En el proceso de transición de una aplicación monolítica a una arquitectura de microservicio, nos enfrentamos a nuevos problemas.
En una aplicación monolítica, generalmente es bastante simple determinar en qué parte del sistema se produjo un error. Lo más probable es que el problema esté en el código del propio monolito o en la base de datos. Pero cuando comenzamos a buscar un problema en la arquitectura de microservicios, no todo es tan obvio. Debe encontrar la ruta completa de acceso de la solicitud de principio a fin, para seleccionarla entre cientos de microservicios. Además, muchos de ellos también tienen sus propios repositorios, que también pueden causar errores lógicos, así como problemas con el rendimiento y la tolerancia a fallas.

Durante mucho tiempo estuve buscando una herramienta que me ayudara a enfrentar tales problemas (escribí sobre ello en Habré: 1 , 2 ), pero al final hice mi propia solución de código abierto. En el artículo, hablo sobre los beneficios del enfoque de malla de servicios y comparto una nueva herramienta para su implementación.
El rastreo distribuido es una solución común al problema de encontrar errores en sistemas distribuidos. Pero, ¿qué sucede si el sistema aún no ha implementado un enfoque de este tipo para recopilar información sobre las interacciones de la red o, lo que es peor, en la parte del sistema que ya funciona correctamente y en la parte que no, ya que no se agrega a los servicios antiguos? Para determinar la causa raíz exacta del problema, debe tener una imagen completa de lo que está sucediendo en el sistema. Es especialmente importante comprender qué microservicios están involucrados en las principales rutas críticas del negocio.
Aquí, un enfoque de malla de servicios puede ayudarnos, que se ocupará de toda la maquinaria para recopilar información de la red a un nivel inferior al que hacen los propios servicios. Este enfoque nos permite interceptar todo el tráfico y analizarlo sobre la marcha. Además, las aplicaciones al respecto ni siquiera deberían saber nada.
Enfoque de malla de servicio
La idea principal del enfoque de malla de servicios es agregar otra capa de infraestructura a través de la red, lo que nos permitirá hacer cualquier cosa con la interacción entre servicios. La mayoría de las implementaciones funcionan de la siguiente manera: se agrega un contenedor de sidecar adicional con un proxy transparente a cada microservicio, a través del cual se pasa todo el tráfico de servicio entrante y saliente. Y este es el lugar donde podemos hacer un balance de clientes, aplicar políticas de seguridad, introducir restricciones en el número de solicitudes y recopilar información importante sobre la interacción de los servicios en la producción.
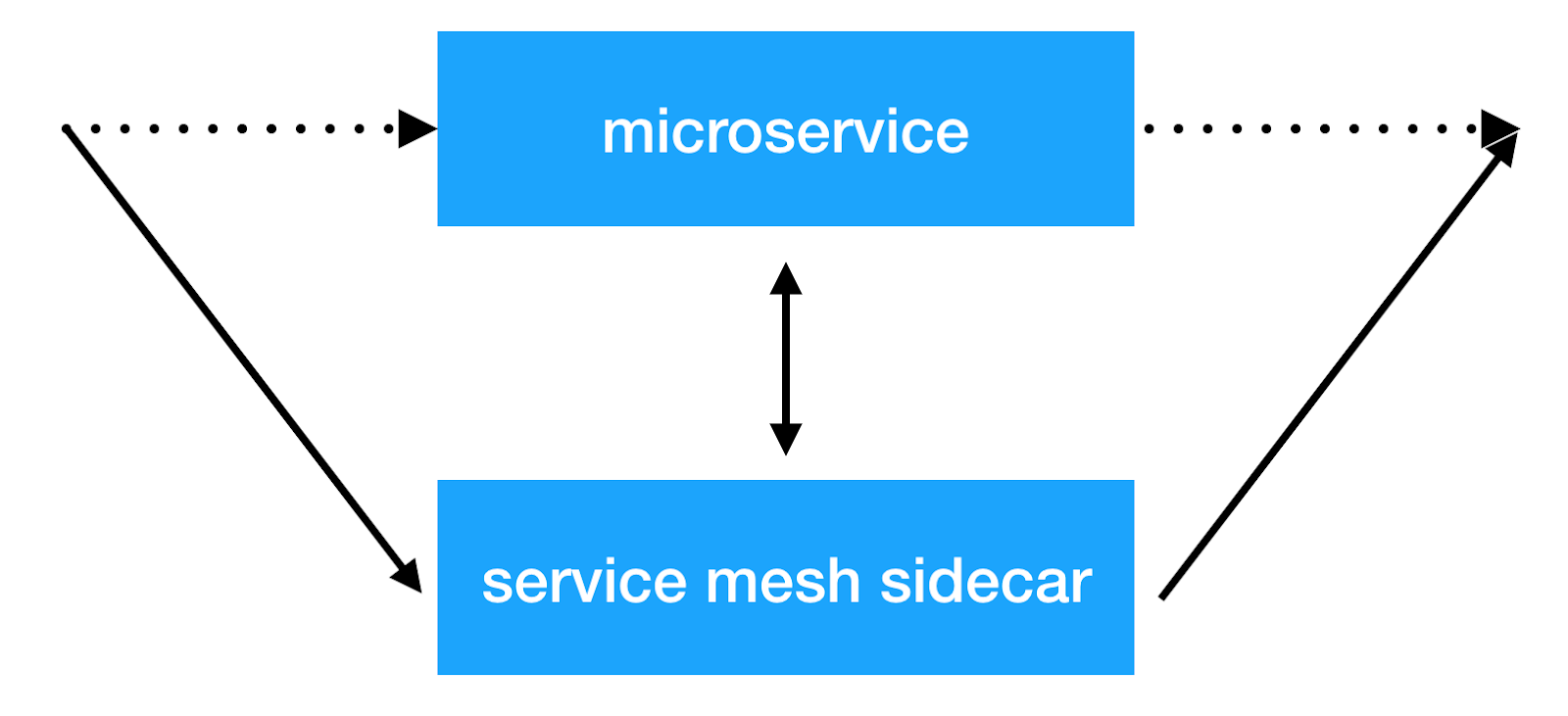
Soluciones
Ya hay varias implementaciones de este enfoque: Istio y linkerd2 . Proporcionan muchas características fuera de la caja. Pero al mismo tiempo, una gran sobrecarga viene a los recursos. Además, cuanto más grande sea el clúster en el que funciona dicho sistema, más recursos se necesitarán para mantener la nueva infraestructura. En Avito, operamos clústeres de kubernetes con miles de instancias de servicio (y su número continúa creciendo rápidamente). En la implementación actual, Istio consume ~ 300Mb de RAM por instancia de servicio. Debido a la gran cantidad de funciones, el equilibrio transparente también afecta el tiempo total de respuesta de los servicios (hasta 10 ms).
Como resultado, observamos exactamente qué características necesitábamos en este momento y decidimos que la razón principal por la que comenzamos a implementar tales soluciones fue la capacidad de recopilar información de rastreo de todo el sistema de manera transparente. También queríamos tener control sobre la interacción de los servicios y hacer varias manipulaciones con los encabezados que se transfieren entre los servicios.
Al final, llegamos a nuestra decisión: Netramesh .
Netramesh
Netramesh es una solución de malla de servicios liviana con escalabilidad infinita, independientemente de la cantidad de servicios en el sistema.
Los objetivos principales de la nueva solución eran una pequeña sobrecarga de recursos y un alto rendimiento. De las características principales, de inmediato queríamos poder enviar de forma transparente tramos de rastreo a nuestro sistema Jaeger.
Hoy, la mayoría de las soluciones en la nube se implementan en Golang. Y, por supuesto, hay razones para esto. Escribir aplicaciones de red de Golang que funcionen de forma asíncrona con E / S y escalar a los núcleos según sea necesario es conveniente y bastante simple. Y, lo que también es muy importante, el rendimiento es suficiente para resolver este problema. Por lo tanto, también elegimos Golang.
Rendimiento
Hemos centrado nuestros esfuerzos en lograr el máximo rendimiento. Para una solución que se implementa junto a cada instancia del servicio, se requiere un pequeño consumo de RAM y tiempo de procesador. Y, por supuesto, la demora en responder también debe ser pequeña.
Veamos cuáles son los resultados.
RAM
Netramesh consume ~ 10Mb sin tráfico y un máximo de 50Mb con una carga de hasta 10,000 RPS por instancia.
El proxy de Istio Envoy siempre consume ~ 300Mb en nuestros clústeres con miles de instancias. Esto no le permite escalarlo a todo el clúster.
