Los registros son una parte importante del sistema, lo que le permite comprender que funciona (o no funciona), como se esperaba. En las condiciones de la arquitectura de microservicios, el trabajo con registros se convierte en una disciplina separada de una Olimpiada especial. Debe resolver de inmediato un montón de preguntas:
- cómo escribir registros desde la aplicación;
- donde escribir registros;
- cómo entregar registros para almacenamiento y procesamiento;
- cómo procesar y almacenar registros.
El uso de tecnologías de contenedorización, ahora populares, agrega arena sobre el rastrillo al campo de opciones de solución.
Sobre esta decodificación del informe de Yuri Bushmelev "Rastrillo de mapa en el campo de la recolección y entrega de registros"
A quién le importa, por favor, debajo del gato.
Me llamo Yuri Bushmelev. Yo trabajo en Lazada. Hoy hablaré sobre cómo hicimos nuestros registros, cómo los recolectamos y qué escribimos allí.

De donde somos Quienes somos Lazada es la tienda en línea número 1 en seis países del sudeste asiático. Todos estos países están distribuidos por centros de datos. Ahora hay 4 centros de datos, ¿por qué es esto importante? Porque algunas decisiones se debieron al hecho de que existe un vínculo muy débil entre los centros. Tenemos una arquitectura de microservicios. Me sorprendió descubrir que ya tenemos 80 microservicios. Cuando comencé la tarea con registros, solo había 20. Además, hay una parte bastante grande del legado de PHP, que también tiene que vivir y soportar. Todo esto nos genera actualmente más de 6 millones de mensajes por minuto en todo el sistema en su conjunto. Además, mostraré cómo estamos tratando de vivir con eso y por qué esto es así.

Necesitamos vivir de alguna manera con estos 6 millones de mensajes. ¿Qué debemos hacer con ellos? 6 millones de mensajes que necesitas:
- enviar desde la aplicación
- aceptar para la entrega
- entregar para análisis y almacenamiento.
- para analizar
- de alguna manera almacenar.

Cuando aparecieron tres millones de mensajes, tenía el mismo aspecto. Porque comenzamos con algunos centavos. Está claro que los registros de aplicaciones están escritos allí. Por ejemplo, no pude conectarme a la base de datos, pude conectarme a la base de datos, pero no pude leer algo. Pero además de esto, cada uno de nuestros microservicios también escribe un registro de acceso. Cada solicitud que llega a un microservicio cae en el registro. ¿Por qué estamos haciendo esto? Los desarrolladores quieren poder rastrear. En cada registro de acceso hay un campo traza, a lo largo del cual una interfaz especial desenrolla aún más toda la cadena y muestra bellamente la traza. El seguimiento muestra cómo fue la solicitud, y esto ayuda a nuestros desarrolladores a lidiar rápidamente con cualquier basura no identificada.

¿Cómo vivir con eso? Ahora describiré brevemente el campo de opciones: cómo en general se resuelve este problema. Cómo resolver el problema de recopilar, transferir y almacenar registros.

¿Cómo escribir desde la aplicación? Está claro que hay diferentes formas. En particular, hay mejores prácticas, como nos dicen los camaradas de moda. Hay una vieja escuela en dos formas, como dijeron los abuelos. Hay otras formas

Con la recopilación de registros sobre la misma situación. No hay muchas opciones para resolver esta parte en particular. Ya hay más, pero no tantos.

Pero con la entrega y el análisis posterior, el número de variaciones comienza a explotar. No describiré cada opción ahora. Creo que todas las personas interesadas en el tema escuchan las principales opciones.

Mostraré cómo lo hicimos en Lazada, y cómo comenzó todo.

Hace un año, vine a Lazada y me enviaron a un proyecto sobre troncos. Fue asi. El registro de la aplicación se escribió en stdout y stderr. Hicieron todo de manera elegante. Pero luego los desarrolladores lo eliminaron de los flujos estándar, y luego los especialistas en infraestructura lo resolverán de alguna manera. Entre los especialistas en infraestructura y los desarrolladores también hay versiones que dicen: "uh ... bueno, envuélvalos en un archivo con un shell, eso es todo". Y como todo esto está en el contenedor, lo envolvieron en el contenedor, descargaron el catálogo y lo pusieron allí. Creo que es aproximadamente obvio para todos lo que surgió.

