Pruebas comparativas de cachés multiproceso implementadas en C / C ++ y una descripción de cómo se organiza el caché LRU / MRU de la serie O (n) Cache ** RU
A lo largo de las décadas, se han desarrollado muchos algoritmos de almacenamiento en caché: LRU, MRU, ARC y otros ... Sin embargo, cuando se necesitaba un caché para el trabajo de subprocesos múltiples, Google sobre este tema ofrecía opciones de uno y medio, y la pregunta sobre StackOverflow generalmente no tenía respuesta. Encontré una solución de Facebook que se basa en contenedores seguros para subprocesos del repositorio Intel TBB . Este último también tiene un caché LRU de subprocesos múltiples que todavía está en prueba beta y, por lo tanto, para usarlo, debe especificar explícitamente en el proyecto:
#define TBB_PREVIEW_CONCURRENT_LRU_CACHE true
De lo contrario, el compilador mostrará un error ya que hay una comprobación en el código Intel TBB:
#if ! TBB_PREVIEW_CONCURRENT_LRU_CACHE #error Set TBB_PREVIEW_CONCURRENT_LRU_CACHE to include concurrent_lru_cache.h #endif
Quería comparar de alguna manera el rendimiento de los cachés, ¿cuál elegir? O escribir el tuyo? Anteriormente, cuando estaba comparando cachés de un solo hilo ( enlace ), recibí ofertas para probar otras condiciones con otras claves y me di cuenta de que se requería un banco de pruebas extensible más conveniente. Para que sea más conveniente agregar algoritmos competitivos a las pruebas, decidí incluirlos en la interfaz estándar:
class IAlgorithmTester { public: IAlgorithmTester() = default; virtual ~IAlgorithmTester() { } virtual void onStart(std::shared_ptr<IConfig> &cfg) = 0; virtual void onStop() = 0; virtual void insert(void *elem) = 0; virtual bool exist(void *elem) = 0; virtual const char * get_algorithm_name() = 0; private: IAlgorithmTester(const IAlgorithmTester&) = delete; IAlgorithmTester& operator=(const IAlgorithmTester&) = delete; };
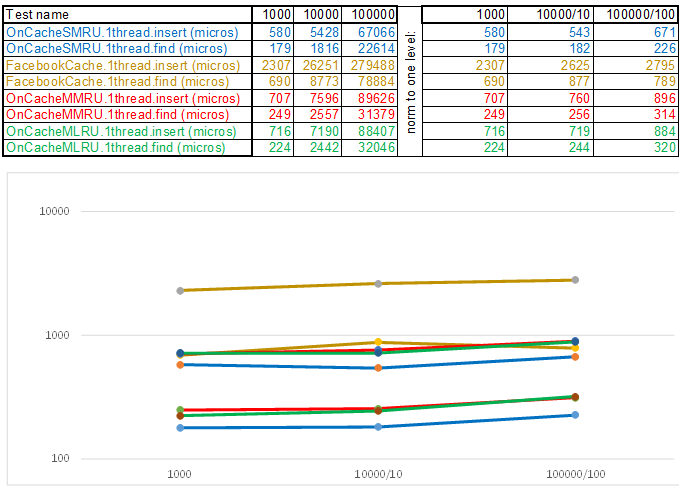
Del mismo modo, las interfaces están envueltas: trabajando con el sistema operativo, obteniendo configuraciones, casos de prueba, etc. Las fuentes se presentan en el repositorio . Hay dos casos de prueba en el stand: inserte / busque hasta 1,000,000 de elementos con una clave de números generados al azar y hasta 100,000 elementos con una clave de cadena (tomada de 10Mb de líneas wiki.train.tokens). Para evaluar el tiempo de ejecución, cada caché de prueba se calienta primero al volumen objetivo sin mediciones de tiempo, luego el semáforo descarga