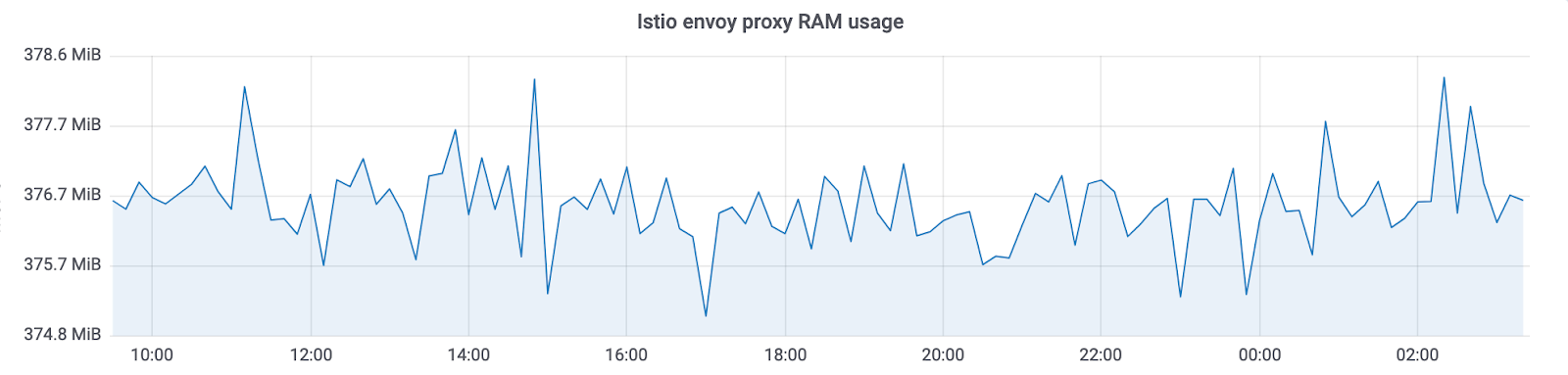

Con Netramesh, obtuvimos ~ 10 veces menos consumo de memoria.
CPU
El uso de la CPU es relativamente igual bajo carga. Depende del número de solicitudes por unidad de tiempo para sidecar. Valores a 3000 solicitudes por segundo en el pico:


Hay otro punto importante: Netramesh: una solución sin un plano de control y sin carga no consume tiempo de CPU. Con Istio, los sidecar siempre actualizan los puntos finales del servicio. Como resultado, podemos ver una imagen sin carga:

Usamos HTTP / 1 para comunicarnos entre servicios. El aumento en el tiempo de respuesta de Istio cuando se procesó a través de un enviado fue de hasta 5-10 ms, lo que es bastante para los servicios que están listos para responder en un milisegundo. Con Netramesh, esta vez disminuyó a 0.5-2ms.
Escalabilidad
Una pequeña cantidad de recursos gastados por cada proxy hace posible colocarlo al lado de cada servicio. Netramesh fue creado intencionalmente sin un componente de plano de control para simplemente mantener la ligereza de cada sidecar. A menudo en soluciones de malla de servicio, el plano de control distribuye información de descubrimiento de servicio a cada sidecar. Junto con ella viene información sobre tiempos de espera, ajustes de equilibrio. Todo esto le permite hacer muchas cosas útiles, pero, desafortunadamente, se infla de tamaño lateral.
Descubrimiento de servicio

Netramesh no agrega ningún mecanismo adicional para el descubrimiento de servicios. Todo el tráfico se representa de forma transparente a través del sidecar netra.
Netramesh admite el protocolo de aplicación HTTP / 1. Se utiliza una lista configurable de puertos para determinarlo. Por lo general, hay varios puertos en un sistema que se comunican a través de HTTP. Por ejemplo, usamos 80, 8890, 8080 para interactuar con los servicios y las solicitudes externas. En este caso, se pueden configurar utilizando la NETRA_HTTP_PORTS entorno NETRA_HTTP_PORTS .
Si usa Kubernetes como una orquesta y su mecanismo de entidades de Servicio para la interacción dentro del clúster entre servicios, entonces el mecanismo permanece exactamente igual. Primero, el microservicio obtiene la dirección IP del servicio usando kube-dns y le abre una nueva conexión. Esta conexión se establece primero con el netra-sidecar local, y todos los paquetes TCP llegan inicialmente a netra. A continuación, netra-sidecar establece una conexión con el destino original. NAT en el pod IP en el nodo permanece exactamente igual que sin netra.
Rastreo distribuido y desplazamiento de contexto
Netramesh proporciona la funcionalidad necesaria para enviar tramos de rastreo sobre interacciones HTTP. Netra-sidecar analiza el protocolo HTTP, mide los retrasos en las solicitudes y recupera la información necesaria de los encabezados HTTP. En última instancia, obtenemos todos los rastros en un solo sistema Jaeger. Para el ajuste, también puede usar las variables de entorno proporcionadas por la biblioteca oficial de jaeger go .


Pero hay un problema. Hasta que los servicios generen y reenvíen un encabezado uber especial, no veremos los tramos de rastreo conectados en el sistema. Y esto es lo que necesitamos para encontrar rápidamente la causa de los problemas. Aquí Netramesh tiene una solución nuevamente. Los proxies leen los encabezados HTTP y, si no tienen una identificación de seguimiento uber, la generan. Netramesh también almacena información sobre solicitudes entrantes y salientes en sidecar y las compara al enriquecer los encabezados necesarios de las solicitudes salientes. Todo lo que debe hacerse en los servicios es lanzar solo un encabezado X-Request-Id , que se puede configurar utilizando la NETRA_HTTP_REQUEST_ID_HEADER_NAME entorno NETRA_HTTP_REQUEST_ID_HEADER_NAME . Para controlar el tamaño del contexto en Netramesh, puede establecer las siguientes variables de entorno: NETRA_TRACING_CONTEXT_EXPIRATION_MILLISECONDS (el tiempo durante el cual se almacenará el contexto) y NETRA_TRACING_CONTEXT_CLEANUP_INTERVAL (periodicidad de limpieza de contexto).
También es posible combinar varias rutas en su sistema marcándolas con un marcador de sesión especial. Netra le permite configurar HTTP_HEADER_TAG_MAP para convertir los encabezados HTTP en etiquetas de trazo de seguimiento adecuadas. Esto puede ser especialmente útil para las pruebas. Después de pasar la prueba funcional, puede ver qué parte del sistema se ha visto afectada por el filtrado por la clave de sesión correspondiente.
Determinar el origen de la solicitud
Para determinar de dónde vino la solicitud, puede usar la función para agregar automáticamente un encabezado con una fuente. Con la NETRA_HTTP_X_SOURCE_HEADER_NAME entorno NETRA_HTTP_X_SOURCE_HEADER_NAME puede especificar el nombre del encabezado que se establecerá automáticamente. Usando NETRA_HTTP_X_SOURCE_VALUE puede establecer el valor en el que se establecerá el encabezado X-Source para todas las solicitudes salientes.
Esto le permite uniformemente en toda la red para hacer la distribución de este útil encabezado. Entonces ya puede usarlo en servicios y agregarlo a registros y métricas.
Tráfico de Netramesh y enrutamiento interno
Netramesh consta de dos componentes principales. El primero, netra-init, establece reglas de red para interceptar el tráfico. Utiliza las reglas de redireccionamiento de iptables para interceptar todo o parte del tráfico en el sidecar, que es el segundo componente principal de Netramesh. Puede configurar qué puertos desea interceptar para las sesiones TCP entrantes y salientes: INBOUND_INTERCEPT_PORTS, OUTBOUND_INTERCEPT_PORTS .
La herramienta también tiene una característica interesante: enrutamiento probabilístico. Si usa Netramesh exclusivamente para recopilar tramos de rastreo, en un entorno de producción puede ahorrar recursos y habilitar el enrutamiento probabilístico utilizando las variables NETRA_INBOUND_PROBABILITY y NETRA_OUTBOUND_PROBABILITY (de 0 a 1). El valor predeterminado es 1 (se intercepta todo el tráfico).
Después de una intercepción exitosa, netra sidecar acepta una nueva conexión y usa la opción de socket SO_ORIGINAL_DST para obtener el destino original. Netra luego abre una nueva conexión a la dirección IP original y establece una comunicación TCP bidireccional entre las partes, escuchando todo el tráfico que pasa. Si el puerto se define como HTTP, Netra intentará analizarlo y enrutarlo. Si el análisis HTTP no tiene éxito, Netra recurrirá a TCP y bytes proxy transparentes.
