Existen varios enfoques para comprender una máquina de habla coloquial: el enfoque clásico de tres componentes (incluye un componente de reconocimiento de voz, un componente de comprensión del lenguaje natural y un componente responsable de una cierta lógica de negocios) y un enfoque End2End que involucra cuatro modelos de implementación: directo, colaborativo, multietapa y multitarea . Consideremos todos los pros y los contras de estos enfoques, incluidos los basados en los experimentos de Google, y analicemos en detalle por qué el enfoque End2End resuelve los problemas del enfoque clásico.

Le damos la palabra al desarrollador líder del centro AI MTS Nikita Semenov.
Hola Como prefacio, quiero citar a los conocidos científicos Jan Lekun, Joshua Benjio y Jeffrey Hinton: estos son tres pioneros de la inteligencia artificial que recientemente recibieron uno de los premios más prestigiosos en el campo de la tecnología de la información: el Premio Turing. En uno de los números de la revista Nature en 2015, lanzaron un artículo muy interesante "Aprendizaje profundo", en el que había una frase interesante: "El aprendizaje profundo vino con la promesa de su capacidad para manejar señales sin necesidad de funciones hechas a mano". Es difícil traducirlo correctamente, pero el significado es más o menos así: "El aprendizaje profundo ha llegado con la promesa de la capacidad de hacer frente a las señales en bruto sin la necesidad de la creación manual de signos". En mi opinión, para los desarrolladores este es el principal motivador de todos los existentes.
Enfoque clásico
Entonces, comencemos con el enfoque clásico. Cuando hablamos de entender hablar con una máquina, queremos decir que tenemos una determinada persona que quiere controlar algunos servicios con la ayuda de su voz o siente la necesidad de que algún sistema responda a sus comandos de voz con cierta lógica.
¿Cómo se resuelve este problema? En la versión clásica, se utiliza un sistema que, como se mencionó anteriormente, consta de tres componentes grandes: un componente de reconocimiento de voz, un componente para comprender un lenguaje natural y un componente responsable de una cierta lógica comercial. Está claro que al principio el usuario crea una cierta señal de sonido, que cae en el componente de reconocimiento de voz y cambia de sonido a texto. Luego, el texto cae en el componente de comprensión del lenguaje natural, del cual se extrae una cierta estructura semántica, que es necesaria para el componente responsable de la lógica empresarial.
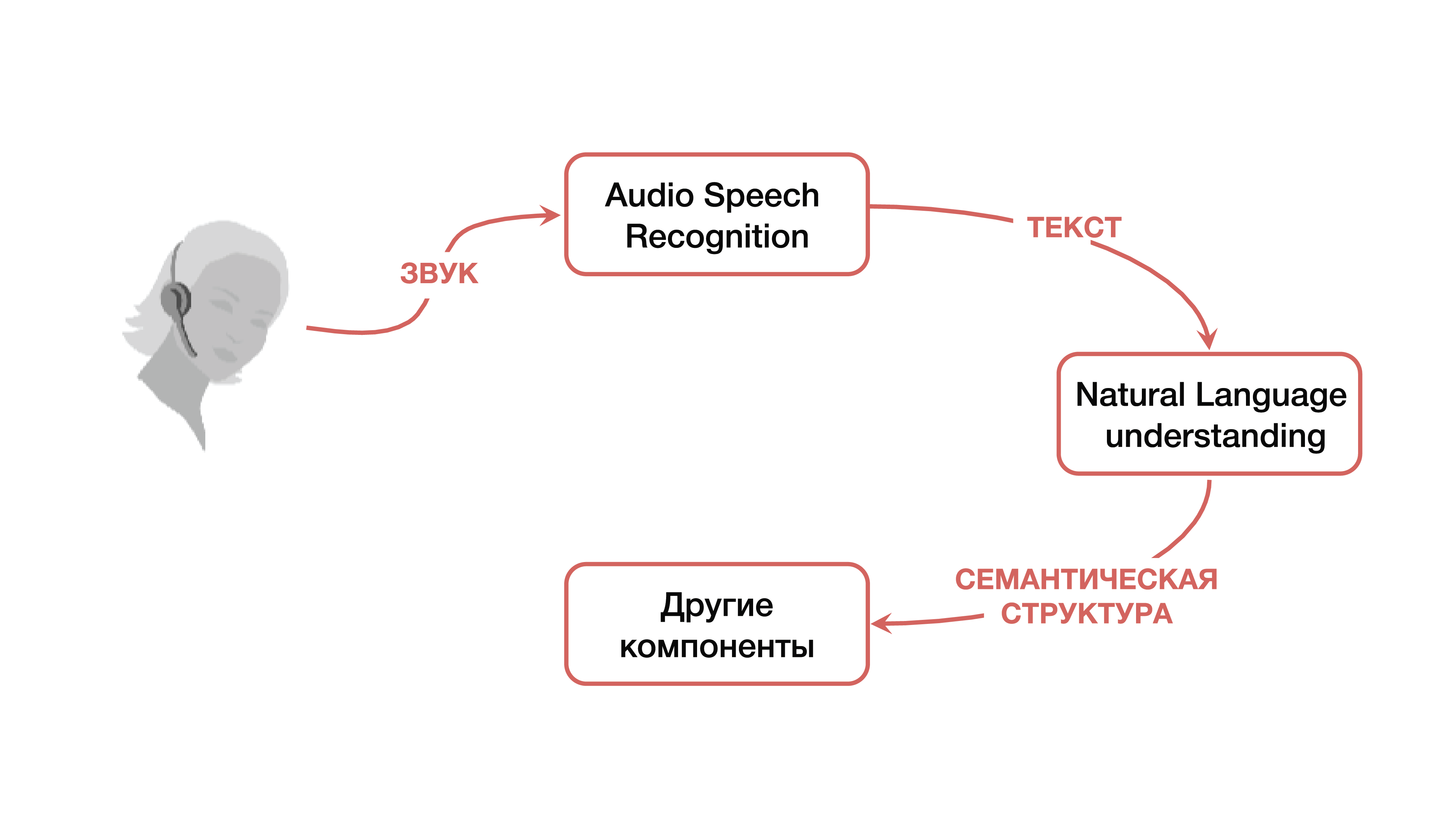
