Un buen servicio de reserva de taxis debe ser seguro, confiable y rápido. El usuario no entrará en detalles: es importante para él que haga clic en el botón Ordenar y reciba un automóvil lo antes posible, lo que lo entregará del punto A al punto B. Si no hay automóviles cerca, el servicio debe informar inmediatamente sobre esto para que el cliente no evolucionó falsas expectativas. Pero si la placa "Sin automóviles" se muestra con demasiada frecuencia, es lógico que una persona simplemente deje de usar este servicio y vaya a un competidor.
En este artículo quiero hablar sobre cómo, con la ayuda del aprendizaje automático, resolvimos el problema de encontrar automóviles en un territorio de baja densidad (en otras palabras, donde, a primera vista, no hay automóviles). Y lo que salió de eso.
Antecedentes
Para llamar a un taxi, el usuario toma algunos pasos simples y ¿qué sucede en las entrañas del servicio?
Sobre
ETA en el pin , ya hemos escrito el
cálculo del precio y la
elección del controlador más adecuado . Y esta es una historia sobre la búsqueda de conductores. Cuando se crea un pedido, la búsqueda se produce dos veces: en el pin y en el pedido. La búsqueda en el pedido se realiza en dos etapas: reclutamiento de candidatos y clasificación. Primero, hay conductores candidatos gratuitos que vienen a lo largo del gráfico de carreteras. Luego se aplican bonificaciones y filtros. Los candidatos restantes se clasifican y el ganador recibe una oferta del pedido. Si está de acuerdo, entonces se asigna al pedido y se dirige al punto de entrega. Si se niega, la oferta llega a la siguiente. Si no hay más candidatos, la búsqueda comienza nuevamente. Esto no dura más de tres minutos, después de lo cual el pedido se cancela, se quema.
