
Descifrado de la 2da parte del Tesla Autonomy Investor Day. Ciclo de entrenamiento de piloto automático, infraestructura de recopilación de datos, etiquetado automático de datos, imitación de conductores humanos, detección de distancia de video, supervisión de sensores y mucho más.La primera parte es el desarrollo de Full Self-Driving Computer (FSDC) .Host: FSDC puede trabajar con redes neuronales muy complejas para el procesamiento de imágenes. Es hora de hablar sobre cómo obtenemos imágenes y cómo las analizamos. Tenemos un director sénior de IA en Tesla, Andrei Karpaty, que le explicará todo esto.
Andrei: He estado entrenando en redes neuronales durante unos diez años, y ahora durante 5-6 años para uso industrial. Incluyendo instituciones tan conocidas como Stanford, Open AI y Google. Este conjunto de redes neuronales no es solo para el procesamiento de imágenes, sino también para el lenguaje natural. Diseñé arquitecturas que combinan estas dos modalidades para mi tesis doctoral.
En Stanford, impartí un curso sobre redes neuronales deconvolucionarias. Fui el maestro principal y desarrollé todo el plan de estudios para él. Al principio tenía unos 150 estudiantes, en los siguientes dos o tres años el número de estudiantes aumentó a 700. Este es un curso muy popular, uno de los cursos más grandes y exitosos en Stanford en este momento.
Ilon: Andrey es realmente uno de los mejores especialistas en visión artificial del mundo. Quizás el mejor.
Andrew: gracias. Hola a todos Pete te contó sobre un chip que desarrollamos específicamente para redes neuronales en un automóvil. Mi equipo es responsable de entrenar estas redes neuronales. Esto incluye la recopilación de datos, la capacitación y, en parte, la implementación.
¿Qué hacen las redes neuronales en un automóvil? Hay ocho cámaras en el automóvil que filman videos. Las redes neuronales miran estos videos, los procesan y hacen predicciones sobre lo que ven. Estamos interesados en las marcas viales, los participantes del tráfico, otros objetos y sus distancias, carreteras, semáforos, señales de tráfico, etc.

Mi presentación se puede dividir en tres partes. Primero, te presentaré brevemente las redes neuronales y cómo funcionan y cómo se entrenan. Esto debe hacerse para que en la segunda parte quede claro por qué es tan importante que tengamos una gran flota de automóviles Tesla (flota). ¿Por qué es este un factor clave en la formación de redes neuronales que funcionan de manera eficiente en el camino? En la tercera parte, hablaré sobre visión artificial, lidar y cómo estimar la distancia usando solo video.
¿Cómo funcionan las redes neuronales?
(No hay muchas novedades aquí, puede omitir e ir al siguiente encabezado)La tarea principal que las redes resuelven en el automóvil es el reconocimiento de patrones. Para nosotros los humanos, esta es una tarea muy simple. Miras las imágenes y ves un violonchelo, un bote, una iguana o unas tijeras. Muy fácil y simple para ti, pero no para la computadora. La razón es que estas imágenes de computadora son solo una matriz de píxeles, donde cada píxel es el valor de brillo en ese punto. En lugar de solo ver la imagen, la computadora recibe un millón de números en una matriz.
Ilon: Matrix, si quieres. Realmente matriz.
 Andrew:
Andrew: si. Necesitamos pasar de esta cuadrícula de píxeles y valores de brillo a conceptos de nivel superior como iguana, etc. Como puede imaginar, esta imagen de una iguana tiene un patrón de brillo específico. Pero las iguanas se pueden representar de diferentes maneras, en diferentes poses, en diferentes condiciones de iluminación, en un fondo diferente. Puede encontrar muchas imágenes diferentes de la iguana y debemos reconocerla en cualquier condición.
La razón por la que usted y yo podemos manejar esto fácilmente es porque tenemos una gran red neuronal dentro que procesa imágenes. La luz ingresa a la retina y se envía a la parte posterior de su cerebro a la corteza visual. La corteza cerebral consta de muchas neuronas que están conectadas entre sí y realizan reconocimiento de patrones.
En los últimos cinco años, los enfoques modernos para el procesamiento de imágenes usando computadoras también han comenzado a usar redes neuronales, pero en este caso, redes neuronales artificiales. Las redes neuronales artificiales son una aproximación matemática cruda de la corteza visual. También hay neuronas aquí, están conectadas entre sí. Una red neuronal típica incluye decenas o cientos de millones de neuronas, y cada neurona tiene miles de enlaces.
Podemos tomar una red neuronal y mostrarle imágenes, como nuestra iguana, y la red hará una predicción que verá. Primero, las redes neuronales se inicializan completamente por accidente, todos los pesos de las conexiones entre las neuronas son números aleatorios. Por lo tanto, el pronóstico de la red también será aleatorio. Puede resultar que la red piense que es probablemente un bote. Durante el entrenamiento, sabemos y notamos que la iguana está en la imagen. Simplemente decimos que nos gustaría que la probabilidad de una iguana para esta imagen aumente, y la probabilidad de que todo lo demás disminuya. Luego se utiliza un proceso matemático llamado método de propagación inversa. Descenso de gradiente estocástico, que nos permite propagar la señal a lo largo de los enlaces y actualizar sus pesos. Actualizaremos bastante el peso de cada uno de estos compuestos, y tan pronto como se complete la actualización, la probabilidad de una iguana para esta imagen aumentará ligeramente, y la probabilidad de otras respuestas disminuirá.
Por supuesto, hacemos esto con más de una sola imagen. Tenemos un gran conjunto de datos etiquetados. Por lo general, son millones de imágenes, miles de etiquetas más o menos. El proceso de aprendizaje se repite una y otra vez. Le muestra una imagen a la computadora, le dice su opinión, luego dice la respuesta correcta y la red está ligeramente configurada. Repites esto millones de veces, a veces mostrando la misma imagen cientos de veces. El entrenamiento generalmente toma varias horas o varios días.
Ahora algo contra-intuitivo sobre el trabajo de las redes neuronales. Realmente necesitan muchos ejemplos. No solo cabe en tu cabeza, sino que realmente comienzan desde cero, no saben nada. Aquí hay un ejemplo: un lindo perro, y probablemente no conoces su raza. Este es un perro de aguas japonés. Estamos viendo esta imagen y vemos un perro de aguas japonés. Podemos decir: "OK, entiendo, ahora sé cómo se ve el spaniel japonés". Si te muestro algunas imágenes más de otros perros, puedes encontrar otros spaniels japoneses entre ellos. Solo necesita un ejemplo, pero las computadoras no. Necesitan muchos datos sobre spaniels japoneses, miles de ejemplos, en diferentes poses, diferentes condiciones de iluminación, en diferentes fondos, etc. Debe mostrarle a la computadora cómo se ve el spaniel japonés desde diferentes puntos de vista. Y realmente necesita todos estos datos, de lo contrario la computadora no podrá aprender la plantilla deseada.
Diseño de imagen para piloto automático
Entonces, ¿cómo se relaciona todo esto con la conducción autónoma? No nos preocupan mucho las razas de perros. Tal vez les importe en el futuro. Pero ahora estamos interesados en las marcas viales, los objetos en el camino, dónde están, dónde podemos ir, etc. Ahora no solo tenemos etiquetas como iguana, sino que tenemos imágenes de la carretera y nos interesan, por ejemplo, las marcas viales. Una persona mira la imagen y la marca con el mouse.

Tenemos la oportunidad de contactar a los autos Tesla y pedir aún más fotos. Si solicita fotos al azar, obtendrá imágenes en las que, por regla general, el automóvil simplemente va por la carretera. Este será un conjunto de datos aleatorio y lo marcaremos.
Si marca solo conjuntos aleatorios, su red aprenderá una situación de tráfico simple y común y funcionará bien solo en ella. Cuando le muestres un ejemplo ligeramente diferente, digamos una imagen de una carretera girando en un área residencial. Su red puede dar el resultado incorrecto. Ella dirá "bueno, lo he visto muchas veces, el camino sigue recto".

Por supuesto, esto es completamente falso. Pero no podemos culpar a la red neuronal. Ella no sabe si el árbol de la izquierda, el auto de la derecha o esos edificios en el fondo importan. La red no sabe nada sobre esto. Todos sabemos que la línea de marcado es importante y el hecho de que gira un poco hacia un lado. La red debería tener esto en cuenta, pero no existe un mecanismo por el cual simplemente podamos decirle a la red neuronal que estos trazos de las marcas viales realmente importan. La única herramienta en nuestras manos son los datos etiquetados.

Tomamos imágenes en las que la red está equivocada y las marcamos correctamente. En este caso, marcamos el marcado de giro. Entonces necesita transferir muchas imágenes similares a la red neuronal. Y con el tiempo, acumulará conocimiento y aprenderá a comprender este patrón, a comprender que esta parte de la imagen no juega un papel, pero este marcado es muy importante. La red aprenderá cómo encontrar correctamente el carril.
No solo es importante el tamaño del conjunto de datos de entrenamiento. Necesitamos más que solo millones de imágenes. Se necesita mucho trabajo para cubrir el espacio de situaciones que un automóvil puede enfrentar en la carretera. Debes enseñarle a una computadora a trabajar de noche y bajo la lluvia. El camino puede reflejar la luz como un espejo, la iluminación puede variar dentro de amplios límites, las imágenes se verán muy diferentes.

Debemos enseñarle a la computadora cómo manejar sombras, tenedores y objetos grandes que ocupan la mayor parte de la imagen. Cómo trabajar con túneles o en un área de reparación de carreteras. Y en todos estos casos no existe un mecanismo directo para decirle a la red qué hacer. Solo tenemos un gran conjunto de datos. Podemos tomar imágenes, marcar y entrenar la red hasta que comience a comprender su estructura.
Los conjuntos de datos grandes y diversos ayudan a las redes a funcionar muy bien. Este no es nuestro descubrimiento. Experimentos e investigaciones en Google, Facebook, Baidu, Deepmind de Alphabet. Todos muestran resultados similares: a las redes neuronales realmente les gustan los datos, como la cantidad y la variedad. Agregue más datos y la precisión de las redes neuronales está creciendo.
Tendrá que desarrollar un piloto automático para simular el comportamiento de los automóviles en una simulación.
Varios expertos señalan que podríamos usar la simulación para obtener los datos necesarios en la escala correcta. En Tesla, hemos hecho esta pregunta repetidamente. Tenemos nuestro propio simulador. Utilizamos ampliamente la simulación para desarrollar y evaluar software. Lo usamos para entrenar con bastante éxito. Pero al final, cuando se trata de datos de entrenamiento para redes neuronales, nada puede reemplazar los datos reales. Las simulaciones tienen problemas para modelar la apariencia, la física y el comportamiento de los participantes.

El mundo real nos arroja un montón de situaciones inesperadas. Condiciones difíciles con nieve, árboles, viento. Varios artefactos visuales que son difíciles de modelar. Zonas de reparación de carreteras, arbustos, bolsas de plástico colgando en el viento. Puede haber muchas personas, adultos, niños y animales mezclados. Modelar el comportamiento y la interacción de todo esto es una tarea absolutamente insoluble.

No se trata del movimiento de un peatón. Se trata de cómo los peatones reaccionan entre sí, y cómo los automóviles reaccionan entre sí, cómo reaccionan ante usted. Todo esto es muy difícil de simular. Primero debe desarrollar un piloto automático, solo para simular el comportamiento de los automóviles en una simulación.
Esto es realmente dificil. Pueden ser perros, animales exóticos, y a veces ni siquiera es algo que no puedes pretender ser, es algo que simplemente nunca se te pasa por la mente. No sabía que un camión puede transportar un camión que lleva un camión que lleva otro camión. Pero en el mundo real, esto y muchas otras cosas están sucediendo que son difíciles de resolver. La variedad que veo en los datos que provienen de los automóviles es una locura en relación con lo que tenemos en el simulador. Aunque tenemos un buen simulador.
Ilon: La simulación es como si estuvieras inventando tu propia tarea para ti. Si sabe que va a fingir, está bien, por supuesto que lidiará con esto. Pero como dijo Andrei, no sabes lo que no sabes. El mundo es muy extraño, tiene millones de casos especiales. Si alguien crea una simulación de conducción que reproduce fielmente la realidad, esto en sí mismo será un logro monumental para la humanidad. Pero nadie puede hacer esto. Simplemente no hay manera.
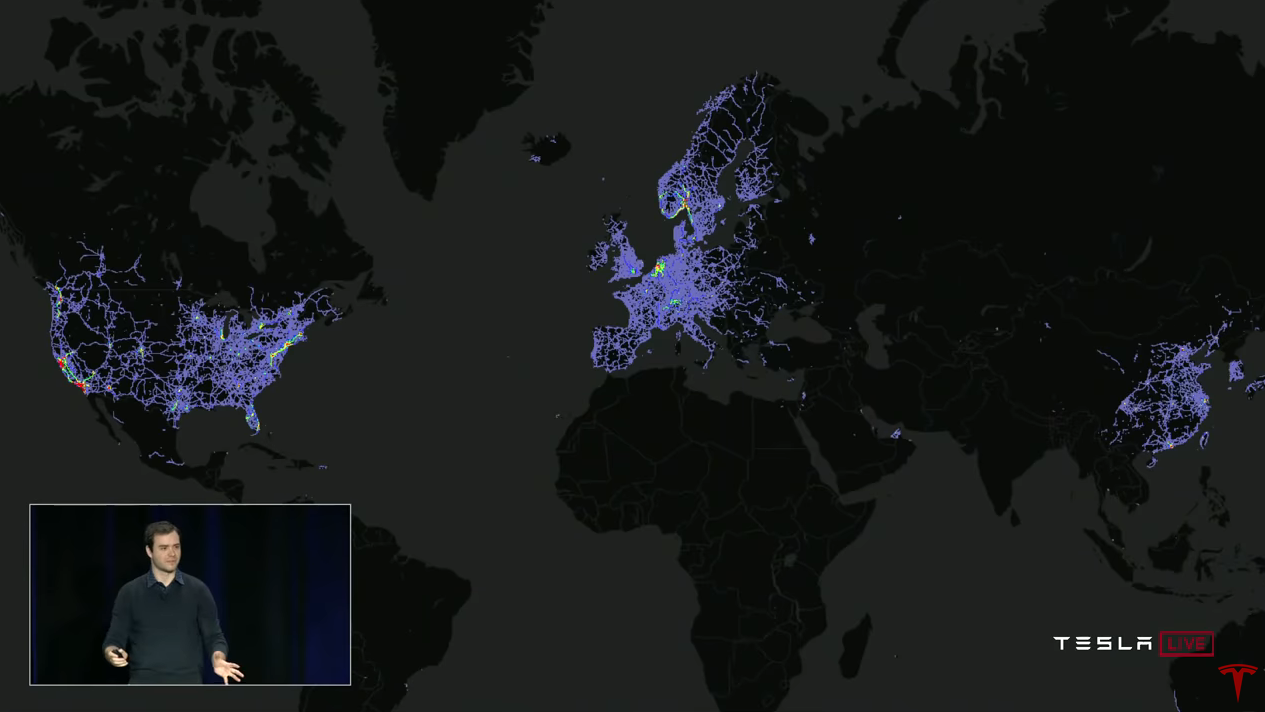
La flota es una fuente de datos clave para la capacitación.
 Andrei:
Andrei: Para que las redes neuronales funcionen bien, necesitas un conjunto de datos grande, diverso y real. Y si tiene uno, puede entrenar su red neuronal y funcionará muy bien. Entonces, ¿por qué Tesla es tan especial en este sentido? La respuesta, por supuesto, es la flota (flota, flota de Tesla). Podemos recopilar datos de todos los vehículos Tesla y usarlos para entrenamiento.
Veamos un ejemplo específico de mejora del funcionamiento de un detector de objetos. Esto le dará una idea de cómo entrenamos redes neuronales, cómo las usamos y cómo mejoran con el tiempo.
La detección de objetos es una de nuestras tareas más importantes. Necesitamos resaltar las dimensiones de los autos y otros objetos para rastrearlos y entender cómo pueden moverse. Podemos pedirle a la gente que marque las imágenes. La gente dirá: "aquí hay autos, aquí hay bicicletas", etc. Y podemos entrenar a la red neuronal en estos datos. Pero en algunos casos, la red hará pronósticos incorrectos.

Por ejemplo, si nos topamos con un automóvil al que está conectada una bicicleta en la parte posterior, entonces nuestra red neuronal detectará 2 objetos: un automóvil y una bicicleta. Así trabajaba ella cuando llegué. Y a su manera, es correcto, porque ambos objetos están realmente presentes aquí. Pero al planificador del piloto automático no le importa el hecho de que esta bicicleta es un objeto separado que se mueve con el automóvil. La verdad es que esta bicicleta está rígidamente unida al automóvil. En términos de objetos en la carretera, este es un objeto: un automóvil.

Ahora nos gustaría marcar muchos objetos similares como "un automóvil". Nuestro equipo utiliza el siguiente enfoque. Tomamos esta imagen o varias imágenes en las que este modelo está presente. Y tenemos un mecanismo de aprendizaje automático con el que podemos pedirle a la flota que nos proporcione ejemplos que se vean iguales. Y la flota envía imágenes en respuesta.

Aquí hay un ejemplo de seis imágenes recibidas. Todos contienen bicicletas unidas a automóviles. Los marcaremos correctamente y nuestro detector funcionará mejor. La red comenzará a comprender cuándo la bicicleta está conectada al automóvil, y que es un objeto. Puede entrenar a la red en esto, siempre que tenga suficientes ejemplos. Y así es como resolvemos tales problemas.
Hablo mucho sobre cómo obtener datos de los autos Tesla. Y quiero decir de inmediato que desarrollamos este sistema desde el principio, teniendo en cuenta la confidencialidad. Todos los datos que utilizamos para el entrenamiento son anónimos.
La flota nos envía no solo bicicletas en automóviles. Constantemente buscamos muchos modelos diferentes. Por ejemplo, estamos buscando embarcaciones: la flota envía imágenes de embarcaciones en las carreteras. Queremos imágenes de las áreas de reparación de carreteras, y la flota nos envía muchas imágenes de todo el mundo. O, por ejemplo, basura en el camino, esto también es muy importante. La flota nos envía imágenes de neumáticos, conos, bolsas de plástico y similares en el camino.

Podemos obtener suficientes imágenes, marcarlas correctamente y la red neuronal aprenderá a trabajar con ellas en el mundo real. Necesitamos la red neuronal para comprender lo que está sucediendo y responder correctamente.
La incertidumbre de la red neuronal desencadena la recopilación de datos
El procedimiento, que repetimos una y otra vez para entrenar la red neuronal, es el siguiente. Comenzamos con un conjunto aleatorio de imágenes recibidas de la flota. Marcamos las imágenes, entrenamos la red neuronal y la cargamos en los automóviles. Tenemos mecanismos por los cuales detectamos imprecisiones en el funcionamiento del piloto automático. Si vemos que la red neuronal no está segura o si hay una intervención del conductor u otros eventos, los datos en los que sucedió esto se envían automáticamente.

Por ejemplo, las marcas de túneles son poco reconocidas. Notamos que hay un problema en los túneles. Las imágenes correspondientes se incluyen en nuestras pruebas unitarias para que el problema no se pueda repetir más tarde. Ahora, para solucionar el problema, necesitamos muchos ejemplos de capacitación. Pedimos a la flota que nos envíe más imágenes de los túneles, las marque correctamente, las agregue al conjunto de entrenamiento y reentrene la red, y luego las cargue en los automóviles. Este ciclo se repite una y otra vez. Llamamos a este proceso iterativo el motor de datos (motor de datos? Motor de datos?). Encendemos la red en modo sombra, detectamos inexactitudes, solicitamos más datos, los incluimos en el conjunto de capacitación. Hacemos esto para todo tipo de predicciones de nuestras redes neuronales.
Marcado automático de datos
Hablé mucho sobre el marcado manual de imágenes. Este es un proceso costoso, tanto a tiempo como financieramente. Puede ser muy costoso. Quiero hablar sobre cómo puedes usar la flota aquí. El marcado manual es un cuello de botella. Solo queremos transferir los datos y marcarlos automáticamente. Y hay varios mecanismos para esto.
Como ejemplo, uno de nuestros proyectos recientes es reconstruir la detección.
Usted está manejando en la autopista, alguien está manejando a la izquierda o derecha, y él está reconstruyendo en su carril. Aquí hay un video donde el piloto automático detecta una reconstrucción. Por supuesto, nos gustaría descubrirlo lo antes posible. El enfoque para resolver este problema es que no escribimos código como: el indicador de dirección izquierdo está encendido, el indicador de dirección derecho está encendido, si el automóvil se movió horizontalmente con el tiempo. En cambio, utilizamos el autoaprendizaje basado en flota.Como funciona Solicitamos a la flota que nos envíe datos cada vez que se registre una reconstrucción en nuestro carril. Luego retrocedemos el tiempo y notamos automáticamente que este automóvil se reconstruirá frente a usted en 1.3 segundos. Estos datos pueden usarse para entrenar la red neuronal. Por lo tanto, la red neuronal misma extraerá los signos necesarios. Por ejemplo, un automóvil está fregando y luego reconstruyéndose, o tiene una señal de giro encendida. La red neuronal se entera de todo esto a partir de ejemplos etiquetados automáticamente.
Aquí hay un video donde el piloto automático detecta una reconstrucción. Por supuesto, nos gustaría descubrirlo lo antes posible. El enfoque para resolver este problema es que no escribimos código como: el indicador de dirección izquierdo está encendido, el indicador de dirección derecho está encendido, si el automóvil se movió horizontalmente con el tiempo. En cambio, utilizamos el autoaprendizaje basado en flota.Como funciona Solicitamos a la flota que nos envíe datos cada vez que se registre una reconstrucción en nuestro carril. Luego retrocedemos el tiempo y notamos automáticamente que este automóvil se reconstruirá frente a usted en 1.3 segundos. Estos datos pueden usarse para entrenar la red neuronal. Por lo tanto, la red neuronal misma extraerá los signos necesarios. Por ejemplo, un automóvil está fregando y luego reconstruyéndose, o tiene una señal de giro encendida. La red neuronal se entera de todo esto a partir de ejemplos etiquetados automáticamente.Verificación de las sombras
Solicitamos a la flota que nos envíe automáticamente los datos. Podemos recopilar medio millón de imágenes más o menos, y las reconstrucciones se marcarán en todas. Entrenamos la red y la cargamos en la flota. Pero hasta que lo activemos por completo, pero lo ejecutemos en modo sombra. En este modo, la red constantemente hace predicciones: "oye, creo que este auto va a ser reconstruido". Y estamos buscando pronósticos erróneos. Aquí hay un ejemplo de un clip que obtuvimos del modo sombra. Aquí la situación no es un poco obvia, y la red pensó que el automóvil de la derecha estaba a punto de reconstruirse. Y puede notar que está coqueteando ligeramente con la línea de marcado. La red reaccionó a esto y sugirió que el automóvil pronto estaría en nuestro carril. Pero esto no sucedió.La red opera en modo sombra y realiza pronósticos. Entre ellos están los falsos positivos y los falsos negativos. Algunas veces la red reacciona erróneamente y otras veces se saltea eventos. Todos estos errores desencadenan la recopilación de datos. Los datos se etiquetan y se incorporan a la capacitación sin esfuerzo adicional. Y no ponemos en peligro a las personas en este proceso. Volvemos a entrenar la red y usamos el modo sombra nuevamente. Podemos repetir esto varias veces, evaluando falsas alarmas en condiciones reales de tráfico. Una vez que los indicadores nos convienen, simplemente hacemos clic en el interruptor y dejamos que la red controle el automóvil.Lanzamos una de las primeras versiones del detector de reconstrucción, hace unos tres meses. Si nota que la máquina se ha vuelto mucho mejor para detectar la reconstrucción, esto es entrenamiento con la flota en acción. Y ni una sola persona resultó herida en este proceso. Es solo una gran cantidad de entrenamiento de redes neuronales basado en datos reales, usando el modo sombra y analizando los resultados.Ilon: De hecho, todos los conductores entrenan constantemente la red. No importa si el piloto automático está activado o desactivado. La red está aprendiendo. Cada milla recorrida por una máquina con equipo HW2.0 o superior educa la red.
Aquí hay un ejemplo de un clip que obtuvimos del modo sombra. Aquí la situación no es un poco obvia, y la red pensó que el automóvil de la derecha estaba a punto de reconstruirse. Y puede notar que está coqueteando ligeramente con la línea de marcado. La red reaccionó a esto y sugirió que el automóvil pronto estaría en nuestro carril. Pero esto no sucedió.La red opera en modo sombra y realiza pronósticos. Entre ellos están los falsos positivos y los falsos negativos. Algunas veces la red reacciona erróneamente y otras veces se saltea eventos. Todos estos errores desencadenan la recopilación de datos. Los datos se etiquetan y se incorporan a la capacitación sin esfuerzo adicional. Y no ponemos en peligro a las personas en este proceso. Volvemos a entrenar la red y usamos el modo sombra nuevamente. Podemos repetir esto varias veces, evaluando falsas alarmas en condiciones reales de tráfico. Una vez que los indicadores nos convienen, simplemente hacemos clic en el interruptor y dejamos que la red controle el automóvil.Lanzamos una de las primeras versiones del detector de reconstrucción, hace unos tres meses. Si nota que la máquina se ha vuelto mucho mejor para detectar la reconstrucción, esto es entrenamiento con la flota en acción. Y ni una sola persona resultó herida en este proceso. Es solo una gran cantidad de entrenamiento de redes neuronales basado en datos reales, usando el modo sombra y analizando los resultados.Ilon: De hecho, todos los conductores entrenan constantemente la red. No importa si el piloto automático está activado o desactivado. La red está aprendiendo. Cada milla recorrida por una máquina con equipo HW2.0 o superior educa la red.Mientras conduce, en realidad está marcando los datos
 Andrei: Otro proyecto interesante que utilizamos en el esquema de entrenamiento de la flota es pronosticar el camino. Cuando conduce, en realidad está marcando los datos. Usted nos dice cómo conducir en diferentes situaciones de manejo. Aquí está uno de los conductores que giró a la izquierda en la intersección. Tenemos un video completo de todas las cámaras y conocemos el camino que eligió el controlador. También sabemos cuál era la velocidad y el ángulo de rotación del volante. Lo reunimos todo y entendemos el camino que una persona ha elegido en esta situación de tráfico. Y podemos usar esto como enseñanza con un maestro. Solo obtenemos la cantidad necesaria de datos de la flota, capacitamos a la red en estas trayectorias y luego la red neuronal puede predecir el camino.Esto se llama imitación de aprendizaje. Tomamos las trayectorias de las personas del mundo real y tratamos de imitarlas. Y nuevamente podemos tomar nuestro enfoque iterativo.Aquí hay un ejemplo de predicción de un camino en condiciones de carretera difíciles. En el video superponemos el pronóstico de la red. El verde marca el camino que la red se movería.
Andrei: Otro proyecto interesante que utilizamos en el esquema de entrenamiento de la flota es pronosticar el camino. Cuando conduce, en realidad está marcando los datos. Usted nos dice cómo conducir en diferentes situaciones de manejo. Aquí está uno de los conductores que giró a la izquierda en la intersección. Tenemos un video completo de todas las cámaras y conocemos el camino que eligió el controlador. También sabemos cuál era la velocidad y el ángulo de rotación del volante. Lo reunimos todo y entendemos el camino que una persona ha elegido en esta situación de tráfico. Y podemos usar esto como enseñanza con un maestro. Solo obtenemos la cantidad necesaria de datos de la flota, capacitamos a la red en estas trayectorias y luego la red neuronal puede predecir el camino.Esto se llama imitación de aprendizaje. Tomamos las trayectorias de las personas del mundo real y tratamos de imitarlas. Y nuevamente podemos tomar nuestro enfoque iterativo.Aquí hay un ejemplo de predicción de un camino en condiciones de carretera difíciles. En el video superponemos el pronóstico de la red. El verde marca el camino que la red se movería. Ilon: La locura es que la red predice un camino que ni siquiera puede ver. Con increíblemente alta precisión. Ella no ve lo que hay alrededor de la curva, pero cree que la probabilidad de esta trayectoria es extremadamente alta. Y resulta ser correcto. Hoy verás esto en autos, incluiremos visión aumentada para que puedas ver las marcas y proyecciones de la trayectoria superpuesta en el video.Andrei: De hecho, bajo el capó, lo que más está sucediendo, yIlon: En realidad, da un poco de miedo (Andrey se ríe).Andrew: Por supuesto, extraño muchos detalles. Es posible que no desee utilizar todos los controladores en una fila para marcar, desea imitar lo mejor. Y utilizamos varias formas de preparar estos datos. Curiosamente, este pronóstico es en realidad tridimensional. Este es un camino en el espacio tridimensional que mostramos en 2D. Pero la red tiene información sobre la pendiente, y esto es muy importante para conducir.Predecir cómo funciona actualmente en los automóviles. Por cierto, cuando pasaste el cruce de la autopista, hace unos cinco meses, tu automóvil no pudo soportarlo. Ahora si puede. Esta es la predicción de la forma, en acción, en sus autos. Lo encendimos hace un tiempo. Y hoy puedes ver cómo funciona en las intersecciones. Una parte importante del entrenamiento para superar las intersecciones se obtiene marcando automáticamente los datos.Logré hablar sobre los componentes clave del entrenamiento de redes neuronales. Necesita un conjunto amplio y diverso de datos reales. En Tesla, lo conseguimos utilizando la flota. Usamos el motor de datos, el modo sombra y la partición automática de datos usando la flota. Y podemos escalar este enfoque.
Ilon: La locura es que la red predice un camino que ni siquiera puede ver. Con increíblemente alta precisión. Ella no ve lo que hay alrededor de la curva, pero cree que la probabilidad de esta trayectoria es extremadamente alta. Y resulta ser correcto. Hoy verás esto en autos, incluiremos visión aumentada para que puedas ver las marcas y proyecciones de la trayectoria superpuesta en el video.Andrei: De hecho, bajo el capó, lo que más está sucediendo, yIlon: En realidad, da un poco de miedo (Andrey se ríe).Andrew: Por supuesto, extraño muchos detalles. Es posible que no desee utilizar todos los controladores en una fila para marcar, desea imitar lo mejor. Y utilizamos varias formas de preparar estos datos. Curiosamente, este pronóstico es en realidad tridimensional. Este es un camino en el espacio tridimensional que mostramos en 2D. Pero la red tiene información sobre la pendiente, y esto es muy importante para conducir.Predecir cómo funciona actualmente en los automóviles. Por cierto, cuando pasaste el cruce de la autopista, hace unos cinco meses, tu automóvil no pudo soportarlo. Ahora si puede. Esta es la predicción de la forma, en acción, en sus autos. Lo encendimos hace un tiempo. Y hoy puedes ver cómo funciona en las intersecciones. Una parte importante del entrenamiento para superar las intersecciones se obtiene marcando automáticamente los datos.Logré hablar sobre los componentes clave del entrenamiento de redes neuronales. Necesita un conjunto amplio y diverso de datos reales. En Tesla, lo conseguimos utilizando la flota. Usamos el motor de datos, el modo sombra y la partición automática de datos usando la flota. Y podemos escalar este enfoque.Percepción de profundidad por video
 En la siguiente parte de mi discurso hablaré sobre percibir la profundidad a través de la visión. Probablemente sepa que los automóviles usan al menos dos tipos de sensores. Una es cámaras de video con brillo, y la otra es lidar, que utilizan muchas compañías. Lidar proporciona mediciones puntuales de la distancia a su alrededor.Me gustaría señalar que todos ustedes vinieron aquí usando solo su red neuronal y su visión. No disparaste con láser de tus ojos y aún así terminaste aquí.Está claro que la red neuronal humana extrae la distancia y percibe el mundo como tridimensional exclusivamente a través de la visión. Ella usa varios trucos. Hablaré brevemente sobre algunos de ellos. Por ejemplo, tenemos dos ojos, así que tienes dos imágenes del mundo frente a ti. Su cerebro combina esta información para obtener una estimación de distancias, esto se hace triangulando puntos en dos imágenes. En muchos animales, los ojos están ubicados a los lados y su campo de visión está ligeramente cruzado. Estos animales usan estructura (movimiento). Mueven sus cabezas para obtener muchas imágenes del mundo desde diferentes puntos y también pueden aplicar triangulación.
En la siguiente parte de mi discurso hablaré sobre percibir la profundidad a través de la visión. Probablemente sepa que los automóviles usan al menos dos tipos de sensores. Una es cámaras de video con brillo, y la otra es lidar, que utilizan muchas compañías. Lidar proporciona mediciones puntuales de la distancia a su alrededor.Me gustaría señalar que todos ustedes vinieron aquí usando solo su red neuronal y su visión. No disparaste con láser de tus ojos y aún así terminaste aquí.Está claro que la red neuronal humana extrae la distancia y percibe el mundo como tridimensional exclusivamente a través de la visión. Ella usa varios trucos. Hablaré brevemente sobre algunos de ellos. Por ejemplo, tenemos dos ojos, así que tienes dos imágenes del mundo frente a ti. Su cerebro combina esta información para obtener una estimación de distancias, esto se hace triangulando puntos en dos imágenes. En muchos animales, los ojos están ubicados a los lados y su campo de visión está ligeramente cruzado. Estos animales usan estructura (movimiento). Mueven sus cabezas para obtener muchas imágenes del mundo desde diferentes puntos y también pueden aplicar triangulación. Incluso con un ojo cerrado y completamente inmóvil, conserva un cierto sentido de percepción de la distancia. Si cierras un ojo, no te parecerá que me he acercado dos metros más o cien metros más. Esto se debe a que existen muchas técnicas monoculares poderosas que su cerebro también aplica. Por ejemplo, una ilusión óptica común, con dos franjas idénticas en el fondo del riel. Su cerebro evalúa la escena y espera que uno de ellos sea más grande que el otro debido a que las líneas ferroviarias desaparecen en la distancia. Su cerebro hace mucho de esto automáticamente, y las redes neuronales artificiales también pueden hacerlo.Daré tres ejemplos de cómo puedes lograr la percepción de profundidad en el video. Un enfoque clásico y dos basados en redes neuronales.
Incluso con un ojo cerrado y completamente inmóvil, conserva un cierto sentido de percepción de la distancia. Si cierras un ojo, no te parecerá que me he acercado dos metros más o cien metros más. Esto se debe a que existen muchas técnicas monoculares poderosas que su cerebro también aplica. Por ejemplo, una ilusión óptica común, con dos franjas idénticas en el fondo del riel. Su cerebro evalúa la escena y espera que uno de ellos sea más grande que el otro debido a que las líneas ferroviarias desaparecen en la distancia. Su cerebro hace mucho de esto automáticamente, y las redes neuronales artificiales también pueden hacerlo.Daré tres ejemplos de cómo puedes lograr la percepción de profundidad en el video. Un enfoque clásico y dos basados en redes neuronales. Podemos tomar un videoclip en unos segundos y recrear los alrededores en 3D utilizando métodos de triangulación y visión estéreo. Aplicamos métodos similares en el automóvil. Lo principal es que la señal realmente tiene la información necesaria, la única pregunta es extraerla.
Podemos tomar un videoclip en unos segundos y recrear los alrededores en 3D utilizando métodos de triangulación y visión estéreo. Aplicamos métodos similares en el automóvil. Lo principal es que la señal realmente tiene la información necesaria, la única pregunta es extraerla.Distancia de marcado usando radar
Como dije, las redes neuronales son una herramienta de reconocimiento visual muy poderosa. Si desea que reconozcan la distancia, debe marcar las distancias, y luego la red aprenderá cómo hacerlo. Nada restringe las redes en su capacidad de predecir la distancia que no sea tener datos etiquetados.Usamos un radar dirigido hacia adelante. Este radar mide y marca la distancia a los objetos que ve la red neuronal. En lugar de decirle a la gente "este auto está a unos 25 metros de distancia", puede marcar los datos mucho mejor usando sensores. El radar funciona muy bien a esta distancia. Usted marca los datos y entrena la red neuronal. Si tiene suficientes datos, una red neuronal será muy buena para predecir la distancia. En esta imagen, los círculos muestran los objetos recibidos por el radar, y los cuboides son los objetos recibidos por la red neuronal. Y si la red funciona bien, entonces, en la vista superior, las posiciones de los cuboides deberían coincidir con la posición de los círculos, que observamos. Las redes neuronales funcionan muy bien con la predicción de distancia. Pueden aprender los tamaños de diferentes vehículos y, de acuerdo con su tamaño en la imagen, determinar con bastante precisión la distancia.
En esta imagen, los círculos muestran los objetos recibidos por el radar, y los cuboides son los objetos recibidos por la red neuronal. Y si la red funciona bien, entonces, en la vista superior, las posiciones de los cuboides deberían coincidir con la posición de los círculos, que observamos. Las redes neuronales funcionan muy bien con la predicción de distancia. Pueden aprender los tamaños de diferentes vehículos y, de acuerdo con su tamaño en la imagen, determinar con bastante precisión la distancia.Auto-supervisión
El último mecanismo, del que hablaré muy brevemente, es un poco más técnico. Solo hay unos pocos artículos, principalmente en el último año o dos, sobre este enfoque. Se llama autocontrol. ¿Qué está pasando aquí? Subes videos sin etiquetar a la red neuronal. Y la red aún puede aprender a reconocer la distancia. Sin entrar en detalles, la idea es que una red neuronal prediga la distancia en cada cuadro de este video. No tenemos etiquetas para la verificación, pero hay una consistencia en el tiempo objetivo. No importa la distancia que predice la red, debe ser consistente en todo el video. Y la única forma de ser consistente es predecir la distancia correctamente. La red predice automáticamente la profundidad para todos los píxeles. Logramos reproducirlo y funciona bastante bien.
¿Qué está pasando aquí? Subes videos sin etiquetar a la red neuronal. Y la red aún puede aprender a reconocer la distancia. Sin entrar en detalles, la idea es que una red neuronal prediga la distancia en cada cuadro de este video. No tenemos etiquetas para la verificación, pero hay una consistencia en el tiempo objetivo. No importa la distancia que predice la red, debe ser consistente en todo el video. Y la única forma de ser consistente es predecir la distancia correctamente. La red predice automáticamente la profundidad para todos los píxeles. Logramos reproducirlo y funciona bastante bien.—
Para resumir.
La gente usa visión, no láser. Quiero enfatizar que el poderoso reconocimiento visual es absolutamente esencial para la conducción autónoma. Necesitamos redes neuronales que realmente entiendan el medio ambiente. Los datos del LIDAR están mucho menos saturados de información. ¿Es esta silueta en la carretera, es una bolsa de plástico o un neumático? Lidar simplemente te dará algunos puntos, mientras que la visión puede decirte de qué se trata. ¿Está este tipo en una bicicleta mirando hacia atrás, está tratando de cambiar de carril o va derecho? En la zona de reparación de carreteras, ¿qué significan estos signos y cómo debo comportarme aquí? Sí, toda la infraestructura vial está diseñada para el consumo visual. Todas las señales, semáforos, todo es para la vista, ahí es donde está toda la información. Y debemos usarlo.Esta chica es una apasionada del teléfono, ¿va a pisar el camino? Las respuestas a tales preguntas se pueden encontrar solo con la ayuda de la visión y son necesarias para el piloto automático de nivel 4-5. Y eso es lo que estamos desarrollando en Tesla. Hacemos esto a través de capacitación en redes neuronales a gran escala, nuestro motor de datos y asistencia de flota.En este sentido, lidar es un intento de cortar el camino. Evita la tarea fundamental de la visión artificial, cuya solución es necesaria para la conducción autónoma. Da una falsa sensación de progreso. Lidar solo es bueno para demostraciones rápidas.
Los datos del LIDAR están mucho menos saturados de información. ¿Es esta silueta en la carretera, es una bolsa de plástico o un neumático? Lidar simplemente te dará algunos puntos, mientras que la visión puede decirte de qué se trata. ¿Está este tipo en una bicicleta mirando hacia atrás, está tratando de cambiar de carril o va derecho? En la zona de reparación de carreteras, ¿qué significan estos signos y cómo debo comportarme aquí? Sí, toda la infraestructura vial está diseñada para el consumo visual. Todas las señales, semáforos, todo es para la vista, ahí es donde está toda la información. Y debemos usarlo.Esta chica es una apasionada del teléfono, ¿va a pisar el camino? Las respuestas a tales preguntas se pueden encontrar solo con la ayuda de la visión y son necesarias para el piloto automático de nivel 4-5. Y eso es lo que estamos desarrollando en Tesla. Hacemos esto a través de capacitación en redes neuronales a gran escala, nuestro motor de datos y asistencia de flota.En este sentido, lidar es un intento de cortar el camino. Evita la tarea fundamental de la visión artificial, cuya solución es necesaria para la conducción autónoma. Da una falsa sensación de progreso. Lidar solo es bueno para demostraciones rápidas.El progreso es proporcional a la frecuencia de colisiones con situaciones complejas en el mundo real.
 Si quisiera ajustar todo lo que se dijo en una diapositiva, se vería así. Necesitamos sistemas de nivel 4-5 que puedan manejar todas las situaciones posibles en el 99.9999% de los casos. La búsqueda de los últimos nueve será difícil y muy difícil. Esto requerirá un sistema de visión artificial muy potente.Aquí se muestran imágenes que puede encontrar en el camino hacia los lugares decimales apreciados. Al principio, solo tienes autos en el futuro, luego estos autos comienzan a verse un poco inusuales, aparecen bicicletas en ellos, autos en autos. Luego te encuentras con eventos realmente raros, como autos invertidos o incluso autos en un salto. Encontramos mucho de todo en los datos provenientes de la flota.Y vemos estos eventos raros con mucha más frecuencia que nuestros competidores. Esto determina la velocidad con la que podemos obtener datos y solucionar problemas mediante el entrenamiento de redes neuronales. La velocidad del progreso es proporcional a la frecuencia con la que te enfrentas a situaciones difíciles en el mundo real. Y los encontramos con más frecuencia que nadie. Por lo tanto, nuestro piloto automático es mejor que otros.