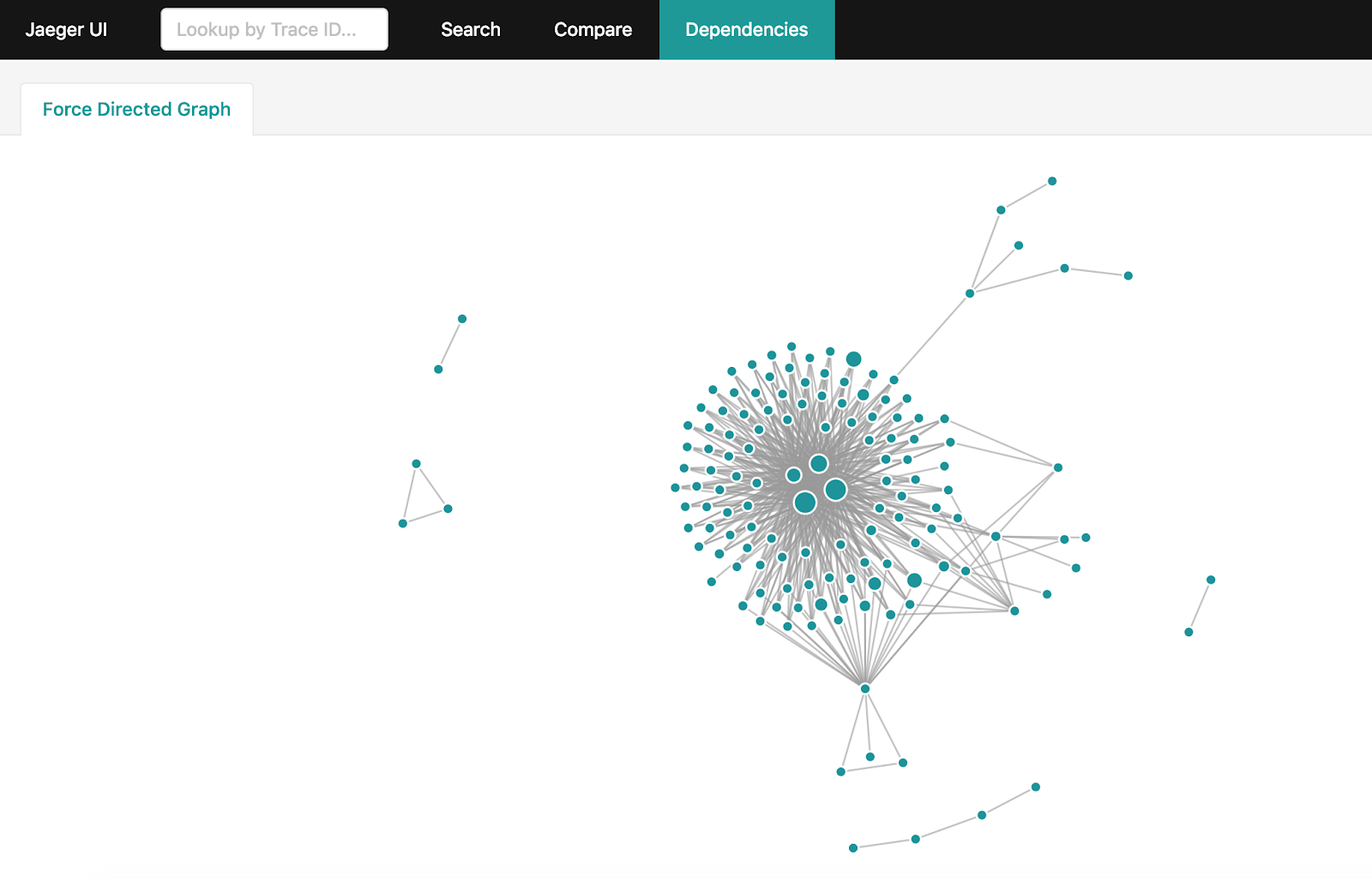
Construyendo un gráfico de dependencia
Después de recibir mucha información de rastreo en Jaeger, quiero obtener un gráfico completo de interacciones en el sistema. Pero si su sistema está suficientemente cargado y se acumulan miles de millones de tramos de rastreo por día, hacer que su agregación no sea una tarea tan simple. Hay una forma oficial de hacer esto: las dependencias de chispa . Sin embargo, llevará horas construir el gráfico completo y forzar la descarga de todo el conjunto de datos de Jaeger en las últimas 24 horas.
Si usa Elasticsearch para almacenar tramos de rastreo, puede usar una utilidad simple en Golang que construirá el mismo gráfico en minutos usando las características y capacidades de Elasticsearch.
Cómo usar Netramesh
Netra simplemente se puede agregar a cualquier servicio que ejecute cualquier orquestador. Puedes ver un ejemplo aquí .
Por el momento, Netra no tiene la capacidad de implementar automáticamente el sidecar en los servicios, pero hay planes para su implementación.
Netramesh futuro
El objetivo principal de Netramesh es lograr costos mínimos de recursos y un alto rendimiento, proporcionando las principales oportunidades para la observabilidad y el control de la interacción entre servicios.
En el futuro, Netramesh recibirá soporte para protocolos de nivel de aplicación que no sean HTTP. En el futuro cercano habrá la posibilidad de enrutamiento L7.
Use Netramesh si encuentra problemas similares y escríbanos preguntas y sugerencias.