Hola Habr! Les presento el post, que es una adaptación de texto de la actuación de
Stella Cotton en RailsConf 2018 y una traducción del artículo
"Construyendo una arquitectura orientada al servicio con Rails y Kafka" de Stella Cotton.
Recientemente, la transición de la arquitectura monolítica a los microservicios es claramente visible. En esta guía, aprenderemos los conceptos básicos de Kafka y cómo un enfoque basado en eventos puede mejorar su aplicación Rails. También hablaremos sobre los problemas de monitoreo y escalabilidad de los servicios que funcionan a través de un enfoque orientado a eventos.
¿Qué es kafka?
Estoy seguro de que le gustaría tener información sobre cómo llegaron sus usuarios a su plataforma o qué páginas visitan, en qué botones hacen clic, etc. Una aplicación verdaderamente popular puede generar miles de millones de eventos y enviar una gran cantidad de datos a los servicios de análisis, lo que puede ser un gran desafío para su aplicación.
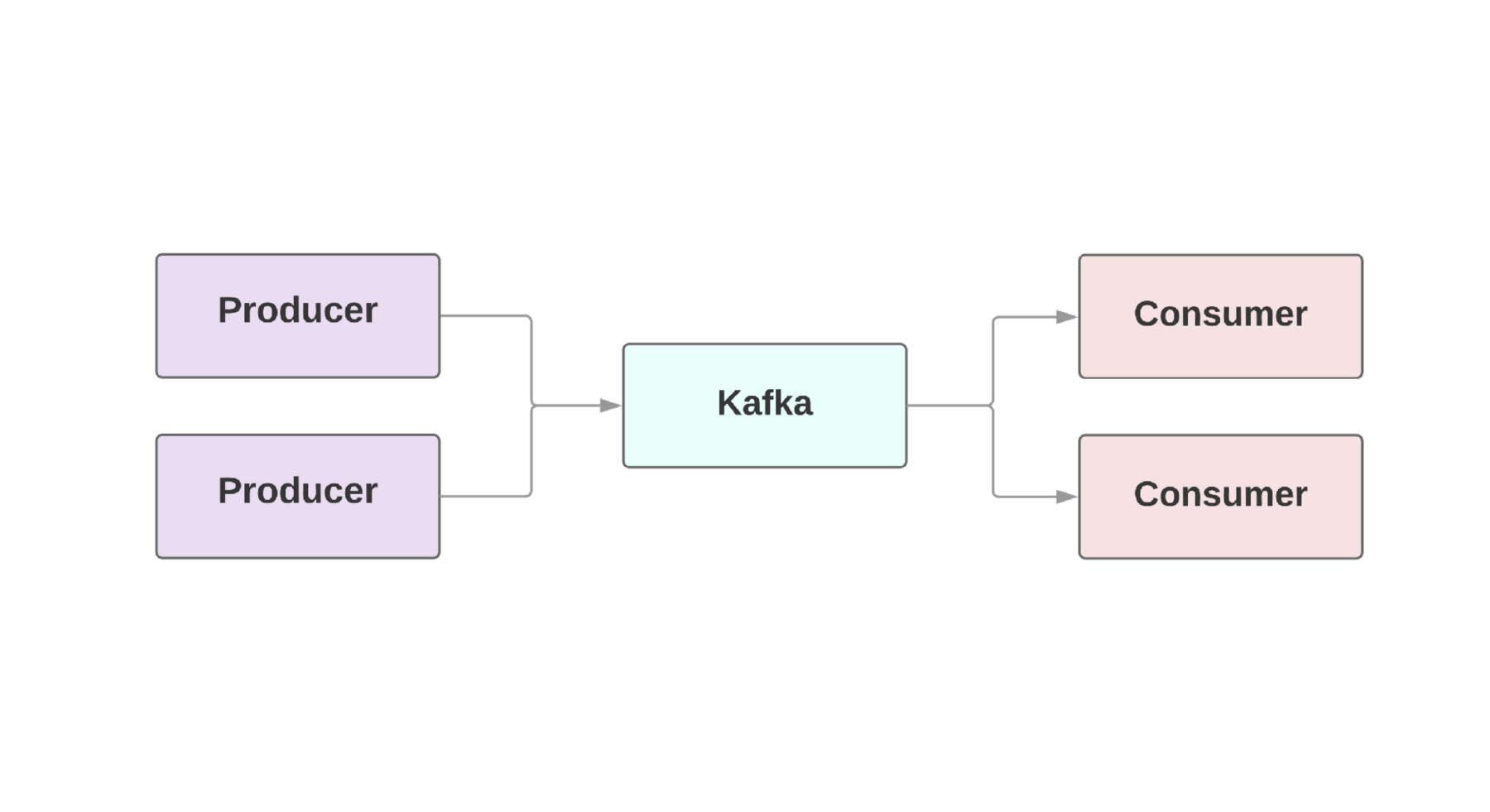
Como regla, una parte integral de las aplicaciones web requiere el llamado
flujo de datos en tiempo real . Kafka proporciona una conexión tolerante a fallas entre
productores , aquellos que generan eventos y
consumidores , aquellos que reciben estos eventos. Incluso puede haber varios productores y consumidores en una sola aplicación. En Kafka, cada evento existe durante un tiempo determinado, por lo que varios consumidores pueden leer el mismo evento una y otra vez. El grupo de Kafka incluye varios corredores que son instancias de Kafka.
Una característica clave de Kafka es la alta velocidad de procesamiento de eventos. Los sistemas de colas tradicionales, como AMQP, tienen una infraestructura que monitorea los eventos procesados para cada consumidor. Cuando el número de consumidores crece a un nivel decente, el sistema apenas comienza a hacer frente a la carga, ya que tiene que controlar un número creciente de condiciones. Además, existen grandes problemas con la coherencia entre el consumidor y el procesamiento de eventos. Por ejemplo, ¿vale la pena marcar inmediatamente un mensaje como enviado tan pronto como sea procesado por el sistema? ¿Y si un consumidor cae en el otro extremo sin recibir un mensaje?
