Automatización fundamental de bloques de construcción - Pruebas
Rod Johnson

No soy un embajador para probar interfaces web, pero es más probable que este ensayo sea útil para los camaradas que ya tienen experiencia en este campo.
También será útil para principiantes, como Proporciono el código fuente donde puede ver cómo se organiza la interacción con el selenio en el producto final.
Hablaré sobre cómo, desde cero, con poca experiencia en desarrollo, escribí una plataforma para ejecutar pruebas y sobre la plataforma misma. Yo mismo creo que mi producto resultó ser muy efectivo, lo que significa que será útil para muchos y tiene un lugar para su consideración.
Del concepto
El proceso de prueba depende del sistema de información.
Para recordar mi concepto, es necesario comprender en qué sistemas me enfoco en primer lugar; esos son sistemas en los que generalmente hay procesos comerciales lineales específicos que se establecen como la clave al realizar pruebas de regresión.
Entonces, un sistema como srm. Una entidad comercial clave son las ofertas de los proveedores. La consideración clave al realizar pruebas de regresión es la integridad del proceso de negocio.
El proceso comercial comienza desde el registro del proveedor en el sistema, luego continúa la creación de la propuesta comercial: pasa a la etapa de consideración, que es realizada por varios tipos de usuarios internos (y cada usuario tiene una interfaz única) hasta que se devuelve la decisión sobre la consideración de la propuesta al proveedor.
Resulta que pasamos por una serie de interfaces diferentes, y casi siempre trabajamos con diferentes. De hecho, si solo lo mira directamente, parece como ver una cinta de video, es decir Este es un proceso que tiene un principio y un final, y es absolutamente lineal: sin ramificaciones, al escribir una prueba, siempre conocemos el resultado esperado. Es decir Quiero decir que ya mirando esta imagen, podemos concluir que hacer pruebas polimórficas es poco probable que tenga éxito. En vista de esto, al crear una plataforma para ejecutar pruebas, el factor clave que establezco es la velocidad de escritura de las pruebas.
Los conceptos que establecí para mí:- La prueba automática debe crearse lo más rápido posible. Si logra esto cualitativamente, entonces otros aspectos, como la confiabilidad y la facilidad de uso, deberían surgir por sí mismos.
- Las pruebas deben declararse declarativamente y vivir por separado del código. Ni siquiera vi otra opción. Esto aumenta la velocidad de escritura, ya que si tiene un intérprete listo para usar, nuestra plataforma, no necesita agregar nada más tarde, no tiene que ingresar al código una vez más; en general, puede olvidarse de la plataforma terminada utilizando el IDE. Entonces las pruebas son más fáciles de mantener. De esta forma, son más fáciles de aprender a escribir, porque no se necesitan habilidades de desarrollo, sino solo una comprensión del lenguaje de marcado. De esta forma, son comprensibles para todos los participantes en el proceso.
Lo que decidí rechazar al principio:
- NO envuelva su sistema en un marco de prueba. Puede comenzar la ejecución de un proceso sin un marco de prueba. "¡Quieres inventar una bicicleta!", Dirán muchos. Pienso diferente Los marcos de prueba usados populares se crearon principalmente para probar el código desde adentro, y vamos a probar la parte externa del sistema desde afuera. Es como si tuviera una bicicleta de carretera, y necesito bajar la montaña fuera de la carretera (grosero, pero el tren del pensamiento refleja). En general, escribiremos el marco nosotros mismos, con blackjack y ... (aunque soy consciente de que, por ejemplo, JUnit 5 ya está mucho más adaptado para tales tareas).
- Negativa a usar envoltorios para el selenio. En realidad, la biblioteca de claves en sí es pequeña. Para comprender que necesita usar el 5 por ciento de su funcionalidad, mientras lo palea por completo, tomará varias horas. Deja de buscar en todas partes una forma de escribir menos código y acostumbrarte al orinal. En el mundo moderno, este deseo a menudo conduce a lo absurdo y casi siempre causa daño a la flexibilidad (me refiero a los enfoques para "escribir menos código" y no los casos de marcos arquitectónicos).
- Hermosa presentación de los resultados no es necesaria. Introdujo este artículo, porque Ni una vez me enfrento a esto. Cuando se completa la prueba automática, necesito saber 2 cosas: el resultado general (positivo / negativo) y si hubo un error, dónde exactamente. Quizás todavía necesite mantener estadísticas. Todo lo demás en términos de resultados es ABSOLUTAMENTE no esencial. Considerar un diseño hermoso como una ventaja significativa, o dedicar tiempo a este hermoso diseño en las etapas iniciales, son alardes superfluos.
Hablaré un poco más sobre el nivel de desarrollo en la empresa y las condiciones para crear la herramienta con el fin de aclarar completamente algunos detalles.
Debido a algunas circunstancias confidenciales, no divulgo la compañía donde trabajo.
En nuestra empresa, el desarrollo ya existe desde hace muchos años y, por lo tanto, todos los procesos se han establecido desde hace mucho tiempo. Sin embargo, están muy por detrás de las tendencias actuales.
Todos los representantes de TI entienden que debe cubrir el código con pruebas, escribir scripts para las pruebas automáticas al momento de coordinar los requisitos para la funcionalidad futura, las tecnologías flexibles ahorran significativamente tiempo y recursos, y CI que simplemente toma y simplifica la vida. Pero todo esto hasta ahora solo nos llega lentamente ...
También lo es el servicio de control de calidad del software: todas las pruebas se realizan manualmente, si observa el proceso "desde arriba", este es el "cuello de botella" de todo el proceso de desarrollo.