Veamos un poco más lejos. ¿Cómo entregamos estos registros? Alguien eligió td-agent, que en realidad es fluido, pero no con bastante fluidez. Todavía no entendía la relación de estos dos proyectos, pero parecen ser casi lo mismo. Y este fluido, escrito en Ruby, lee los archivos de registro, los analiza en JSON durante algunos períodos regulares. Luego los envió a Kafka. Y en Kafka para cada API teníamos 4 temas separados. ¿Por qué 4? Porque hay vivo, hay puesta en escena, y porque hay stdout y stderr. Los desarrolladores los dan a luz, y los ingenieros de infraestructura deben crearlos en Kafka. Además, Kafka estaba controlada por otro departamento. Por lo tanto, era necesario crear un ticket para que crearan 4 temas para cada API allí. Todos lo olvidaron. En general, había basura y humos.
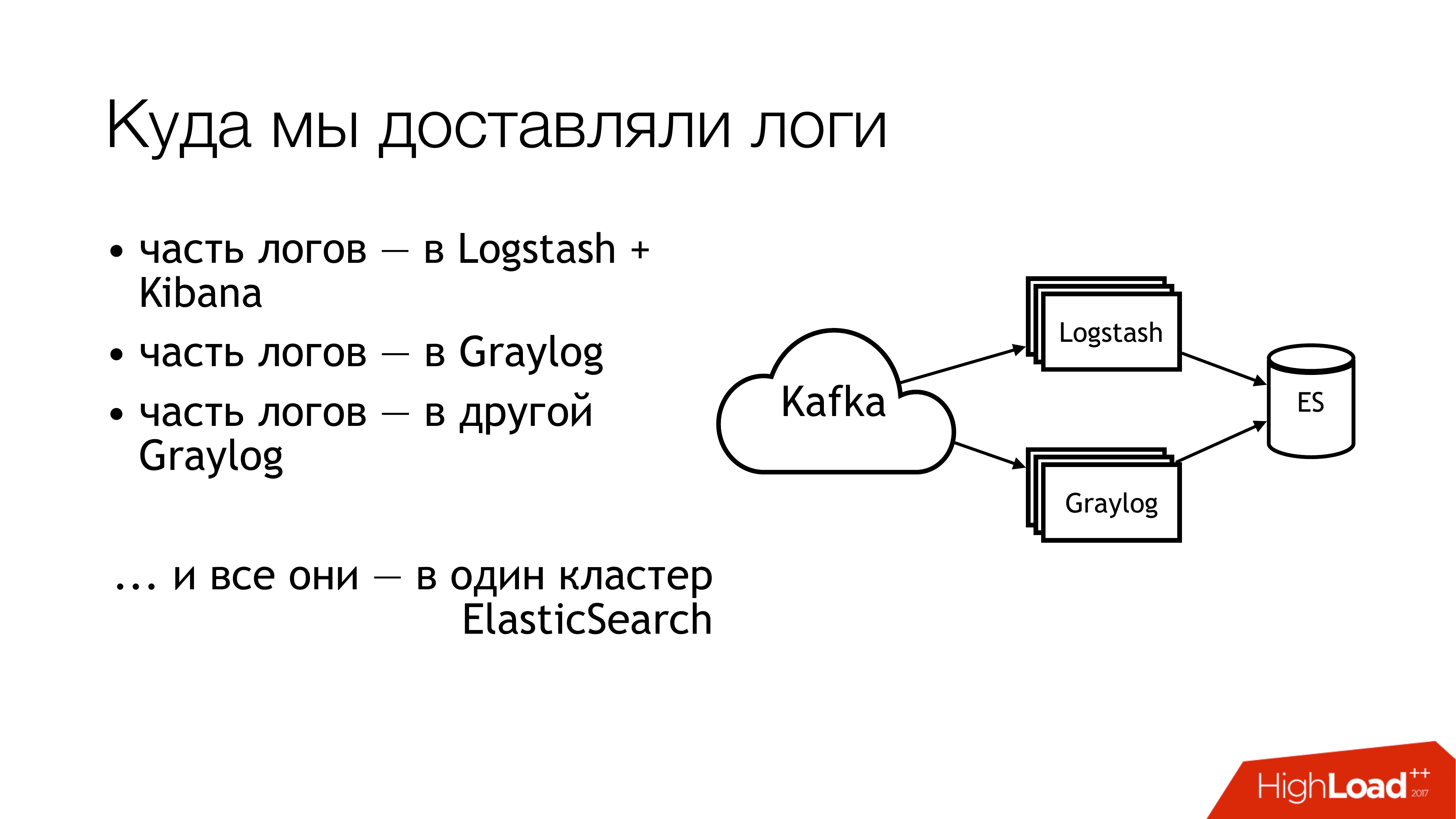
¿Qué hicimos después con esto? Lo enviamos a kafka. Más allá de Kafka, la mitad de los troncos volaron a Logstash. La otra mitad de los registros fue compartida. Parte voló en un Graylog, parte - en otro Graylog. Como resultado, todo esto voló en un clúster Elasticsearch. Es decir, todo este desastre finalmente cayó allí. ¡No tienes que hacer esto!