Kafka también tiene una arquitectura a prueba de fallas. El sistema se ejecuta como un clúster en uno o más servidores, que se pueden escalar horizontalmente agregando nuevas máquinas. Todos los datos se escriben en el disco y se copian a varios corredores. Para comprender las posibilidades de escalabilidad, vale la pena echar un vistazo a empresas como Netflix, LinkedIn, Microsoft. ¡Todos ellos envían billones de mensajes por día a través de sus grupos de Kafka!
Configurar Kafka en Rails
Heroku proporciona un
complemento de clúster Kafka que se puede usar para cualquier entorno. Para aplicaciones de rubí, recomendamos usar la
gema ruby-kafka . La implementación mínima se parece a esto:
Después de configurar la configuración, puede usar la gema para enviar mensajes. Gracias al envío asincrónico de eventos, podemos enviar mensajes desde cualquier lugar:
class OrdersController < ApplicationController def create @comment = Order.create!(params) $kafka_producer.produce(order.to_json, topic: "user_event", partition_key: user.id) end end
Hablaremos sobre los formatos de serialización a continuación, pero por ahora usaremos el viejo JSON. El argumento del
topic refiere al registro en el que Kafka escribe este evento. Los temas se extienden en diferentes secciones, que le permiten dividir los datos de un tema en particular en diferentes corredores para una mejor escalabilidad y confiabilidad. Y es realmente una buena idea tener dos o más secciones para cada tema, porque si una de las secciones cae, sus eventos se registrarán y procesarán de todos modos. Kafka asegura que los eventos se entreguen en el orden de la cola dentro de la sección, pero no dentro del tema completo. Si el orden de los eventos es importante, el envío de la partición_clave asegura que todos los eventos de un tipo particular se almacenen en la misma partición.