Descripción de montaje
La plataforma está escrita en Java usando JDK 12
Herramientas clave de infraestructura - Selenium Web Driver, OJDBC
Para que la aplicación funcione, el navegador FireFox versión 52 debe estar instalado en la PC
Aplicación Build Composition
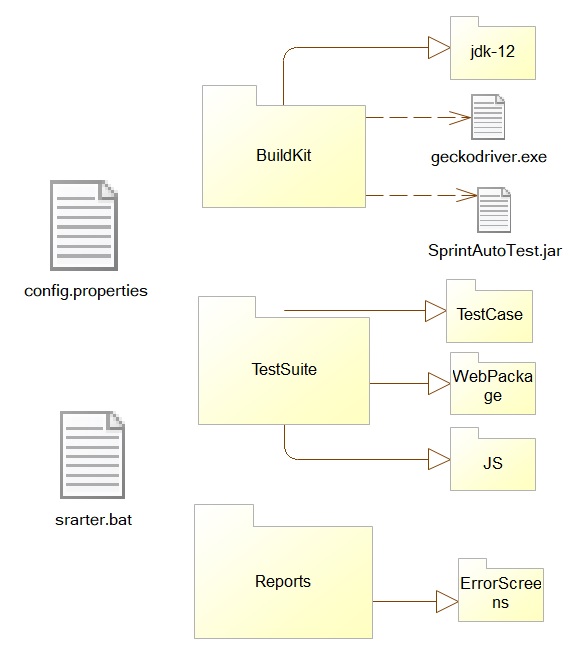
Con la aplicación, se requieren 3 carpetas y 2 archivos:
• Carpeta
BuildKit : contiene:
- jdk12, a través del cual se inicia la aplicación (JVM);
- geckodriver.exe: para que Selenium Web Driver funcione con el navegador FireFox;
- SprintAutoTest.jar: directamente la instancia de la aplicación
• Carpeta de informes: los informes se guardan después de que la aplicación completa el caso de prueba. También debe contener la carpeta ErrorScreens, donde se guarda la captura de pantalla en caso de error
• Carpeta
TestSuite : paquetes web, javascripts, un conjunto de casos de prueba (llenar esta carpeta se discutirá en detalle por separado)
• archivo config.properties: contiene una configuración para conectarse a una base de datos Oracle y valores de expectativas explícitas para WebDriverWait
• starter.bat: archivo para iniciar la aplicación (es posible iniciar automáticamente la aplicación sin especificar manualmente TestCase si ingresa el nombre TestCase como parámetro al final).
Breve descripción de la aplicación.
La aplicación se puede iniciar con el parámetro (nombre TestCase) o sin él; en este caso, debe ingresar el nombre del caso de prueba en la consola usted mismo.
Un ejemplo del contenido general de un archivo bat para ejecutar sin un parámetro : inicie "AutoTest launcher"% cd% \ BuildKit \ jdk-12 \ bin \ java.exe -Xmx768M -jar --enable-preview% cd% \ BuildKit \ SprintAutoTest.jarEn el lanzamiento general de la aplicación, analiza los archivos xml ubicados en el directorio "\ TestSuite \ TestCase" (sin ver el contenido de las subcarpetas). En este caso, se produce la validación primaria de los archivos xml para la corrección de la estructura (es decir, todas las etiquetas desde el punto de vista del marcado xml se especifican correctamente), y se toman los nombres indicados en la etiqueta "testCaseName", después de lo cual se solicita al usuario que ingrese uno de los nombres posibles para la prueba disponible casos. En caso de una entrada errónea, el sistema le pedirá que ingrese el nombre nuevamente.
Después de recibir el nombre TestCase, se construye el modelo interno, que es un conjunto de TestCase (script de prueba) - WebPackage (almacenamiento de elementos) en forma de objetos java. Después de construir el modelo, TestCase (el objeto ejecutable del programa) se construye directamente. En la etapa de construcción de TestCase, la validación secundaria también tiene lugar: se verifica que todos los formularios especificados en TestCase estén en el WebPackage asociado y que todos los elementos especificados en acción estén en el WebPackage dentro de las páginas especificadas. (La estructura de TestCase y WebPackage se describe en detalle a continuación)
Después de que se crea TestCase, el script se ejecuta directamente
Algoritmo de operación de script (lógica de teclas)
TestCase es una colección de entidades Action, que a su vez es una colección de entidades Event.
Testcase
-> Lista {Acción}
-> Lista {Evento}Cuando se inicia TestCase, la acción se inicia secuencialmente (cada acción devuelve un resultado lógico)
Cuando comienza la acción, el evento comienza secuencialmente (cada evento devuelve un resultado lógico)
El resultado de cada evento se guarda.
En consecuencia, la prueba se completa cuando todas las acciones se completaron con éxito o si la Acción devuelve falso.
* Mecanismo de bloqueo
Porque mi sistema de prueba es antiguo y ha detectado errores / errores que no son errores, y algunos eventos no funcionan la primera vez, la plataforma tiene un mecanismo que puede apartarse del concepto anterior de una prueba estrictamente lineal (sin embargo, está fuertemente tipado). Al detectar tales errores, es posible repetir los casos primero y realizar acciones adicionales para poder repetir accionesAl final de la aplicación, se genera un informe, que se guarda en el directorio "\ Informes". En caso de error, se toma una captura de pantalla que se guarda en "\ Reports \ ErrorScreens"
TestSuite Filling
Entonces, la descripción de la prueba. Como ya se mencionó, el parámetro principal que se necesita para ejecutar es el nombre de la prueba que se ejecutará. Este nombre se almacena en el archivo xml en el directorio "/ TestSuite / TestCase". Todos los scripts de prueba se almacenan en este directorio. Puede haber cualquier número de ellos. El nombre del caso de prueba no se toma del nombre del archivo, sino de la etiqueta "testCaseName" dentro del archivo.
TestCase establece qué se hará exactamente, es decir, acción En el directorio "/ TestSuite / WebPackage" en los archivos xml se almacenan todos los localizadores. Es decir todo en las mejores tradiciones: las acciones se almacenan por separado, los localizadores de formularios web por separado.
TestCase también almacena el nombre de WebPackage en la etiqueta "webPackageName".
La imagen total ya está allí. Para ejecutar, debe tener 2 archivos xml: TestCase y WebPackage. Ellos hacen un montón. WebPackage es independiente: el identificador es el nombre en la etiqueta "webPackageName". En consecuencia, aquí está la primera regla: los nombres TestCase y WebPackage deben ser únicos. Es decir una vez más, de hecho, nuestra prueba es un montón de archivos TestCase y WepPackage, que están conectados por el nombre WebPackage, que se especifica en TestCase. En la práctica, automatizo un sistema y entretejo todos mis casos de prueba a un WebPackage en el que tengo un montón de descripciones de todas las formas.
La siguiente capa de descomposición lógica se basa en un patrón como el Objeto de página.
Objeto de páginaPage Object es una de las soluciones arquitectónicas más útiles y utilizadas en automatización. Este patrón de diseño ayuda a encapsular el trabajo con elementos de página individuales. Page Object, por así decirlo, simula las páginas de la aplicación bajo prueba como objetos.
Separación de lógica e implementación.
Hay una gran diferencia entre la lógica de prueba (qué verificar) y su implementación (cómo verificar). Un ejemplo de un escenario de prueba: "El usuario ingresa un nombre de usuario o contraseña incorrectos, presiona el botón de inicio de sesión y recibe un mensaje de error". Este escenario describe la lógica de la prueba, mientras que la implementación contiene acciones tales como buscar campos de entrada en la página, completarlos, verificar errores, etc. Y si, por ejemplo, el método de mostrar el mensaje de error cambia, esto no afectará el script de prueba, también deberá ingresar datos incorrectos, presionar el botón de inicio de sesión y verificar el error. Pero esto afectará directamente la implementación de la prueba: será necesario cambiar el método que recibe y procesa el mensaje de error. Al separar la lógica de la prueba de su implementación, las pruebas automáticas se vuelven más flexibles y, por regla general, más fáciles de mantener.
*! No se puede decir que este enfoque arquitectónico se haya aplicado completamente. Es solo una cuestión de descomponer la descripción del escenario de prueba página por página, lo que ayuda a escribir pruebas más rápido y agregar autocomprobaciones adicionales en todas las páginas, estimula la descripción correcta de los localizadores (para que no sean los mismos en páginas diferentes) y construye una estructura lógica "hermosa" de la prueba. La plataforma en sí se implementa según los principios de "Arquitectura limpia"
A continuación, intentaré no detallar la estructura de WebPackage y TestCase. Para ellos, creé un esquema DTD para WebPackage y XSD 1.1 para TestCase.
! IMPORTANTE
Al mantener los esquemas DTD y XSD, se implementa el concepto de escritura de prueba rápida.
Al escribir WebPackage y TestCase directamente, debe usar el editor xml con funciones de validación DTD y XSD incorporadas en tiempo real con generación automática de etiquetas, lo que hará que el proceso de escribir una prueba automática sea en gran medida automatizado (todas las etiquetas necesarias se sustituirán automáticamente, se mostrarán listas desplegables para los valores de los atributos posibles valores, según el tipo de evento se generarán etiquetas correspondientes) .
Cuando estos esquemas se "atornillan" al archivo xml en sí mismo, entonces puede olvidarse de la corrección de la estructura del archivo xml, si utiliza un entorno especial. Mi elección recayó en oXygen XLM Editor. Una vez más, sin usar dicho programa, no comprenderá la esencia de la velocidad de escritura. La idea no es muy adecuada para esto. no maneja la construcción "alternativa" XSD 1.1, que es clave para TestCase.
Paquete web
WebPackaege: un archivo xml que describe los elementos de los formularios web, ubicados en el directorio "\ TestSuite \ WebPackage". (puede haber tantos archivos como desee. El nombre de los archivos puede ser cualquier cosa, solo importa el contenido).