Así es como se ve si miras remotamente desde arriba. ¡No hagas esto! Aquí, los números indican inmediatamente las áreas problemáticas. En realidad, hay más de ellos, pero 6 son realmente bastante problemáticos, con lo que debes hacer algo. Hablaré de ellos por separado ahora.

Aquí (1,2,3) estamos escribiendo archivos y, en consecuencia, aquí hay tres rastrillos a la vez.
El primero (1) es que necesitamos escribirlos en alguna parte. No siempre quisiera darle a la API la capacidad de escribir directamente en un archivo. Es deseable que la API esté aislada en el contenedor, y aún mejor, que sea de solo lectura. Soy un administrador de sistemas, así que tengo una visión ligeramente alternativa de estas cosas.
El segundo punto (2,3): tenemos muchas solicitudes que llegan a la API. La API escribe muchos datos en un archivo. Los archivos están creciendo. Necesitamos rotarlos. Porque de lo contrario no hay forma de obtener ningún disco. Rotarlos es malo porque se redirigen a través del shell a un directorio. No podemos moverlo de ninguna manera. No se le puede decir a una aplicación que redescubra los descriptores. Porque los desarrolladores te mirarán como un tonto: “¿Cuáles son los descriptores? Generalmente escribimos a stdout ". Los ingenieros de infraestructura hicieron copytruncate en logrotate, lo que hace solo una copia del archivo y trankeytit el original. En consecuencia, entre estos procesos de copia, el espacio en disco generalmente termina.
(4) Teníamos diferentes formatos y estábamos en diferentes API. Eran ligeramente diferentes, pero la expresión regular tuvo que escribirse de manera diferente. Como todo esto estaba controlado por Puppet, había un gran paquete de clases con sus cucarachas. Además, td-agent la mayor parte del tiempo podría comer memoria, estúpido, simplemente podría fingir que funciona y no hacer nada. Afuera, era imposible entender que no estaba haciendo nada. En el mejor de los casos, se caerá y alguien lo recogerá más tarde. Más precisamente, llegará la alerta, y alguien irá con sus manos.

(6) Y la mayoría de la basura y el desperdicio: fue la búsqueda elástica. Porque era una versión antigua. Porque no teníamos maestros dedicados en ese momento. Teníamos registros heterogéneos en los que los campos podían cruzarse. Se podrían escribir diferentes registros de diferentes aplicaciones con los mismos nombres de campo, pero al mismo tiempo podría haber diferentes datos en su interior. Es decir, un registro viene con Integer en el campo, por ejemplo, nivel. Otro registro viene con String en el campo de nivel. En ausencia de mapeo estático, se obtiene algo tan maravilloso. Si, después de la rotación del índice en elasticsearch, llega el primer mensaje con una cadena, entonces vivimos normalmente. Y si llegó primero con Integer, entonces todos los mensajes posteriores que llegaron con String simplemente se descartan. Porque el tipo de campo no coincide.

