Los errores y el software fueron de la mano desde el comienzo de la era de la programación de computadoras. Con el tiempo, los desarrolladores han desarrollado un conjunto de prácticas para probar y depurar programas antes de su implementación, pero estas prácticas ya no son adecuadas para sistemas modernos con aprendizaje profundo. Hoy en día, la práctica principal en el campo del aprendizaje automático puede llamarse capacitación en un conjunto de datos en particular, seguida de verificación en otro conjunto. De esta manera, puede calcular la eficiencia promedio de los modelos, pero también es importante garantizar la confiabilidad, es decir, una eficiencia aceptable en el peor de los casos. En este artículo, describimos tres enfoques para identificar y eliminar errores en modelos predictivos entrenados: pruebas adversas, aprendizaje sólido y
verificación formal .
Los sistemas con MO son, por definición, no estables. Incluso los sistemas que ganan contra una persona en un área determinada pueden no ser capaces de hacer frente a la solución de problemas simples al hacer diferencias sutiles. Por ejemplo, considere el problema de perturbar imágenes: una red neuronal que puede clasificar las imágenes mejor que las personas puede fácilmente hacer creer que un perezoso es un auto de carreras, agregando una pequeña fracción de ruido cuidadosamente calculado a la imagen.
 La información competitiva cuando se superpone en una imagen normal puede confundir a la IA. Dos imágenes extremas difieren en no más de 0.0078 por cada píxel. El primero se clasifica como un perezoso, con una probabilidad del 99%. El segundo es como un auto de carreras con un 99% de probabilidad.
La información competitiva cuando se superpone en una imagen normal puede confundir a la IA. Dos imágenes extremas difieren en no más de 0.0078 por cada píxel. El primero se clasifica como un perezoso, con una probabilidad del 99%. El segundo es como un auto de carreras con un 99% de probabilidad.Este problema no es nuevo. Los programas siempre han tenido errores. Durante décadas, los programadores han estado adquiriendo una impresionante variedad de técnicas, desde pruebas unitarias hasta verificación formal. En los programas tradicionales, estos métodos funcionan bien, pero adaptar estos enfoques para pruebas rigurosas de modelos MO es extremadamente difícil debido a la escala y la falta de estructura en los modelos que pueden contener cientos de millones de parámetros. Esto sugiere la necesidad de desarrollar nuevos enfoques para garantizar la fiabilidad de los sistemas MO.
Desde el punto de vista del programador, un error es cualquier comportamiento que no cumple con la especificación, es decir, la funcionalidad planificada del sistema. Como parte de nuestra investigación de IA, estamos estudiando técnicas para evaluar si los sistemas MO cumplen los requisitos no solo en los conjuntos de entrenamiento y prueba, sino también en la lista de especificaciones que describen las propiedades deseadas del sistema. Entre estas propiedades puede haber resistencia a cambios suficientemente pequeños en los datos de entrada, restricciones de seguridad que evitan fallas catastróficas o cumplimiento de las predicciones con las leyes de la física.
En este artículo, discutiremos tres problemas técnicos importantes que enfrenta la comunidad MO al trabajar para hacer que los sistemas MO sean robustos y se ajusten de manera confiable a las especificaciones deseadas:
- Verificación efectiva del cumplimiento de las especificaciones. Estamos estudiando formas efectivas de verificar que los sistemas de MO corresponden a sus propiedades (por ejemplo, estabilidad e invariancia) que el desarrollador y los usuarios les exigen. Un enfoque para encontrar casos en los que un modelo puede alejarse de estas propiedades es buscar sistemáticamente los peores resultados de trabajo.
- Entrenamiento de modelos MO a especificaciones. Incluso si hay una cantidad suficientemente grande de datos de entrenamiento, los algoritmos MO estándar pueden producir modelos predictivos cuya operación no cumple con las especificaciones deseadas. Estamos obligados a revisar los algoritmos de entrenamiento para que no solo funcionen bien en los datos de entrenamiento, sino que también cumplan con las especificaciones deseadas.
- Prueba formal de la conformidad de los modelos MO con las especificaciones deseadas. Se deben desarrollar algoritmos para confirmar que el modelo cumple con las especificaciones deseadas para todos los datos de entrada posibles. Aunque el campo de la verificación formal ha estudiado tales algoritmos durante varias décadas, a pesar de su impresionante progreso, estos enfoques no son fáciles de escalar a los sistemas MO modernos.