los flujos de la cadena para agregar y buscar datos. El número de subprocesos y la configuración del caso de prueba se establecen en assets / settings.json . Las instrucciones de compilación paso a paso y una descripción de la configuración de JSON se describen en el repositorio de WiKi . Se registra el tiempo desde el momento en que se libera el semáforo hasta que se detiene el último hilo. Esto es lo que sucedió:
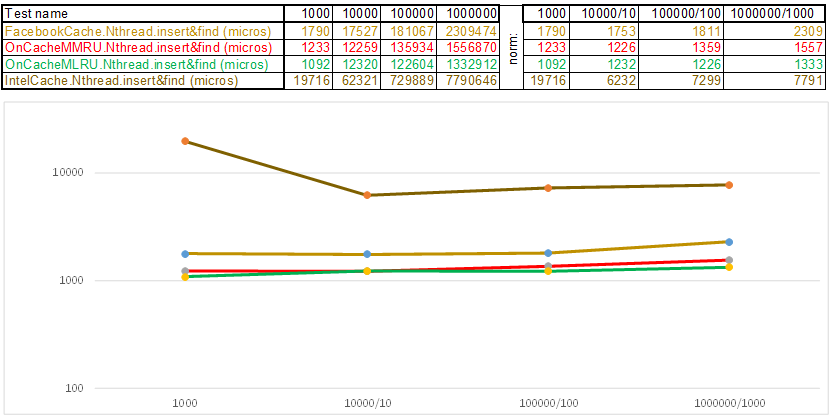
Caso de prueba 1: una clave en forma de matriz de números aleatorios uint64_t keyArray [3]:
Test case2 - clave como una cadena:
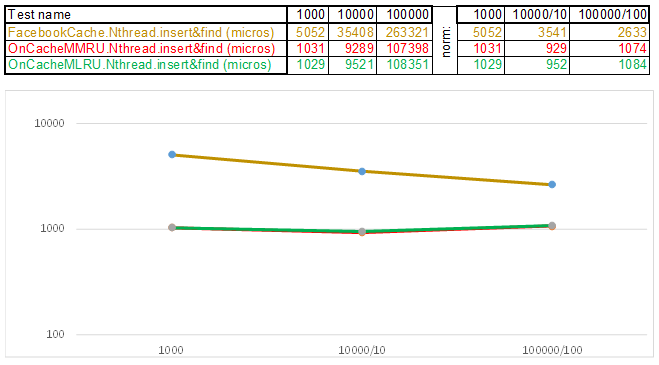
Tenga en cuenta que el volumen de datos insertados / buscados en cada paso del caso de prueba aumenta 10 veces. Luego, el tiempo que se dedicó a procesar el siguiente volumen, lo divido por 10, 100, 1000, respectivamente ... Si el algoritmo se comporta como O (n) en complejidad de tiempo, entonces la línea de tiempo permanecerá aproximadamente paralela al eje X. A continuación, revelaré el conocimiento sagrado, como lo logré obtenga 3-5 veces superioridad sobre el caché de Facebook en los algoritmos de la serie O (n) Cache ** RU cuando trabaje con una tecla de cadena:
- La función hash, en lugar de leer cada letra de la cadena, simplemente lanza un puntero a los datos de la cadena a uint64_t keyArray [3] y cuenta la suma de los enteros. Es decir, funciona como el programa "Adivina la melodía", y supongo que la melodía con 3 notas ... 3 * 8 = 24 letras si es en latín, y esto ya te permite dispersar las líneas bastante bien en las canastas hash. Sí, se pueden recopilar muchas líneas en una cesta hash, y aquí el algoritmo comienza a acelerarse:
- La Lista de saltos en cada canasta le permite saltar rápidamente en diferentes hashes (id de canasta = número de hash% de canastas, por lo que pueden aparecer diferentes hashes en una canasta), luego dentro del mismo hash a lo largo de los vértices:
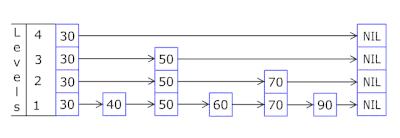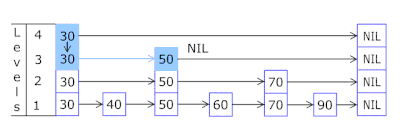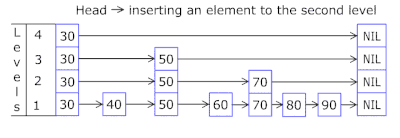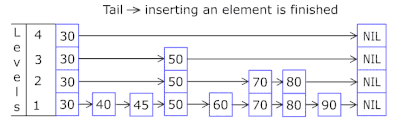
- Los nodos en los que se almacenan las claves y los datos se toman de la matriz de nodos previamente asignada, el número de nodos coincide con la capacidad de caché. El identificador atómico indica qué nodo tomar a continuación: si llega al final del grupo de nodos, comienza con 0 = por lo que el asignador va en un círculo sobrescribiendo los nodos antiguos ( caché LRU en OnCacheMLRU ).