Comenzamos a hacer estas preguntas. Decidimos no buscar al culpable.

¡Pero hay que hacer algo! Lo obvio es establecer estándares. Ya teníamos algunos estándares. Algunos los conseguimos un poco más tarde. Afortunadamente, un formato de registro uniforme para todas las API ya estaba aprobado en ese momento. Está escrito directamente en los estándares para la interacción de servicios. En consecuencia, aquellos que quieran recibir registros deben escribirlos en este formato. Si alguien no escribe registros en este formato, no garantizamos nada.
Además, me gustaría establecer un estándar único para los métodos de grabación, entrega y recolección de registros. En realidad, dónde escribirlos y cómo entregarlos. La situación ideal es cuando los proyectos usan la misma biblioteca. Aquí hay una biblioteca de registro separada para Go, hay una biblioteca separada para PHP. Todos los que tenemos, todos deberían usarlos. Por el momento, diría que lo conseguimos en un 80 por ciento. Pero algunos continúan comiendo cactus.
Y allí (en la diapositiva) apenas apareció "SLA para la entrega de registros". Todavía no está allí, pero estamos trabajando en ello. Porque es muy conveniente cuando el infra dice que si escribe en tal y tal formato en tal y tal lugar y no más de N mensajes por segundo, entonces es probable que entreguemos tal y tal cosa allí. Esto alivia un montón de dolores de cabeza. Si hay un SLA, ¡esto es simplemente maravilloso!

¿Cómo comenzamos a resolver el problema? El rastrillo principal fue con td-agent. No estaba claro a dónde iban los registros. ¿Se entregan? Van a? ¿Dónde están en absoluto? Por lo tanto, el primer elemento se decidió reemplazar td-agent. Esbocé brevemente las opciones con las que reemplazarlo.
Fluido En primer lugar, me encontré con él en un trabajo anterior, y él también cayó allí periódicamente. En segundo lugar, esto es lo mismo, solo en el perfil.
Filebeat. ¿Cómo fue conveniente para nosotros? El hecho de que él está en Go, y tenemos mucha experiencia en Go. En consecuencia, si eso, de alguna manera podríamos agregarlo por nosotros mismos. Por lo tanto, no lo tomamos. De modo que incluso ninguna tentación fue comenzar a reescribirlo por ti mismo.
La solución obvia para el administrador del sistema es todos los registros del sistema en esta cantidad (syslog-ng / rsyslog / nxlog).
O escribimos algo propio, pero lo dejamos caer, al igual que filebeat. Si escribe algo, es mejor escribir algo útil para los negocios. Para la entrega de registros es mejor llevar algo listo.
Por lo tanto, la elección en realidad se redujo a la elección entre syslog-ng y rsyslog. Se inclinó hacia rsyslog simplemente porque ya teníamos clases para rsyslog en Puppet, y no encontré ninguna diferencia obvia entre ellos. Qué es syslog, qué es syslog. Sí, alguien tiene peor documentación, alguien tiene mejor. Él sabe cómo y él, de una manera diferente.

Y un poco sobre rsyslog. En primer lugar, es genial porque tiene muchos módulos. Tiene RainerScript legible por humanos (un lenguaje de configuración moderno). Una ventaja increíble es que podríamos emular el comportamiento de td-agent utilizando sus medios habituales, y nada ha cambiado para las aplicaciones. Es decir, estamos cambiando td-agent a rsyslog, pero no estamos tocando todo lo demás. E inmediatamente recibimos una entrega de trabajo. A continuación, mmnormalize es algo increíble en rsyslog. Le permite analizar registros, pero no usar Grok y regexp. Ella hace un árbol de sintaxis abstracta. Analiza los registros aproximadamente, como el compilador analiza los códigos fuente. Esto le permite trabajar muy rápido, comer poca CPU y, en general, es algo muy bueno. Hay toneladas de otras bonificaciones. No me detendré sobre ellos.