Verifique el cumplimiento del modelo con las especificaciones deseadas
La resistencia a los ejemplos competitivos es un problema de defensa civil bastante bien estudiado. Una de las principales conclusiones es la importancia de evaluar las acciones de la red como resultado de fuertes ataques y el desarrollo de modelos transparentes que puedan analizarse con bastante eficacia. Nosotros, junto con otros investigadores, hemos encontrado que muchos modelos demuestran resistencia contra ejemplos débiles y competitivos. Sin embargo, proporcionan una precisión de casi 0% para ejemplos competitivos más fuertes (
Athalye et al., 2018 ,
Uesato et al., 2018 ,
Carlini y Wagner, 2017 ).
Aunque la mayor parte del trabajo se enfoca en fallas raras en el contexto de la enseñanza con un maestro (y esto es principalmente una clasificación de imágenes), existe la necesidad de expandir la aplicación de estas ideas a otras áreas. En un trabajo reciente con un enfoque competitivo para encontrar fallas catastróficas, aplicamos estas ideas a las redes de prueba entrenadas con refuerzo y diseñadas para ser utilizadas en lugares con altos requisitos de seguridad. Uno de los desafíos de desarrollar sistemas autónomos es que, dado que un error puede tener serias consecuencias, incluso una pequeña probabilidad de falla no se considera aceptable.
Nuestro objetivo es diseñar un "rival" que ayudará a reconocer dichos errores de antemano (en un entorno controlado). Si un adversario puede determinar efectivamente los peores datos de entrada para un modelo dado, esto nos permitirá detectar casos raros de fallas antes de implementarlo. Al igual que con los clasificadores de imágenes, evaluar cómo trabajar con un oponente débil te da una falsa sensación de seguridad durante el despliegue. Este enfoque es similar al desarrollo de software con la ayuda del "equipo rojo" [red-teaming - involucrando a un equipo de desarrollo de terceros que asume el rol de atacantes para detectar vulnerabilidades / aprox. transl.], sin embargo, va más allá de la búsqueda de fallas causadas por intrusos, y también incluye errores que ocurren naturalmente, por ejemplo, debido a una generalización insuficiente.
Hemos desarrollado dos enfoques complementarios para pruebas competitivas de redes de aprendizaje reforzadas. En el primero, utilizamos la optimización sin derivados para minimizar directamente la recompensa esperada. En el segundo, aprendemos una función de valor de confrontación, que en la experiencia predice en qué situaciones la red puede fallar. Luego usamos esta función aprendida para la optimización, concentrándonos en evaluar los datos de entrada más problemáticos. Estos enfoques forman solo una pequeña parte del espacio rico y creciente de algoritmos potenciales, y estamos muy interesados en el desarrollo futuro de esta área.
Ambos enfoques ya muestran mejoras significativas sobre las pruebas aleatorias. Usando nuestro método, en unos minutos es posible detectar fallas que previamente tuvieron que buscarse durante todo el día, o tal vez no se pudieron encontrar en absoluto (
Uesato et al., 2018b ). También descubrimos que las pruebas competitivas podrían revelar un comportamiento cualitativamente diferente de las redes en comparación con lo que podría esperarse de una evaluación en un conjunto de pruebas aleatorias. En particular, utilizando nuestro método, descubrimos que las redes que realizaron la tarea de orientación en un mapa tridimensional, y que generalmente hacen frente a esto a nivel humano, no pueden encontrar el objetivo en laberintos inesperadamente simples (
Ruderman et al., 2018 ). Nuestro trabajo también enfatiza la necesidad de diseñar sistemas que sean seguros contra fallas naturales, y no solo rivales.
 Al realizar pruebas en muestras aleatorias, casi nunca vemos tarjetas con una alta probabilidad de falla, pero las pruebas competitivas muestran la existencia de dichas tarjetas. La probabilidad de falla sigue siendo alta incluso después de la eliminación de muchos muros, es decir, la simplificación de los mapas en comparación con los originales.
Al realizar pruebas en muestras aleatorias, casi nunca vemos tarjetas con una alta probabilidad de falla, pero las pruebas competitivas muestran la existencia de dichas tarjetas. La probabilidad de falla sigue siendo alta incluso después de la eliminación de muchos muros, es decir, la simplificación de los mapas en comparación con los originales.Entrenamiento del modelo de especificaciones
Las pruebas competitivas intentan encontrar un contraejemplo que viole las especificaciones. A menudo, sobreestima la consistencia del modelo con estas especificaciones. Desde un punto de vista matemático, la especificación es un tipo de relación que debe mantenerse entre los datos de entrada y salida de la red. Puede tomar la forma de un límite superior e inferior o algunos parámetros clave de entrada y salida.