La búsqueda en el pin es similar a la búsqueda en el pedido, solo que el pedido no se crea y la búsqueda en sí se realiza solo una vez. Además, se utilizan configuraciones simplificadas para el número de candidatos y el radio de búsqueda. Tales simplificaciones son necesarias, porque hay un orden de magnitud más pines que órdenes, y la búsqueda es una operación bastante difícil.
El momento clave para nuestra historia: si durante la búsqueda preliminar en el pin no hubo candidatos adecuados, entonces no permitimos hacer un pedido. Al menos solía ser.
Esto es lo que el usuario vio en la aplicación:
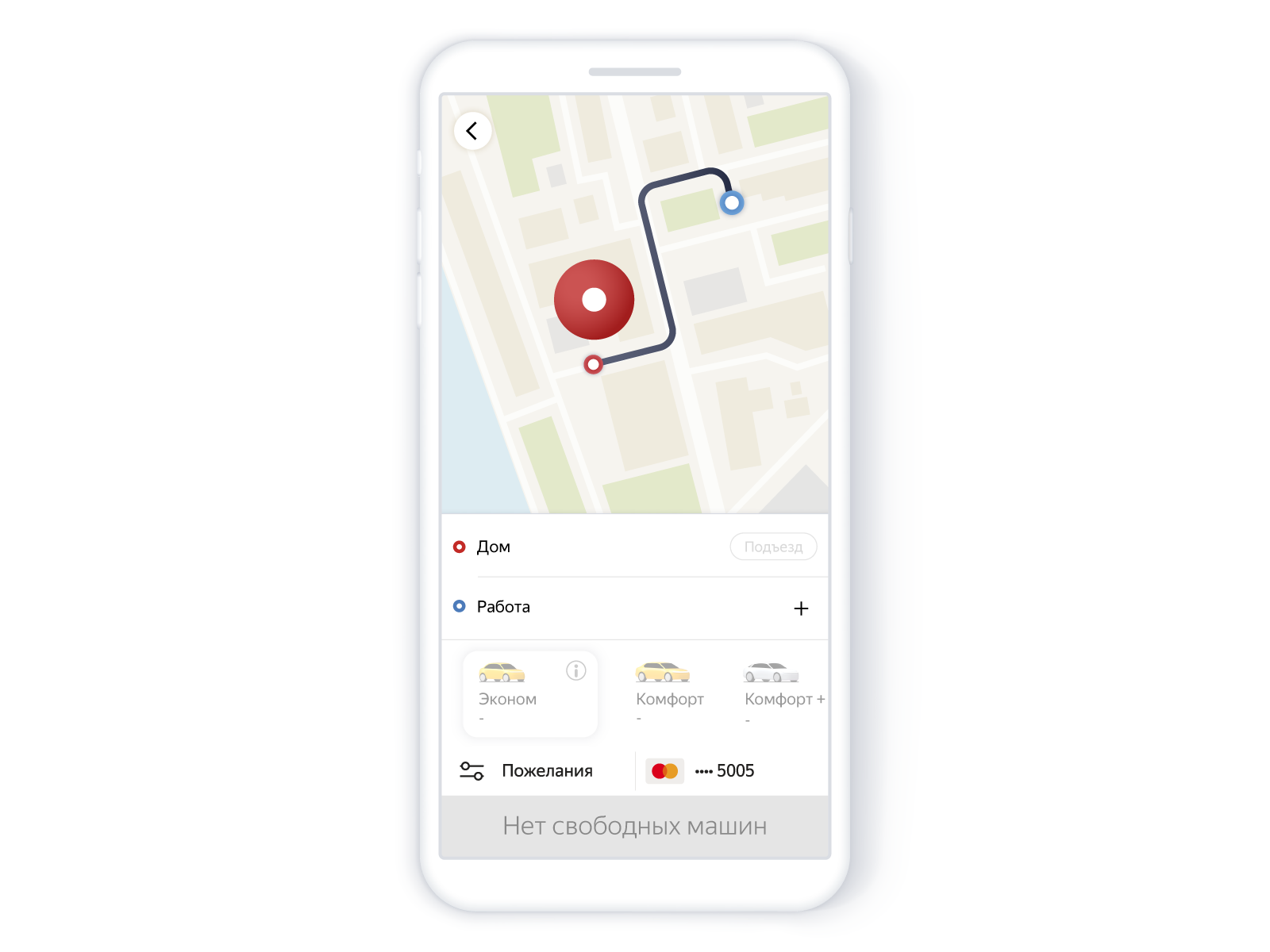
Buscar autos sin autos
Una vez que teníamos una hipótesis: quizás, en algunos casos, el pedido aún se puede completar, incluso si no había autos en el pasador. De hecho, pasa un tiempo entre el pin y el pedido, y la búsqueda en el pedido es más completa y a veces se repite varias veces: durante este tiempo pueden aparecer controladores gratuitos. También sabíamos lo contrario: si los controladores se encontraban en un pin, entonces no es un hecho que se encontrarán al hacer el pedido. A veces desaparecen o todos rechazan el pedido.
Para probar esta hipótesis, lanzamos un experimento: dejamos de verificar la presencia de máquinas durante una búsqueda de pines para un grupo de prueba de usuarios, es decir, tuvieron la oportunidad de hacer un "pedido sin máquinas". El resultado fue bastante inesperado:
si el automóvil no estaba en el pasador, en el 29% de los casos fue más tarde, ¡al buscar un pedido! Además, los pedidos sin automóviles no diferían mucho de los habituales en términos de tasas de cancelación, calificaciones y otros indicadores de calidad. El número de pedidos sin automóviles fue del 5% de todos los pedidos, pero un poco más del 1% de todos los viajes exitosos.