Kafka por tus servicios
Algunas de las características que hacen de Kafka una herramienta útil también lo convierten en un RPC de conmutación por error entre servicios. Eche un vistazo a un ejemplo de una aplicación de comercio electrónico:
def create_order create_order_record charge_credit_card
Cuando el usuario
create_order un pedido, se
create_order función
create_order . Esto crea un pedido en el sistema, deduce dinero de la tarjeta y envía un correo electrónico con la confirmación. Como puede ver, los dos últimos pasos se llevan a cabo en servicios separados.
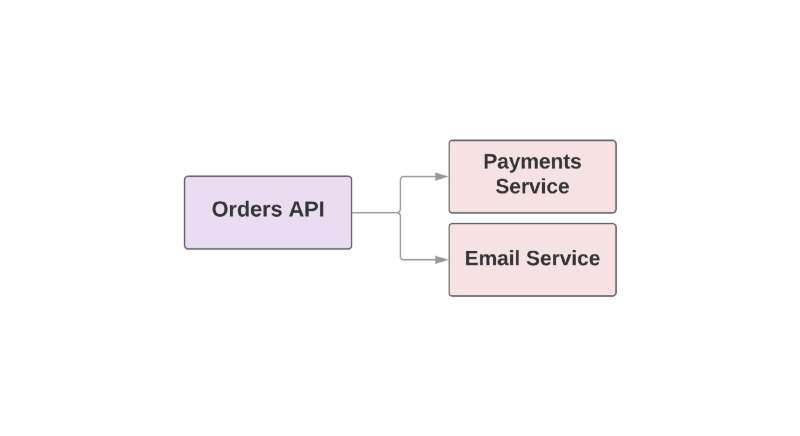
Uno de los problemas con este enfoque es que el servicio superior en la jerarquía es responsable de monitorear la disponibilidad del servicio descendente. Si el servicio para enviar cartas resultó ser un mal día, el servicio superior debe saberlo. Y si el servicio de envío no está disponible, debe repetir un determinado conjunto de acciones. ¿Cómo puede ayudar Kafka en esta situación?
Por ejemplo:
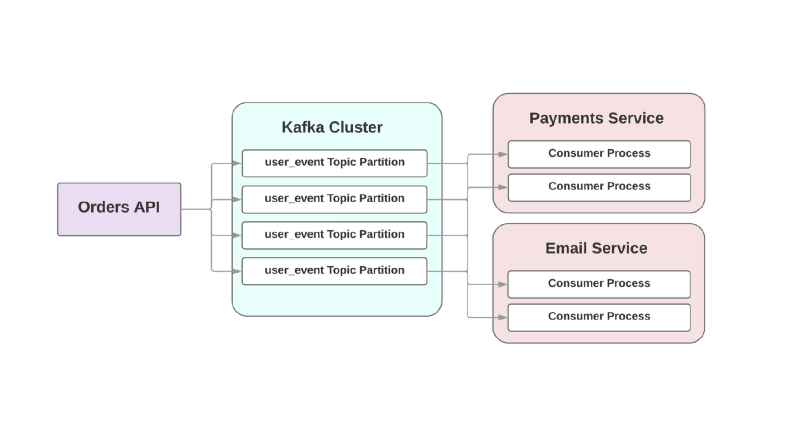
En este enfoque basado en eventos, un servicio superior puede registrar un evento en Kafka en el que se ha creado un pedido. Debido al llamado enfoque de
al menos una vez , el evento se grabará en Kafka al menos una vez y estará disponible para la lectura de los consumidores intermedios. Si el servicio de envío de cartas yace, el evento esperará en el disco hasta que el consumidor se levante y lo lea.
Otro problema con la arquitectura orientada a RPC está en los sistemas de rápido crecimiento: agregar un nuevo servicio descendente implica cambios en el flujo ascendente. Por ejemplo, le gustaría agregar un paso más después de crear un pedido. En un mundo impulsado por eventos, deberá agregar otro consumidor para manejar un nuevo tipo de evento.

Integración de eventos en la arquitectura orientada a servicios
Una publicación titulada "
¿Qué quieres decir con" Impulsado por
eventos "por Martin Fowler discute la confusión en torno a las aplicaciones basadas en eventos. Cuando los desarrolladores discuten tales sistemas, en realidad están hablando de una gran cantidad de aplicaciones diferentes. Para dar una comprensión general de la naturaleza de tales sistemas, Fowler definió varios patrones arquitectónicos.