Rsyslog todavía tiene muchos defectos. Son casi lo mismo que los bonos. Los principales problemas: necesita poder cocinarlo y debe seleccionar la versión.
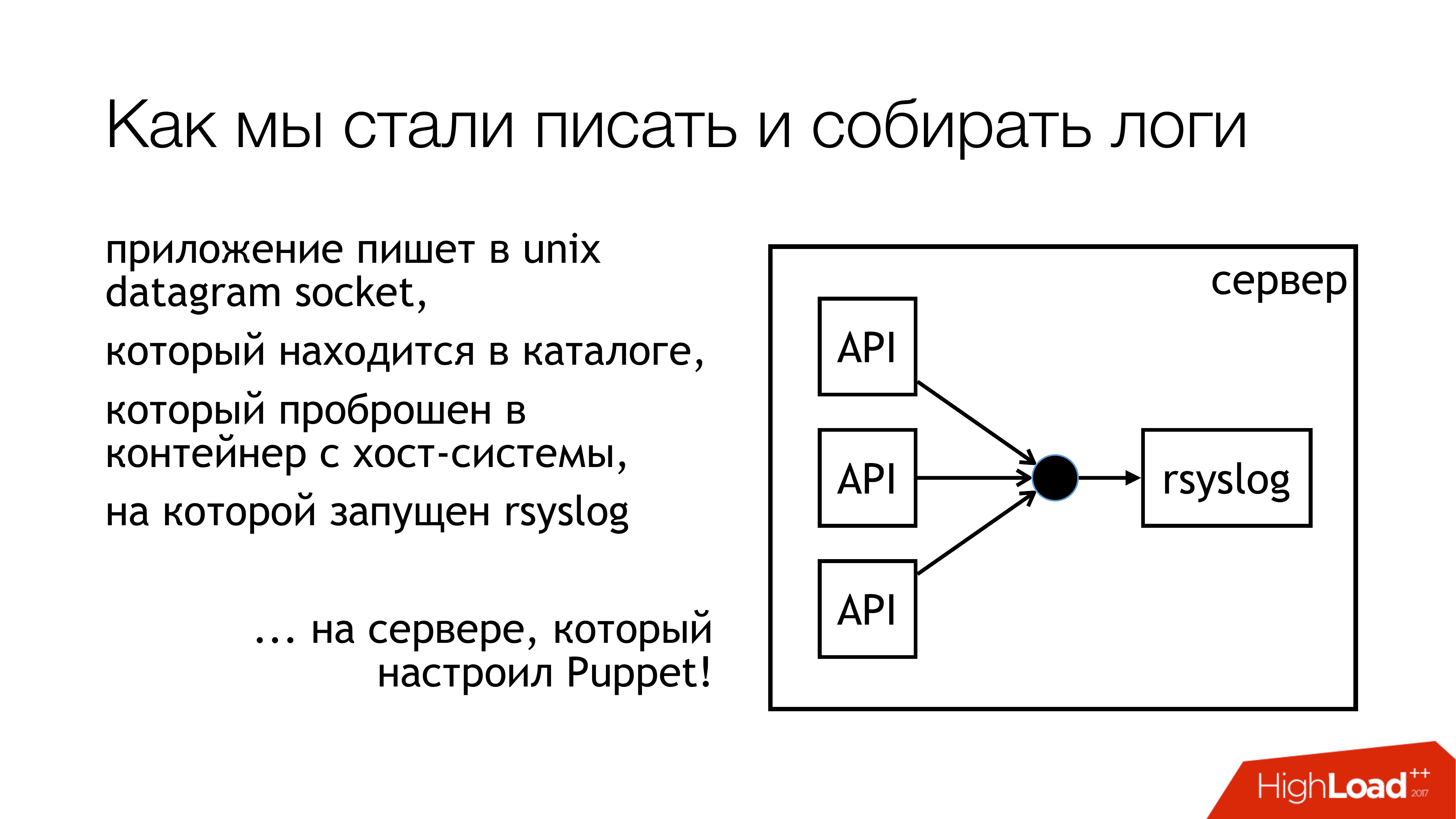
Decidimos que escribiríamos registros en el socket Unix. Y no en / dev / log, porque allí tenemos gachas de ave de los registros del sistema, hay un diario en esta tubería. Así que vamos a escribir en un socket personalizado. Lo adjuntamos a un conjunto de reglas separado. No vamos a interferir Todo será transparente y claro. Así que en realidad lo hicimos. El directorio con estos sockets está estandarizado y se reenvía a todos los contenedores. Los contenedores pueden ver el socket que necesitan, abrirlo y escribirlo.
¿Por qué no un archivo? Porque todos leyeron un artículo sobre Badushechka que intentó reenviar el archivo a Docker, y resultó que después de que rsyslog reiniciara, el descriptor de archivo cambia y Docker pierde este archivo. Mantiene abierto algo más, pero no el mismo zócalo donde escriben. Decidimos que pasaríamos por alto este problema y, al mismo tiempo, pasaríamos por alto el problema de bloqueo.