Para entender de dónde provienen los ejecutores de estas órdenes, veamos sus estados durante la búsqueda en el pin:
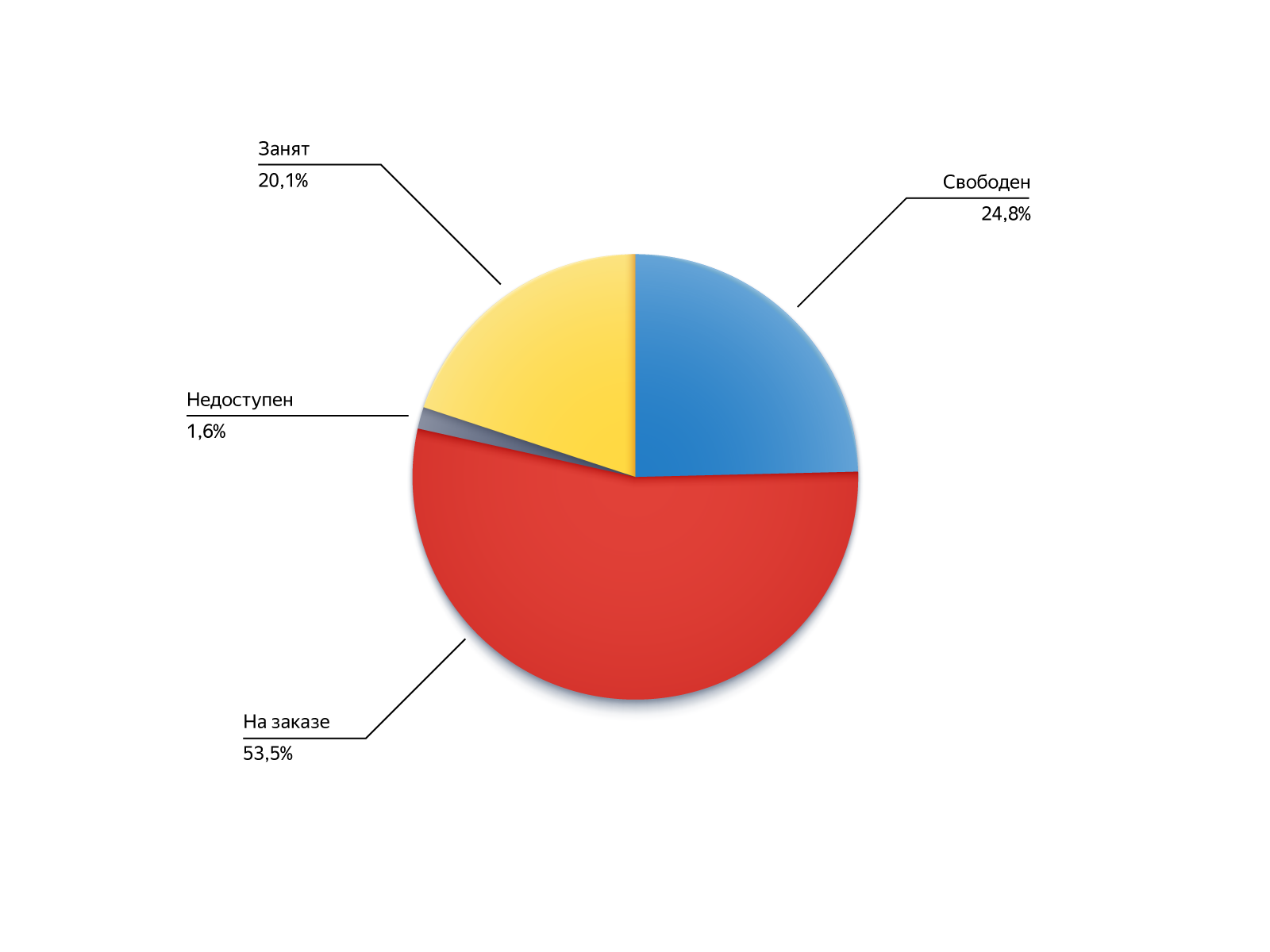
- Gratis: estaba disponible, pero por alguna razón no se metió en los candidatos, por ejemplo, estaba demasiado lejos;
- En orden: estaba ocupado, pero logró liberarse o estar disponible para ordenar a lo largo de la cadena ;
- Ocupado: se deshabilitó la capacidad de tomar pedidos, pero luego el conductor regresó a la línea;
- No disponible: el controlador no estaba en línea, pero apareció.
Agregar confiabilidad
Los pedidos adicionales son geniales, pero el 29% de las búsquedas exitosas significan que en el 71% de los casos el usuario ha estado esperando mucho tiempo y como resultado no se ha ido a ninguna parte. Aunque desde el punto de vista de la eficiencia del sistema esto no es terrible, de hecho, el usuario recibe falsas esperanzas y pasa tiempo, después de lo cual está molesto y (posiblemente) deja de usar el servicio. Para resolver este problema, aprendimos a predecir la probabilidad de que se encuentre una máquina en el pedido.
El esquema es el siguiente:
- El usuario pone un pin.
- Buscando en el pin.
- Si no hay automóviles, predecimos: tal vez aparecerán.
- Y dependiendo de la probabilidad, damos o no una orden, pero advertimos que la densidad de automóviles en esta área es pequeña en este momento.
