
RabbitMQ es un agente de mensajes escrito en lenguaje Erlang que le permite organizar un clúster de conmutación por error con replicación de datos completa en varios nodos, donde cada nodo puede manejar solicitudes de lectura y escritura. Con muchos clústeres de Kubernetes en producción, admitimos una gran cantidad de instalaciones de RabbitMQ y nos enfrentamos a la necesidad de migrar datos de un clúster a otro sin tiempo de inactividad.
Esta operación fue necesaria para nosotros en al menos dos casos:
- Transferencia de datos desde un clúster RabbitMQ que no está en Kubernetes a un nuevo clúster que ya está "desconectado" (es decir, que funciona en los pods de K8).
- Migración de RabbitMQ dentro de Kubernetes de un espacio de nombres a otro (por ejemplo, si las rutas están delimitadas por espacios de nombres, entonces para transferir la infraestructura de una ruta a otra).
La receta propuesta en el artículo se centra en situaciones (pero no limitadas a ellas) en las que hay un clúster RabbitMQ antiguo (por ejemplo, de 3 nodos), ubicado en K8 o en algunos servidores antiguos. Una aplicación alojada en Kubernetes funciona con ella (ya existe o en el futuro):

... y nos enfrentamos al desafío de migrarlo a una nueva producción en Kubernetes.
Primero, se describirá un enfoque general de la migración en sí y, después, detalles técnicos sobre su implementación.
Algoritmo de migración
El primer paso preliminar antes de cualquier acción es verificar que el modo de alta disponibilidad (
HA ) esté habilitado en la antigua instalación de RabbitMQ. La razón es obvia: no queremos perder ningún dato. Para llevar a cabo esta verificación, puede ir al panel de administración de RabbitMQ y en la pestaña Admin → Políticas asegúrese de que el valor
ha-mode: all :

El siguiente paso es generar un nuevo clúster RabbitMQ en los pods de Kubernetes (en nuestro caso, por ejemplo, que consta de 3 nodos, pero su número puede ser diferente).
Después de eso, fusionamos los viejos y nuevos clústeres RabbitMQ, obteniendo un solo clúster (de 6 nodos):
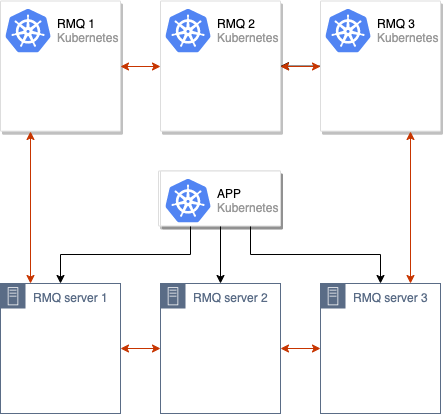
Se inicia el proceso de sincronización de datos entre los clústeres RabbitMQ antiguos y nuevos. Después de que todos los datos estén sincronizados entre todos los nodos en el clúster, podemos cambiar la aplicación para usar el nuevo clúster:
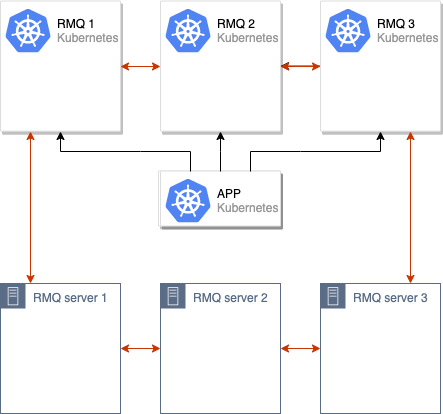
Después de estas operaciones, es suficiente eliminar los nodos antiguos del clúster RabbitMQ, y el movimiento puede considerarse completado:

Hemos utilizado repetidamente este esquema en nuestra producción. Sin embargo, para su propia conveniencia, lo implementamos dentro del marco de un sistema especializado que distribuye configuraciones típicas de RMQ en conjuntos de clústeres de Kubernetes
(para aquellos que tienen curiosidad: estamos hablando de addon-operator , del que hablamos recientemente ) . A continuación se presentan instrucciones individuales que cualquiera puede aplicar en sus instalaciones para probar la solución propuesta en acción.
Lo intentamos en la práctica
Requisitos
Los detalles son muy simples:
- Clúster de Kubernetes (minikube también es adecuado);
- RabbitMQ cluster (puede implementarse en metal desnudo y hacerse como un cluster regular en Kubernetes desde la tabla oficial de Helm).
Para el ejemplo descrito a continuación, implementé RMQ en Kubernetes y lo
rmq-old .
Preparación del stand
1. Descargue el gráfico Helm y edítelo un poco:
helm fetch --untar stable/rabbitmq-ha
Para mayor comodidad, establecemos una contraseña,
ErlangCookie y establecemos la política
ha-all para que, de forma predeterminada, las colas se sincronicen entre todos los nodos del clúster RMQ:
rabbitmqPassword: guest rabbitmqErlangCookie: mae9joopaol7aiVu3eechei2waiGa2we definitions: policies: |- { "name": "ha-all", "pattern": ".*", "vhost": "/", "definition": { "ha-mode": "all", "ha-sync-mode": "automatic", "ha-sync-batch-size": 81920 } }
2. Establecer el gráfico:
helm install . --name rmq-old --namespace rmq-old
3. Vaya al panel de administración de RabbitMQ, cree una nueva cola y agregue algunos mensajes. Serán necesarios para que después de la migración podamos asegurarnos de que todos los datos se hayan guardado y que no hayamos perdido nada:

