Introducción a los sistemas operativos
Hola Habr! Quiero llamar su atención sobre una serie de artículos-traducciones de una literatura interesante en mi opinión: OSTEP. Este artículo analiza en profundidad el trabajo de los sistemas operativos tipo Unix, a saber, el trabajo con procesos, varios programadores, memoria y otros componentes similares que componen el sistema operativo moderno. El original de todos los materiales que puedes ver
aquí . Tenga en cuenta que la traducción se realizó de manera no profesional (con bastante libertad), pero espero haber conservado el significado general.
El trabajo de laboratorio sobre este tema se puede encontrar aquí:
Otras partes:
Y puedes mirar mi canal en
telegram =)
Planificación: cola de comentarios de varios niveles
En esta conferencia hablaremos sobre los problemas de desarrollar uno de los enfoques más famosos para
La planificación se llama
Multi-Level Feedback Queue (MLFQ). El programador MLFQ fue descrito por primera vez en 1962 por Fernando J. Corbató en un sistema llamado Sistema de tiempo compartido compatible (CTSS). Estos trabajos (incluido el trabajo posterior en Multics) se presentaron posteriormente al Premio Turing. El planificador se mejoró posteriormente y adquirió un aspecto que ya se puede encontrar en algunos sistemas modernos.
El algoritmo MLFQ intenta resolver 2 problemas fundamentales transversales.
Primero , intenta optimizar el tiempo de respuesta, que, como examinamos en la conferencia anterior, se optimiza comenzando al comienzo de la cola de las tareas más cortas. Sin embargo, el sistema operativo no sabe cuánto tiempo funcionará este o aquel proceso, y este es el conocimiento necesario para el funcionamiento de los algoritmos SJF, STCF.
En segundo lugar , MLFQ intenta hacer que el sistema responda a los usuarios (por ejemplo, aquellos que están sentados y mirando la pantalla mientras esperan que se complete la tarea) y así minimizar el tiempo de respuesta. Desafortunadamente, los algoritmos como RR reducen el tiempo de respuesta, pero tienen un efecto muy malo en las métricas de tiempo de respuesta. De ahí nuestro problema: ¿cómo diseñar un planificador que cumpla con nuestros requisitos y al mismo tiempo no sepa nada sobre la naturaleza del proceso, en general? ¿Cómo puede el planificador aprender las características de las tareas que inicia y así tomar mejores decisiones de planificación?
La esencia del problema: ¿Cómo planificar la formulación de tareas sin un conocimiento perfecto? ¿Cómo desarrollar un planificador que minimice simultáneamente el tiempo de respuesta para tareas interactivas y al mismo tiempo minimice el tiempo de respuesta sin saber el tiempo para completar la tarea?Nota: aprender de eventos anteriores
La alineación MLFQ es un gran ejemplo de un sistema que aprende de eventos pasados para predecir el futuro. A menudo se encuentran enfoques similares en el sistema operativo (y en muchas otras ramas de la informática, incluidas las ramas de predicción de hardware y los algoritmos de almacenamiento en caché). Los viajes similares funcionan cuando las tareas tienen fases de comportamiento y, por lo tanto, son predecibles.
Sin embargo, uno debe tener cuidado con tal técnica, porque las predicciones pueden resultar fácilmente erróneas y llevar al sistema a tomar peores decisiones de las que serían sin conocimiento.
MLFQ: Reglas básicas
Considere las reglas básicas del algoritmo MLFQ. Aunque hay varias implementaciones de este algoritmo, los enfoques básicos son similares.
En la implementación que consideraremos, en MLFQ habrá varias colas separadas, cada una de las cuales tendrá una prioridad diferente. En cualquier momento, una tarea lista para su ejecución está en una cola. MLFQ usa prioridades para decidir qué tarea ejecutar, es decir primero se iniciará una tarea con una prioridad más alta (una tarea de la cola con una prioridad más alta).
Sin lugar a dudas, más de una tarea puede estar en una cola particular, por lo que tendrán la misma prioridad. En este caso, el motor RR se utilizará para programar el lanzamiento entre estas tareas.