Inspirados por esta observación, varios investigadores (
Raghunathan et al., 2018 ;
Wong et al., 2018 ;
Mirman et al., 2018 ;
Wang et al., 2018 ), incluido nuestro equipo de DeepMind (
Dvijotham et al., 2018 ;
Gowal et al., 2018 ), trabajaron en algoritmos invariables para pruebas competitivas. Esto se puede describir geométricamente: podemos limitar (
Ehlers 2017 ,
Katz et al.2017 ,
Mirman et al., 2018 ) la peor violación de las especificaciones, limitando el espacio de datos de salida en función de un conjunto de entradas. Si este límite es diferenciable por parámetros de red y puede calcularse rápidamente, puede usarse durante el entrenamiento. Luego, el límite original puede propagarse a través de cada capa de la red.
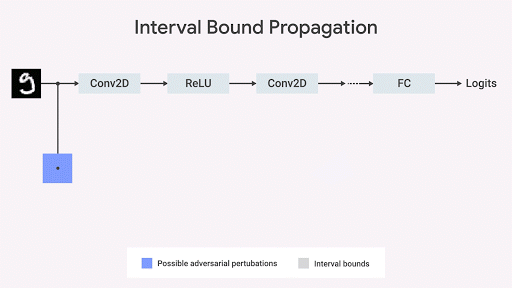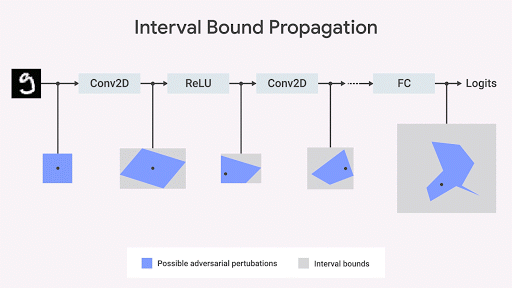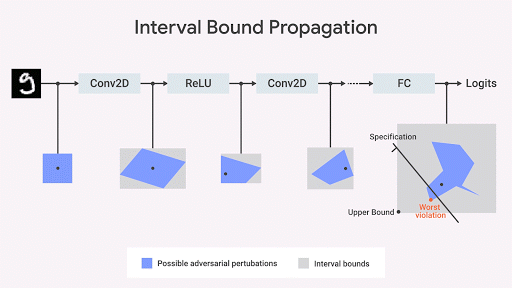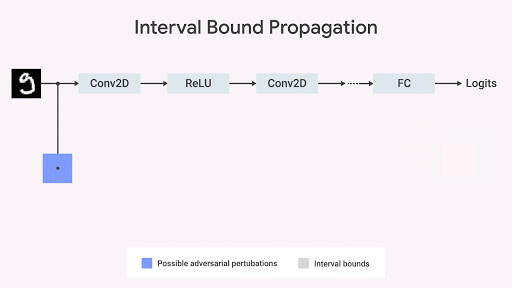
Mostramos que la extensión del límite del intervalo es rápida, eficiente y, a diferencia de lo que se pensaba anteriormente, da buenos resultados (
Gowal et al., 2018 ). En particular, mostramos que puede reducir el número de errores (es decir, el número máximo de errores que cualquier oponente puede causar) en comparación con los clasificadores de imágenes más avanzados en conjuntos de las bases de datos MNIST y CIFAR-10.
El próximo objetivo será estudiar las abstracciones geométricas correctas para calcular aproximaciones excesivas del espacio de salida. También queremos entrenar redes para que funcionen de manera confiable con especificaciones más complejas que describan el comportamiento deseado, como la invariancia y el cumplimiento de las leyes físicas mencionados anteriormente.
Verificación formal
Las pruebas y la capacitación exhaustivas pueden ser de gran ayuda para crear sistemas MO confiables. Sin embargo, las pruebas voluminosas formalmente arbitrarias no pueden garantizar que el comportamiento del sistema coincida con nuestros deseos. En modelos a gran escala, enumerar todas las opciones de salida posibles para un conjunto dado de entrada (por ejemplo, cambios menores de imagen) parece difícil de implementar debido al número astronómico de posibles cambios de imagen. Sin embargo, como en el caso de la capacitación, uno puede encontrar enfoques más efectivos para establecer restricciones geométricas en el conjunto de datos de salida. La verificación formal es el tema de una investigación en curso en DeepMind.
