
Los desarrolladores están locos por las cosas más extrañas. Todos preferimos considerarnos seres súper racionales, pero cuando se trata de elegir una tecnología en particular, caemos en una especie de locura, saltando de un comentario en HackerNews a una publicación en un blog, y ahora, como si estuviéramos en el olvido, estamos indefensos. Estamos navegando hacia la fuente de luz más brillante y nos inclinamos obedientemente hacia ella, habiendo olvidado por completo lo que estábamos buscando originalmente.
Esto no es en absoluto cómo las personas racionales toman decisiones. Pero exactamente así los desarrolladores deciden usar, por ejemplo, MapReduce.
Como Joe Hellerstein señaló en su conferencia sobre bases de datos para estudiantes universitarios (en el minuto 54):
El hecho es que hay aproximadamente 5 empresas en el mundo que realizan tareas tan ambiciosas. En cuanto a todos los demás ... gastan recursos increíbles para proporcionar un sistema tolerante a fallas que realmente no necesitan. La gente tenía una especie de "googleing" en la década de 2000: "haremos todo exactamente como lo hace Google, porque también gestionamos el servicio de procesamiento de datos más grande del mundo ..." [Irónicamente sacude la cabeza y espera la risa de la audiencia]

¿Cuántos pisos en el edificio de su centro de datos? Google decidió quedarse a las cuatro, al menos en este centro de datos en particular ubicado en el condado de Mays, Oklahoma.
Sí, su sistema es más resistente de lo que necesita, pero piense en lo que podría costar. El punto no es solo la necesidad de procesar grandes cantidades de datos. Es probable que esté intercambiando un sistema completo, con transacciones, índices y optimización de consultas, por algo relativamente débil. Este es un paso significativo hacia atrás. ¿Cuántos usuarios de Hadoop hacen esto conscientemente? ¿Cuántos de ellos toman una decisión realmente equilibrada?
MapReduce / Hadoop es un ejemplo muy simple. Incluso los seguidores del Cargo Cult ya se dieron cuenta de que los aviones no resolverían todos sus problemas. Sin embargo, el uso de MapReduce le permite hacer una generalización importante: si usa tecnología creada para una gran corporación, pero al mismo tiempo resuelve pequeños problemas, puede estar actuando sin pensar. Aun así, lo más probable es que te guíen las ideas místicas de que imitando a gigantes como Google y Amazon, alcanzarás las mismas alturas.

Sí, este artículo es otro oponente del culto a la carga. Pero espere, tengo una lista de verificación útil para usted, que puede usar para tomar decisiones más informadas.
Marco genial: UNPHAT
La próxima vez que busques en Google alguna nueva técnica genial para (re) dar forma a tu sistema, te insto a que pares y solo uses el marco UNPHAT :
- Ni siquiera trate de pensar en posibles soluciones antes de comprender el problema (Comprender) . Su objetivo principal es "resolver" el problema en términos del problema, no en términos de soluciones.
- Enumere (eNumerate) varias soluciones posibles. No es necesario señalar con el dedo inmediatamente su opción favorita.
- Considere una solución separada y luego lea la documentación (Papel) , si la hay.
- Defina el contexto histórico en el que se creó esta solución.
- Ventajas del partido con defectos. Analice lo que los tomadores de decisiones tuvieron que sacrificar para lograr su objetivo.
- ¡Piensa (piensa) ! Considere con sobriedad y calma qué tan bien esta solución es adecuada para satisfacer sus necesidades. ¿Qué debe cambiar exactamente para que cambies de opinión? Por ejemplo, ¿cuánto menos deben ser los datos, para que prefiera no usar Hadoop?
No eres amazon
Usar UNPHAT es fácil. Recordemos mi conversación reciente con una compañía que decidió apresuradamente usar Cassandra para un proceso intensivo de lectura de datos descargados por la noche.
Como ya estaba familiarizado con la documentación de Dynamo y sabía que Cassandra es un sistema derivado, entendí que en estas bases de datos el foco principal estaba en la capacidad de grabar (Amazon necesitaba hacer que la acción "agregar al carrito" nunca no falló) También aprecié que los desarrolladores sacrificaran la integridad de los datos y, de hecho, todas las características inherentes al RDBMS tradicional. Pero después de todo, la compañía con la que hablé, la capacidad de grabar no era una prioridad. Honestamente, el proyecto significaba crear un gran disco al día.