El banco de pruebas está listo: tenemos el RabbitMQ "antiguo" con los datos que deben transferirse.
RabbitMQ Cluster Migration
1. Primero, implemente el nuevo RabbitMQ en un espacio de nombres
diferente con
la misma ErlangCookie y contraseña para el usuario. Para hacer esto, realizamos las operaciones descritas anteriormente, cambiando el comando final de instalación de RMQ a lo siguiente:
helm install . --name rmq-new --namespace rmq-new
2. Ahora necesita fusionar el nuevo clúster con el anterior. Para hacer esto, vaya a cada uno de los pods del
nuevo RabbitMQ y ejecute los comandos:
export OLD_RMQ=rabbit@rmq-old-rabbitmq-ha-0.rmq-old-rabbitmq-ha-discovery.rmq-old.svc.cluster.local && \ rabbitmqctl stop_app && \ rabbitmqctl join_cluster $OLD_RMQ && \ rabbitmqctl start_app
La variable
OLD_RMQ dirección de uno de los nodos del
antiguo clúster RMQ.
Estos comandos detendrán el nodo actual del
nuevo clúster RMQ, lo conectarán al clúster anterior y lo reiniciarán.
3. El clúster RMQ de 6 nodos está listo:

Debe esperar hasta que los mensajes estén sincronizados entre todos los nodos. Es fácil adivinar que el tiempo de sincronización de los mensajes depende de las capacidades de la plancha en la que se implementa el clúster y de la cantidad de mensajes. En el escenario descrito, solo hay 10 de ellos, por lo que los datos se sincronizaron instantáneamente, pero con un número suficientemente grande de mensajes, la sincronización puede llevar horas.
Entonces, el estado de sincronización:

Aquí,
+5 significa que los mensajes
ya están en
otros 5 nodos (excepto por lo que se especifica en el campo
Node ). Por lo tanto, la sincronización fue exitosa.
4. Solo queda cambiar la dirección de RMQ en la aplicación al nuevo clúster (las acciones específicas aquí dependen de la pila de tecnología que esté utilizando y otros detalles de la aplicación), después de lo cual puede despedirse del anterior.
Para la última operación (es decir,
después de cambiar la aplicación a un nuevo clúster), vamos a cada nodo del clúster anterior y ejecutamos los comandos:
rabbitmqctl stop_app rabbitmqctl reset
El clúster "olvidó" los nodos antiguos: puede eliminar el antiguo RMQ, que completará el movimiento.
Nota : Si usa RMQ con certificados, básicamente nada cambia: el proceso de traslado se realizará exactamente igual.Conclusiones
El esquema descrito es adecuado para casi todos los casos en los que necesitamos transferir RabbitMQ o simplemente pasar a un nuevo clúster.
En nuestro caso, las dificultades ocurrieron solo una vez cuando se accedió a RMQ desde muchos lugares, y no tuvimos la oportunidad de cambiar la dirección de RMQ a una nueva en todas partes. Luego lanzamos un nuevo RMQ en el mismo espacio de nombres con las mismas etiquetas, de modo que quedaba incluido en los servicios e Ingreso existentes, y cuando comenzamos el pod, manipulamos las etiquetas con nuestras manos, eliminándolas al principio, para que las solicitudes no cayeran en un RMQ vacío, y agregarlos nuevamente después de la sincronización de mensajes.
Utilizamos la misma estrategia al actualizar RabbitMQ a una nueva versión con una configuración modificada: todo funcionaba como un reloj.
PS
Como continuación lógica de este material, estamos preparando artículos sobre MongoDB (migración de un servidor de hierro a Kubernetes) y MySQL (una de las opciones para "preparar" este DBMS dentro de Kubernetes). Serán publicados en los próximos meses.
PPS
Lea también en nuestro blog: