Nuestro equipo en poco tiempo pasó de una docena de empleados a una unidad completa de casi 200 personas y queremos compartir algunos hitos de este camino. Además, discutiremos quién se necesita exactamente en Big Data en este momento y cuál es el umbral de entrada real.

Receta para el éxito en un nuevo campo
Trabajar con Big Data es un área tecnológica relativamente nueva que, como todo, atraviesa el ciclo de crecimiento a medida que se desarrolla.
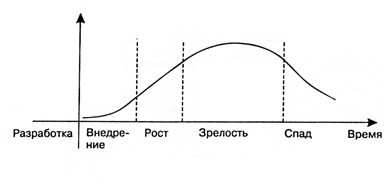
Desde el punto de vista de un especialista en particular, el trabajo en el campo tecnológico en cada etapa de este ciclo tiene sus ventajas y desventajas.
Etapa 1. ImplementaciónEn la primera etapa, esta es una creación de las unidades de I + D, que todavía no proporciona ganancias reales.
De los profesionales: se invierte mucho dinero en ello. Junto con las inversiones, crecen las esperanzas de resolver tareas previamente inaccesibles y devolver inversiones.
Contras: cualquier tecnología, por prometedora que parezca al principio, tiene sus propias limitaciones: no se puede utilizar para eliminar todos los problemas existentes. Estos límites se revelan a medida que se llevan a cabo experimentos con una nueva idea, lo que lleva a un enfriamiento del interés por la tecnología después del llamado "pico de altas expectativas".
Etapa 2. CrecimientoEl despegue real será solo para la tecnología que superará el posterior vacío de decepción debido a sus capacidades reales, y no al ruido de marketing.
Pros: en esta etapa, la tecnología atrae inversiones a largo plazo: no solo dinero, sino también el tiempo de especialistas en el mercado laboral. Cuando queda claro que esto no es solo una exageración, sino un nuevo enfoque o incluso un segmento de mercado, es hora de que los especialistas se integren en la "tendencia". Este es un momento ideal para dominar tecnologías prometedoras en términos de despegue profesional.
Contras: en esta etapa, la tecnología aún está poco documentada.
Etapa 3. MadurezLa tecnología madura es el verdadero caballo de batalla del mercado.
Pros: a medida que envejece, aumenta el volumen de documentación acumulada, aparecen entrenamientos y cursos, se hace más fácil ingresar a la tecnología.
Contras: al mismo tiempo, la competencia en el mercado laboral está creciendo.
Etapa 4. RecesiónLa etapa de declive (puesta del sol) ocurre en todas las tecnologías, aunque continúan funcionando.
Pros: en este punto, la tecnología ya está completamente descrita, los límites son claros, una gran cantidad de documentación, los cursos están disponibles.
Contras: desde el punto de vista de adquirir nuevos conocimientos y perspectivas, ya no es tan atractivo. De hecho, esto es un acompañamiento.
La etapa de crecimiento es la más atractiva para todos los que desean comenzar a trabajar en un nuevo campo tecnológico: tanto para profesionales jóvenes como para profesionales ya establecidos de segmentos relacionados.
El desarrollo de big data ahora está en esta etapa. Las altas expectativas se quedaron atrás. Las empresas ya han demostrado que los grandes datos pueden generar ganancias y, por lo tanto, hay una meseta de productividad por delante. Este momento brinda una excelente oportunidad a los especialistas en el mercado laboral.
Nuestra historia big dataLa introducción de la tecnología en cualquier empresa individual esencialmente repite el ciclo general de crecimiento. Y nuestra experiencia aquí es bastante típica.
Comenzamos a construir nuestro equipo de big data en X5 hace un año y medio. Entonces era solo un pequeño grupo de especialistas clave, y ahora somos casi 200 de nosotros.
Nuestros equipos de proyecto pasaron por varias etapas evolutivas, durante las cuales obtuvimos una comprensión más profunda de los roles y tareas. Como resultado, tenemos nuestro propio formato de equipo. Nos decidimos por el enfoque ágil. La idea principal es que el equipo tenía todas las competencias para resolver el problema y no es tan importante cómo se distribuyen exactamente entre los especialistas. En base a esto, la composición de los roles de los equipos se formó gradualmente, incluso teniendo en cuenta el crecimiento de la tecnología. Y ahora tenemos:
- Propietario del producto (propietario del producto): comprende el área temática, formula una idea comercial general y predice cómo se puede monetizar.
