
Todos perciben textos de manera única, independientemente de si esta persona lee noticias en Internet o novelas clásicas mundialmente conocidas. Esto también se aplica a una variedad de algoritmos y técnicas de aprendizaje automático, que entienden los textos de una manera más matemática, es decir, utilizando el espacio vectorial de alta dimensión.
Este artículo está dedicado a visualizar incrustaciones de palabras de Word2Vec de alta dimensión usando t-SNE. La visualización puede ser útil para comprender cómo funciona Word2Vec y cómo interpretar las relaciones entre los vectores capturados de sus textos antes de usarlos en redes neuronales u otros algoritmos de aprendizaje automático. Como datos de capacitación, utilizaremos artículos de Google News y obras literarias clásicas de Leo Tolstoy, el escritor ruso que es considerado como uno de los mejores autores de todos los tiempos.
Revisamos la breve descripción general del algoritmo t-SNE, luego pasamos al cálculo de inserción de palabras usando Word2Vec y, finalmente, procedemos a la visualización de vectores de palabras con t-SNE en espacio 2D y 3D. Escribiremos nuestros scripts en Python usando Jupyter Notebook.
Incrustación de vecinos estocásticos distribuidos en T
T-SNE es un algoritmo de aprendizaje automático para la visualización de datos, que se basa en una técnica de reducción de dimensionalidad no lineal. La idea básica de t-SNE es reducir el espacio dimensional manteniendo la distancia relativa por pares entre puntos. En otras palabras, el algoritmo asigna datos multidimensionales a dos o más dimensiones, donde los puntos que inicialmente estaban lejos uno del otro también se encuentran lejos, y los puntos cercanos también se convierten en cercanos. Se puede decir que t-SNE busca una nueva representación de datos donde se preservan las relaciones de vecindad. La descripción detallada de la lógica completa de t-SNE se puede encontrar en el artículo original [1].
El modelo de Word2Vec
Para empezar, debemos obtener representaciones vectoriales de palabras. Para este propósito, seleccioné Word2vec [2], es decir, un modelo predictivo computacionalmente eficiente para aprender incrustaciones de palabras multidimensionales a partir de datos textuales sin procesar. El concepto clave de Word2Vec es localizar palabras, que comparten contextos comunes en el corpus de entrenamiento, muy cerca del espacio vectorial en comparación con otros.
Como datos de entrada para la visualización, utilizaremos artículos de Google News y algunas novelas de Leo Tolstoy. Google publicó en
la página oficial vectores pre-entrenados formados en parte del conjunto de datos de Google News (alrededor de 100 mil millones de palabras), por lo que lo utilizaremos.
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
Además del modelo pre-entrenado, entrenaremos otro modelo sobre las novelas de Tolstoi usando la biblioteca Gensim [3]. Word2Vec toma oraciones como datos de entrada y produce vectores de palabras como salida. En primer lugar, es necesario descargar Punkt Sentence Tokenizer previamente entrenado, que divide un texto en una lista de oraciones considerando palabras abreviadas, colocaciones y palabras, que probablemente indican un comienzo o final de las oraciones. Por defecto, el paquete de datos NLTK no incluye un tokenizador Punkt pre-entrenado para ruso, por lo que utilizaremos modelos de
terceros de
github.com/mhq/train_punkt .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
En la etapa de entrenamiento de Word2Vec se usaron los siguientes hiperparámetros:
- La dimensionalidad del vector de características es 200.
- La distancia máxima entre palabras analizadas dentro de una oración es 5.
- Ignora todas las palabras con una frecuencia total inferior a 5 por corpus.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
Visualización de incrustaciones de palabras con t-SNE
T-SNE es bastante útil en caso de que sea necesario visualizar la similitud entre los objetos que se encuentran en el espacio multidimensional. Con un gran conjunto de datos, es cada vez más difícil hacer un diagrama t-SNE fácil de leer, por lo que es una práctica común visualizar grupos de las palabras más similares.