Así llegamos a dos reglas básicas para MLFQ:
- Regla 1: si la prioridad (A)> Prioridad (B), se iniciará la tarea A (B no)
- Regla 2: Si prioridad (A) = Prioridad (B), A&B se inician usando RR
Con base en lo anterior, los elementos clave para la planificación de MLFQ son prioridades. En lugar de establecer una prioridad fija para cada tarea, MLFQ cambia su prioridad según el comportamiento observado.
Por ejemplo, si una tarea deja de funcionar constantemente en la CPU mientras espera la entrada del teclado, MLFQ mantendrá la prioridad del proceso en un nivel alto, porque así es como debería funcionar el proceso interactivo. Si, por el contrario, la tarea utiliza constante e intensamente la CPU durante un período prolongado, MLFQ reducirá su prioridad. Por lo tanto, MLFQ estudiará el comportamiento de los procesos en el momento de su operación y utilizará el comportamiento.
Dibujemos un ejemplo de cómo podrían verse las colas en algún momento y luego obtenemos algo como esto:

En este esquema, 2 procesos A y B están en la cola con la máxima prioridad. El proceso C está en algún punto intermedio, y el proceso D está al final de la cola. De acuerdo con las descripciones anteriores del algoritmo MLFQ, el planificador ejecutará tareas solo con la prioridad más alta de acuerdo con RR, y las tareas C, D estarán sin trabajo.
Naturalmente, una instantánea estática no dará una imagen completa de cómo funciona MLFQ.
Es importante comprender exactamente cómo cambia la imagen con el tiempo.
Intento 1: cómo cambiar la prioridad
En este punto, debe decidir cómo MLFQ cambiará el nivel de prioridad de la tarea (y, por lo tanto, la posición de la tarea en la cola) durante su ciclo de vida. Para hacer esto, debe tener en cuenta el flujo de trabajo: una serie de tareas interactivas con un tiempo de trabajo corto (y, por lo tanto, una liberación frecuente de la CPU) y varias tareas largas que usan la CPU todo su tiempo de trabajo, mientras que el tiempo de respuesta para tales tareas no es importante. Y así, puede hacer el primer intento de implementar el algoritmo MLFQ con las siguientes reglas:
- Regla 3: cuando una tarea ingresa al sistema, se pone en cola con el más alto
- prioridad
- Regla 4a: Si una tarea usa toda la ventana de tiempo asignada, entonces su
- La prioridad baja.
- Regla 4b: si la tarea libera a la CPU antes de que expire su ventana de tiempo, entonces
- permanece con la misma prioridad.
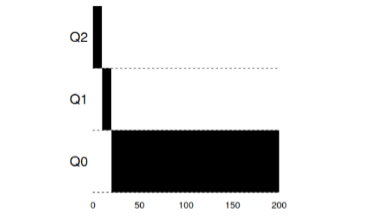
Ejemplo 1: una sola tarea de larga duraciónComo puede ver en este ejemplo, la tarea de admisión se plantea con la máxima prioridad. Después de una ventana de tiempo de 10 ms, el planificador reduce la prioridad del proceso. Después de la próxima ventana de tiempo, la tarea finalmente cae a la prioridad más baja en el sistema, donde permanece.
 Ejemplo 2: trajeron una tarea corta
Ejemplo 2: trajeron una tarea cortaAhora veamos un ejemplo de cómo MLFQ intentará acercarse a SJF. Hay dos tareas en este ejemplo: A, que es una tarea de larga duración que ocupa constantemente la CPU, y B, que es una tarea interactiva corta. Suponga que A ya trabajó durante algún tiempo cuando llega la tarea B.
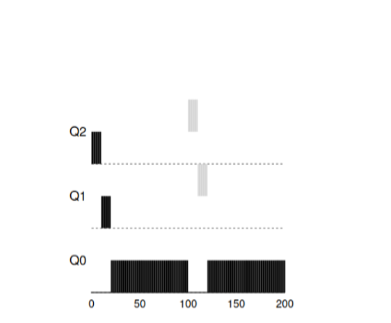
En este gráfico, los resultados del script son visibles. La tarea A, como cualquier tarea que use una CPU, está en la parte inferior. La tarea B llegará a T = 100 y se colocará en la cola con la máxima prioridad. Como el tiempo de su trabajo es corto, terminará antes de llegar a la última etapa.