Rsyslog realiza las acciones indicadas en la diapositiva y envía los registros al relé o a Kafka. Kafka coincide con la vieja manera. Retransmisión: intenté usar rsyslog puro para entregar registros. Sin Message Queue, herramientas estándar de rsyslog. Básicamente funciona.

Pero hay matices sobre cómo incluirlos más adelante en esta parte (Logstash / Graylog / ES). Esta parte (rsyslog-rsyslog) se usa entre centros de datos. Aquí hay un enlace tcp comprimido, que le permite ahorrar ancho de banda y, en consecuencia, de alguna manera aumentar la probabilidad de que recibamos algún tipo de registros de otro centro de datos en condiciones cuando el canal esté lleno. Porque tenemos a Indonesia, en la que todo está mal. Aquí es donde está este problema constante.

Pensamos en cómo monitoreamos realmente, ¿con qué probabilidad llegan a ese fin los registros que registramos desde la aplicación? Decidimos obtener las métricas. Rsyslog tiene su propio módulo de recopilación de estadísticas, que tiene algún tipo de contadores. Por ejemplo, puede mostrarle el tamaño de la cola o cuántos mensajes llegaron en dicha acción. Ya se les puede quitar algo. Además, tiene contadores personalizados que se pueden configurar y le mostrará, por ejemplo, la cantidad de mensajes que escribieron algunas API. Luego, escribí rsyslog_exporter en Python, y lo enviamos todo a Prometheus y lo trazamos. Las métricas de Graylog realmente se querían, pero hasta ahora no hemos tenido tiempo de configurarlas.

Cuales son los problemas? Surgieron problemas con el hecho de que descubrimos (¡REPENTINAMENTE!) Que nuestras API en vivo escriben 50 mil mensajes por segundo. Esta es solo una API en vivo sin puesta en escena. Y Graylog nos muestra solo 12 mil mensajes por segundo. Y surgió una pregunta razonable, pero ¿dónde están las sobras? De lo cual concluimos que Graylog simplemente no puede hacer frente. Miraron y, de hecho, Graylog con Elasticsearch no dominó esta corriente.
Además, otros descubrimientos que hicimos en el proceso.
Escribir en el socket están bloqueados. ¿Cómo sucedió esto? Cuando utilicé rsyslog para la entrega, en algún momento nuestro canal entre los centros de datos se rompió. La entrega se levantó en un lugar, la entrega se levantó en otro lugar. Todo esto ha llegado a una máquina con API que escriben en el socket rsyslog. Había una cola Luego se completó la cola para escribir en el socket de Unix, que por defecto es de 128 paquetes. Y el siguiente write () en la aplicación está bloqueado. Cuando miramos la biblioteca que usamos en las aplicaciones en Go, se escribió allí que la escritura en el socket ocurre en modo sin bloqueo. Estábamos seguros de que nada está bloqueando. Porque leemos un artículo sobre Badushechka que escribió al respecto. Pero hay un momento. Alrededor de esta llamada todavía había un ciclo interminable en el que se hacía un intento constante de insertar el mensaje en el socket. No lo notamos. Tuve que reescribir la biblioteca. Desde entonces, ha cambiado varias veces, pero ahora hemos eliminado los bloqueos en todos los subsistemas. Por lo tanto, puede detener rsyslog y nada caerá.
Es necesario controlar el tamaño de las colas, lo que ayuda a no pisar este rastrillo. Primero, podemos monitorear cuando comenzamos a perder mensajes. En segundo lugar, podemos controlar que, en principio, tenemos problemas de entrega.
Y otro momento desagradable - amplificación 10 veces en arquitectura de microservicio - es muy fácil. No tenemos muchas solicitudes entrantes, pero debido al gráfico que atraviesan estos mensajes, debido a los registros de acceso, realmente aumentamos la carga en los registros aproximadamente una vez cada diez. Lamentablemente, no tuve tiempo para calcular los números exactos, pero sí los microservicios. Esto debe tenerse en cuenta. Resulta que en este momento el subsistema de recopilación de registros es el más cargado en Lazada.

