tenemos dos bloques Datapath conectados en una cadena. Cuando hacemos algo por nuestra cuenta, también podemos necesitar esto (aunque, la herramienta de edición de Datapath puede crear bloques ya vinculados en una cadena, por lo que esto no da miedo):
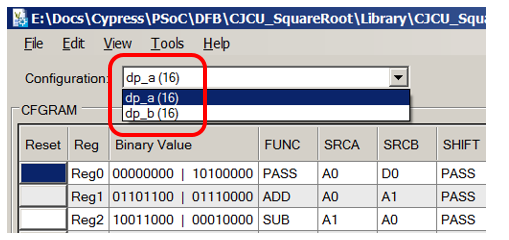
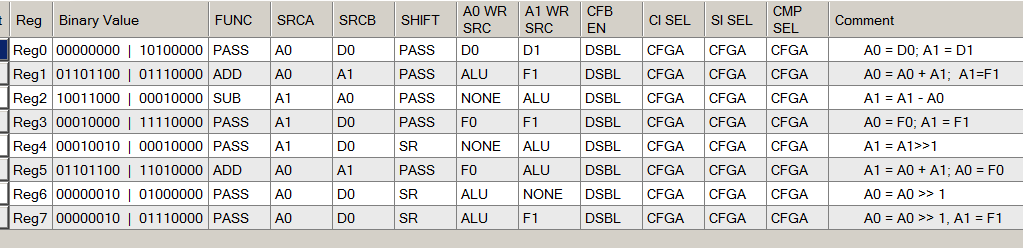
Al leer (y completar) el gráfico correspondiente a ALU, siempre abrimos un documento con la siguiente figura:

Es cierto que los desarrolladores de este ejemplo nos cuidaron y completaron los campos de comentarios. Ahora podemos usarlos para comprender para qué está configurado. Al mismo tiempo, notamos por nosotros mismos que escribir comentarios siempre es útil tanto para quienes acompañarán el código como para nosotros, cuando en seis meses lo olvidaremos todo.
Observamos el código X000 correspondiente a los estados 0 y 12:

A partir del comentario, ya está claro lo que está sucediendo allí (los contenidos del registro D0 se copian en el registro A0, y los contenidos de D1 se copian en el registro A1. Sabiendo esto, entrenamos nuestra intuición para el futuro y encontramos una entrada similar en los campos de configuración:

Allí vemos que la ALU funciona en modo
PASS , el registro de desplazamiento también es
PASS , por lo que no se realizan realmente otras acciones.
En el camino, miramos el texto en Verilog y vemos dónde es igual el valor de los registros D0 y D1:

Si lo desea, se puede ver lo mismo en la herramienta de configuración de Datapath, seleccionando Ver-> Valores de registro iniciales:
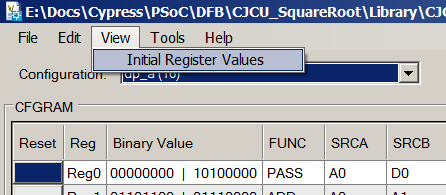
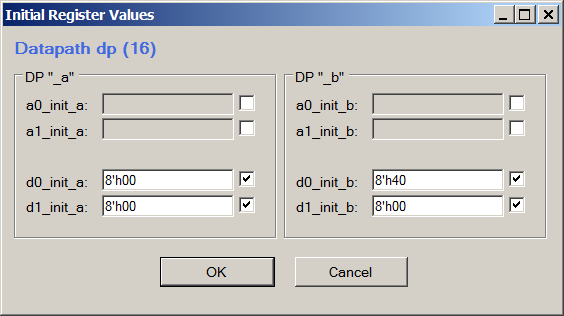
Para ver, es más conveniente analizar directamente el código Verilog, para crear su propia versión: trabaje a través del editor para no tener en cuenta la sintaxis.
Del mismo modo, analizamos (primero, mirando en los comentarios) todas las otras funciones de ALU:
Rehacemos el gráfico de transición del autómata teniendo en cuenta los nuevos conocimientos:

Ya se avecina algo, pero hasta ahora no puedo confiar con confianza en ninguno de los algoritmos encontrados por Google en este gráfico. Más bien, sobre algunos puedes decir con confianza que no son ellos, pero incluso para los creíbles, todavía no puedo dar una respuesta segura de que son ellos. Confunde el uso activo de los registros FIFO F0 y F1. Generalmente en el archivo
\ CJCU_SquareRoot \ Library \ CJCU_SquareRoot.cylib \ CJCU_Isqrt_v1_0 \ API \ CJCU_Isqrt.c
Se puede ver que F1 se utiliza para pasar el argumento y devolver el resultado:

Mismo texto:void `$INSTANCE_NAME`_ComputeIsqrtAsync(uint`$regWidth` square) { /* Set up FIFOs, start the computation. */ CY_SET_REG`$dpWidth`(`$INSTANCE_NAME`_F1, square); CY_SET_REG8(`$INSTANCE_NAME`_CTL, 0x01); } … uint`$resultWidth` `$INSTANCE_NAME`_ReadIsqrtAsync() { /* Read back result. */ return CY_GET_REG`$dpWidth`(`$INSTANCE_NAME`_F1); }
Pero un argumento y un resultado. ¿Y por qué hay tantas llamadas a FIFO en el curso del trabajo? ¿Y qué tiene que ver FIFO0 con él? Me cortó en pedazos, pero parece que los autores aprovecharon el modo que se encontró en las traducciones de la documentación, cuando en lugar de un FIFO completo, este bloque actuó como un registro único. Supongamos que los autores deciden expandir el conjunto de registros. Si es así, entonces su metodología nos será útil en nuestro trabajo práctico, estudiemos los detalles. De hecho, la documentación habla sobre diferentes enfoques para trabajar con FIFO. Puedes, así que puedes, pero puedes, más o menos. Y sin detalles. Nuevamente tenemos la oportunidad de aprender sobre las mejores prácticas internacionales. ¿Qué hacen los autores con FIFO?
Primero, estas son las asignaciones de señal:
wire f0_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_4); wire f1_load = (state == B_SQRT_STATE_1 || state == B_SQRT_STATE_3 || state == B_SQRT_STATE_9 || state == B_SQRT_STATE_11); wire fifo_dyn = (state == B_SQRT_STATE_0 || state == B_SQRT_STATE_12);
En segundo lugar, aquí hay una conexión con Datapath:
/* input */ .f0_load(f0_load), /* input */ .f1_load(f1_load), /* input */ .d0_load(1'b0), /* input */ .d1_load(fifo_dyn),
Según la descripción del controlador, no está particularmente claro qué significa todo esto. Pero de la Nota de aplicación, descubrí que esta configuración es la culpable de todo:

Por cierto, precisamente debido a esta configuración, este bloque no se puede describir con el Editor UDB. Cuando estos bits de control están en estado
ON , FIFO puede trabajar en diferentes fuentes y receptores. Si
Dx_LOAD es igual a uno,
Fx intercambia con el bus del sistema, si es cero, entonces con el registro seleccionado aquí:

Resulta que F0 siempre intercambia con el registro A0 y F1 en los estados 12 y 0, con el bus del sistema (para cargar el resultado y cargar el argumento), en otros estados, con A1.
Además, a partir del código Verilog, descubrimos que en F0 los datos se cargarán en los estados 1 y 4, y en F1 - en los estados 1, 3, 9, 11.
Agregue los conocimientos adquiridos a la gráfica. Para evitar confusiones durante la secuencia de operaciones, también era hora de reemplazar la marca de asignación "a la UDB Editor" con las flechas de Verilogov para enfatizar que la fuente es el valor de la señal que tenía antes de ingresar al bloque.

Desde el punto de vista del análisis del algoritmo, todo ya está claro. Ante nosotros hay una modificación de dicho algoritmo:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 30; // The second-to-top bit is set: use 1u << 14 for uint16_t type; use 1uL<<30 for uint32_t type // "one" starts at the highest power of four <= than the argument. while (one > op) { one >>= 2; } while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; }
Solo en relación con nuestro sistema se verá más así:
uint32_t SquareRoot(uint32_t a_nInput) { uint32_t op = a_nInput; uint32_t res = 0; uint32_t one = 1uL << 14; // The second-to-top bit is set while (one != 0) { if (op >= res + one) { op -= res + one; res += one << 1; } res >>= 1; one >>= 2; } return res; }
Los estados 4 y 10 codifican explícitamente la cadena:
res >>= 1;
para diferentes ramas
La linea es:
one >>= 2;
está explícitamente codificado por un par de estados 6 y 7, o un par de estados 9 y 7. Por ahora, quiero exclamar: "¡Bueno, los inventores son los mismos autores!", pero muy pronto se hará evidente por qué hay tanta dificultad con dos ramas (en el código C hay una rama y solución alternativa).
El estado 2 codifica una rama condicional. El estado 7 codifica una declaración de bucle. La operación de comparación en el paso 2 es muy costosa. En general, en la mayoría de los pasos, el registro A0 contiene la variable. Pero en el paso 1, la variable uno se descarga a F0, y en su lugar
se carga el valor
res + one , luego en el paso 2 se realiza la resta con el propósito de comparación, y en los pasos 3 y 8, se restaura el valor de
uno . Por qué, en el paso 4, A0 se copia a F0 nuevamente, no lo entendí. Quizás esto sea algún tipo de rudimento.
Queda por descubrir quién es
res y quién es
op . Sabemos que la condición compara op y res + one. En el estado 1, se agregan A0 (
uno ) y A1. Así que A1 es
res . Resulta que en el estado 11 A1 también es
res , y es él quien entra en F1, que se alimenta a la salida de la función. F1 en el estado 1 es claramente
op . Propongo introducir la diferenciación de color de los
pantalones de las variables. Denotamos
res como rojo,
op como verde y
uno como marrón (no del todo contrastado, pero los otros colores son aún menos contrastados).
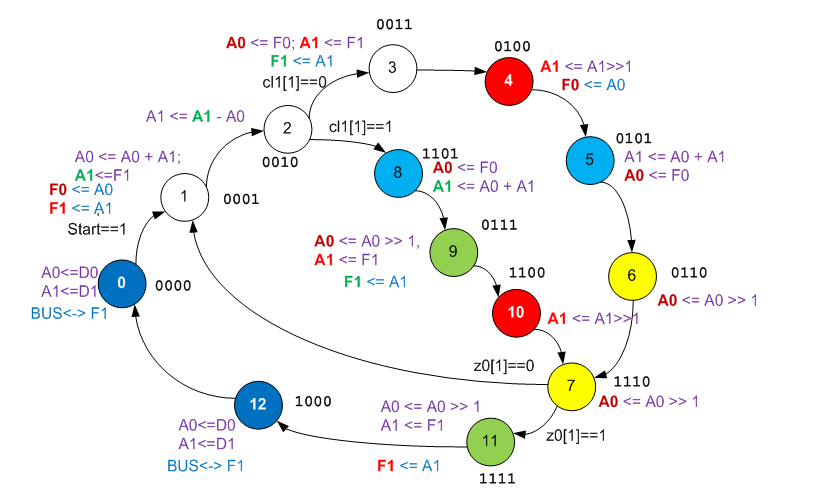
En realidad, toda la verdad se revela. Vemos cómo A1 cambia temporalmente de F1 para la comparación y los cálculos, cómo se usa la misma diferencia tanto para la comparación (en realidad, generar el bit C) como para participar en la fórmula. Incluso vemos por qué el espacio vacío (bypass) en el algoritmo C está codificado por una rama larga del gráfico de transición del autómata (en esta rama, los registros se intercambian de manera idéntica al intercambio que ocurre en la rama del código principal). Lo vemos todo
La única pregunta que nunca deja de atormentarme es ¿cómo cambiaron los autores FIFO al modo de un solo byte? La documentación dice que para esto necesita elevar los bits CLR en el registro de Control Auxiliar en una unidad, pero no veo que la API tenga dichos registros. Quizás alguien lo entienda y escriba en los comentarios.
Bueno, y desarrollar algo propio, en orden inverso, utilizando las habilidades adquiridas.
Conclusión
Para desarrollar las habilidades de desarrollar "firmware" basado en UDB, es útil no solo leer la documentación, sino también inspirarse en los diseños de otras personas. El código que viene con PSoC Creator puede ser útil como referencia, y los modelos de comportamiento incluidos con el compilador lo ayudarán a comprender mejor lo que se entiende en la documentación. El artículo también proporciona un enlace a un conjunto de ejemplos de terceros fabricantes y muestra el proceso de analizar uno de esos ejemplos.
En este sentido, el ciclo de artículos de copyright sobre el trabajo con UDB puede considerarse completado. Me alegraría si ayudara a alguien a obtener conocimientos útiles en la práctica. Hay un par de traducciones de documentación por delante, pero las estadísticas muestran que casi nadie las lee. Se planean limpiamente para no dejar caer el tema en pocas palabras.