A partir de este ejemplo, uno debe comprender el objetivo principal del algoritmo: dado que el algoritmo no conoce una tarea larga o corta, en primer lugar se supone que la tarea es corta y le da la máxima prioridad. Si esta es una tarea realmente corta, se completará rápidamente, de lo contrario, si es una tarea larga, se moverá lentamente hacia abajo en prioridad y pronto demostrará que es una tarea realmente larga que no requiere una respuesta.
Ejemplo 3: ¿Qué pasa con las E / S?Ahora eche un vistazo al ejemplo de E / S. Como se indica en la regla 4b, si un proceso libera un procesador sin utilizar completamente su tiempo de procesador, entonces permanece en el mismo nivel de prioridad. La intención de esta regla es bastante simple: si una tarea interactiva realiza muchas operaciones de E / S, por ejemplo, esperando que un usuario presione una tecla o un mouse, dicha tarea liberará el procesador antes de la ventana asignada. No quisiéramos omitir dicha tarea por prioridad y, por lo tanto, permanecerá en el mismo nivel.

Este ejemplo muestra cómo funcionará el algoritmo con dichos procesos: una tarea interactiva B, que necesita una CPU durante solo 1 ms antes de realizar el proceso de E / S, y una tarea larga A, que usa la CPU todo el tiempo.
MLFQ mantiene el proceso B con la máxima prioridad, ya que continúa todo el tiempo.
liberar la CPU. Si B es una tarea interactiva, entonces el algoritmo logró su objetivo de lanzar tareas interactivas rápidamente.
Problemas con el algoritmo MLFQ actualEn los ejemplos anteriores, creamos la versión base de MLFQ. Y parece que hace su trabajo bien y honestamente, distribuyendo honestamente el tiempo del procesador entre tareas largas y permitiendo que las tareas cortas o las tareas de acceso intensivo a E / S funcionen rápidamente. Lamentablemente, este enfoque contiene varios problemas graves.
En primer lugar , el problema del hambre: si hay muchas tareas interactivas en el sistema, consumirán todo el tiempo del procesador y, por lo tanto, no se podrá ejecutar una sola tarea larga (se están muriendo de hambre).
En segundo lugar , los usuarios inteligentes pueden escribir sus programas para que
engañar al planificador. El truco es hacer algo para hacer
planificador para dar al proceso más tiempo de procesador. Algoritmo que
descrito anteriormente es bastante vulnerable a tales ataques: antes de que la ventana de tiempo sea prácticamente
finalizado, debe realizar una operación de E / S (para algunos, sin importar qué archivo)
y así liberar la CPU. Este comportamiento te permitirá permanecer en el mismo
la cola en sí misma y nuevamente obtiene un mayor porcentaje de tiempo de CPU. Si hecho
esto es correcto (por ejemplo, el 99% del tiempo de la ventana antes de liberar la CPU)
tal tarea puede simplemente monopolizar el procesador.
Finalmente, un programa puede cambiar su comportamiento con el tiempo. Esas tareas
quién usó la CPU puede volverse interactivo. En nuestro ejemplo, similar
las tareas no recibirán el tratamiento adecuado del planificador, como otros recibirían
(inicial) tareas interactivas.
Pregunta a la audiencia: ¿qué ataques al planificador podrían realizarse en el mundo moderno?
Intento 2: Elevar la prioridad
Tratemos de cambiar las reglas y ver si podemos evitar problemas con
ayuno ¿Qué podríamos hacer para asegurar que
Las tareas de la CPU tendrán su tiempo (aunque no sea por mucho tiempo).
Como una solución simple al problema, puede ofrecer periódicamente
aumentar la prioridad de todas esas tareas en el sistema. Hay muchas formas
para lograr esto, intentemos implementar como ejemplo algo simple: traducir
todas las tareas a la vez en la más alta prioridad, de ahí la nueva regla:
- Regla 5 : Después de un cierto período de S, transfiera todas las tareas en el sistema a la máxima prioridad.
