Según el informe del desarrollador senior Sergey Murylyov, puede obtener información sobre el contenedor asociativo multiproceso para la biblioteca estándar, que se está desarrollando como parte de WG21. Sergey habló sobre los pros y los contras de las soluciones populares a este problema y el camino elegido por los desarrolladores.
- Probablemente ya haya adivinado por el título que el informe de hoy será sobre cómo nosotros, en el marco del Grupo de trabajo 21, hicimos nuestro contenedor similar a std :: unordered_map, pero para un entorno de subprocesos múltiples.
En muchos lenguajes de programación, Java, C #, Python, esto ya existe y se usa bastante. Pero en nuestro querido, más rápido y productivo C ++, esto no sucedió. Pero consultamos y decidimos hacer tal cosa.

Antes de agregar algo al estándar, debe pensar en cómo las personas lo usarán. Luego, para hacer una interfaz más correcta, que probablemente será adoptada por el comité, preferiblemente sin enmiendas. Y para que al final no hubiera tal cosa que hicieran una cosa, pero resultó otra.
La opción más famosa y ampliamente utilizada es el almacenamiento en caché de computación pesada grande. Existe un servicio Memcached bastante conocido que simplemente almacena en caché las respuestas del servidor web en la memoria. Está claro que puede hacer aproximadamente lo mismo en el lado de su solicitud, si tiene un contenedor asociativo competitivo. Ambos enfoques tienen sus pros y sus contras. Pero si no tiene ese contenedor, tendrá que hacer su propia bicicleta o usar algún tipo de Memcached.
Otro caso de uso popular es la deduplicación de eventos. Creo que muchos en esta sala escriben todo tipo de sistemas distribuidos y saben que a menudo se usan colas distribuidas para comunicarse entre componentes, como Apache Kafka y Amazon Kinesis. Se distinguen por una característica tal que pueden enviar un mensaje a un consumidor varias veces. Esto se llama al menos una vez entrega, lo que significa una garantía de entrega al menos una vez: más es posible, menos no.
Considere esto en términos de la vida real. Imagine que tenemos un servidor de alguna sala de chat o red social donde se realizan mensajes. Esto puede llevar al hecho de que alguien escribió un mensaje y más tarde alguien recibió una notificación automática en su teléfono móvil varias veces. Está claro que si los usuarios ven esto, no estarán contentos con eso. Se argumenta que este problema se puede resolver con un maravilloso contenedor multiproceso.
El siguiente caso, menos utilizado es cuando solo necesitamos guardar algo en algún lugar del lado del servidor, algunos metadatos para el usuario. Por ejemplo, podemos ahorrar el tiempo en que el usuario se autenticó por última vez, para entender cuándo la próxima vez se le debe solicitar su nombre de usuario y contraseña.
La última opción en esta diapositiva son las estadísticas. A partir de aplicaciones de la vida real, se puede dar un ejemplo de uso en una máquina virtual de Facebook. Crearon una máquina virtual completa para optimizar PHP y en su máquina virtual intentan escribir los argumentos con los que fueron llamados a una tabla hash de subprocesos múltiples para todas las funciones integradas. Y si tienen un resultado en el caché, entonces tratan de regalarlo de inmediato y no contar nada.