DTD (insertado al principio del documento):<!DOCTYPE webPackage [ <!ELEMENT webPackage (webPackageName, forms)> <!ELEMENT webPackageName (#PCDATA)> <!ELEMENT forms (form+)> <!ELEMENT form (formName, elements+)> <!ELEMENT formName (#PCDATA)> <!ELEMENT elements (element+)> <!ELEMENT element (name, locator)> <!ATTLIST element type (0|1|2|3|4|5|6|7) #REQUIRED> <!ATTLIST element alwaysVisible (0|1) #IMPLIED> <!ELEMENT name (#PCDATA)> <!ELEMENT locator (#PCDATA)> <!ATTLIST locator type (1|2) #IMPLIED> ]>
En general, se ve aproximadamente <webPackage> <webPackageName>_</webPackageName> <forms> <form> <formName>______</formName> <elements> <element type="2" alwaysVisible="1"> <name>_</name> <locator type="2">.//div/form/div/div/form/table/tbody/tr/td[text()=""]/following-sibling::td/input</locator> </element> <element type="2"> <name>__</name> <locator>.//div/form/div/div/form/table/tbody/tr/td[text()=""]/following-sibling::td/input</locator> </element> ....... </elements> </form> ....... </forms> </webPackage>
Como ya se mencionó, para que los elementos no estén en un montón: todo se descompone de acuerdo con los formularios web
La entidad clave es
<element>
La etiqueta del elemento tiene 2 atributos:
El atributo
type es obligatorio y especifica el tipo de elemento. En la plataforma, establezca el tipo de byte
Por el momento, específicamente para mí en la plataforma, he implementado los siguientes tipos:
• 0: no tiene un significado funcional, generalmente algún tipo de inscripción
• 1 - botón (botón)
• 2 - campo de entrada
• 3 - casilla de verificación (casilla de verificación)
• 4: lista desplegable (seleccionar): no se implementó realmente, pero dejó un lugar para ello
• 5 - para la lista desplegable de srm: escriba el nombre, espere a que aparezca el valor - seleccione de acuerdo con la plantilla específica de xpath - el tipo específicamente para mi sistema
• 6: selección de srm: se utiliza en funciones típicas como búsqueda, etc. - escriba específicamente para mi sistema
El atributo
AlwaysVisible , opcional, muestra si un elemento siempre está presente en el formulario, se puede usar durante la validación inicial / final de la acción (es decir, en modo automático, puede verificar que cuando abre el formulario, contiene todos los elementos que siempre están en él, al cerrar formas, todos estos elementos han desaparecido)
Posibles valores:
- 0 - por defecto (o si el atributo no está configurado) - el elemento puede no estar en la página (no validar)
- 1 - el elemento siempre está presente en la página
Se implementa un atributo de
tipo opcional opcional con la etiqueta de localización
Posibles valores:
- 1 - busca un elemento por id (respectivamente, especifica solo id en el localizador)
- 2 - por defecto (o si el atributo no está configurado) - buscar en xpath - se recomienda usar solo la búsqueda en xpath, porque Este método combina casi todas las ventajas del resto y es universal
Testcase
TestCase: un archivo xml que describe directamente el script de prueba se encuentra en el directorio "\ TestSuite \ TestCase" (puede haber tantos archivos como desee. El nombre de los archivos puede ser cualquiera, solo el contenido es importante).
Circuito XSD: <xs:schema elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema" version="1.1"> <xs:element name="testCase"> <xs:complexType> <xs:sequence> <xs:element name="testCaseName" type="xs:string"/> <xs:element name="webPackageName" type="xs:string"/> <xs:element name="actions" type="actionsType"/> </xs:sequence> </xs:complexType> </xs:element> <xs:complexType name="actionsType"> <xs:sequence> <xs:element name="action" type="actionType" maxOccurs="unbounded"/> </xs:sequence> </xs:complexType> <xs:complexType name="actionType"> <xs:sequence> <xs:element name="name" type="xs:string"/> <xs:element name="orderNumber" type="xs:positiveInteger"/> <xs:element name="runConfiguration" type="runConfigurationType"/> </xs:sequence> </xs:complexType> <xs:complexType name="runConfigurationType"> <xs:sequence> <xs:element name="formName" type="xs:string"/> <xs:element name="repeatsOnError" type="xs:positiveInteger" minOccurs="0"/> <xs:element name="events" type="eventsType"/> <xs:element name="exceptionBlock" type="eventsType" minOccurs="0"/> </xs:sequence> <xs:attribute name="openValidation" use="required"> <xs:simpleType> <xs:restriction base="xs:byte"> <xs:enumeration value="1"/> <xs:enumeration value="0"/> </xs:restriction> </xs:simpleType> </xs:attribute> <xs:attribute name="closeValidation" use="required"> <xs:simpleType> <xs:restriction base="xs:byte"> <xs:enumeration value="1"/> <xs:enumeration value="0"/> </xs:restriction> </xs:simpleType> </xs:attribute> </xs:complexType> <xs:complexType name="eventBaseType"> <xs:sequence> <xs:element name="orderNumber" type="xs:positiveInteger"/> </xs:sequence> <xs:attribute name="type" use="required"> <xs:simpleType> <xs:restriction base="xs:string"> <xs:enumeration value="goToURL"/> <xs:enumeration value="checkElementsVisibility"/> <xs:enumeration value="checkElementsInVisibility"/> <xs:enumeration value="fillingFields"/> <xs:enumeration value="clickElement"/> <xs:enumeration value="dbUpdate"/> <xs:enumeration value="wait"/> <xs:enumeration value="scrollDown"/> <xs:enumeration value="userInput"/> <xs:enumeration value="checkInputValues"/> <xs:enumeration value="checkQueryResultWithUtilityValue"/> <xs:enumeration value="checkFieldsPresenceByQueryResult"/> </xs:restriction> </xs:simpleType> </xs:attribute> <xs:attribute