Para el caso en que es necesario que los elementos más populares en las consultas de búsqueda se almacenen en la memoria caché, se crea la segunda clase OnCacheMMRU , el algoritmo es el siguiente: además de la capacidad de la memoria caché, el constructor de la clase también pasa el segundo parámetro uint32_t inutilidad, el límite de popularidad es si el número de solicitudes de búsqueda que desean el nodo actual del grupo cíclico es menor Si los límites son inútiles, entonces el nodo se reutiliza para la siguiente operación de inserción (será desalojado). Si en este círculo la popularidad del nodo (std :: atomic <uint32_t> utilizado {0}) es alta, en el momento de solicitar el asignador del grupo cíclico, el nodo podrá sobrevivir, pero el contador de popularidad se restablecerá a 0. Por lo tanto, habrá otro círculo del pase del asignador en un grupo de nodos y tener la oportunidad de ganar popularidad nuevamente para continuar existiendo. Es decir, es una mezcla de los algoritmos MRU (donde los más populares permanecen en la memoria caché para siempre) y MQ (donde se realiza un seguimiento de la vida útil). El caché se actualiza constantemente y, al mismo tiempo, funciona muy rápidamente; en lugar de 10 servidores, puede colocar 1 ..
En general, el algoritmo de almacenamiento en caché pasa tiempo en lo siguiente:
- Mantenimiento de la infraestructura de caché (contenedores, asignadores, seguimiento de la vida útil y popularidad de los elementos)
- Cálculo de hash y operaciones de comparación de claves al agregar / buscar datos
- Algoritmos de búsqueda: árbol rojo-negro, tabla hash, lista de saltos, ...
Solo era necesario reducir el tiempo de funcionamiento de cada uno de estos elementos, dado que el algoritmo más simple es temporalmente complejo y, a menudo, el más eficiente, ya que cualquier lógica requiere ciclos de CPU. Es decir, sea lo que sea que escriba, estas son operaciones que deberían dar sus frutos a tiempo en comparación con el método de enumeración simple: mientras se llama a la siguiente función, la enumeración tendrá que pasar por otros cien o dos nodos. Desde este punto de vista, los cachés de subprocesos múltiples siempre se reproducirán con un solo subproceso, ya que proteger las cestas a través de std :: shared_mutex y los nodos a través de std :: atomic_flag in_use no es gratuito. Por lo tanto, para emitir en el servidor, utilizo el caché de un solo subproceso OnCacheSMRU en el subproceso principal del servidor Epoll (solo se realizan operaciones largas para trabajar con el DBMS, disco, criptografía en flujos de trabajo paralelos). Para una evaluación comparativa, se utiliza una versión de un solo subproceso de casos de prueba:
Caso de prueba 1: una clave en forma de matriz de números aleatorios uint64_t keyArray [3]:

Test case2 - clave como una cadena:
En conclusión, quiero decirle qué más interesante se puede extraer de las fuentes del banco de pruebas:
- La biblioteca de análisis JSON, que consta de un solo archivo specjson.h, es un pequeño algoritmo simple y rápido para aquellos que no desean arrastrar unos pocos megabytes del código de otras personas a su proyecto para analizar el archivo de configuración o el JSON entrante de un formato conocido.
- Un enfoque con la inyección de la implementación de operaciones específicas de la plataforma en la forma (clase LinuxSystem: public ISystem {...}) en lugar de la tradicional (#ifdef _WIN32). Es más conveniente envolver, por ejemplo, semáforos, trabajar con bibliotecas conectadas dinámicamente, servicios: en las clases solo hay código y encabezados de un sistema operativo específico. Si necesita otro sistema operativo, inyecte otra implementación (clase WindowsSystem: public ISystem {...}).
- El soporte irá a CMake: es conveniente abrir el proyecto CMakeLists.txt en Qt Creator o Microsoft Visual Studio 2017. Trabajar con el proyecto a través de CmakeLists.txt le permite automatizar algunas operaciones preparatorias, por ejemplo, copiar archivos de casos de prueba y archivos de configuración en el directorio de instalación:
- Para aquellos que dominan las nuevas características de C ++ 17, este es un ejemplo de trabajo con std :: shared_mutex, std :: allocator <std :: shared_mutex>, static thread_local en las plantillas (hay matices: ¿dónde asignar?), Iniciando una gran cantidad de pruebas en hilos de diferentes maneras con la medición del tiempo de ejecución:
- Instrucciones paso a paso sobre cómo compilar, configurar y ejecutar este banco de pruebas: WiKi .
Si aún no tiene instrucciones paso a paso para un sistema operativo conveniente, le agradeceré la contribución al repositorio para implementar ISystem y las instrucciones de compilación paso a paso (para WiKi) ... O simplemente escríbame. Trataré de encontrar el tiempo para levantar la máquina virtual y describir los pasos para el ensamblaje.