Agregar algo grande y complicado al estándar no es fácil ni rápido. Como regla general, si se agrega algo grande, pasa por la especificación técnica. Actualmente, el estándar se está moviendo mucho para expandir el soporte de subprocesos múltiples en la biblioteca estándar. Y específicamente, la propuesta P0260R3 sobre colas multiproceso está llegando allí ahora mismo. Esta propuesta trata sobre una estructura de datos muy similar a la nuestra, y nuestras decisiones de diseño son muy similares en muchos aspectos.
En realidad, uno de los conceptos básicos de su diseño es que su interfaz es diferente de la estándar std :: queue. Cual es el punto? Si observa la cola estándar, para extraer un elemento de ella, debe realizar dos operaciones. Debe realizar una operación frontal para contar y una operación emergente para eliminar. Si trabajamos en condiciones de subprocesos múltiples, entonces podemos tener algún tipo de operación en la cola entre estas dos llamadas, y puede suceder que consideremos un elemento y eliminemos otro, lo que parece conceptualmente incorrecto. Por lo tanto, estas dos llamadas fueron reemplazadas allí por una, y se agregaron algunas llamadas más de la categoría de prueba push y try pop. Pero la idea general es que un contenedor multiproceso no será lo mismo que una interfaz normal.
Las colas multiproceso también tienen muchas implementaciones diferentes que resuelven varias tareas diferentes. La tarea más común es la tarea de productores y consumidores, cuando tenemos algunos hilos que producen algunas tareas y hay algunos hilos que toman tareas de la cola y las procesan.
El segundo caso es cuando solo necesitamos tener algún tipo de cola sincronizada. En el caso de fabricantes y consumidores, obtenemos una cola que se limita a la parte superior e inferior. Si tratamos, relativamente hablando, de extraer de una cola vacía, entramos en un estado de espera. Y lo mismo ocurre aproximadamente si tratamos de agregar algo que no encaja en el tamaño de la cola.
También en esta propuesta se describe que tenemos una interfaz hecha por separado que nos permite distinguir qué implementación tenemos dentro del bloqueo, o sin bloqueo. El hecho de que aquí en todas partes de la propuesta esté escrito sin bloqueo, de hecho, está escrito en libros como esperar gratis. Esto significa que nuestro algoritmo funciona para un número fijo de operaciones. Bloquear gratis allí significa un poco diferente, pero ese no es el punto.
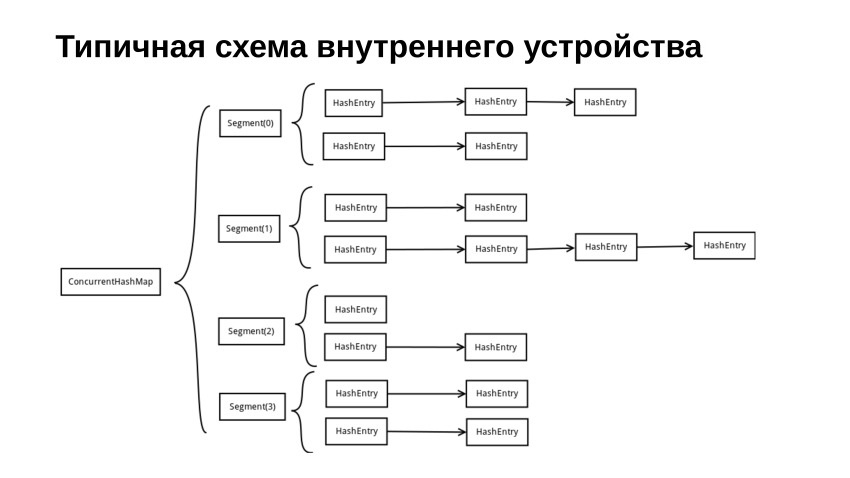
Veamos un diagrama típico de cómo se vería la implementación de nuestra tabla hash si está bloqueada. Lo tenemos dividido en varios segmentos. Cada segmento, por regla general, contiene algún tipo de bloqueo, como Mutex, Spinlock o algo aún más complicado. Y además de Mutex o Spinlock, también contiene la tabla hash habitual, que está protegida por este negocio.
En esta imagen, tenemos una tabla hash, que se encuentra en las listas. De hecho, en nuestra implementación de referencia, escribimos una tabla hash con direccionamiento abierto por razones de rendimiento. Las consideraciones de rendimiento son básicamente las mismas que por qué std :: vector es más rápido que std :: list porque el vector, relativamente hablando, se almacena secuencialmente en la memoria. Cuando lo seguimos, tenemos acceso secuencial, que está bien almacenado en caché. Si usamos algún tipo de hojas, tendremos todo tipo de saltos entre diferentes secciones de la memoria. Y todo, como regla, termina con el hecho de que perdemos productividad.
Al principio, cuando queremos encontrar algo en esta tabla hash, tomamos el código hash de la clave. Puede tomar el módulo y hacer algo más con él para que obtengamos el número de segmento, y en el segmento que estamos buscando, como en una tabla hash normal, pero al mismo tiempo, por supuesto, tomamos el candado.

Las ideas principales de nuestro diseño. Por supuesto, también creamos una interfaz que no coincide con std :: unordered_map. La razón es esta. Por ejemplo, en std :: unordered_map ordinario tenemos algo maravilloso como iteradores. En primer lugar, no todas las implementaciones pueden soportarlas normalmente. Y aquellos que pueden soportar, por regla general, son algún tipo de implementaciones sin bloqueo que requieren una recolección de basura o algún tipo de punteros inteligentes que limpian la memoria detrás de él.
Además de esto, hay varios otros tipos de operaciones que descartamos. De hecho, iteradores, están en muchos lugares. Por ejemplo, están en Java. Pero, como regla, por extraño que parezca, no se sincronizan allí. Y si intenta hacer algo con ellos desde diferentes subprocesos, pueden pasar fácilmente a un estado no válido, y puede obtener una excepción en Java, y si escribe esto en las ventajas, lo más probable es que este sea un comportamiento indefinido, que es aún peor . Y, por cierto, sobre el tema del comportamiento indefinido: en mi opinión, los camaradas de Facebook en la locura de su biblioteca, que se publica en código abierto en GitHub, hicieron exactamente eso. Simplemente copié la interfaz con Java y obtuve iteradores tan maravillosos.
Tampoco tenemos una queja de memoria, es decir, si agregamos algo al contenedor y tomamos memoria para ello, no lo devolveremos, incluso si eliminamos todo. Otro requisito previo para esta decisión era que teníamos una tabla hash con direccionamiento abierto en el interior. Funciona en una estructura de datos lineal, que como el vector no devuelve memoria.
El siguiente momento conceptual es que bajo ninguna circunstancia entregaremos a nadie enlaces externos e indicadores a objetos internos. Esto se hizo precisamente para evitar la necesidad de una recolección de basura y no para aplicar punteros inteligentes. Está claro que si almacenamos algunos objetos lo suficientemente grandes, almacenarlos por valor dentro no será rentable. Pero, en este caso, siempre podemos envolverlos en algún tipo de punteros inteligentes de nuestra elección. Y, si queremos, por ejemplo, hacer algún tipo de sincronización en los valores, podemos envolverlos en algún tipo de boost :: synchronized_value.
Observamos el hecho de que hace algún tiempo, la clase shared_ptr se eliminó del método que devolvió el número de enlaces activos a este objeto. Y llegamos a la conclusión de que también necesitamos descartar varias funciones, a saber, size, count, empty, buckets_count, porque tan pronto como devolvemos este valor de la función, inmediatamente deja de ser válido, porque alguien puede cambia el mismo momento
En una de nuestras reuniones anteriores, nos pidieron que agreguemos un tipo de modo para que podamos acceder a nuestro contenedor en modo de subproceso único, como un std :: unordered_map normal. Tal semántica nos permite distinguir claramente dónde trabajamos en modo multiproceso y dónde no. Y para evitar algunas situaciones desagradables cuando las personas toman un contenedor de múltiples subprocesos, espere que todo esté bien con ellos, tome iteradores y, de repente, resulta que todo está mal.