Echemos un vistazo a cuáles son estos patrones. Si quieres saber más, te aconsejo que leas su
informe en GOTO Chicago 2017.
Notificación de evento
El primer patrón de Fowler se llama
Notificación de eventos . En este escenario, el servicio de productor notifica a los consumidores del evento con una cantidad mínima de información:
{ "event": "order_created", "published_at": "2016-03-15T16:35:04Z" }
Si los consumidores necesitan más información sobre el evento, hacen una solicitud al productor y obtienen más datos.
Transferencia de estado llevada por evento
La segunda plantilla se llama
Transferencia de estado llevada por evento . En este escenario, el productor proporciona información adicional sobre el evento y el consumidor puede almacenar una copia de estos datos sin hacer llamadas adicionales:
{ "event": "order_created", "order": { "order_id": 98765, "size": "medium", "color": "blue" }, "published_at": "2016-03-15T16:35:04Z" }
De origen de eventos
Fowler llamó a la tercera plantilla
Event-Sourced y es bastante arquitectónica. El lanzamiento de la plantilla implica no solo la comunicación entre sus servicios, sino también la preservación de la presentación del evento. Esto garantiza que, incluso si pierde la base de datos, puede restaurar el estado de la aplicación simplemente ejecutando la secuencia de eventos guardada. En otras palabras, cada evento guarda un cierto estado de la aplicación en un momento determinado.
El gran problema con este enfoque es que el código de la aplicación siempre cambia, y con él puede cambiar el formato o la cantidad de datos que proporciona el productor. Esto hace que la restauración del estado de la aplicación sea problemática.
Segmentación de responsabilidad de consulta de comando
Y la última plantilla es
la segregación de responsabilidad de consulta de comando , o CQRS. La idea es que las acciones que aplique al objeto, por ejemplo: crear, leer, actualizar, se dividan en diferentes dominios. Esto significa que un servicio debe ser responsable de la creación, otro de la actualización, etc. En los sistemas orientados a objetos, todo se almacena a menudo en un solo servicio.
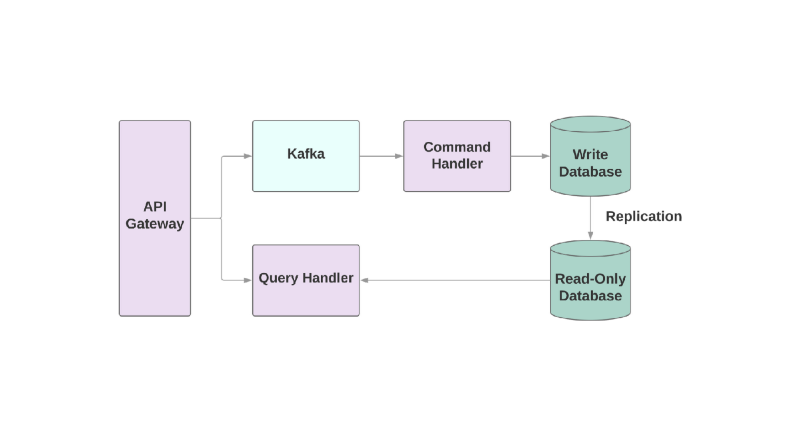
Un servicio que escribe en la base de datos leerá el flujo de eventos y los comandos de proceso. Pero cualquier solicitud se produce solo en la base de datos de solo lectura. Dividir la lógica de lectura y escritura en dos servicios diferentes aumenta la complejidad, pero le permite optimizar el rendimiento por separado para estos sistemas.
Los problemas
Hablemos sobre algunos de los problemas que puede encontrar al integrar Kafka en su aplicación orientada al servicio.