Si quisiera ajustar todo lo que se dijo en una diapositiva, se vería así. Necesitamos sistemas de nivel 4-5 que puedan manejar todas las situaciones posibles en el 99.9999% de los casos. La búsqueda de los últimos nueve será difícil y muy difícil. Esto requerirá un sistema de visión artificial muy potente.Aquí se muestran imágenes que puede encontrar en el camino hacia los lugares decimales apreciados. Al principio, solo tienes autos en el futuro, luego estos autos comienzan a verse un poco inusuales, aparecen bicicletas en ellos, autos en autos. Luego te encuentras con eventos realmente raros, como autos invertidos o incluso autos en un salto. Encontramos mucho de todo en los datos provenientes de la flota.Y vemos estos eventos raros con mucha más frecuencia que nuestros competidores. Esto determina la velocidad con la que podemos obtener datos y solucionar problemas mediante el entrenamiento de redes neuronales. La velocidad del progreso es proporcional a la frecuencia con la que te enfrentas a situaciones difíciles en el mundo real. Y los encontramos con más frecuencia que nadie. Por lo tanto, nuestro piloto automático es mejor que otros. Gracias
Preguntas y respuestas
Pregunta: ¿Cuántos datos recopila en promedio de cada automóvil?
Andrew: No se trata solo de la cantidad de datos, se trata de la diversidad. En algún momento, ya tiene suficientes imágenes de conducción a lo largo de la carretera, la red las comprende, ya no es necesario. Por lo tanto, estamos estratégicamente enfocados en obtener los datos correctos. Y nuestra infraestructura, con un análisis bastante complicado, nos permite obtener los datos que necesitamos en este momento. No se trata de grandes cantidades de datos, se trata de datos muy bien seleccionados.
Pregunta: Me pregunto cómo va a resolver el problema de cambiar de carril. Cada vez que trato de reconstruir en una corriente densa, me cortan. El comportamiento humano se está volviendo irracional en las carreteras de Los Ángeles. El piloto automático quiere conducir de forma segura, y casi tienes que hacerlo de forma insegura.
Andrew: hablé sobre el motor de datos como entrenamiento de redes neuronales. Pero hacemos lo mismo a nivel de software. Todos los parámetros que afectan la elección, por ejemplo, cuándo reconstruir, qué agresivo. También los cambiamos en modo sombra y observamos qué tan bien funcionan y ajustamos la heurística. De hecho, diseñar tales heurísticas para el caso general es una tarea difícil. Creo que tendremos que usar el entrenamiento de la flota para tomar tales decisiones. ¿Cuándo la gente cambia de carril? ¿En que escenarios? ¿Cuándo sienten que cambiar de carril no es seguro? Veamos una gran cantidad de datos y enseñemos al clasificador de aprendizaje automático a distinguir cuándo la reconstrucción es segura. Estos clasificadores podrán escribir un código mucho mejor que las personas, ya que dependen de una gran cantidad de datos sobre el comportamiento de los controladores.
Ilon: Probablemente, tendremos el modo "tráfico en Los Ángeles". En algún lugar después del modo Mad Max. Sí, Mad Max lo pasaría mal en Los Ángeles.
Andrei tendrá que comprometerse. No desea crear situaciones inseguras, pero quiere llegar a casa. Y los bailes que las personas realizan al mismo tiempo, es muy difícil de programar. Creo que el correcto es el aprendizaje automático. Donde solo miramos las muchas formas en que las personas hacen esto y tratamos de imitarlas.
Ilon: Ahora somos un poco conservadores y, a medida que crezca nuestra confianza, será posible elegir un régimen más agresivo. Los usuarios podrán elegirlo. En modos agresivos, cuando se intenta cambiar de carril en un atasco de tráfico, existe una pequeña posibilidad de arrugar el ala. Sin riesgo de accidente grave. Tendrá la opción de elegir si está de acuerdo con una probabilidad distinta de cero de aplastar el ala. Desafortunadamente, esta es la única forma de quedarse atrapado en el tráfico en la carretera.
Pregunta: ¿Podría suceder en uno de esos nueve después del punto decimal que lidar será útil? La segunda pregunta es, si los lidares realmente no valen nada, ¿qué pasará con aquellos que construyen sus decisiones sobre ellos?
Ilon: Todos se librarán de los lidares, este es mi pronóstico, puedes escribirlo. Debo decir que no odio lidar tanto como parece. SpaceX Dragon usa el LIDAR para moverse a la ISS y al muelle. SpaceX ha desarrollado su propio lidar desde cero para esto. Yo personalmente dirigí este proyecto porque lidar tiene sentido en este escenario. Pero en los autos es muy estúpido. Es costoso y no necesario. Y, como Andrei dijo, tan pronto como manejes el video, el lidar se volverá inútil. Tendrá equipo costoso que es inútil para el automóvil.
Tenemos un radar de avance. Es económico y útil, especialmente en condiciones de poca visibilidad. Niebla, polvo o nieve, el radar puede ver a través de ellos. Si va a utilizar la generación activa de fotones, no use la longitud de onda de la luz visible. Porque, al tener una óptica pasiva, ya te has ocupado de todo en el espectro visible. Ahora es mejor usar una longitud de onda con buenas propiedades de penetración, como el radar. Lidar es simplemente la generación activa de fotones en el espectro visible. Quiere generar fotones activamente, hágalo fuera del espectro visible. Usando 3.8 mm versus 400-700 nm, podrá ver en condiciones climáticas adversas. Por lo tanto, tenemos un radar. Además de doce sensores ultrasónicos para el entorno inmediato. El radar es más útil en la dirección del movimiento, porque es directamente que te estás moviendo muy rápido.
Hemos planteado el tema de los sensores muchas veces. ¿Hay suficientes de ellos? ¿Tenemos todo lo que necesitamos? ¿Necesitas agregar algo más? Hmmm Suficiente
Pregunta: Parece que los autos están haciendo algún tipo de cálculo para determinar qué información enviarle. ¿Se hace esto en tiempo real o se basa en la información almacenada?
Andrey: Los cálculos se hacen en tiempo real en los autos mismos. Transmitimos las condiciones que nos interesan, y los autos hacen todos los cálculos necesarios. Si no lo hicieran, tendríamos que transferir todos los datos seguidos y procesarlos en nuestro back-end. No queremos hacer esto.
Ilon: Tenemos cuatrocientos veinticinco mil autos con HW2.0 +. Esto significa que tienen ocho cámaras, un radar, sensores ultrasónicos y al menos una computadora nVidia. Es suficiente calcular qué información es importante y cuál no. Comprimen información importante y la envían a la red para capacitación. Este es un gran grado de compresión de datos del mundo real.
Pregunta: Tiene esta red de cientos de miles de computadoras, que se asemeja a un poderoso centro de datos distribuido. ¿Ves su aplicación para fines distintos al piloto automático?