En esta reunión en Hawái, se escribió una propuesta completa contra nosotros. :) Nos dijeron que tales cosas no tienen cabida en el estándar, porque hay muchas formas de hacer su contenedor asociativo de subprocesos múltiples.
Cada uno tiene sus pros y sus contras, y no está claro cómo usar lo que finalmente logramos. Como regla general, se usa cuando necesita algún tipo de rendimiento extremo. Y parece que nuestra solución en caja no es adecuada, es necesario optimizarla para cada caso específico.
El segundo punto de esta propuesta fue que nuestra interfaz no es compatible con el hecho de que Facebook publicó en GitHub desde su biblioteca estándar.
De hecho, no hubo problemas particulares allí. Simplemente hubo una pregunta de la categoría de "No he leído, pero condenar". Simplemente miraron: la interfaz es diferente, lo que significa que no es compatible.
La idea de la propuesta también era que tareas similares deberían resolverse con la ayuda del llamado diseño basado en políticas, cuando es necesario hacer un parámetro de plantilla adicional en el que pueda pasar una máscara de bits con las características que queremos habilitar y cuáles desactivar. De hecho, esto suena un poco salvaje y lleva al hecho de que obtenemos alrededor de 2 ^ n implementaciones, donde n es el número de características diferentes.

En código, se parece a esto. Tenemos algún tipo de parámetro y cierto número de constantes predefinidas que se pueden pasar allí. Por extraño que parezca, esta propuesta fue rechazada.

Porque, de hecho, el comité ya ha tomado la posición de que tales cosas deberían ser cuando la cola de subprocesos múltiples pasó por SG1. Ni siquiera hubo una votación sobre este tema. Pero dos preguntas fueron sometidas a votación.
El primero Mucha gente nos quería del lado de nuestra implementación de referencia para apoyar la lectura sin tener que bloquear. Para que tengamos una lectura completamente sin bloqueo. Realmente tiene sentido: como regla, el caso de usuario más popular es el almacenamiento en caché. Y es muy beneficioso para nosotros tener una lectura rápida.
Segundo momento Todos escucharon mucho del amigo anterior que habló sobre el diseño basado en políticas. Todos tenían una idea, pero qué, ¡déjenme hablar sobre mi idea también! Y todos votaron para tener un diseño basado en políticas. Aunque debo decir que toda esta historia ha estado sucediendo durante bastante tiempo, y antes que nosotros, nuestros colegas de Intel, Arch Robinson y Anton Malakhov estaban haciendo esto. Y ya tenían varias propuestas sobre este tema. Simplemente ofrecieron agregar una implementación sin bloqueo basada en el algoritmo
SeepOrderedList . Y también tenían un diseño basado en políticas con la queja de memoria.
Y a esta propuesta no le gustó el Grupo de Trabajo de Evolución de la Biblioteca. Fue concluido con la razón de que simplemente tendremos un aumento ilimitado en el número de palabras en el estándar. Será simplemente imposible obtener una vista previa adecuada y simplemente implementarlo en el código.
No tenemos comentarios sobre las ideas mismas. Tenemos comentarios, en su mayor parte, sobre la implementación de referencia. Y, por supuesto, tenemos un par de ideas que se pueden presentar para hacerlo más claro. Pero esencialmente, la próxima vez iremos con la misma propuesta. Esperamos sinceramente que no tengamos, como con los módulos, cinco llamadas con la misma propuesta. Creemos sinceramente en nosotros mismos, y que nos permitirán pasar a la próxima convocatoria, y que el Grupo de Trabajo de la Evolución de la Biblioteca, sin embargo, insistirá en nuestra opinión y no nos permitirá impulsar el diseño basado en políticas. Porque nuestro oponente no se detiene. Decidió demostrar a todos que era necesario. Pero como dicen, el tiempo lo dirá. Tengo todo, gracias por su atención.