El primer problema puede ser lento para los consumidores. En un sistema orientado a eventos, sus servicios deberían poder procesar eventos instantáneamente cuando se reciben de un servicio superior. De lo contrario, simplemente se colgarán sin alertas sobre el problema o los tiempos de espera. El único lugar donde puede definir tiempos de espera es una conexión de socket con los corredores Kafka. Si el servicio no procesa el evento lo suficientemente rápido, la conexión puede ser interrumpida por el tiempo de espera, pero la restauración del servicio requiere tiempo adicional, porque la creación de dichos sockets es costosa.
Si el consumidor es lento, ¿cómo puede aumentar la velocidad del procesamiento de eventos? En Kafka, puede aumentar el número de consumidores en un grupo, por lo que se pueden procesar más eventos en paralelo. Pero se requerirán al menos 2 consumidores para un servicio: en caso de que uno caiga, las secciones dañadas pueden reasignarse.
También es muy importante tener métricas y alertas para monitorear la velocidad del procesamiento de eventos.
ruby-kafka puede funcionar con alertas ActiveSupport, también tiene módulos StatsD y Datadog, que están habilitados de forma predeterminada. Además, la gema proporciona una
lista de métricas recomendadas para el monitoreo.
Otro aspecto importante de la construcción de sistemas con Kafka es el diseño de consumidores con la capacidad de manejar fallas. Kafka tiene la garantía de enviar un evento al menos una vez; excluyó el caso cuando el mensaje no se envió en absoluto. Pero es importante que los consumidores estén preparados para manejar eventos recurrentes. Una forma de hacerlo es utilizar siempre
UPSERT para agregar nuevos registros a la base de datos. Si el registro ya existe con los mismos atributos, la llamada estará esencialmente inactiva. Además, puede agregar un identificador único a cada evento y simplemente omitir los eventos que ya se han procesado anteriormente.
Formatos de datos
Una de las sorpresas al trabajar con Kafka puede ser su simple actitud hacia el formato de datos. Puede enviar cualquier cosa en bytes y los datos se enviarán al consumidor sin ninguna verificación. Por un lado, brinda flexibilidad y le permite no preocuparse por el formato de datos. Por otro lado, si el productor decide cambiar los datos que se envían, existe la posibilidad de que algún consumidor finalmente se rompa.
Antes de construir una arquitectura orientada a eventos, seleccione un formato de datos y analice cómo ayudará en el futuro registrar y desarrollar esquemas.
Uno de los formatos recomendados para su uso, por supuesto, es JSON. Este formato es legible y compatible con todos los lenguajes de programación conocidos. Pero hay dificultades. Por ejemplo, el tamaño de los datos finales en JSON puede llegar a ser terriblemente grande. Se requiere el formato para almacenar pares clave-valor, que es lo suficientemente flexible, pero los datos se duplican en cada evento. Cambiar el esquema también es una tarea difícil porque no hay soporte incorporado para superponer una clave sobre otra si necesita cambiar el nombre del campo.
El equipo que creó Kafka aconseja a
Avro como un sistema de serialización. Los datos se envían en forma binaria, y este no es el formato más legible para los humanos, pero en el interior hay un soporte más confiable para los circuitos. La entidad final en Avro incluye tanto el esquema como los datos. Avro también admite ambos tipos simples, como los números y los complejos: fechas, matrices, etc. Además, le permite incluir documentación dentro del esquema, lo que le permite comprender el propósito de un campo específico en el sistema y contiene muchas otras herramientas integradas para trabajar con el esquema.
avro-builder es una gema creada por Salsify que ofrece un DSL similar al rubí para crear esquemas. Puedes leer más sobre Avro en
este artículo .
Información adicional
Si está interesado en cómo alojar Kafka o cómo se usa en Heroku, hay varios informes que pueden ser de su interés.
Jeff Chao en DataEngConf SF '17 "
Más allá de 50,000 particiones: cómo Heroku opera y empuja los límites de Kafka a escala "
Pavel Pravosud en la
conferencia Dreamforce '16 “
Dogfooding Kafka: Cómo construimos la plataforma de eventos en tiempo real de la plataforma de Heroku ”
Que tengas una linda vista!