En la aplicación, se veía así:
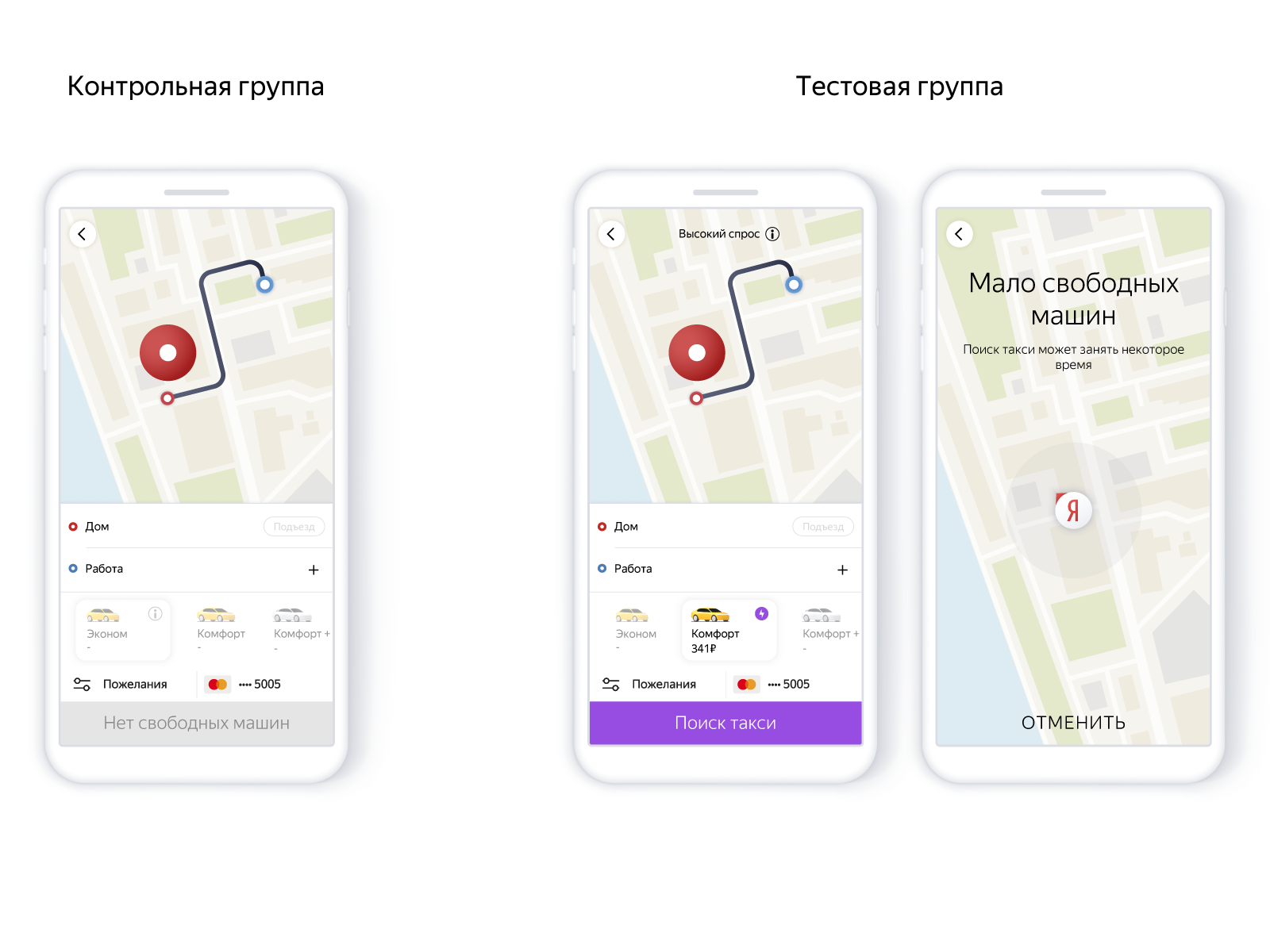
El uso del modelo le permite crear cuidadosamente nuevas órdenes, no tranquilizar a una persona en vano. Es decir, para ajustar la relación de confiabilidad y el número de pedidos sin máquinas que utilizan el modelo de recuperación de precisión. La confiabilidad del servicio afecta el deseo de continuar usando el producto, es decir, al final, todo se reduce a la cantidad de viajes.