¿Qué es una estructura semántica? Este es un tipo de generalización / agregación de varias tareas en una sola, para facilitar la comprensión. La estructura incluye tres partes importantes: la clasificación del dominio (una determinada definición del tema), la clasificación de la intención (comprender lo que debe hacerse) y la asignación de entidades nombradas para completar las tarjetas que son necesarias para tareas comerciales específicas en la siguiente etapa. Para comprender qué es una estructura semántica, puede considerar un ejemplo simple, que Google cita con mayor frecuencia. Tenemos una simple solicitud: "Por favor, toque alguna canción de algún artista".

El dominio y el tema en esta solicitud es la música; intento: tocar una canción; atributos de la tarjeta "reproducir una canción": qué tipo de canción, qué tipo de artista. Tal estructura es el resultado de entender un lenguaje natural.
Si hablamos de resolver un problema complejo y de varias etapas para comprender el habla coloquial, entonces, como dije, consta de dos etapas: la primera es el reconocimiento de voz, la segunda es la comprensión del lenguaje natural. El enfoque clásico implica una separación completa de estas etapas. Como primer paso, tenemos un cierto modelo que recibe una señal acústica en la entrada, y en la salida, utilizando modelos lingüísticos y acústicos y un léxico, determina la hipótesis verbal más probable de esta señal acústica. Esta es una historia completamente probabilística: puede descomponerse de acuerdo con la conocida fórmula de Bayes y obtener una fórmula que le permita escribir la función de probabilidad de la muestra y utilizar el método de máxima probabilidad. Tenemos una probabilidad condicional de la señal X siempre que la secuencia de palabras W se multiplique por la probabilidad de esta secuencia de palabras.

La primera etapa que atravesamos: obtuvimos una hipótesis verbal de la señal de sonido. Luego viene el segundo componente, que toma esta hipótesis muy verbal e intenta extraer la estructura semántica descrita anteriormente.
Tenemos la probabilidad de la estructura semántica S siempre que la secuencia verbal W esté en la entrada.

¿Qué tiene de malo el enfoque clásico, que consiste en estos dos elementos / pasos, que se enseñan por separado (es decir, primero entrenamos el modelo del primer elemento y luego el modelo del segundo)?
- El componente de comprensión del lenguaje natural funciona con las hipótesis verbales de alto nivel que genera ASR. Este es un gran problema porque el primer componente (ASR en sí) funciona con datos brutos de bajo nivel y genera una hipótesis verbal de alto nivel, y el segundo componente toma la hipótesis como entrada, no los datos brutos de la fuente original, sino la hipótesis que proporciona el primer modelo, y construye su hipótesis sobre la hipótesis de la primera etapa. Esta es una historia bastante problemática, porque se vuelve demasiado "condicional".