Nuestra nueva regla resuelve dos problemas a la vez. Primero, los procesos
garantizado para no morir de hambre: las tareas de mayor prioridad compartirán
tiempo de procesador de acuerdo con el algoritmo RR y, por lo tanto, todos los procesos recibirán
tiempo de procesador En segundo lugar, si hay algún proceso que utilizó anteriormente
solo el procesador se vuelve interactivo, entonces permanecerá en línea con el más alto
prioridad después de una vez recibirá un aumento de prioridad al más alto.
Considera un ejemplo. En este escenario, considere un proceso usando

CPU y dos procesos cortos interactivos. A la izquierda de la figura, la figura muestra el comportamiento sin aumentar la prioridad y, por lo tanto, la tarea larga comienza a morir de hambre después de que llegan dos tareas interactivas al sistema. En la figura de la derecha, cada 50 ms aumenta la prioridad y, por lo tanto, se garantiza que todos los procesos recibirán tiempo de procesador y se iniciarán periódicamente. 50ms en este caso se toma como ejemplo, en realidad este número es algo mayor.
Obviamente, la adición de tiempo para un aumento periódico en S conduce a
pregunta lógica: ¿qué valor se debe establecer? Uno de los honrados
Los ingenieros de sistemas John Ousterhout llamaron cantidades similares en sistemas como voo-doo
constante, porque de alguna manera exigían magia negra para corregir
exponiendo Y, desafortunadamente, S tiene ese aroma. Si configura el valor también
grandes tareas largas comenzarán a morir de hambre. Y si establece el valor demasiado bajo,
Las tareas interactivas no recibirán el tiempo de procesador adecuado.
Intento 3: Mejor contabilidad
Ahora tenemos un problema más que debe resolverse: cómo no
dejar engañar a nuestro planificador? Los culpables de esta oportunidad son
reglas 4a, 4b, que permiten que la tarea mantenga prioridad, liberando el procesador
antes de la expiración del tiempo asignado. ¿Cómo lidiar con esto?
La solución en este caso puede considerarse la mejor contabilidad del tiempo de CPU en cada
Nivel MLFQ. En lugar de olvidar el tiempo que el programa usó
procesador para el período asignado, debe considerar y guardarlo. Despues
el proceso ha gastado el tiempo asignado para que se reduzca al siguiente
nivel de prioridad Ahora, no importa cómo el proceso use su tiempo, cómo
computación constante en el procesador o tantas llamadas. De esta manera
La regla 4 debe reescribirse de la siguiente manera:
- Regla 4 : después de que la tarea haya agotado el tiempo asignado en la cola actual (independientemente de cuántas veces haya liberado la CPU), la prioridad de dicha tarea disminuye (baja por la cola).
Veamos un ejemplo:

"
La figura muestra lo que sucede si intenta engañar al planificador, cómo
si fuera con las reglas anteriores 4a, 4b, obtenemos el resultado a la izquierda. Feliz nuevo
La regla es el resultado a la derecha. Antes de la protección, cualquier proceso podría invocar E / S hasta su finalización y
así dominar la CPU, después de habilitar la protección, independientemente del comportamiento
E / S, seguirá bajando por la línea y, por lo tanto, no será deshonesto
tomar posesión de los recursos de la CPU.
Mejora de MLFQ y otros problemas
Con las mejoras anteriores, surgen nuevos problemas: uno de los principales
preguntas: ¿cómo parametrizar tal programador? Es decir Cuanto debe ser
ráfagas? ¿Cuál debería ser el tamaño de la ventana del programa dentro de la cola? Como
La prioridad del programa a menudo debe aumentarse para evitar el hambre y
tener en cuenta los cambios en el comportamiento del programa? Para estas preguntas, no es fácil
respuesta y solo experimentos con cargas y configuración posterior
El planificador puede conducir a un equilibrio satisfactorio.