name="invertResult" use="optional" default="0"> <xs:simpleType> <xs:restriction base="xs:byte"> <xs:enumeration value="1"/> <xs:enumeration value="0"/> </xs:restriction> </xs:simpleType> </xs:attribute> <xs:attribute name="hasExceptionBlock" use="optional" default="0"> <xs:simpleType> <xs:restriction base="xs:byte"> <xs:enumeration value="1"/> <xs:enumeration value="0"/> </xs:restriction> </xs:simpleType> </xs:attribute> </xs:complexType> <xs:complexType name="eventsType"> <xs:sequence> <xs:element name="event" type="eventBaseType" maxOccurs="unbounded"> <xs:alternative test="@type='goToURL'" type="eventGoToURL"/> <xs:alternative test="@type='checkElementsVisibility'" type="eventCheckElementsVisibility"/> <xs:alternative test="@type='checkElementsInVisibility'" type="eventCheckElementsVisibility"/> <xs:alternative test="@type='fillingFields'" type="eventFillingFields"/> <xs:alternative test="@type='checkInputValues'" type="eventFillingFields"/> <xs:alternative test="@type='clickElement'" type="eventClickElement"/> <xs:alternative test="@TYPE='dbUpdate'" type="eventRequest"/> <xs:alternative test="@type='wait'" type="utilityValueInteger"/> <xs:alternative test="@type='scrollDown'" type="eventClickElement"/> <xs:alternative test="@type='userInput'" type="eventClickElement"/> <xs:alternative test="@type='checkQueryResultWithUtilityValue'" type="eventRequestWithValue"/> <xs:alternative test="@type='checkFieldsPresenceByQueryResult'" type="eventRequestWithValue"/> </xs:element> </xs:sequence> </xs:complexType> <xs:complexType name="eventGoToURL"> <xs:complexContent> <xs:extension base="eventBaseType"> <xs:sequence> <xs:element name="url" type="xs:anyURI"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> <xs:complexType name="eventCheckElementsVisibility"> <xs:complexContent> <xs:extension base="eventBaseType"> <xs:sequence> <xs:element name="fields" type="fieldType"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> <xs:complexType name="eventFillingFields"> <xs:complexContent> <xs:extension base="eventBaseType"> <xs:sequence> <xs:element name="fields" type="fieldTypeWithValue"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> <xs:complexType name="eventClickElement"> <xs:complexContent> <xs:extension base="eventBaseType"> <xs:sequence> <xs:element name="elementName" type="xs:string"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> <xs:complexType name="eventRequest"> <xs:complexContent> <xs:extension base="eventBaseType"> <xs:sequence> <xs:element name="dbRequest" type="xs:string"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> <xs:complexType name="utilityValueInteger"> <xs:complexContent> <xs:extension base="eventBaseType"> <xs:sequence> <xs:element name="utilityValue" type="xs:positiveInteger"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> <xs:complexType name="eventRequestWithValue"> <xs:complexContent> <xs:extension base="eventBaseType"> <xs:sequence> <xs:element name="dbRequest" type="xs:string"/> <xs:element name="utilityValue" type="xs:string"/> </xs:sequence> </xs:extension> </xs:complexContent> </xs:complexType> <xs:complexType name="fieldType"> <xs:sequence> <xs:element name="field" maxOccurs="unbounded"> <xs:complexType> <xs:choice> <xs:element name="element" type="xs:string"/> <xs:element name="xpath" type="xs:string"/> </xs:choice> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> <xs:complexType name="fieldTypeWithValue"> <xs:sequence> <xs:element name="field" maxOccurs="unbounded"> <xs:complexType> <xs:sequence> <xs:element name="element" type="xs:string"/> <xs:element name="value" type="valueType"/> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> <xs:complexType name="valueType"> <xs:complexContent> <xs:extension base="xs:anyType"> <xs:attribute name="type" use="optional" default="1"> <xs:simpleType> <xs:restriction base="xs:byte"> <xs:enumeration value="1"/> <xs:enumeration value="2"/> <xs:enumeration value="3"/> </xs:restriction> </xs:simpleType> </xs:attribute> </xs:extension> </xs:complexContent> </xs:complexType> </xs:schema>
Vista general: <!DOCTYPE testCase SYSTEM "./TestSuite/TestCase/entities.dtd" []> <testCase xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="testShema.xsd"> <testCaseName>__testCase</testCaseName> <webPackageName>_webPackage__webPackageName</webPackageName> <actions> <action> <name> </name> <orderNumber>10</orderNumber> <runConfiguration openValidation="1" closeValidation="1"> <formName>______</formName> <events> <event type="goToURL"> <orderNumber>10</orderNumber> <url>&srmURL;</url> </event> ....... </events> </runConfiguration> </action> ....... </actions> </testCase>
Aquí, en esta línea, puede ver cómo ajustar el esquema xsd para que el Editor XML lo vea:
<testCase xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="testShema.xsd">
En TestCase, también utilizo entidades DTD que se almacenan por separado en el mismo directorio: un archivo con la extensión .dtd. En él, almaceno casi todos los datos - constantes. También construí la lógica de tal manera que para lanzar una nueva prueba, y durante toda la prueba, se crearon nuevas entidades únicas, se registró una nueva nave espacial, fue suficiente para cambiar 1 dígito en este archivo.
Su estructura es muy simple. Daré un ejemplo: <?xml version="1.0" encoding="UTF-8"?> <!ENTITY mainNumber '040'> <!ENTITY mail '@mail.ru'> <!ENTITY srmURL 'https://srm-test.ru'>
Dichas constantes se insertan en el valor de la etiqueta de la siguiente manera:
<url>&srmURL;</url>
- Se puede combinar.
! Recomendación : al escribir testCase, debe especificar estas entidades DTD dentro del documento y, después de que todo haya funcionado de manera estable, transferirlo a un archivo separado. Mi editor xml tiene dificultades con esto: no puede encontrar DTD y no tiene en cuenta XSD, por lo que recomiendo esto
testCasetestCase: la etiqueta principal contiene:
- testCaseName : el nombre de nuestro caso de prueba, este parámetro se pasa a la entrada de la aplicación
- webPackageName : el nombre de WebPackage, que se especifica en webPackageName (consulte el párrafo anterior en WebPackage)
- acciones - contenedor de entidad de acción
acciónContiene:
- nombre - nombre - se recomienda especificar el nombre del formulario y las acciones clave - qué y por qué
- orderNumber - número de serie - parámetro necesario para la acción de clasificación (introducido debido al hecho de que al analizar xml en Java utilizando ciertas herramientas, el análisis se puede realizar en un entorno de subprocesos múltiples, por lo que el orden puede continuar) - al especificar la siguiente acción, puede saltar - es decir al ordenar, solo importa "más / menos", por lo que es posible llevar a cabo acciones entre los ya descritos sin la necesidad de cambiar la numeración completa
- runConfiguration : la descripción real de lo que sucederá como parte de la acción
runConfigurationContiene:
- Atributo openValidation : opcional, el valor predeterminado es "0"
- 0: no realizar la validación inicial del formulario
- 1 - validación inicial del formulario
- atributo closeValidation : opcional, el valor predeterminado es "0"
- 0 - no realizar la validación final del formulario
- 1 - validación final del formulario
- formName : el nombre del formulario dentro del cual se realizarán las acciones: el valor formName de WebPackage
- repeatsOnError : opcional, indica cuántas repeticiones se deben realizar en caso de falla
- eventos - contenedor de entidad de evento
- exceptionBlock - opcional - un contenedor de entidades de eventos que se ejecutan en caso de error
acontecimientoUnidad estructural mínima: esta entidad muestra qué acciones se realizan
Cada evento es especial, puede tener etiquetas y atributos únicos.
El tipo base contiene:
- atributo de tipo : indica el tipo de elemento
- el atributo hasExceptionBlock es un atributo opcional, de forma predeterminada, "0" es necesario para implementar el mecanismo de falla; el atributo indica que podemos esperar un error en este evento
- 0 - no se espera error
- 1 - se espera un posible error en la acción
- atributo invertResult - atributo opcional, el valor predeterminado es "0" - el atributo indica que es necesario cambiar el resultado del evento
- 0 - deja el resultado del evento
- 1 - cambia el resultado del evento al contrario
*! Un mecanismo para describir el error esperado.Déjame darte un ejemplo trivial de dónde lo usé por primera vez y qué hacer para que funcione.
Caso: entrada Captcha. Por el momento, no pude automatizar, por así decirlo, un cheque para el robot se bloquea hasta el momento: no me escriben un servicio de prueba de captcha (pero es más fácil para mí hacer una red neuronal para el reconocimiento))) Entonces, podemos cometer un error al ingresar. En este caso, realizo un evento de control en el que compruebo que no tenemos un elemento: una notificación sobre un código de control incorrecto, pongo el atributo hasExceptionBlock en él. Anteriormente, le pedí a la acción que pudiéramos tener varias repeticiones (5) y, después de todo, escribí exceptionBlock, en el que escribí que tenía que presionar el botón de salida para la notificación, y luego la acción se repitió.
Ejemplos de mi contexto.
Así es como registré el evento:
<event type="checkElementsInVisibility" hasExceptionBlock="1"> <orderNumber>57</orderNumber> <fields> <field> <element>___</element> </field> </fields> </event>
Y aquí excepción Bloqueo después de eventos
<exceptionBlock> <event type="clickElement"> <orderNumber>10</orderNumber> <elementName>_____</elementName> </event> </exceptionBlock>
Y sí, las acciones en una página se pueden descomponer en varias acciones.
+ que notó 2 parámetros en la configuración: defaultTimeOutsForWebDriverWait, lowTimeOutsForWebDriverWait. Por eso lo son. Porque Tengo todo el controlador web en un singleton, y no quería crear un nuevo WebDriverWait cada vez, entonces tengo 1 rápido y es en caso de error (bueno, o si simplemente pones hasExceptionBlock = "1", será estúpido con menos tiempo espera explícita): bueno, debe estar de acuerdo, espere un minuto para asegurarse de que el mensaje no salió como es debido, y cree un nuevo WebDriverWait cada vez. Bueno, esta situación en qué lado no se pega requiere una muleta. Decidí hacerlo.
Tipos de eventos
Aquí daré un conjunto mínimo de mis eventos, como un conjunto de exploración, con el que puedo probar casi todo en mi sistema.
Y ahora es sencillo para el código comprender qué es un evento y cómo se construye. El código esencialmente implementa el marco. Tengo 2 clases: DataBaseWrapper y SeleniumWrapper. En estas clases, se describe la interacción con los componentes de la infraestructura y también se reflejan las características de la plataforma. Daré la interfaz que implementa SeleniumWrapper
package logic.selenium; import models.ElementWithStringValue; import models.webpackage.Element; import org.openqa.selenium.WebElement; public interface SeleniumService { void initialization(boolean webDriverWait); void nacigateTo(String url); void refreshPage(); boolean checkElementNotPresent(Element element); WebElement findSingleVisibleElement(Element element); WebElement findSingleElementInDOM(Element element); void enterSingleValuesToWebField(ElementWithStringValue element); void click(Element element); String getInputValue(Element element); Object jsReturnsValue(String jsFunction);
Describe todas las características de selenio y superpone chips de plataforma; bueno, en realidad el chip principal es el método "enterSingleValuesToWebField". Recuerde que en WebPackage especificamos el tipo de elemento. Entonces, cómo reaccionar a este tipo al completar los campos se escribe aquí. Escribimos 1 vez y olvidamos. El método anterior debe corregirse usted mismo en primer lugar. Por ejemplo, los tipos 5 y 6, actualmente en vigor, solo son adecuados para mi sistema. Y si tiene un filtro y necesita filtrar mucho, y es típico (en su aplicación web), pero para usarlo primero debe mover el mouse sobre el campo, esperar a que aparezcan algunos campos, cambiar a algunos, esperar hay algo, luego ve allí y entra ... Prescribe estúpidamente el mecanismo de acción 1 vez, dale un tipo único a todo esto en la estructura del interruptor, no te molestes más, obtén un método polimórfico para todos los filtros de aplicación similares.
Entonces, en el paquete "package logic.testcase.events" hay una clase abstracta que describe las acciones generales del evento. Para crear su propio evento único, debe crear una nueva clase, heredar de esta clase abstracta, y ya tiene dataBaseService y seleniumService en el kit, y luego determinar qué datos necesita y qué hacer con ellos. Algo asi. Bueno, y en consecuencia, después de crear un nuevo evento, debe finalizar la clase de fábrica TestCaseActionFactory y, si es posible, el esquema XSD. Bueno, si se agrega un nuevo atributo, modifique el modelo en sí. De hecho, es muy fácil y rápido.
Entonces, un conjunto de exploradores.
goToURL , generalmente la primera acción, haga clic en el enlace especificado
Un ejemplo: <event type="goToURL"> <orderNumber>10</orderNumber> <url>testURL</url> </event>
filledFields - Relleno de elementos específicos
Etiquetas especiales:
- campos - entidad contenedor fiel
- campo : contiene la etiqueta del elemento
- element : indica el nombre del elemento de webPackage
- valor : qué valor indicar, tiene un atributo de tipo opcional (si el elemento es una casilla de verificación, entonces se indica uno de los valores: "marcar" o "desmarcar")
- atributo de tipo : indica cómo tomar el valor, opcional, el valor predeterminado es "1"
- 1 - se toma el valor especificado
- 2 - en este caso, se ejecuta la función JS especificada del directorio "\ TestSuite \ JS". IMPORTANTE: el nombre del archivo txt se indica sin ".txt" (y hasta ahora he encontrado aplicaciones para funciones js hasta ahora solo en esta forma; lo uso en un lugar para generar una posada aleatoria, pero el espectro de posibles aplicaciones es amplio)
- 3 - en este caso, la consulta en la base de datos se indica como el valor, y el programa sustituye el primer resultado de esta consulta
Un ejemplo: <event type="fillingFields"> <orderNumber>10</orderNumber> <fields> <field> <element>test</element> <value>test</value> </field> </fields> </event>
checkElementsVisibility : comprueba que los elementos especificados están presentes en el formulario (es decir, visibles y no solo en el DOM). En el atributo de campo, se puede especificar un elemento de WebPackage o directamente xpath
Un ejemplo: <event type="checkElementsVisibility"> <orderNumber>10</orderNumber> <fields> <field> <element>test</element> </field> <field> <xpath>test</xpath> </field> </fields> </event>
checkElementsInVisibility - similar a checkElementsVisibility, pero viceversa
clickElement : haga clic en el elemento especificado
Un ejemplo: <event type="clickElement"> <orderNumber>10</orderNumber> <elementName>test</elementName> </event>
checkInputValues - verifica los valores ingresados
Un ejemplo: <event type="checkInputValues"> <orderNumber>10</orderNumber> <fields> <field> <element>test</element> <value>test</value> </field> </fields> </event>
dbUpdate : realice una actualización en la base de datos (
oXygen reacciona de manera extraña a 1 evento del tipo dbUpdate; no sé qué hacer con él y no entiendo por qué )
Un ejemplo: <event type="dbUpdate"> <orderNumber>10</orderNumber> <dbRequest>update - </dbRequest> </event>
CheckQueryResultWithUtilityValue - verifica el valor ingresado por el usuario con el valor de la base de datos
Un ejemplo: <event type="checkQueryResultWithUtilityValue"> <orderNumber>10</orderNumber> <dbRequest>select ...</dbRequest> <utilityValue>test</utilityValue> </event>
checkFieldsPresenceByQueryResult : comprueba la presencia de elementos en el formulario por xpath por patrón. Si no se especifica el patrón deseado, la búsqueda se realizará de acuerdo con el patrón .//* [text () [contiene (normalize-space (.), "$")]], Donde en lugar de "$" habrá un valor de la base de datos. Al describir su propio patrón, debe indicar "$" en el lugar donde desea colocar el valor de la base de datos. En mi sistema hay las llamadas cuadrículas en las que hay valores que generalmente se forman desde algún tipo de vista. Este evento para probar tales cuadrículas
Un ejemplo: <event type="checkFieldsPresenceByQueryResult"> <orderNumber>10</orderNumber> <dbRequest>test</dbRequest> <utilityValue></utilityValue> </event>
Espere , todo es simple, esperando el número especificado de milisegundos. Desafortunadamente, a pesar de que esto se considera una muleta, lo diré con seguridad, a veces es imposible prescindir de él.
Un ejemplo: <event type="wait"> <orderNumber>10</orderNumber> <utilityValue>1000</utilityValue> </event>
scrollDown : desplácese hacia abajo desde el elemento especificado. Se hace de esta manera: hace clic en el elemento especificado y presiona la tecla "PgDn". En mis casos donde tuve que desplazarme hacia abajo, funciona bien:
Un ejemplo: <event type="scrollDown"> <orderNumber>10</orderNumber> <elementName>test</elementName> </event>
userInput : ingrese un valor en el elemento especificado. El único dispositivo semiautomático en mi automatización, usado solo para captcha. Se indica el elemento para ingresar el valor. El valor se ingresa en el cuadro de diálogo emergente.