¿Cómo resolver el problema de Elasticsearch? Si necesita obtener rápidamente los registros en un solo lugar, para no ejecutarlos en todas las máquinas y no recopilarlos allí, use el almacenamiento de archivos. Esto está garantizado para trabajar. Está hecho desde cualquier servidor. Solo necesita pegar los discos allí y colocar syslog. Después de eso, tiene la garantía de tener todos los registros en un solo lugar. Además, ya será posible ajustar lentamente Elasticsearch, Graylog, algo más. Pero ya tendrá todos los registros y, además, puede almacenarlos en una cantidad suficiente de matrices de discos.

En el momento de mi informe, el circuito comenzó a verse así. Prácticamente dejamos de escribir en el archivo. Ahora, muy probablemente, apagaremos las sobras. En las máquinas locales que ejecutan la API, dejaremos de escribir en archivos. En primer lugar, hay un almacenamiento de archivos que funciona muy bien. En segundo lugar, el lugar en estas máquinas se agota constantemente, es necesario controlarlo constantemente.
Esta parte con Logstash y Graylog, realmente se dispara. Por lo tanto, debemos deshacernos de él. Tienes que elegir una cosa.

Decidimos lanzar Logstash y Kibana. Porque tenemos un departamento de seguridad. ¿Cuál es la conexión? La conexión es que Kibana sin X-Pack y sin Shield no permite diferenciar los derechos de acceso a los registros. Por lo tanto, tomaron Graylog. El lo tiene todo. No me gusta, pero funciona. Compramos hierro nuevo, pusimos Graylog fresco allí y movimos todos los registros con formatos estrictos a un Graylog separado. Resolvimos el problema con diferentes tipos de campos idénticos organizacionalmente.

Qué se incluye exactamente en el nuevo Graylog. Acabamos de grabar todo en la ventana acoplable. Tomamos un montón de servidores, implementamos tres instancias de Kafka, 7 servidores Graylog versión 2.3 (porque quería Elasticsearch versión 5). Todo esto en las redadas del disco duro planteado. Vimos una tasa de indexación de hasta 100 mil mensajes por segundo. Vimos la cifra de 140 terabytes de datos por semana.

Y de nuevo un rastrillo! Se acercan dos ventas. Nos hemos movido por 6 millones de mensajes. A nosotros Graylog no tiene tiempo para masticar. De alguna manera tenemos que sobrevivir de nuevo.

Sobrevivimos así. Agregamos algunos servidores y SSD más. Por el momento, vivimos de esta manera. Ahora ya estamos masticando 160k mensajes por segundo. Todavía no hemos alcanzado el límite, por lo que aún no está claro cuánto podemos realmente sacar de esto.

Estos son nuestros planes para el futuro. De estos, realmente, el más importante es probablemente la alta disponibilidad. Aún no lo tenemos. Varios automóviles están configurados de la misma manera, pero hasta ahora todo pasa por un solo automóvil. , failover .
Graylog.
rate limit , API, bandwidth .
, - SLA c , . , .
.