Por ejemplo, la mayoría de las implementaciones de MLFQ le permiten asignar diferentes
intervalos de tiempo a diferentes colas. Colas de alta prioridad generalmente
Se asignan intervalos cortos. Estas colas consisten en tareas interactivas,
cambiar entre lo que es bastante sensible y debería tomar 10 o menos
ms Por el contrario, las colas de baja prioridad consisten en tareas largas que utilizan
CPU Y en este caso, los intervalos de tiempo largos se ajustan muy bien (100 ms).
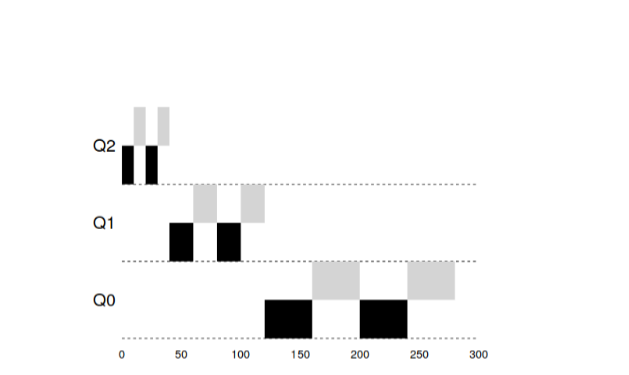
En este ejemplo, hay 2 tareas que funcionaron en la cola de alta prioridad 20
ms, roto por windows durante 10 ms. 40 ms en la cola media (ventana a 20 ms) y en prioridad baja
El tiempo de espera se convirtió en 40 ms, donde las tareas completaron su trabajo.
La implementación de Solaris OS MLFQ es una clase de programadores de tiempo compartido.
El planificador proporciona un conjunto de tablas que determinan exactamente cómo debería
cambiar la prioridad del proceso sobre su vida, cuál debería ser el tamaño
la ventana seleccionada y con qué frecuencia necesita elevar las prioridades de la tarea. Administrador
los sistemas pueden interactuar con esta tabla y hacer que el planificador se comporte
de una manera diferente Por defecto, hay 60 colas incrementales en esta tabla.
tamaño de ventana de 20 ms (prioridad alta) a varios cientos de ms (prioridad más baja), y
También con un impulso de todas las tareas una vez por segundo.
Otros planificadores de MLFQ no usan una tabla ni ninguna
las reglas que se describen en esta conferencia, por el contrario, calculan prioridades utilizando
fórmulas matemáticas Entonces, por ejemplo, el planificador en FreeBSD usa la fórmula para
calcular la prioridad actual de una tarea en función de cuánto el proceso
CPU utilizada Además, el uso de la CPU decae con el tiempo, y así
Por lo tanto, el aumento de prioridad ocurre de manera algo diferente a lo descrito anteriormente. Es asi
llamados algoritmos de descomposición. Desde la versión 7.1, FreeBSD usa el planificador ULE.
Finalmente, muchos planificadores tienen otras características. Por ejemplo, algunos
los planificadores reservan los niveles más altos para el sistema operativo y así
de esta manera, ningún proceso de usuario puede obtener la máxima prioridad en
sistema Algunos sistemas le permiten dar consejos para ayudar.
el planificador para establecer prioridades correctamente. Por ejemplo, usando el comando
nicepuede aumentar o disminuir la prioridad de la tarea y así aumentar o
reducir las posibilidades del programa para el tiempo de procesador.
MLFQ: Resumen
Describimos un enfoque de planificación llamado MLFQ. Su nombre
—
.
:
- Rule1 : () > (), ( )
- Rule2 : () = (), RR
- Rule3 : , .
- Rule4 : ( CPU) ( ).
- Rule5 : S .
MLFQ —
,
. — (SJF, STCF) ,
CPU . , BSD ,
Solaris, Windows, Mac
MLFQ .
:
- manpages.debian.org/stretch/manpages/sched.7.en.html
- en.wikipedia.org/wiki/Scheduling_ (computing)
- pages.lip6.fr/Julia.Lawall/atc18-bouron.pdf
- www.usenix.org/legacy/event/bsdcon03/tech/full_papers/roberson/roberson.pdf
- chebykin.org/freebsd-process-scheduling