Seleccionemos algunas palabras del vocabulario del modelo pre-entrenado de Google News y preparemos vectores de palabras para su visualización.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
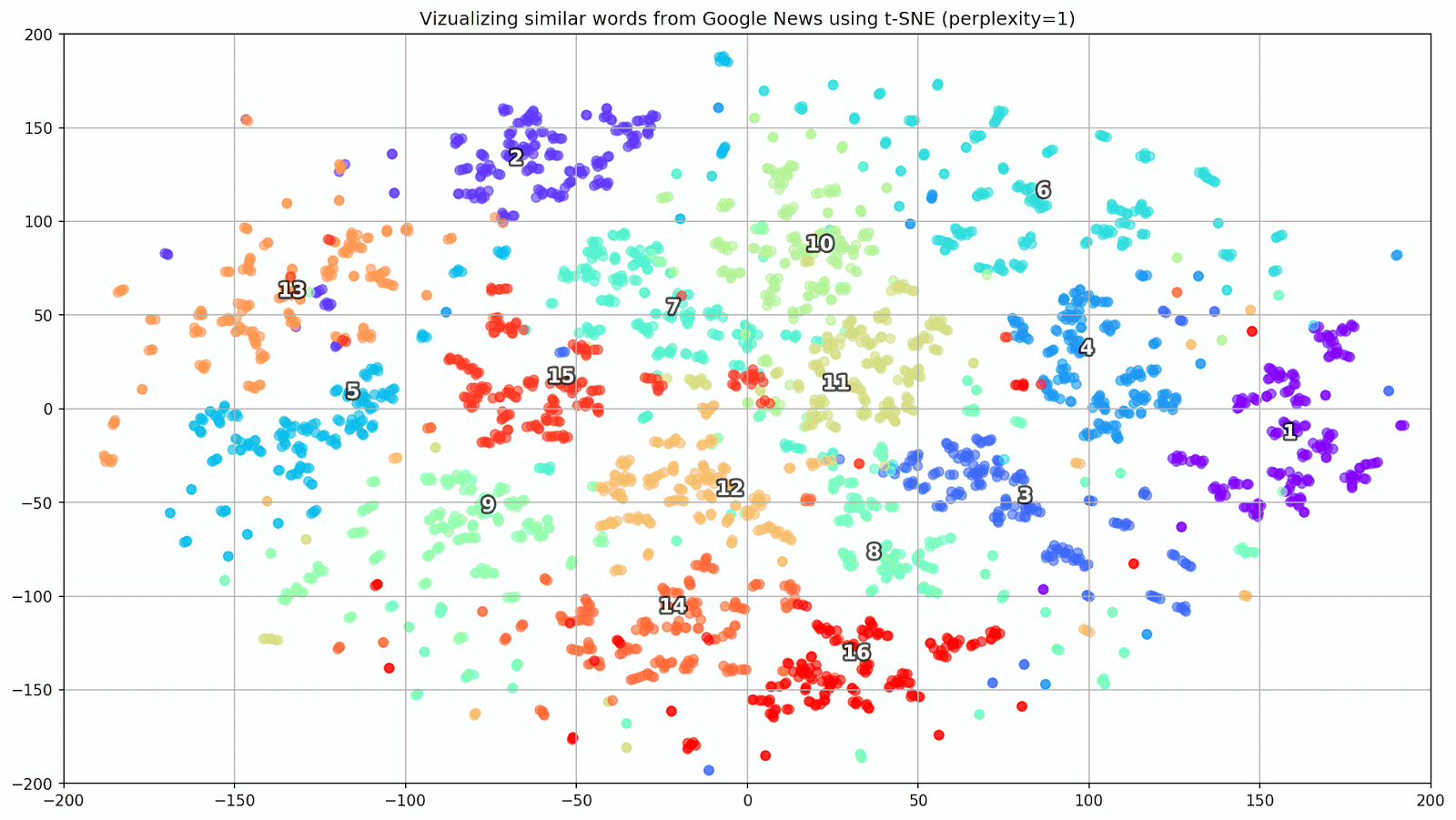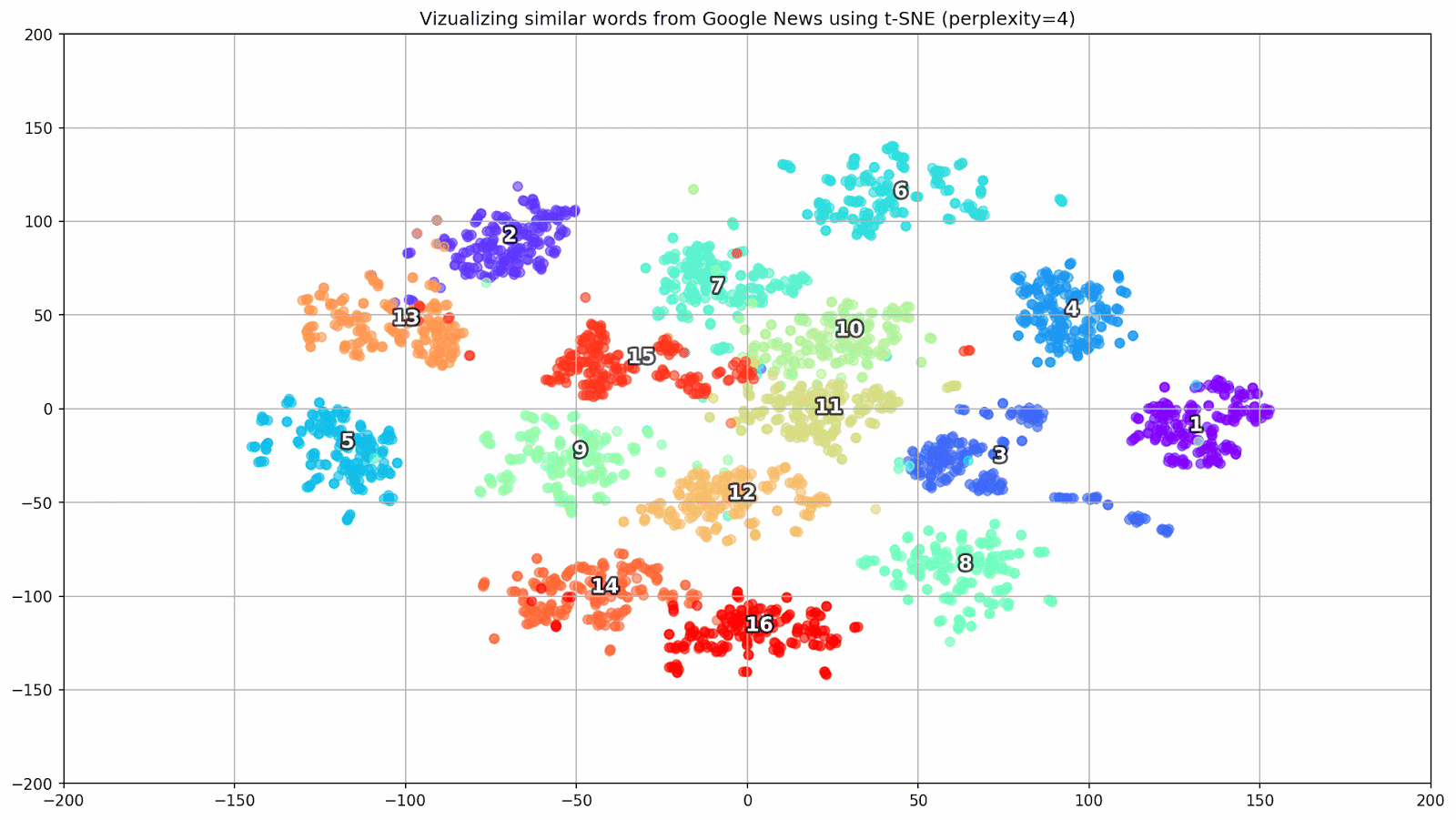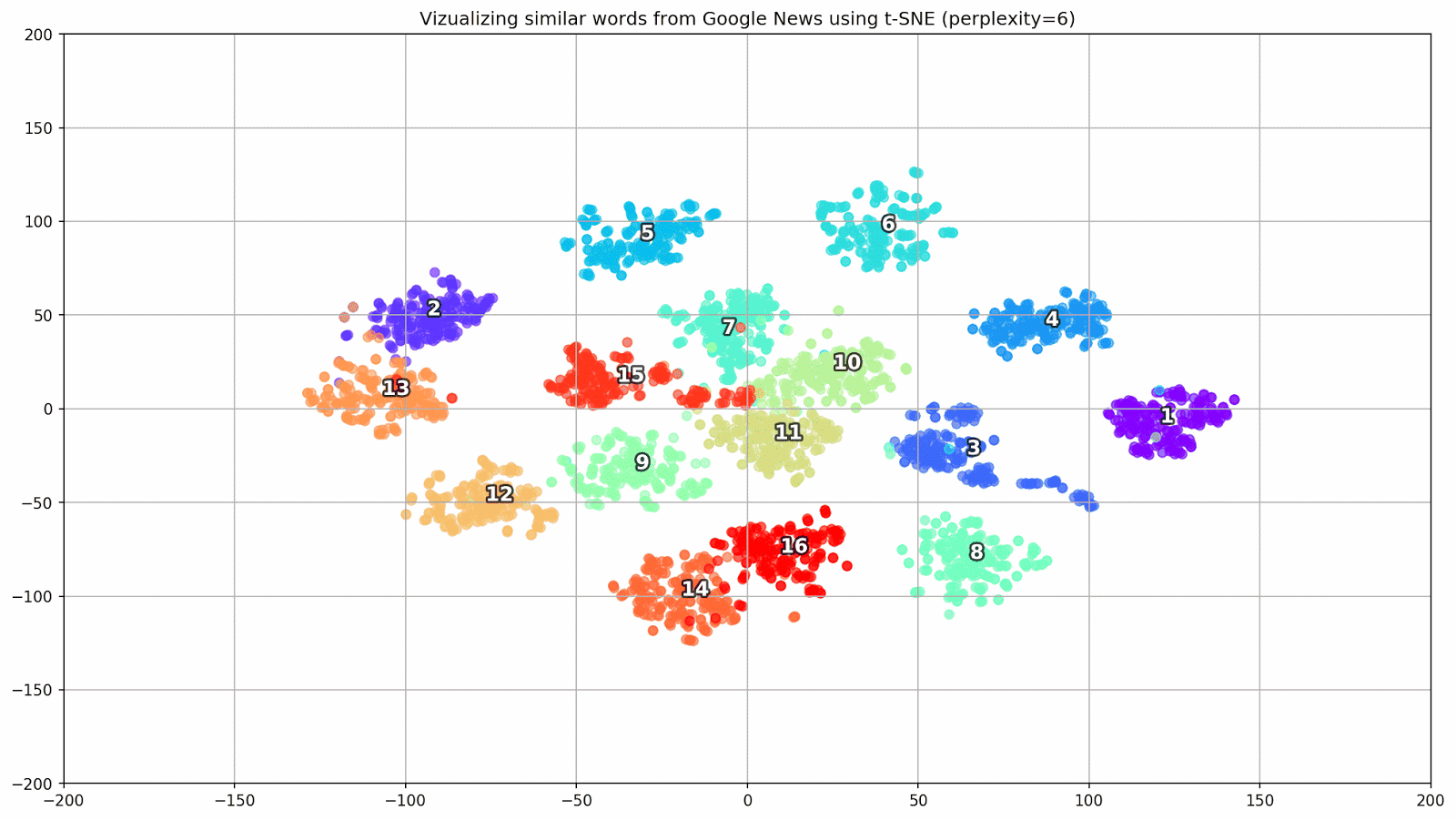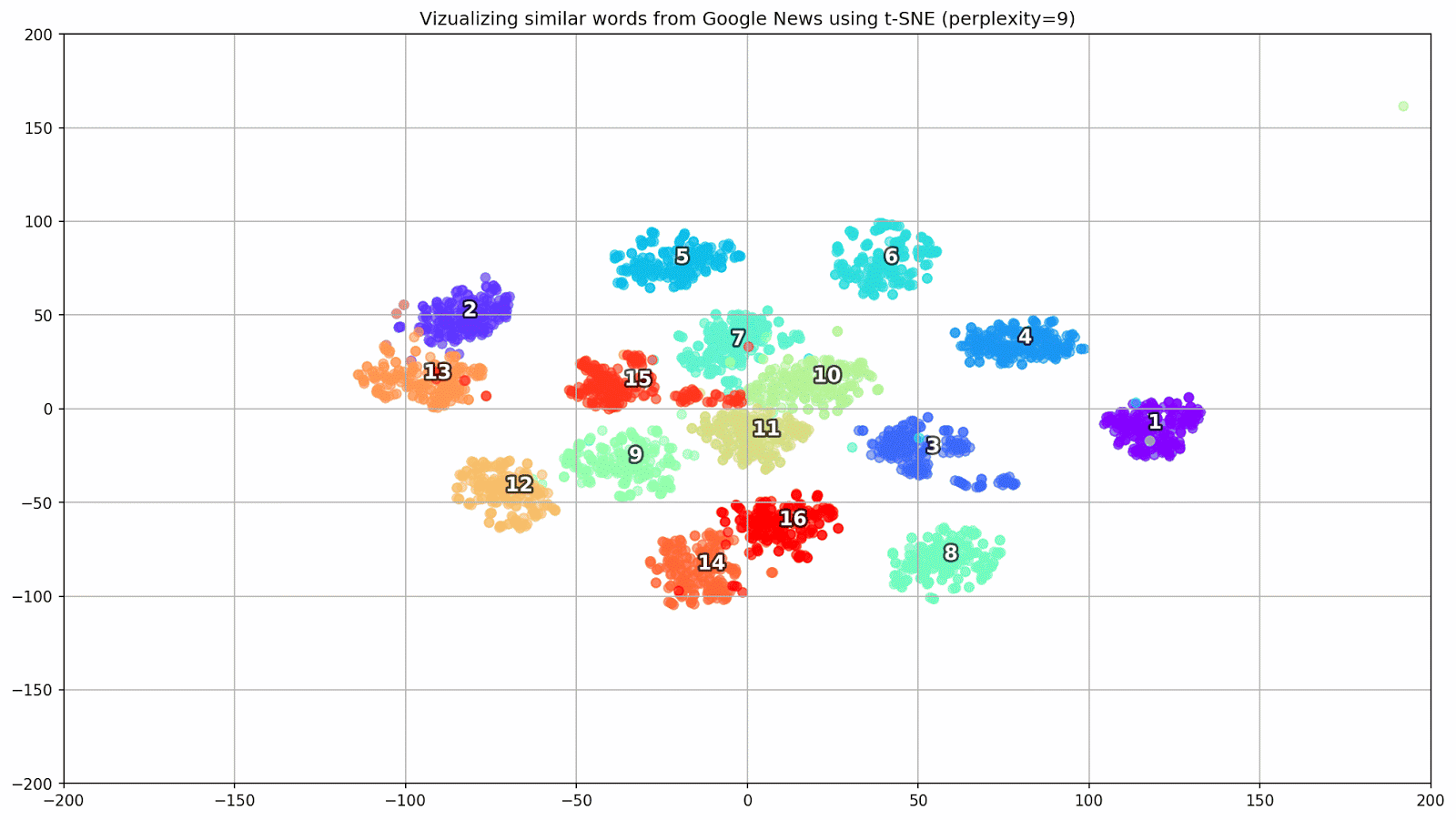 Fig. 1. El efecto de varios valores de perplejidad en la forma de los grupos de palabras.
Fig. 1. El efecto de varios valores de perplejidad en la forma de los grupos de palabras.A continuación, procedemos a la parte fascinante de este documento, la configuración de t-SNE. En esta sección, debemos prestar atención a los siguientes hiperparámetros.
- El número de componentes , es decir, la dimensión del espacio de salida.
- El valor de perplejidad , que en el contexto de t-SNE, puede verse como una medida uniforme del número efectivo de vecinos. Está relacionado con el número de vecinos más cercanos que se emplean en muchos otros estudiantes múltiples (vea la imagen de arriba). De acuerdo con [1], se recomienda seleccionar un valor entre 5 y 50.
- El tipo de inicialización inicial para incrustaciones.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
Cabe mencionar que t-SNE tiene una función objetivo no convexa, que se minimiza utilizando una optimización de descenso de gradiente con iniciación aleatoria, por lo que diferentes ejecuciones producen resultados ligeramente diferentes.
A continuación puede encontrar un script para crear un diagrama de dispersión 2D usando Matplotlib, una de las bibliotecas más populares para la visualización de datos en Python.