- El siguiente problema: no podemos hacer ninguna conexión entre la importancia de las palabras que son necesarias para construir la estructura semántica y lo que el primer componente prefiere al construir nuestra hipótesis verbal. Es decir, si reformula, obtenemos que la hipótesis ya se ha construido. Está construido sobre la base de tres componentes, como dije: la parte acústica (la que entró en la entrada y de alguna manera está modelada), la parte del lenguaje (modela completamente los engramas del lenguaje - la probabilidad de hablar) y el léxico (pronunciación de las palabras). Estas son tres partes grandes que deben combinarse y encontrar algunas hipótesis en ellas. Pero no hay forma de influir en la elección de la misma hipótesis, por lo que esta hipótesis es importante para la siguiente etapa (que, en principio, es el punto de que aprenden completamente por separado y no se afectan entre sí de ninguna manera).
Enfoque End2End
Entendimos cuál es el enfoque clásico, qué problemas tiene. Intentemos resolver estos problemas utilizando el enfoque End2End.
Por End2End nos referimos a un modelo que combinará los diversos componentes en un solo componente. Modelaremos utilizando modelos que consisten en arquitectura codificador-decodificador que contiene módulos de atención (atención). Dichas arquitecturas se utilizan a menudo en problemas de reconocimiento de voz y en tareas relacionadas con el procesamiento de un lenguaje natural, en particular, la traducción automática.
Existen cuatro opciones para la implementación de dichos enfoques que podrían resolver el problema que nos presenta el enfoque clásico: estos son modelos directos, colaborativos, de etapas múltiples y tareas múltiples.
Modelo directo
El modelo directo adquiere los atributos sin procesar de bajo nivel de entrada, es decir señal de audio de bajo nivel, y en la salida obtenemos inmediatamente una estructura semántica. Es decir, obtenemos un módulo: la entrada del primer módulo desde el enfoque clásico y la salida del segundo módulo desde el mismo enfoque clásico. Solo una "caja negra". A partir de aquí hay algunas ventajas y desventajas. El modelo no aprende a transcribir completamente la señal de entrada; esta es una clara ventaja, ya que no necesitamos recolectar marcas grandes y grandes, no necesitamos recolectar mucha señal de audio y luego dársela a los accesores para el marcado. Solo necesitamos esta señal de audio y la estructura semántica correspondiente. Y eso es todo. Esto muchas veces reduce la mano de obra involucrada en el marcado de datos. Probablemente el mayor inconveniente de este enfoque es que la tarea es demasiado complicada para tal "caja negra", que está tratando de resolver dos problemas de manera inmediata y condicional. Primero, dentro de sí mismo, intenta construir algún tipo de transcripción, y luego, a partir de esta transcripción, revela la estructura semántica. Esto plantea una tarea bastante difícil: aprender a ignorar partes de la transcripción. Y es muy dificil. Este factor es un inconveniente bastante grande y colosal de este enfoque.
Si hablamos de probabilidades, este modelo resuelve el problema de encontrar la estructura semántica más probable S a partir de la señal acústica X con los parámetros del modelo θ.
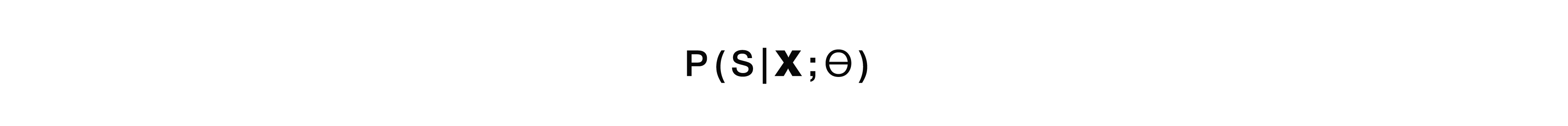
Modelo conjunto
Cual es la alternativa? Este es un modelo colaborativo. Es decir, algún modelo es muy similar a una línea recta, pero con una excepción: el resultado para nosotros ya consiste en secuencias verbales y una estructura semántica simplemente se concatena con ellas. Es decir, en la entrada tenemos una señal de sonido y un modelo de red neuronal, que en la salida ya proporciona transcripción verbal y estructura semántica.