Un poco sobre el recuerdo de precisiónUna de las tareas básicas en el aprendizaje automático es el problema de clasificación: asignar un objeto a una de dos clases. En este caso, el resultado del funcionamiento del algoritmo de aprendizaje automático a menudo se convierte en una estimación numérica de pertenencia a una de las clases, por ejemplo, una estimación de probabilidad. Sin embargo, las acciones que se llevan a cabo suelen ser binarias: si tenemos un automóvil, lo damos a la orden, y si no, entonces no. Para mayor precisión, llamaremos al modelo un algoritmo que produce una estimación numérica, y el clasificador, una regla que se relaciona con una de dos clases (1 o –1). Para hacer un clasificador basado en la evaluación del modelo, debe seleccionar un umbral de evaluación. Cómo exactamente, depende en gran medida de la tarea.
Supongamos que hacemos una prueba (clasificador) para alguna enfermedad rara y peligrosa. Según los resultados de la prueba, enviamos al paciente para un examen más detallado o le decimos: "Saludable, vete a casa". Para nosotros, enviar a una persona enferma a casa es mucho peor que examinar a una persona sana en vano. Es decir, queremos que la prueba funcione para la mayor cantidad posible de personas realmente enfermas. Este valor se llama recordar =
. El recuerdo ideal del clasificador es 100%. Una situación degenerada es enviar a todos a un examen, luego el retiro también será del 100%.
Sucede y viceversa. Por ejemplo, hacemos un sistema de prueba para estudiantes y tiene un detector de trampas. Si de repente un cheque no funciona para algunos casos de trampa, entonces esto es desagradable, pero no crítico. Por otro lado, es extremadamente malo culpar injustamente a los estudiantes por lo que no hicieron. Es decir, es importante para nosotros que entre las respuestas positivas del clasificador haya tantas respuestas correctas como sea posible, posiblemente en detrimento de su número. Entonces necesitas maximizar la precisión =
. Si las operaciones comienzan a ocurrir en todos los objetos, la precisión será igual a la frecuencia de la clase determinada en la muestra.
Si el algoritmo proporciona un valor numérico de probabilidad, entonces, al elegir diferentes umbrales, puede lograr diferentes valores de recuperación de precisión.
En nuestra tarea, la situación es la siguiente. Recordar es la cantidad de pedidos que podemos ofrecer, la precisión es la fiabilidad de estos pedidos. Aquí está la curva de recuperación de precisión de nuestro modelo:
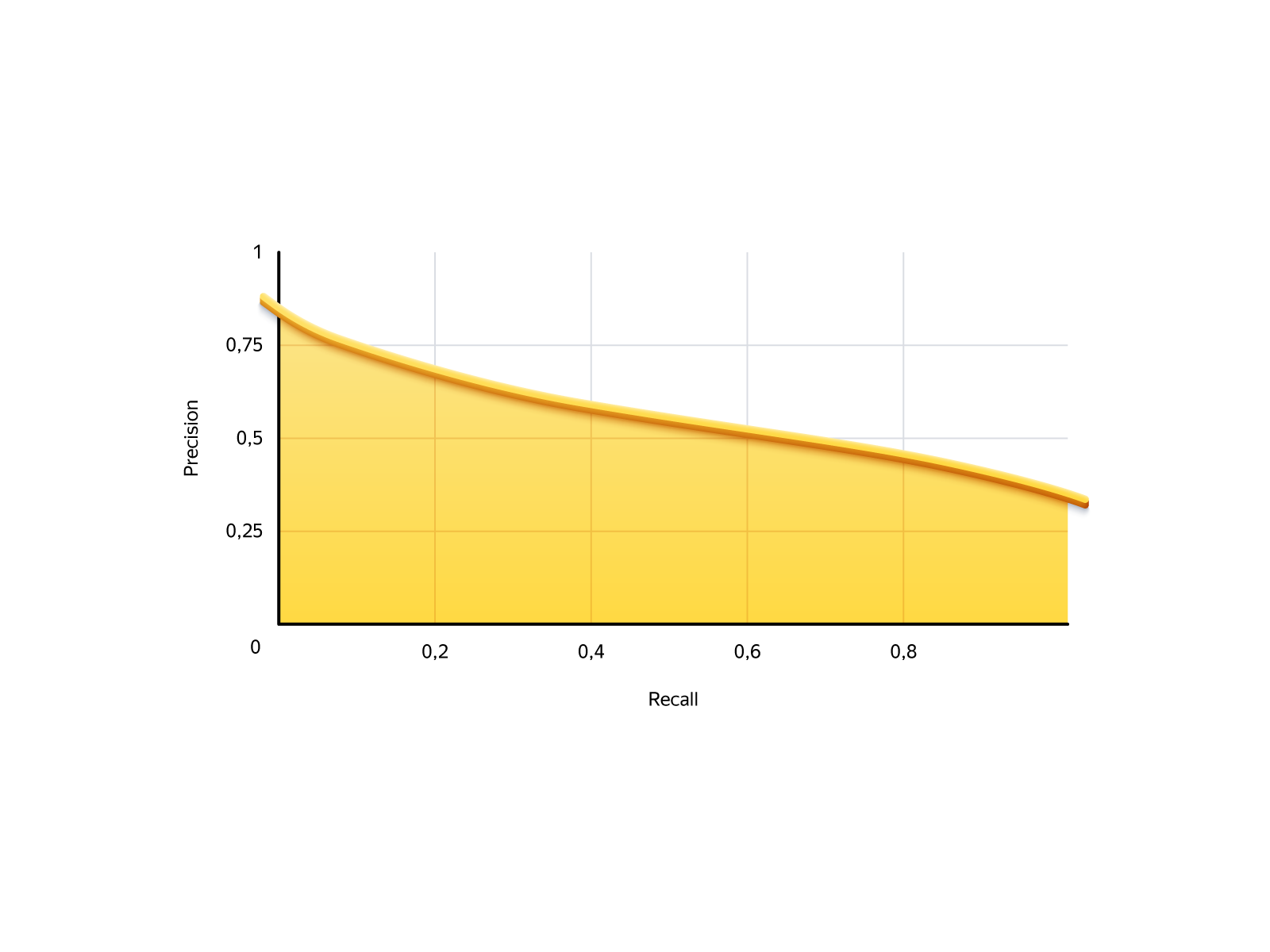