Amazon vende mucho de todo. Si la función "agregar a la cesta" dejara de funcionar de repente, perderían MUCHO dinero. ¿Tienes un problema del mismo orden?
Esta compañía decidió usar Cassandra porque le tomó varios minutos completar la consulta PostgreSQL en cuestión, y decidieron que estas eran limitaciones técnicas por parte de su hardware. Después de aclarar un par de puntos, nos dimos cuenta de que la tabla constaba de aproximadamente 50 millones de filas de 80 bytes cada una. Le tomaría unos 5 segundos leerlo desde el SSD si tuviera que revisarlo por completo. Esto es lento, pero aún es dos órdenes de magnitud más rápido que la velocidad de ejecución de la consulta en ese momento.
En esta etapa, tenía muchas preguntas (U = entender, ¡entender el problema!) Y comencé a sopesar alrededor de 5 estrategias diferentes que podrían resolver el problema original (N = eNumerate, ¡enumere algunas posibles soluciones!), Pero en cualquier caso Ya estaba claro hasta el momento que usar Cassandra era fundamentalmente una decisión equivocada. Todo lo que necesitaban era un poco de paciencia para configurar, probablemente un nuevo diseño para la base de datos y, posiblemente (aunque poco probable), la elección de una tecnología diferente ... Pero definitivamente no era un almacenamiento de datos de valor clave con grabación intensiva que Amazon creó para su cesta!
No eres LinkedIn
Me sorprendió mucho descubrir que una startup de estudiantes decidió construir su arquitectura alrededor de Kafka. Eso fue asombroso. Por lo que pude ver, su negocio llevó a cabo solo unas pocas docenas de operaciones muy grandes por día. Quizás unos cientos en los días más exitosos. Con este ancho de banda, el almacén de datos principal podría ser entradas escritas a mano en un libro ordinario.
A modo de comparación, recuerde que Kafka fue creado para manejar todos los eventos analíticos en LinkedIn. Esto es solo una enorme cantidad de datos. Incluso hace un par de años, se trataba de aproximadamente 1 billón de eventos diarios , con una carga máxima de 10 millones de mensajes por segundo. Por supuesto, entiendo que Kafka se puede usar para trabajar con cargas más bajas, ¿pero para 10 pedidos menos?

El Sol, siendo un objeto muy masivo, es solo 6 órdenes de magnitud más pesado que la Tierra.
Tal vez los desarrolladores incluso tomaron una decisión deliberada, basada en las necesidades esperadas y una buena comprensión del propósito de Kafka. Pero creo que estaban más bien alimentados por el entusiasmo (generalmente justificado) de la comunidad por Kafka y casi nunca se preguntaron si esta era realmente la herramienta que necesitaban. Solo imagina ... ¡10 pedidos!
¿Ya dije eso? No eres amazon
Aún más popular que el almacén de datos distribuido de Amazon, es el enfoque de diseño arquitectónico que les proporciona escalabilidad: una arquitectura orientada a servicios. Como Werner Vogels señaló en una entrevista de 2006 con Jim Gray, Amazon se dio cuenta en 2001 de que estaban teniendo dificultades para escalar la parte frontal y que una arquitectura orientada a servicios podría ayudarlos. Esta idea infectó a un desarrollador tras otro, mientras que las startups, que constaban de solo un par de desarrolladores y casi ningún cliente, no comenzaron a dividir su software en nanoservicios.
Cuando Amazon decidió cambiar a SOA (arquitectura orientada a servicios), tenían unos 7.800 empleados y sus ventas superaron los $ 3 mil millones .