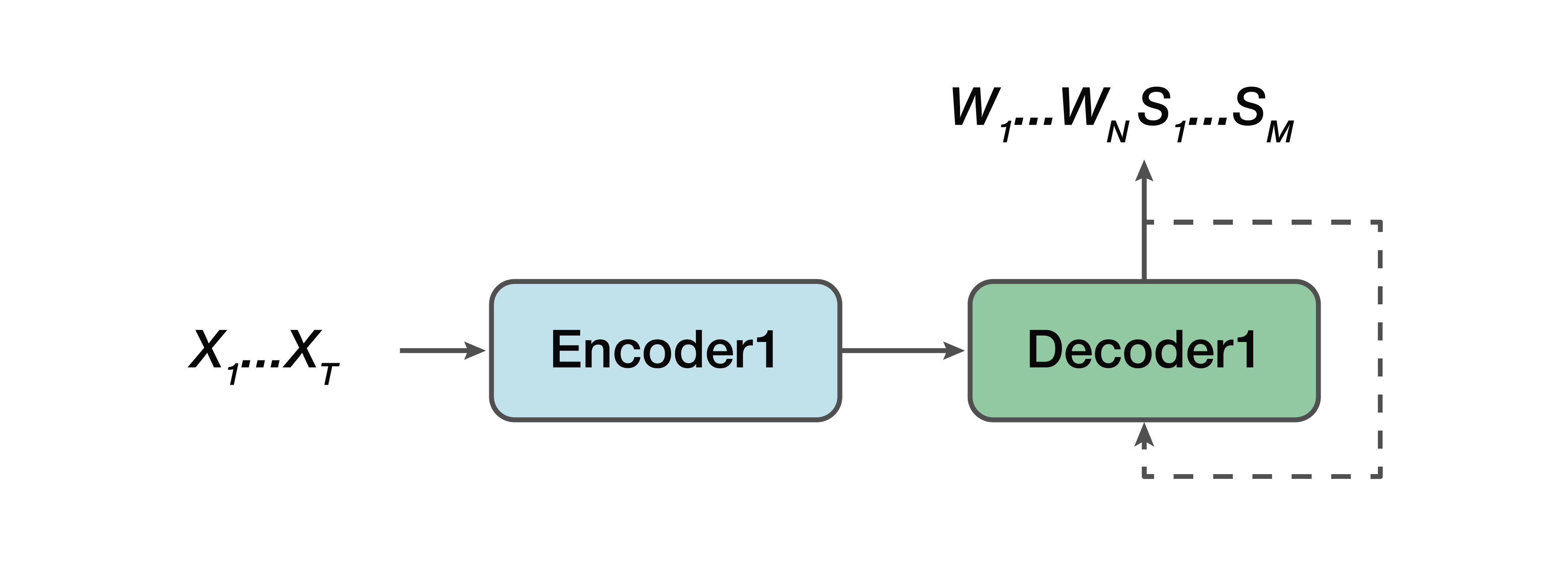
De los profesionales: todavía tenemos un codificador simple, un decodificador simple. El aprendizaje se facilita porque el modelo no intenta resolver dos problemas a la vez, como en el caso del modelo directo. Una ventaja más es que esta dependencia de la estructura semántica de los atributos de sonido de bajo nivel todavía está presente. Porque, de nuevo, un codificador, un decodificador. Y, en consecuencia, una de las ventajas se puede notar que existe una dependencia en la predicción de esta estructura semántica y su influencia directamente en la transcripción misma, lo que no nos convenía en el enfoque clásico.
Nuevamente, necesitamos encontrar la secuencia más probable de palabras W y las estructuras semánticas correspondientes S a partir de la señal acústica X con los parámetros θ.
Modelo multitarea
El siguiente enfoque es un modelo multitarea. Nuevamente, el enfoque codificador-decodificador, pero con una excepción.