La comunidad MO ha desarrollado algunas ideas interesantes para calcular los límites geométricos exactos del espacio de salida de la red (Katz et al. 2017,
Weng et al., 2018 ;
Singh et al., 2018 ). Nuestro enfoque (
Dvijotham et al., 2018 ), basado en la optimización y la dualidad, consiste en formular el problema de verificación en términos de optimización, que es tratar de encontrar la mayor violación de la propiedad que se está probando. La tarea se vuelve computable si se utilizan ideas de dualidad en la optimización. Como resultado, obtenemos restricciones adicionales que especifican los límites calculados al mover el límite de intervalo [propagación de límite de intervalo] utilizando los llamados planos de corte. Este es un enfoque confiable pero incompleto: puede haber casos en que se satisfaga la propiedad que nos interesa, pero el límite calculado por este algoritmo no es lo suficientemente estricto como para que se pueda demostrar formalmente la presencia de esta propiedad. Sin embargo, después de haber recibido la frontera, obtenemos una garantía formal de la ausencia de violaciones de esta propiedad. En la fig. Debajo de este enfoque se ilustra gráficamente.

Este enfoque nos permite ampliar la aplicabilidad de los algoritmos de verificación en redes de uso más general (funciones activadoras, arquitecturas), especificaciones generales y modelos GO más complejos (modelos generativos, procesos neuronales, etc.) y especificaciones que van más allá de la confiabilidad competitiva (
Qin , 2018 ).
Perspectivas
La implementación de MO en situaciones de alto riesgo tiene sus propios desafíos y dificultades únicos, y esto requiere el desarrollo de tecnologías de evaluación que garanticen la detección de errores poco probables. Creemos que la capacitación constante sobre especificaciones puede mejorar significativamente el rendimiento en comparación con los casos en que las especificaciones surgen implícitamente de los datos de capacitación. Esperamos con interés los resultados de estudios de evaluación competitiva en curso, modelos de capacitación sólidos y verificación de especificaciones formales.
Se requerirá mucho más trabajo para que podamos crear herramientas automatizadas que garanticen que los sistemas de inteligencia artificial en el mundo real "harán todo bien". En particular, estamos muy contentos de progresar en las siguientes áreas:
- Capacitación para evaluación y verificación competitiva. Con la escala y la sofisticación de los sistemas de IA, cada vez es más difícil diseñar algoritmos competitivos de evaluación y verificación que estén suficientemente adaptados al modelo de IA. Si podemos usar todo el poder de la IA para la evaluación y verificación, este proceso puede ampliarse.
- Desarrollo de herramientas disponibles públicamente para la evaluación y verificación competitivas: es importante proporcionar a los ingenieros y otras personas que usan IA herramientas fáciles de usar que arrojen luz sobre los posibles modos de falla del sistema de IA antes de que esta falla tenga consecuencias negativas extensas. Esto requerirá cierta estandarización de evaluaciones competitivas y algoritmos de verificación.
- Expandiendo el espectro de ejemplos competitivos. Hasta ahora, gran parte del trabajo en ejemplos competitivos se ha centrado en la estabilidad de los modelos a pequeños cambios, generalmente en el área de la imagen. Esto se ha convertido en un excelente campo de pruebas para desarrollar enfoques para evaluaciones competitivas, capacitación y verificación confiables. Comenzamos a estudiar varias especificaciones para propiedades que están directamente relacionadas con el mundo real, y esperamos los resultados de futuras investigaciones en esta dirección.
- Especificaciones de entrenamiento. Las especificaciones que describen el comportamiento "correcto" de los sistemas de IA a menudo son difíciles de formular con precisión. A medida que creamos más y más sistemas inteligentes capaces de comportamientos complejos y trabajamos en un entorno no estructurado, necesitaremos aprender cómo crear sistemas que puedan usar especificaciones parcialmente formuladas y obtener especificaciones adicionales de los comentarios.
DeepMind está comprometido con el impacto positivo en la sociedad a través del desarrollo responsable y la implementación de sistemas MO. Para asegurarnos de que la contribución de los desarrolladores sea positiva, debemos enfrentar muchos obstáculos técnicos. Tenemos la intención de contribuir a esta área y estamos felices de trabajar con la comunidad para resolver estos problemas.