El Auditorio Bill Graham de la Sala de Conciertos en San Francisco tiene capacidad para 7,000 personas. Amazon tenía unos 7.800 empleados cuando cambiaron a SOA.
Esto no significa que deba posponer la transición a SOA hasta que su empresa alcance el nivel de 7800 empleados ... solo piense siempre con su propia cabeza . ¿Es esta realmente la mejor solución para su tarea? ¿Cuál es exactamente la tarea que tienes delante y hay otras formas de resolverla?
Si me dice que el trabajo de su organización, que consta de 50 desarrolladores, simplemente terminará sin SOA, entonces me pregunto por qué tantas grandes empresas simplemente trabajan maravillosamente usando una aplicación única pero bien organizada.
Incluso Google no es Google.
Los ejemplos del uso de sistemas para procesar flujos de datos altamente cargados (Hadoop o Spark) pueden ser realmente desconcertantes. Muy a menudo, los DBMS tradicionales se adaptan mejor a la carga, y a veces la cantidad de datos es tan pequeña que incluso la memoria disponible sería suficiente para ellos. ¿Sabía que puede comprar 1 TB de RAM en algún lugar por $ 10,000? Incluso si tuviera mil millones de usuarios, aún podría proporcionar a cada uno de ellos 1 KB de RAM.
Quizás esto no sea suficiente para su carga, porque necesitará leer y escribir en el disco. ¿Pero realmente necesita varios miles de discos para leer y escribir? Aquí está la cantidad de datos que tiene de hecho? GFS y MapReduce se crearon para resolver problemas informáticos en Internet ... por ejemplo, para volver a calcular el índice de búsqueda en Internet .
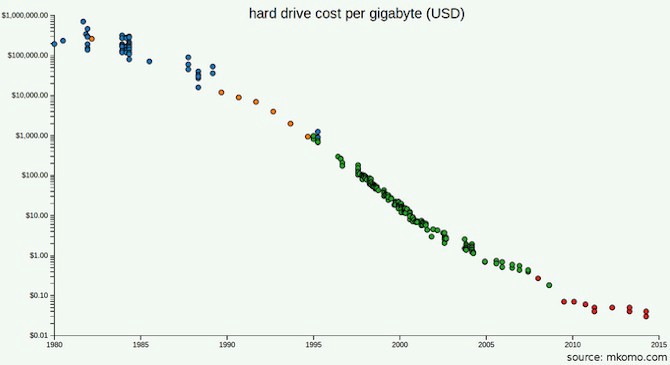
Los precios de los discos duros ahora son mucho más bajos que en 2003 cuando se publicó la documentación de GFS.
Tal vez leyó la documentación de GFS y MapReduce y notó que uno de los problemas para Google no era la cantidad de datos, sino el ancho de banda (velocidad de procesamiento): usaban almacenamiento distribuido porque tomaba demasiado tiempo transferir bytes de los discos. Pero, ¿cuál será el ancho de banda de los dispositivos que usará este año? Dado que ni siquiera necesita tantos dispositivos como Google, ¿sería mejor comprar unidades más modernas? ¿Cuánto costará usar un SSD?
Tal vez desee considerar la escalabilidad de antemano. ¿Ya has hecho todos los cálculos necesarios? ¿Va a acumular datos más rápido de lo que bajan los precios de SSD? ¿Cuántas veces tendrá que crecer su negocio para que todos los datos disponibles ya no quepan en un dispositivo? A partir de 2016, Stack Exchange procesaba 200 millones de consultas por día con soporte para solo 4 servidores SQL : el principal para Stack Overflow, uno más para todo lo demás y dos copias.
Una vez más, puede recurrir a UNPHAT y aún decidir usar Hadoop o Spark. Y la decisión puede incluso ser correcta. Lo principal es que realmente utilizas la tecnología adecuada para resolver tu problema . Por cierto, esto es bien conocido en Google: cuando decidieron que MapReduce no era adecuado para la indexación, dejaron de usarlo.
Primero lo primero, comprende el problema
Mi mensaje puede no ser algo nuevo, pero puede ser de esa forma que le responderá o tal vez le sea fácil recordar UNPHAT y aplicarlo en la vida. Si no, puedes ver a Rich Hickey hablar en el Hammock Driven Development , o en el libro de Paul , Cómo resolverlo , o El arte de hacer ciencia e ingeniería de Hamming. ¡Porque lo principal que todos pedimos es pensar!
Y realmente entiendo el problema que estás tratando de resolver. En las palabras inspiradoras de Pablo:
“ Es una tontería responder una pregunta que no entiendes. Es triste luchar por un objetivo que no quieres alcanzar ".
Traducción al ruso
Traducción: Alexander Tregubov
Editado por Alexey Ivanov (@ponchiknews)
Comunidad: @ponchiknews
Figura: Equipo de contenido de LucidChart