Un ejemplo: <event type="userInput"> <orderNumber>10</orderNumber> <elementName>capch_input</elementName> </event>
Sobre el código
Entonces, traté de hacer la plataforma de acuerdo con los principios de la arquitectura limpia del tío Bob.
Paquetes:
aplicación - inicialización y lanzamiento + configs e informe (no me regañen por la clase Report - esto es lo que lo hace lo más rápido posible, luego lo más rápido posible)
Lógica: los servicios de lógica + clave de Selenium y DB. Hay eventos
modelos: POJO en XML y todas las clases de objetos auxiliares
utils - singleton para selenio y db
Para ejecutar el código, debe descargar jdk 12 y especificarlo en todas partes para que se activen sus chips. En Idea, esto se hace a través de la Estructura del proyecto -> Módulos y Proyecto. Además, no te olvides del corredor Maven.
Y cuando comience en el archivo bat, agregue --enable-preview. Un ejemplo fue.Bueno, para que todo se inicie, JDK deberá descargar el controlador ojdbc y soltar el dzharnik en el directorio "SprintAutoTest \ src \ lib". No lo proporciono, porque En este momento, todo es serio con Oracle: para descargarlo es necesario registrarse, pero estoy seguro de que todos lo harán de una forma u otra (bueno, asegúrese de que se creen todas las carpetas, de lo contrario el informe no se guardará)Resumen
Por lo tanto, tenemos un lanzador de pruebas, que escribe pruebas para las cuales es realmente rápido. Durante la semana laboral, pude automatizar 1.5 horas de trabajo manual, que realiza el robot en 5-6 minutos. Estas son aproximadamente 3700 líneas del caso de prueba concatenado y 830 elementos descritos (más de 4800 líneas). Los números son aproximados y, por lo tanto, no se miden, pero aquellos que se dedican a la automatización deben entender que este es un indicador muy alto, especialmente para los sistemas hostiles a los robots. Al mismo tiempo, pruebo todo: la lógica de negocios, a lo largo del camino realizo algunas pruebas negativas para la corrección de los atributos completados, y como beneficio adicional, verifico cada formulario web que no soy flojo, y describo todos los elementos funcionales y clave, son necesarios de forma independiente yo o no (Una pequeña digresión: uso closeValidation principalmente solo cuando escribo un examen.Cuando es estable y está claro que los localizadores no se cruzan, lo apago para todas las acciones, para que el proceso vaya más rápido).A primera vista, parece que hay muchas líneas de xml, pero en la práctica se generan semiautomáticamente, y solo se puede cometer un error en los parámetros ingresados directamente (porque de hecho tenemos 2 niveles de validación: el primero es el xml del esquema, el segundo comprobar la presencia de los formularios y elementos especificados al comienzo de TestCase).De las desventajas, no hay límites claros de las pruebas. Como tales, faltan y puedes culparme de que esto es solo un lanzador de macros, no pruebas. Digo esto:en la plataforma, las pruebas se dividen conceptualmente desde varios puntos de vista en varios niveles de abstracción:- + — « » + — ( – .. -)
- ( action — event c + )
- , , – -. , – . , . , – ,
- cada acción en la página es una prueba unitaria (devuelve un único resultado verdadero o falso)
Si compara mi enfoque con algo, entonces los inconvenientes de, por ejemplo, el popular Pepino y el concepto mismo de BDD son más significativos para mí (exactamente cuando probamos los que son como mi sistema):- No podemos garantizar el rendimiento de las pruebas al probar una aplicación web inestable. Es decir en mi caso, para la mayoría de las pruebas no podemos garantizar su ejecución, y caerán en "Cuándo", que en mi opinión no es generalmente aceptable, si describimos las pruebas con un conjunto de pruebas.
- Bueno y en todas partes se da este enorme ejemplo con un inicio de sesión. Sí, para toda mi práctica, es precisamente en el inicio de sesión que nunca ha habido errores (aunque ciertamente debería estar cubierto, eso es seguro). Y el ejemplo es bueno, pero para el resto de las pruebas, debe esculpir muletas interminables de Given y When: en el sistema que di para pruebas reales, tomará el 99% para describir las condiciones intermedias, mientras llegamos a esta prueba en sí misma: muchos problemas, un poco de esencia y también subir al código.
Por lo que me gustaría hacer, pensar, pero mis manos aún no han llegado:- ejecutando no una sino varias pruebas secuencialmente en una ejecución
- Creo que bombeando entidades para que puedan generar valores sobre el hecho de una nueva prueba, y se guardaron durante la ejecución
- hacer control de versiones centralizado. No solo git, sino también para indicar qué versión de la prueba ejecutar, bueno, o, de nuevo, un módulo inteligente que comprenda qué versión es relevante y cuál aún no
- Como dije, para comenzar una nueva prueba con nuevos valores, necesito cambiar 1 dígito, automatizar, por así decirlo, crear un módulo inteligente para ello.
- aunque no me molesta mucho que tenga todos los localizadores almacenados en un solo lugar, aún así, en el buen sentido, tendría que hacer una estructura aún más fácil de usar para almacenarlos
- no incursionó con el servidor de selenio. Creo que vale la pena pensar en esto, así como en la posibilidad de una mayor adaptación a CI, Team City, etc.
Bueno eso es todo. Adjunto una referencia a github: códigos fuente .Estaré muy contento con las críticas constructivas, espero que este proyecto sea realmente útil.