- Analista de negocios (analista de negocios): está trabajando en esta tarea.
- Calidad de datos (especialista en calidad de datos): comprueba si los datos existentes pueden utilizarse para resolver el problema.
- Directamente Ciencia de datos / Analista de datos (científico de datos / analista de datos): crea modelos matemáticos (existen diferentes subespecies, incluidas aquellas que funcionan solo con hojas de cálculo).
- Gerentes de prueba.
- Desarrolladores
En nuestro caso, la infraestructura y los datos son utilizados por todos los equipos, y los siguientes roles se implementan para los equipos como servicios: - Infraestructura
- ETL (comando de carga de datos).
 ¿Cómo llegamos al equipo soñado?
¿Cómo llegamos al equipo soñado?
Dream-not´dream, pero, como dije, la composición de los equipos cambió debido a la madurez del análisis de big data y su penetración en la vida diaria de X5 y nuestras redes de distribución.
"Inicio rápido" : roles mínimos, velocidad máxima
El primer equipo incluyó solo dos roles:
- El propietario del producto propuso un modelo, hizo recomendaciones.
- Analista de datos: estadísticas recopiladas basadas en datos existentes.
Todo se planeó rápidamente y se implementó manualmente en el negocio.
"¿Creemos que sí?" - aprendimos a entender el negocio y producir el resultado más útil
Han aparecido nuevos roles para interactuar con los negocios:
- Analista de negocios: requisitos de proceso descritos.
- Calidad de los datos: realizó una verificación de la coherencia de los datos.
- Dependiendo de la tarea, el analista de datos / científico de datos analizó las estadísticas de datos / realizó el cálculo del modelo en la estación de trabajo local.
"Necesita más recursos" : las tareas de cálculo locales se trasladaron al clúster y comenzaron a tocar sistemas externos
Para admitir la escala requerida:
- La infraestructura que levantó el servidor HADOOP.
- Desarrolladores: implementaron la integración con sistemas de TI externos y comprobaron las interfaces de usuario en esta etapa.
Ahora Data Analyst / Data Scientist podría verificar varias opciones para calcular el modelo en el clúster, aunque la implementación manual en el negocio aún se conserva.
“Las cargas continúan creciendo” : aparecen nuevos datos, se requieren nuevas capacidades para procesarlos
Estos cambios no se pudieron reflejar en el equipo:
- Infraestructura desarrolló el clúster HADOOP bajo cargas crecientes.
- El equipo de ETL comenzó a descargar y actualizar datos regularmente.
- Pruebas funcionales ha aparecido.
"Automatización en todo" : la tecnología ha echado raíces, es hora de automatizar la implementación del negocio
En esta etapa, DevOps apareció en el equipo, que configuró el ensamblaje automático, las pruebas y la instalación de la funcionalidad.
Pensamientos clave sobre el trabajo en equipo1. No es un hecho que todo saldría bien si no hubiéramos tenido los especialistas correctos desde el principio, alrededor de los cuales podríamos construir un equipo. Este es el esqueleto en el que los músculos comenzaron a crecer.
2. El mercado de Big Data es completamente ecológico, por lo que no hay suficientes especialistas "preparados" para cada uno de los roles. Por supuesto, sería muy conveniente reclutar a toda una división de seniors, pero, obviamente, tales equipos "estrella" no se pueden construir mucho. Decidimos no perseguir solo al personal "confeccionado". Como mencionamos, adhiriéndonos a ágil, solo deberíamos preocuparnos de que el equipo en su conjunto tenga las competencias para resolver un problema en particular. En otras palabras, podemos tomar (y tomar) en un equipo profesionales y principiantes con una cierta base técnica y matemática, de modo que juntos formen un conjunto de competencias necesarias para lograr los resultados deseados.
3. Cada uno de los roles implica una comprensión de los principios de trabajar con big data, lo que requiere, sin embargo, su profundidad de comprensión. La mayor variabilidad de roles que tienen analogías directas en el desarrollo clásico: probadores, analistas, etc. Para ellos, hay tareas en las que pertenecer a big data es casi invisible, y tareas en las que debe profundizar un poco más. De una forma u otra, para comenzar una carrera, es suficiente una cierta experiencia, una comprensión de TI, un deseo de aprender y algunos conocimientos teóricos sobre las herramientas utilizadas (que se pueden obtener leyendo los artículos).
4. La práctica ha demostrado que, a pesar del hecho de que la tecnología es bien conocida y a muchos les gustaría hacerlo, lejos de todo especialista que sea adecuado para comenzar una carrera en Big Data (y le gustaría trabajar allí en el fondo) realmente trata de venir aquí .
Muchos candidatos excelentes creen que trabajar en equipos BigData es estrictamente ciencia de datos. ¿Qué es un cambio cardinal de actividad con un alto umbral de entrada? Sin embargo, subestiman sus competencias o simplemente no saben que las personas de varios perfiles tienen gran demanda en big data, y sería más fácil comenzar una carrera en un rol alternativo, cualquiera de los anteriores.
a. De hecho, para comenzar a trabajar en un equipo mixto en muchos roles, no necesita una educación especializada limitada en el campo de big data.
b. Expandimos activamente el equipo, adhiriéndonos a la idea de construir unidades estructurales mixtas. Y lo más interesante es que las personas que llegaron a nuestras tareas, que nunca antes habían trabajado con Big Data, se arraigaron perfectamente en la empresa, habiendo hecho frente a las tareas. Pudieron aprender rápidamente la práctica de big data.
5. Sin siquiera tener mucha experiencia, puede sumergirse más profundamente, aprender los idiomas y herramientas necesarios, y estar motivado para crecer en este segmento con el fin de abordar tareas más estratégicas dentro del proyecto. Y la experiencia acumulada ayuda a cambiar a aquellos roles donde se requiere conocimiento en big data y comprender la lógica de esta dirección. Por cierto, en este sentido, un equipo mixto ayuda mucho a acelerar el desarrollo.
¿Cómo entrar en BigData?
En nuestro caso, la idea de equipos equilibrados de especialistas de diferentes niveles "despegó": el grupo ya ha implementado más de un proyecto interno. Me parece que con la escasez de personal ya preparado y un aumento en la necesidad comercial de tales equipos, otras compañías llegarán al mismo escenario.
Si realmente desea elegir esta dirección, sumergirse en Data Sciense - Kaggle, ODS y otros recursos especializados lo ayudarán. Además, si en el futuro cercano no se ve a sí mismo en el rol de Científico de Datos, pero está interesado en la dirección en sí mismo, ¡todavía es necesario en Big Data!
Para aumentar su valor:
- Actualiza tus conocimientos de matemáticas. Para resolver problemas comunes de big data, no se requiere un doctorado, pero aún se necesitan conocimientos básicos en matemáticas superiores. Al comprender los mecanismos subyacentes a las estadísticas, será más fácil para usted conocer los procesos;
- Elija los roles más cercanos a su especialidad actual. Descubra qué desafíos enfrentará en este rol (y en una compañía en particular, a dónde quiere ir). Y si ha resuelto problemas similares anteriormente, debe enfatizarlos en el currículum;
- Las herramientas específicas para el rol seleccionado son muy importantes, incluso si parece que esto no es relevante para Big Data. Por ejemplo, al desarrollar nuestra solución interna, resultó que necesitamos muchos desarrolladores front-end que trabajen con interfaces complejas;
- recuerde que el mercado se está desarrollando activamente. Alguien está construyendo y bombeando equipos dentro, mientras que alguien espera encontrar especialistas ya preparados en el mercado laboral. Si es un principiante, intente formar un equipo fuerte, donde habrá una oportunidad de obtener conocimientos adicionales.
PD: Por cierto, en este momento seguimos creciendo activamente y estamos buscando un
ingeniero de datos ,
un especialista en pruebas , un
desarrollador de React y un especialista en
UI / UX . Del 10 al 11 de mayo, discutiremos la inclusión del trabajo en # bigdatax5 con todos en nuestro stand en
DataFest .