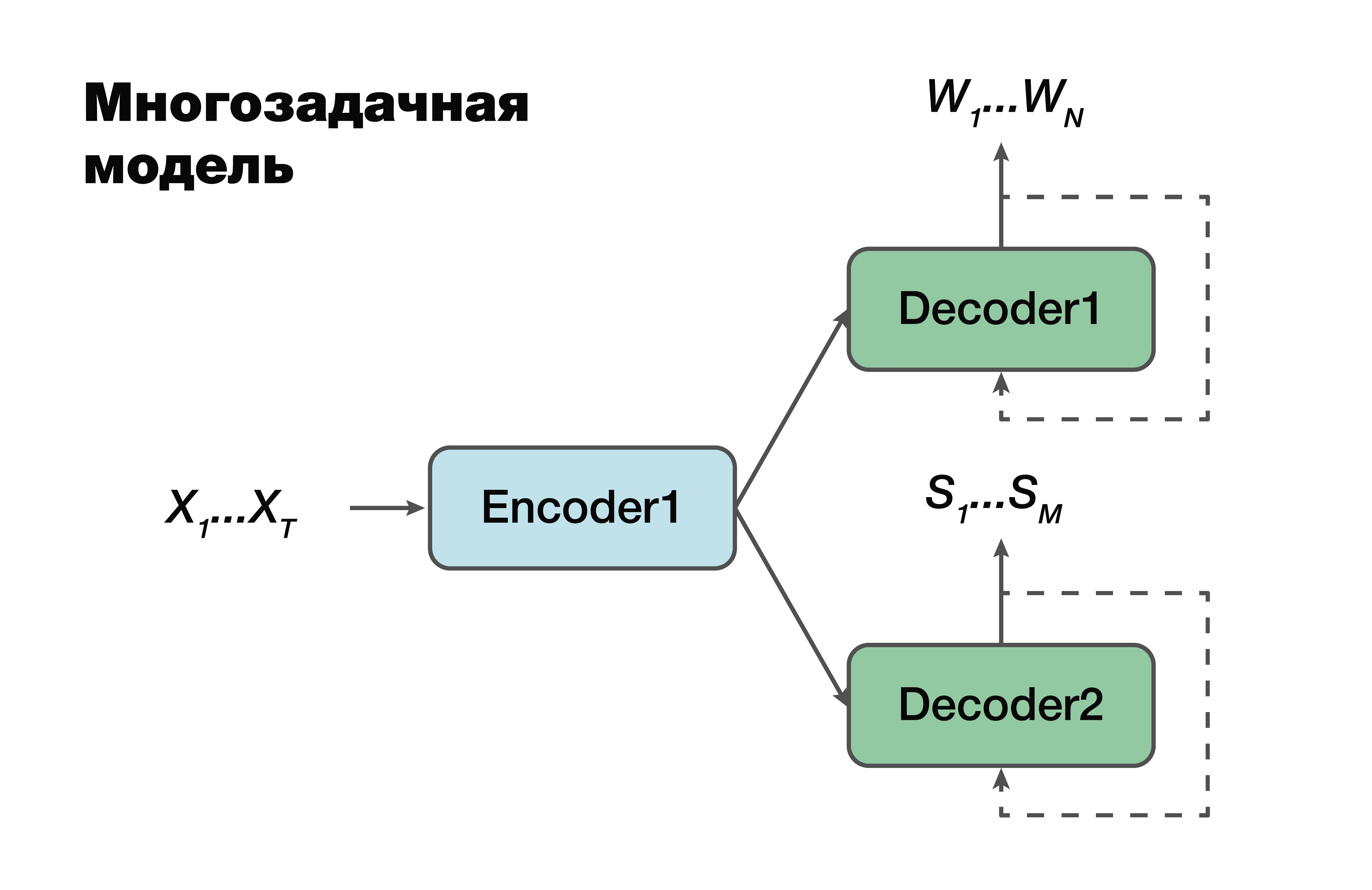
Para cada tarea, es decir, crear una secuencia verbal, crear una estructura semántica, tenemos nuestro propio decodificador que usa una representación oculta común que genera un solo codificador. Un truco muy famoso en el aprendizaje automático, muy utilizado en el trabajo. Resolver dos problemas diferentes a la vez ayuda a buscar dependencias en los datos de origen mucho mejor. Y como consecuencia de esto, la mejor capacidad de generalización, ya que el parámetro óptimo se selecciona para varias tareas a la vez. Este enfoque es más adecuado para tareas con menos datos. Y los decodificadores usan un espacio vectorial oculto en el que crea su codificador.

Es importante tener en cuenta que ya es probable que exista una dependencia de los parámetros de los modelos de codificador y decodificador. Y estos parámetros son importantes.
Modelo de etapas múltiples
En mi opinión, recurrimos al enfoque más interesante: un modelo de etapas múltiples. Si observa con mucho cuidado, puede ver que, de hecho, este es el mismo enfoque clásico de dos componentes con una excepción.
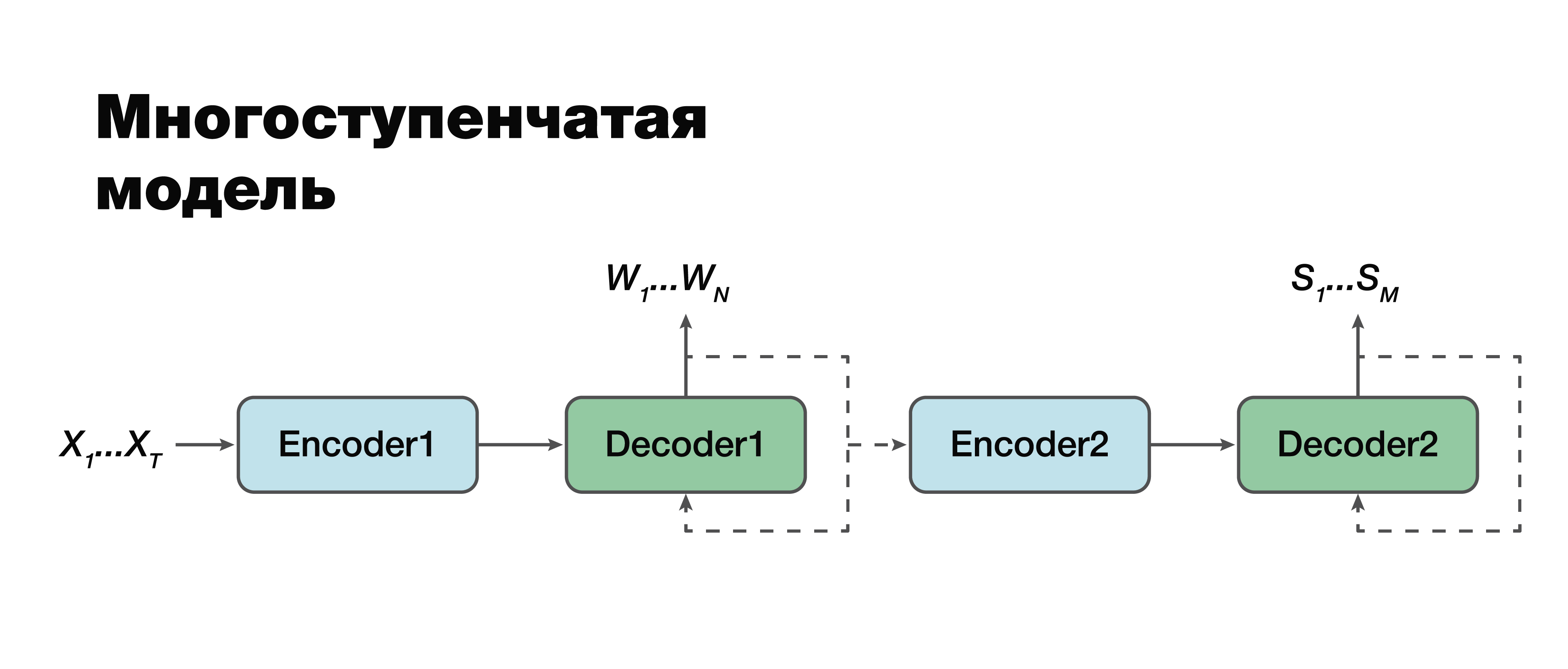
Aquí es posible establecer una conexión entre los módulos y hacerlos de un solo módulo. Por lo tanto, la estructura semántica se considera condicionalmente dependiente de la transcripción. Hay dos opciones para trabajar con este modelo. Podemos entrenar individualmente estos dos mini-bloques: el primer y segundo codificador-decodificador. O combínalos y entrena ambas tareas al mismo tiempo.
En el primer caso, los parámetros para las dos tareas no están relacionados (podemos entrenar usando datos diferentes). Supongamos que tenemos un gran cuerpo de sonido y las correspondientes secuencias verbales y transcripciones. Los “manejamos”, entrenamos solo la primera parte. Nos metemos en una buena simulación de transcripción. Luego tomamos la segunda parte, entrenamos en otro caso. Nos conectamos y obtenemos una solución que en este enfoque es 100% consistente con el enfoque clásico, porque tomamos y capacitamos por separado la primera parte y por separado la segunda. Y luego entrenamos el modelo conectado en el caso, que ya contiene tríadas de datos: una señal de audio, la transcripción correspondiente y la estructura semántica correspondiente. Si tenemos un edificio así, podemos volver a entrenar el modelo, entrenado individualmente en edificios grandes, para nuestra pequeña tarea específica y obtener la máxima ganancia en precisión de una manera tan complicada. Este enfoque nos permite tener en cuenta la importancia de las diferentes partes de la transcripción y su influencia en la predicción de la estructura semántica
teniendo en cuenta los errores de la segunda etapa en la primera.
Es importante tener en cuenta que la tarea final es muy similar al enfoque clásico con solo una gran diferencia: el segundo término de nuestra función, el logaritmo de la probabilidad de la estructura semántica, siempre que la señal acústica de entrada X también dependa de los parámetros del
modelo de
la primera etapa .

También es importante tener en cuenta aquí que el segundo componente depende de los parámetros del primer y segundo modelo.
Metodología para evaluar la precisión de los enfoques.