, , . -, . -, syslog — . -, rsyslog , . .
.
: - … (filebeat?)
: . . API , , . pipe. : « , , »? , , : « , ».
: HDFS?
: . , , , , long term solution.
: .
: . "" .
: rsyslog. TCP, UDP. UDP, ?
: . , , . , : « , - , - », «! , , , .» . , ? , ? best effort. , 100% . . .
: API - , , ? - .
: , . . , . , API . rsyslog . API , , timestamp . Graylog, timestamp. .
: Timestamp .
: Timestamp API. , , . NTP. API timestamp . rsyslog .
: . , . ? ?
: . - . , . . Log Relay. Rsyslog . . . . . . , (), Graylog. storage. , , . . .
: ?
: ( ) .
: , ?
: , . . , Go API, . , socket. . . socket. , . . , . prometheus, Grafana . . , .
: elasticsearch . ?
: .
: ?
: . .
: rsyslog - ?
: unix socket. 128 . . . , 128 . , , , , . , . .
c : JSON?
: JSON relay, . Graylog, JSON . , , rsyslog. issue, .
c : Kafka? RabbitMQ? Graylog ?
: Graylog . Graylog . . . , , . rsyslog elasticsearch Kibana. . , Graylog Kibana. Logstash . , rsyslog. elasticsearch. Graylog - . . .
Kafka. . , , . . , , . RabbitMQ… c RabbitMQ. RabbitMQ . , . , . . . Graylog AMQP 0.9, rsyslog AMQP 1.0. , , . . Kafka. . omkafka rsyslog, , , rsyslog. .
Pregunta : ¿Utiliza Kafka porque lo tenía? ¿No se usa para ningún otro propósito?
Respuesta : Kafka, que fue utilizada por el equipo de Data Science. Este es un proyecto completamente separado, sobre el cual, desafortunadamente, no puedo decir nada. No lo se. Fue dirigida por el equipo de Data Science. Cuando comenzaron los registros, decidieron usarlo, para no poner los suyos. Ahora hemos actualizado Graylog y hemos perdido la compatibilidad, porque hay una versión antigua de Kafka. Teníamos que conseguir el nuestro. Al mismo tiempo, eliminamos estos cuatro temas para cada API. Hicimos un tema amplio para todo en vivo, un tema amplio para toda la puesta en escena y simplemente viñetas todo allí. Graylog rastrilla todo esto en paralelo.
Pregunta : ¿Por qué es necesario este chamanismo con enchufes? ¿Has intentado usar el controlador de registro syslog para contenedores?
Respuesta : En ese momento cuando hicimos esta pregunta, tuvimos una relación tensa con el acoplador. Fue docker 1.0 o 0.9. Docker en sí era extraño. En segundo lugar, si también empujas los registros en él ... Tengo una sospecha no verificada de que él pasa todos los registros a través de sí mismo, a través del demonio acoplable. Si tenemos una API que se está volviendo loca, entonces el resto de las API están estancadas en el hecho de que no pueden enviar stdout y stderr. No sé a dónde llevará esto. Tengo la sospecha a nivel de sensación de que no necesita utilizar el controlador syslog de Docker en este lugar. Nuestro departamento de pruebas funcionales tiene su propio clúster Graylog con registros. Usan controladores de registro de Docker y todo parece estar bien allí. Pero inmediatamente escriben GELF a Graylog. En ese momento, cuando todo esto estaba en marcha, lo necesitábamos para funcionar. Quizás más tarde, cuando alguien venga y diga que ha estado funcionando normalmente durante cien años, lo intentaremos.
Pregunta : Realiza entregas entre centros de datos en rsyslog. ¿Por qué no en Kafka?
Respuesta : Estamos haciendo ambas cosas, y así en realidad. Por dos razones Si el canal está completamente muerto, entonces tenemos todos los registros, incluso en forma comprimida, no se arrastrarán a través de él. Y kafka les permite simplemente perderse en el proceso. De esta forma nos deshacemos de pegar estos registros. Simplemente usamos Kafka en este caso directamente. Si tenemos un buen canal y queremos liberarlo, entonces usamos su rsyslog. Pero, de hecho, puede configurarlo para que él mismo descarte lo que no se arrastró. Por el momento, estamos en algún lugar utilizando la entrega de rsyslog directamente, en algún lugar de Kafka.