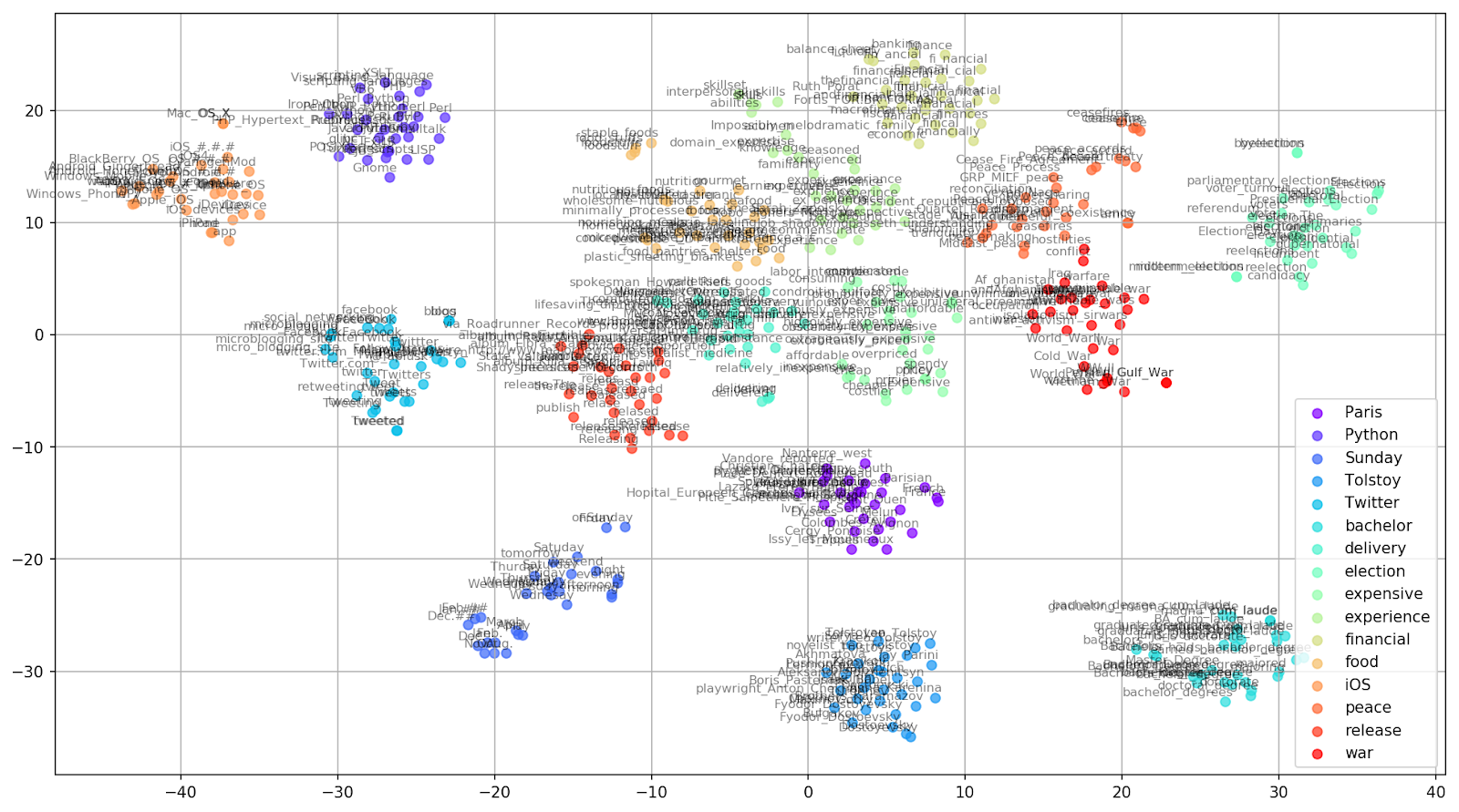 Fig. 2. Grupos de palabras similares de Google News (preplejidad = 15).
Fig. 2. Grupos de palabras similares de Google News (preplejidad = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
En algunos casos, puede ser útil trazar todos los vectores de palabras a la vez para ver la imagen completa. Analicemos ahora a Anna Karenina, una novela épica de pasión, intriga, tragedia y redención.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
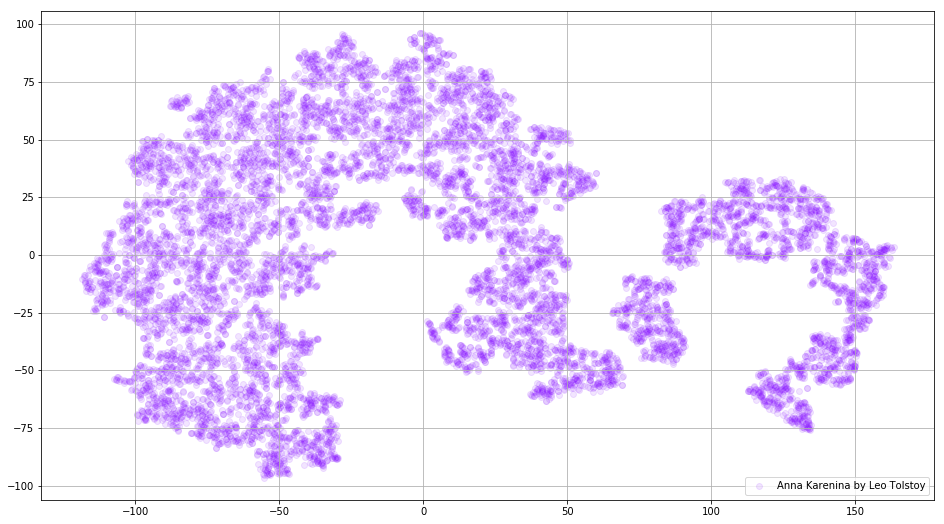
 Fig. 3. Visualización del modelo Word2Vec entrenado en Anna Karenina.