Ahora vale la pena decidir sobre la metodología para evaluar la precisión. ¿Cómo, de hecho, medir esta precisión para tener en cuenta las características que no nos convienen en el enfoque clásico? Hay etiquetas clásicas para estas tareas separadas. Para evaluar los componentes de reconocimiento de voz, podemos tomar la clásica métrica WER. Esta es una tasa de error de Word. Consideramos, de acuerdo con una fórmula no muy complicada, el número de inserciones, sustituciones, permutaciones de la palabra y las dividimos por el número de todas las palabras. Y obtenemos una cierta característica estimada de la calidad de nuestro reconocimiento. Para una estructura semántica, por componentes, simplemente podemos considerar la puntuación F1. Esta también es una métrica clásica para el problema de clasificación. Aquí todo más o menos está claro. Hay plenitud, hay precisión. Y esto es solo una media armónica entre ellos.
Pero surge la pregunta de cómo medir la precisión cuando la transcripción de entrada y el argumento de salida no coinciden o cuando la salida son datos de audio. Google ha propuesto una métrica que tendrá en cuenta la importancia de predecir el primer componente del reconocimiento de voz al evaluar el efecto de este reconocimiento en el segundo componente. Lo llamaron Arg WER, es decir, pesa WER sobre las entidades de estructura semántica.
Tome la solicitud: "Configure la alarma por 5 horas". Esta estructura semántica contiene un argumento como "cinco horas", un argumento del tipo "fecha y hora". Es importante comprender que si el componente de reconocimiento de voz produce este argumento, entonces la métrica de error de este argumento, es decir, WER, es 0%. Si este valor no corresponde a cinco horas, la métrica tiene un 100% de WER. Por lo tanto, simplemente consideramos el valor promedio ponderado para todos los argumentos y, en general, obtenemos una determinada métrica agregada que estima la importancia de los errores de transcripción que crean el componente de reconocimiento de voz.
Permítame darle un ejemplo de los experimentos de Google que realizó en uno de sus estudios sobre este tema. Utilizaron datos de cinco dominios, cinco temas: Medios, Media_Control, Productividad, Delight, Ninguno, con la distribución correspondiente de datos en conjuntos de datos de pruebas de capacitación. Es importante tener en cuenta que todos los modelos fueron entrenados desde cero. Se utilizó Cross_entropy, el parámetro de búsqueda de haz fue 8, el optimizador que utilizaron, por supuesto, Adam. Considerado, por supuesto, en una gran nube de su TPU. Cual es el resultado? Estos son números interesantes:
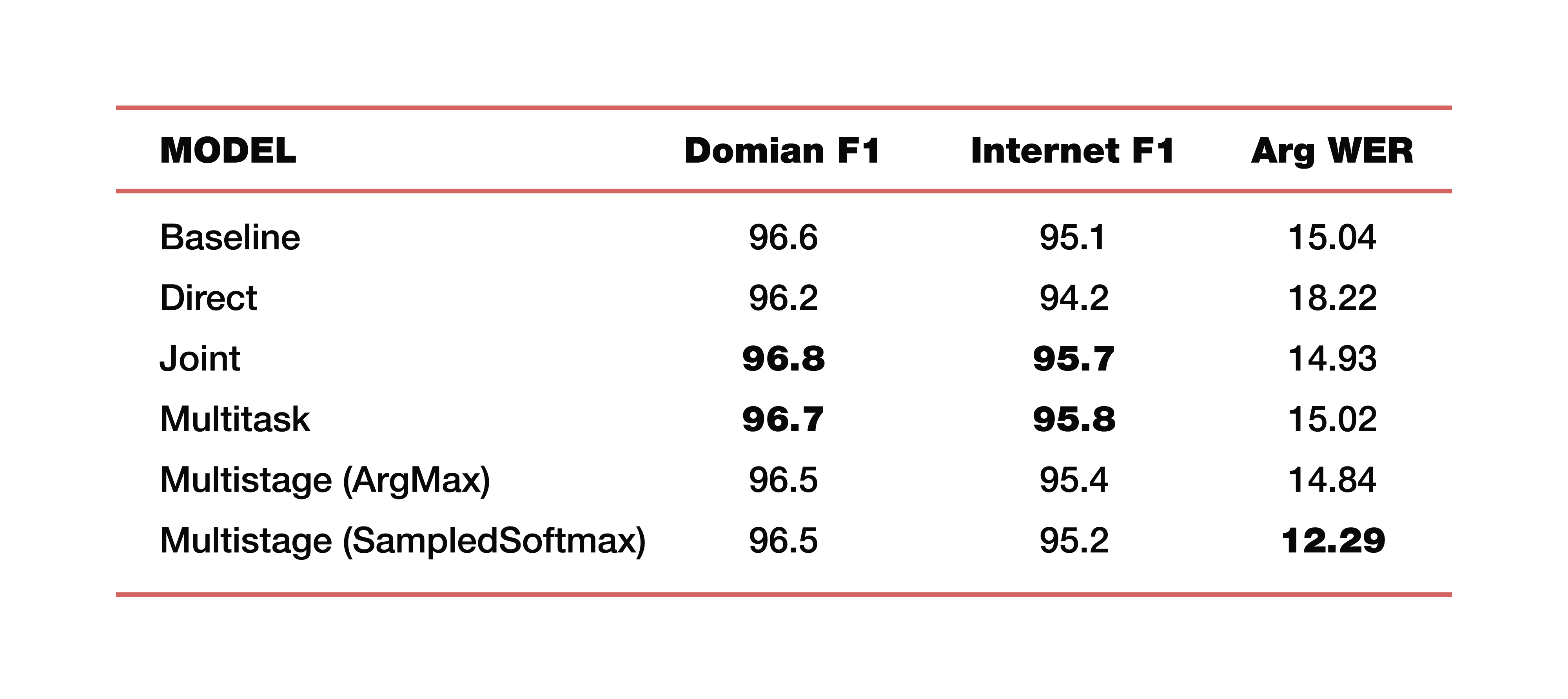
Para comprender, la línea de base es un enfoque clásico que consta de dos componentes, como dijimos al principio. Los siguientes son ejemplos de modelos directos, conectados, multitarea y de etapas múltiples.
¿Cuánto cuestan dos modelos de etapas múltiples? Justo en la unión de la primera y segunda parte, se usaron diferentes capas. En el primer caso, se trata de ArgMax, en el segundo caso, SampedSoftmax.