Hay dos casos extremos: no permita que nadie ordene y permita que todos ordenen. Si no permite a nadie, el retiro será 0: no creamos pedidos, pero ninguno fallará. Si permite a todos, el retiro será del 100% (recibiremos todos los pedidos posibles) y la precisión del 29%, es decir, el 71% de los pedidos resultarán ser malos.
Como signos, utilizamos varios parámetros del punto de partida:
- Hora / lugar.
- Estado del sistema (número de automóviles ocupados de todas las tarifas y pasadores en las proximidades).
- Parámetros de búsqueda (radio, número de candidatos, restricciones).
Detalles sobre los síntomas.
Conceptualmente, queremos distinguir entre dos situaciones:
- "Bosque muerto": no hay coches aquí en este momento.
- “Desafortunado”: hay automóviles, pero no hubo vehículos adecuados cuando se busca.
Un ejemplo de "desafortunado" es si hay una gran demanda en el centro el viernes por la noche. Hay muchos pedidos, hay muchos que quieren mucho, no hay suficientes conductores. Puede suceder de esta manera: no hay controladores adecuados en el pin. Pero, literalmente, aparecen en segundos, porque en este momento en este lugar hay muchos conductores y su estado cambia constantemente.
Por lo tanto, varias características del sistema en la vecindad del punto A resultaron ser buenas características:
- El número total de autos.
- El número de autos en orden.
- El número de máquinas no disponibles para ordenar en el estado "Ocupado".
- El número de usuarios.
Después de todo, cuantos más autos estén alrededor, más probable es que alguno de ellos esté disponible.
De hecho, es importante para nosotros no solo tener autos, sino también hacer viajes exitosos. Por lo tanto, fue posible predecir la probabilidad de un viaje exitoso. Pero decidimos no hacer esto, porque este valor depende en gran medida del usuario y el controlador.
CatBoost se utilizó como el algoritmo de aprendizaje modelo. Para el entrenamiento utilizamos datos obtenidos del experimento. Después de la implementación, fue necesario recopilar datos de capacitación, lo que a veces permitió que un pequeño número de usuarios hiciera un pedido contrario a la decisión del modelo.
Resumen
Los resultados del experimento resultaron ser esperados: el uso del modelo permite aumentar significativamente el número de viajes exitosos debido a pedidos sin automóviles, pero al mismo tiempo no reduce la confiabilidad.
En este momento, el mecanismo se lanza en todas las ciudades y países, y con él ocurre aproximadamente el 1% de los viajes exitosos. Además, en algunas ciudades con baja densidad de automóviles, la proporción de dichos viajes alcanza el 15%.
Otros puestos de tecnología de taxi