Fig. 3. Visualización del modelo Word2Vec entrenado en Anna Karenina.Toda la imagen puede ser aún más informativa si mapeamos las incrustaciones iniciales en el espacio 3D. En este momento echemos un vistazo a Guerra y paz, una de las novelas vitales de la literatura mundial y uno de los mayores logros literarios de Tolstoi.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
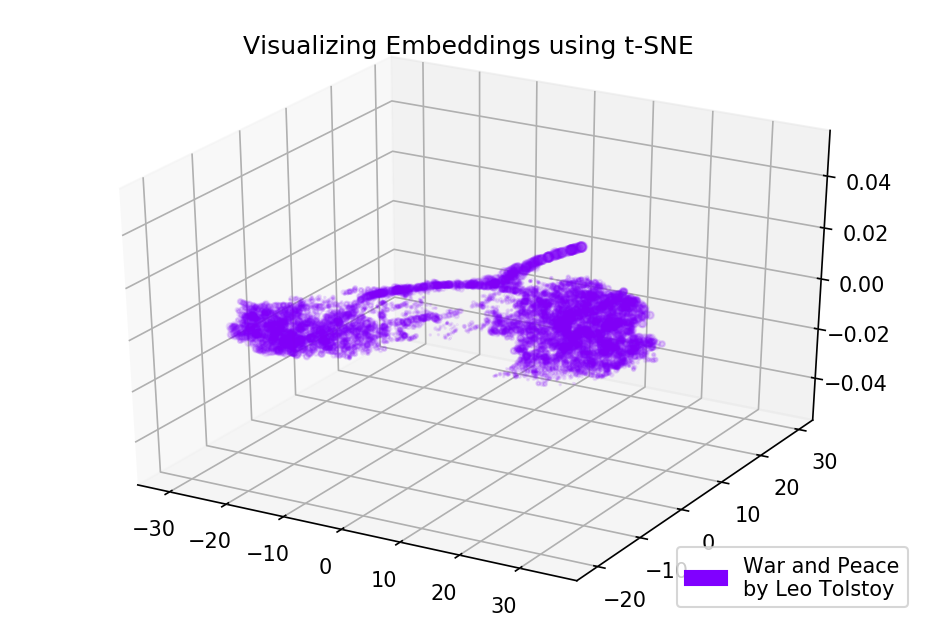 Fig. 4. Visualización del modelo Word2Vec entrenado en Guerra y paz.
Fig. 4. Visualización del modelo Word2Vec entrenado en Guerra y paz.Los resultados
Así es como se ven los textos de la perspectiva de Word2Vec y t-SNE. Trazamos un cuadro bastante informativo para palabras similares de Google News y dos diagramas para las novelas de Tolstoi. Además, una cosa más, ¡GIFs! Los GIF son increíbles, pero trazar GIF es casi lo mismo que trazar gráficos regulares. Entonces, decidí no mencionarlos en el artículo, pero puede encontrar el código para la generación de animaciones en las fuentes.
El código fuente está disponible en
Github .
El artículo fue publicado originalmente en
Towards Data Science .
Referencias
- L. Maate y G. Hinton, "Visualización de datos utilizando t-SNE", Journal of Machine Learning Research, vol. 9, pp. 2579-2605, 2008.
- T. Mikolov, I. Sutskever, K. Chen, G. Corrado y J. Dean, "Representaciones distribuidas de palabras y frases y su composicionalidad", Avances en los sistemas de procesamiento de información neural, págs. 3111-3119, 2013.
- R. Rehurek y P. Sojka, "Marco de software para el modelado de temas con grandes corporaciones", Actas del Taller LREC 2010 sobre nuevos desafíos para los marcos de PNL, 2010.