¿A qué vale la pena prestarle atención? El enfoque clásico pierde en las tres métricas, que son una estimación de la colaboración directa de estos dos componentes. Sí, no estamos interesados en qué tan bien se realiza la transcripción allí, solo estamos interesados en qué tan bien funciona el elemento que predice la estructura semántica. Se evalúa mediante tres métricas: F1 - por tema, F1 - por intención y métrica ArgWer, que es considerada por los argumentos de las entidades. F1 se considera un promedio ponderado entre precisión e integridad. Es decir, el estándar es 100. ArgWer, por el contrario, no es un éxito, es un error, es decir, aquí el estándar es 0.
Vale la pena señalar que nuestros modelos acoplados y multitarea superan por completo a todos los modelos de clasificación por temas e intenciones. Y el modelo, que es de varias etapas, tiene un aumento muy grande en ArgWer total. ¿Por qué es esto importante? Porque en las tareas asociadas con la comprensión del discurso coloquial, la acción final que se realizará en el componente responsable de la lógica de negocios es importante. No depende directamente de las transcripciones creadas por ASR, sino de la calidad de los componentes ASR y NLU que trabajan juntos. Por lo tanto, una diferencia de casi tres puntos en la métrica argWER es un indicador muy bueno, que indica el éxito de este enfoque. También vale la pena señalar que todos los enfoques tienen valores comparables por definición de temas e intenciones.
Daré un par de ejemplos del uso de tales algoritmos para comprender el habla conversacional. Google, cuando habla sobre las tareas de comprender el habla conversacional, observa principalmente las interfaces hombre-computadora, es decir, estos son todo tipo de asistentes virtuales como Google Assistant, Apple Siri, Amazon Alexa, etc. Como segundo ejemplo, vale la pena mencionar un grupo de tareas como Interactive Voice Response. Es decir, esta es una cierta historia que se dedica a la automatización de los centros de llamadas.
Por lo tanto, examinamos los enfoques con la posibilidad de utilizar la optimización conjunta, lo que ayuda al modelo a centrarse en los errores que son más importantes para las SLU. Este enfoque de la tarea de comprender el idioma hablado simplifica enormemente la complejidad general.
Tenemos la oportunidad de llegar a una conclusión lógica, es decir, obtener algún tipo de resultado, sin la necesidad de recursos adicionales como el léxico, los modelos de lenguaje, los analizadores, etc. (es decir, todos estos son factores inherentes al enfoque clásico). La tarea se resuelve "directamente".
De hecho, no puedes parar ahí. Y si ahora hemos combinado los dos enfoques, los dos componentes de una estructura común, entonces podemos aspirar a más. Combine los tres componentes y los cuatro, simplemente continúe combinando esta cadena lógica y "empuje" la importancia de los errores a un nivel más bajo, dada la criticidad que ya existe. Esto nos permitirá aumentar la precisión para resolver el problema.