Ilon: Supongo que esto podría usarse para otra cosa. Mientras nos centramos en piloto automático. Tan pronto como lo llevemos al nivel correcto, podemos pensar en otras aplicaciones. Para entonces, serán millones o decenas de millones de automóviles con HW3.0 o FSDC.
Pregunta: ¿ Cálculo del tráfico?
Ilon: Sí, tal vez. podría ser algo como AWS (Amazon Web Services).
Pregunta: Soy un piloto de Model 3 en Minnesota, donde hay mucha nieve. La cámara y el radar no pueden ver las marcas viales a través de la nieve. ¿Cómo vas a resolver este problema? ¿Usarás GPS de alta precisión?
Andrew: Ya hoy, el piloto automático se comporta bastante bien en un camino nevado. Incluso cuando las marcas están ocultas, deshilachadas o cubiertas de agua bajo una fuerte lluvia, el piloto automático se comporta relativamente bien. Todavía no hemos manejado específicamente el camino nevado con nuestro motor de datos. Pero estoy seguro de que este problema puede resolverse. Porque en muchas imágenes de un camino nevado, si le preguntas a una persona dónde deberían estar las marcas, él te lo mostrará. La gente acuerda dónde dibujar líneas de marcado. Y si bien las personas pueden aceptar y marcar sus datos, la red neuronal podrá aprender esto y funcionará bien. La única pregunta es si hay suficiente información en la señal original. ¿Suficiente para una persona anotadora? Si la respuesta es sí, entonces la red neuronal funcionará bien.
Ilon: Hay varias fuentes importantes de información en la señal fuente. Entonces marcado, este es solo uno de ellos. La fuente más importante es el camino de entrada. A dónde puedes ir y a dónde no. Más importante que el marcado. El reconocimiento de carreteras funciona muy bien. Creo que, especialmente después del próximo invierno, funcionará increíblemente. Nos preguntaremos cómo puede funcionar esto tan bien. Esto es una locura.
Andrew: Ni siquiera se trata de la capacidad de las personas para marcar. Mientras usted, una persona, pueda superar esta sección del camino. La flota aprenderá de ti. Sabemos cómo condujo aquí. Y obviamente usaste visión para esto. No vio el marcado, pero utilizó la geometría de toda la escena. Ves cómo se dobla la carretera, cómo se ubican otros autos a tu alrededor. La red neuronal resaltará automáticamente todos estos patrones, solo necesita obtener suficientes datos sobre cómo las personas superan tales situaciones.
Ilon: Es muy importante no apegarse al GPS. El error del GPS puede ser muy significativo. Y la situación real del tráfico puede ser impredecible. Puede ser una reparación de carretera o un desvío. Si el automóvil depende demasiado del GPS, esta es una mala situación. Estás pidiendo problemas. El GPS es bueno para usar solo como una pista.
Pregunta: Algunos de sus competidores hablan sobre cómo usan mapas de alta definición para mejorar la percepción y la planificación de rutas. ¿Utiliza algo similar en su sistema, ve algún beneficio en esto? ¿Hay áreas donde le gustaría tener más datos, no de la flota, sino algo así como tarjetas?
Ilon: Creo que los mapas de alta resolución son una muy mala idea. El sistema se vuelve extremadamente inestable. No se puede adaptar a los cambios si está conectado a GPS y mapas de alta resolución y no le da prioridad a la visión. La visión es lo que debe hacer todo. Mira, el marcado es solo una guía, no lo más importante. Intentamos usar tarjetas de marcado y rápidamente nos dimos cuenta de que se trataba de un gran error. Los abandonamos por completo.
Pregunta: Entender dónde están los objetos y cómo se mueven los autos es muy útil. Pero, ¿qué pasa con el aspecto de la negociación? Durante el estacionamiento, en las rotondas y en otras situaciones en las que interactúa con otros automóviles que las personas conducen. Es más un arte que una ciencia.
Ilon: Funciona bastante bien. Si observa situaciones con reordenamientos, etc., el piloto automático normalmente se las arregla.
Andrew: Ahora usamos mucho aprendizaje automático para crear una idea del mundo real. Además de esto, tenemos un programador y controlador y muchas heurísticas sobre cómo conducir, cómo tener en cuenta otros automóviles, etc. Y al igual que en el reconocimiento de patrones, hay muchos casos no estándar aquí, es como un juego de halcones y palomas, que juegas con otras personas. Estamos seguros de que, en última instancia, utilizaremos la capacitación basada en la flota para resolver este problema. La heurística de escritura a mano se apoya rápidamente en una meseta.
Pregunta: ¿Tienes un modo de pelotón? ¿El sistema es capaz de esto?
Andrei: Estoy absolutamente seguro de que podríamos hacer un régimen así. Pero, de nuevo, si solo entrena la red para imitar a las personas. Las personas se apegan y conducen frente al automóvil y la red recuerda este comportamiento. Hay una especie de magia en él, todo sucede solo. Los diferentes problemas se reducen a uno, solo recopile el conjunto de datos y úselo para entrenar la red neuronal.
Ilon: tres pasos para la conducción autónoma. El primero es simplemente implementar esta funcionalidad. El segundo es llevarlo a tal punto que una persona en un automóvil no necesite prestar atención a la carretera. Y el tercero es mostrar el nivel de confiabilidad que convence a los reguladores. Estos son tres niveles. Esperamos alcanzar el primer nivel este año. Y esperamos, en algún momento del segundo trimestre del próximo año, alcanzar un nivel de confianza cuando una persona ya no necesita mantener las manos en el volante y mirar la carretera. Después de eso, esperamos la aprobación regulatoria en al menos algunas jurisdicciones para fines del próximo año. Estas son mis expectativas.
Para los camiones, es probable que el régimen de convoyes sea aprobado por los reguladores antes que cualquier otra cosa. Quizás para viajes largos puede usar un conductor en el auto principal y 4 camiones Semi detrás de él en el modo de convoy.
Pregunta: Estoy muy impresionado con la mejora del piloto automático. La semana pasada conducía en el carril derecho de la autopista, y había una entrada. Mi Modelo 3 fue capaz de detectar dos autos que ingresaban a la carretera y disminuyó la velocidad para que uno se construyera silenciosamente frente a mí y el otro detrás de mí. Entonces pensé, maldita sea, esto es una locura, no sabía que mi Modelo 3 es capaz de eso.
Pero esa misma semana conducía nuevamente en el carril derecho, y hubo un estrechamiento, mi carril derecho se fusionó con el izquierdo. Y mi Modelo 3 no pudo reaccionar correctamente, tuve que intervenir. ¿Puedes decir cómo Tesla puede resolver este problema?
Andrew: hablé sobre la infraestructura de recopilación de datos. Si intervino, lo más probable es que tengamos este clip. Se metió en las estadísticas, por ejemplo, con qué probabilidad fluimos correctamente en la corriente. Observamos estos números, miramos los clips y vemos lo que está mal. Y estamos tratando de corregir el comportamiento para lograr una mejora en comparación con los puntos de referencia.
Ilon: Bueno, tenemos otra presentación sobre software. Tuvimos una presentación sobre el equipo con Pete, luego las redes neuronales con Andrey, y ahora sigue el software con Stuart.
...