
Yo vivo en una buena ciudad Pero, como en muchos otros, la búsqueda de un espacio de estacionamiento siempre se convierte en una prueba. Los espacios libres ocupan rápidamente, e incluso si tiene el suyo propio, será difícil para los amigos llamarlo, ya que no tendrán dónde estacionar.
Así que decidí apuntar la cámara por la ventana y usar el aprendizaje profundo para que mi computadora me diga cuándo hay espacio disponible:

Puede sonar complicado, pero en realidad escribir un prototipo funcional con aprendizaje profundo es rápido y fácil. Todos los componentes necesarios ya están allí, solo necesita saber dónde encontrarlos y cómo armarlos.
Así que divirtámonos y escribamos un sistema preciso de notificación de estacionamiento gratuito usando Python y aprendizaje profundo
Descomponiendo la tarea
Cuando tenemos una tarea difícil que queremos resolver utilizando el aprendizaje automático, el primer paso es dividirla en una secuencia de tareas simples. Entonces podemos usar varias herramientas para resolver cada una de ellas. Al combinar varias soluciones simples juntas, obtenemos un sistema que es capaz de hacer algo complejo.
Así es como rompí mi tarea:

La transmisión de video de la cámara web dirigida a la ventana ingresa a la entrada del transportador:

A través de la tubería, transmitiremos cada cuadro del video, uno a la vez.
El primer paso es reconocer todos los espacios de estacionamiento posibles en el marco. Obviamente, antes de que podamos buscar lugares desocupados, necesitamos entender en qué partes de la imagen hay estacionamiento.
Luego, en cada cuadro necesitas encontrar todos los autos. Esto nos permitirá rastrear el movimiento de cada máquina de cuadro a cuadro.
El tercer paso es determinar qué lugares están ocupados por máquinas y cuáles no. Para hacer esto, combine los resultados de los primeros dos pasos.
Finalmente, el programa debe enviar una alerta cuando el espacio de estacionamiento se vuelva libre. Esto estará determinado por los cambios en la ubicación de las máquinas entre los cuadros del video.
Cada uno de estos pasos se puede completar de diferentes maneras utilizando diferentes tecnologías. No existe una única forma correcta o incorrecta de componer este transportador; los diferentes enfoques tendrán sus ventajas y desventajas. Tratemos cada paso con más detalle.
Reconocemos espacios de estacionamiento
Esto es lo que ve nuestra cámara:

Necesitamos escanear de alguna manera esta imagen y obtener una lista de lugares para estacionar:

La solución "en la frente" sería simplemente codificar las ubicaciones de todos los espacios de estacionamiento manualmente en lugar de reconocerlos automáticamente. Pero en este caso, si movemos la cámara o queremos buscar espacios de estacionamiento en otra calle, tendremos que hacer todo el procedimiento nuevamente. Suena más o menos, así que busquemos una forma automática de reconocer los espacios de estacionamiento.
Alternativamente, puede buscar parquímetros en la imagen y asumir que hay un espacio de estacionamiento al lado de cada uno de ellos:

Sin embargo, con este enfoque, no todo es tan sencillo. En primer lugar, no todos los espacios de estacionamiento tienen un parquímetro, y de hecho, estamos más interesados en encontrar espacios de estacionamiento por los que no tenga que pagar. En segundo lugar, la ubicación del parquímetro no nos dice nada sobre dónde está el espacio de estacionamiento, sino que solo nos permite hacer una suposición.
Otra idea es crear un modelo de reconocimiento de objetos que busque marcas de espacio de estacionamiento dibujadas en la carretera:

Pero este enfoque es regular. En primer lugar, en mi ciudad, todas esas marcas son muy pequeñas y difíciles de ver a distancia, por lo que será difícil detectarlas usando una computadora. En segundo lugar, la calle está llena de todo tipo de otras líneas y marcas. Será difícil separar las marcas de estacionamiento de los divisores de carriles y los cruces peatonales.
Cuando encuentre un problema que a primera vista parece difícil, tómese unos minutos para encontrar otro enfoque para resolver el problema, lo que ayudará a sortear algunos problemas técnicos. ¿Qué hay un espacio de estacionamiento? Este es solo un lugar donde un automóvil está estacionado durante mucho tiempo. Quizás no necesitamos reconocer espacios de estacionamiento en absoluto. ¿Por qué no solo reconocemos los autos que permanecen quietos durante mucho tiempo y no asumimos que están parados en el estacionamiento?
En otras palabras, los espacios de estacionamiento se encuentran donde los automóviles permanecen de pie durante mucho tiempo:

Por lo tanto, si podemos reconocer los autos y descubrir cuáles de ellos no se mueven entre cuadros, podemos adivinar dónde están los espacios de estacionamiento. Tan simple como eso: ¡vaya al reconocimiento de máquina!
Reconocer autos
Reconocer autos en un cuadro de video es una tarea clásica de reconocimiento de objetos. Hay muchos enfoques de aprendizaje automático que podríamos utilizar para el reconocimiento. Estos son algunos de ellos en orden de la "vieja escuela" a la "nueva escuela":
- Puede entrenar el detector basado en HOG (histograma de gradientes orientados, histogramas de gradientes direccionales) y recorrerlo a través de la imagen completa para encontrar todos los autos. Este viejo enfoque, que no utiliza el aprendizaje profundo, funciona relativamente rápido, pero no se adapta muy bien a las máquinas ubicadas de diferentes maneras.
- Puede entrenar el detector basado en CNN (Red neuronal convolucional, una red neuronal convolucional) y recorrer toda la imagen hasta encontrar todos los automóviles. Este enfoque funciona exactamente, pero no tan eficientemente, ya que necesitamos escanear la imagen varias veces usando CNN para encontrar todas las máquinas. Y aunque podemos encontrar máquinas ubicadas de diferentes maneras, necesitamos muchos más datos de entrenamiento que para un detector HOG.
- Puede utilizar un nuevo enfoque con aprendizaje profundo como Mask R-CNN, Faster R-CNN o YOLO, que combina la precisión de CNN y un conjunto de trucos técnicos que aumentan enormemente la velocidad de reconocimiento. Dichos modelos funcionarán relativamente rápido (en la GPU) si tenemos muchos datos para entrenar el modelo.
En el caso general, necesitamos la solución más simple, que funcionará como debería y requerirá la menor cantidad de datos de entrenamiento. No es necesario que sea el algoritmo más nuevo y rápido. Sin embargo, específicamente en nuestro caso, Mask R-CNN es una opción razonable, a pesar del hecho de que es bastante nuevo y rápido.
La arquitectura de la máscara R-CNN está diseñada de tal manera que reconoce objetos en toda la imagen, gasta recursos de manera efectiva y no utiliza el enfoque de ventana deslizante. En otras palabras, funciona bastante rápido. Con una GPU moderna, podremos reconocer objetos en video en alta resolución a una velocidad de varios cuadros por segundo. Para nuestro proyecto esto debería ser suficiente.
Además, la máscara R-CNN proporciona mucha información sobre cada objeto reconocido. La mayoría de los algoritmos de reconocimiento devuelven solo un cuadro delimitador para cada objeto. Sin embargo, la máscara R-CNN no solo nos dará la ubicación de cada objeto, sino también su contorno (máscara):

Para entrenar a la máscara R-CNN, necesitamos muchas imágenes de objetos que queremos reconocer. Podríamos salir, tomar fotografías de automóviles y marcarlas en fotografías, lo que requeriría varios días de trabajo. Afortunadamente, los automóviles son uno de esos objetos que las personas a menudo quieren reconocer, por lo que ya existen varios conjuntos de datos públicos con imágenes de automóviles.
Uno de ellos es el popular
conjunto de datos SOCO (abreviatura de Common Objects In Context), que tiene imágenes anotadas con máscaras de objetos. Este conjunto de datos contiene más de 12,000 imágenes con máquinas ya etiquetadas. Aquí hay una imagen de ejemplo del conjunto de datos:

Dichos datos son excelentes para entrenar un modelo basado en la máscara R-CNN.
Pero aguanta los caballos, ¡hay noticias aún mejores! No somos los primeros que quisimos entrenar su modelo utilizando el conjunto de datos COCO; muchas personas ya lo han hecho antes que nosotros y han compartido sus resultados. Por lo tanto, en lugar de entrenar a nuestro modelo, podemos tomar uno listo que ya reconozca los autos. Para nuestro proyecto, utilizaremos el
modelo de código abierto de Matterport.Si le damos una imagen de la cámara a la entrada de este modelo, esto es lo que ya tenemos "listo para usar":

El modelo reconoció no solo automóviles, sino también objetos como semáforos y personas. Es curioso que ella reconociera el árbol como una planta de interior.
Para cada objeto reconocido, el modelo Mask R-CNN devuelve 4 cosas:
- Tipo de objeto detectado (entero). El modelo COCO pre-entrenado puede reconocer 80 objetos comunes diferentes como automóviles y camiones. Una lista completa de ellos se puede encontrar aquí.
- El grado de confianza en los resultados del reconocimiento. Cuanto mayor sea el número, más fuerte será el modelo confía en el reconocimiento del objeto.
- Un cuadro delimitador para un objeto en forma de coordenadas XY de píxeles en la imagen.
- Una "máscara" que muestra qué píxeles dentro del cuadro delimitador forman parte del objeto. Usando los datos de la máscara, puede encontrar el contorno del objeto.
A continuación se muestra el código de Python para detectar el cuadro delimitador para máquinas que utilizan los modelos pre-entrenados Mask R-CNN y OpenCV:
import numpy as np import cv2 import mrcnn.config import mrcnn.utils from mrcnn.model import MaskRCNN from pathlib import Path
Después de ejecutar este script, aparecerá una imagen con un marco alrededor de cada máquina detectada en la pantalla:

Además, las coordenadas de cada máquina se mostrarán en la consola:
Cars found in frame of video: Car: [492 871 551 961] Car: [450 819 509 913] Car: [411 774 470 856]
Entonces aprendimos a reconocer los autos en la imagen.
Reconocemos espacios de estacionamiento vacíos
Conocemos las coordenadas de píxeles de cada máquina. Mirando a través de varios cuadros consecutivos, podemos determinar fácilmente cuáles de los autos no se movieron, y asumir que hay espacios de estacionamiento. Pero, ¿cómo entender que el auto salió del estacionamiento?
El problema es que los marcos de las máquinas se superponen parcialmente entre sí:

Por lo tanto, si imagina que cada marco representa un espacio de estacionamiento, puede resultar que esté parcialmente ocupado por la máquina, cuando en realidad está vacío. Necesitamos encontrar una manera de medir el grado de intersección de dos objetos para buscar solo los cuadros "más vacíos".
Usaremos una medida llamada Intersection Over Union (relación del área de intersección con el área total) o IoU. IoU se puede encontrar calculando el número de píxeles donde se cruzan dos objetos y dividiéndolos por el número de píxeles ocupados por estos objetos:
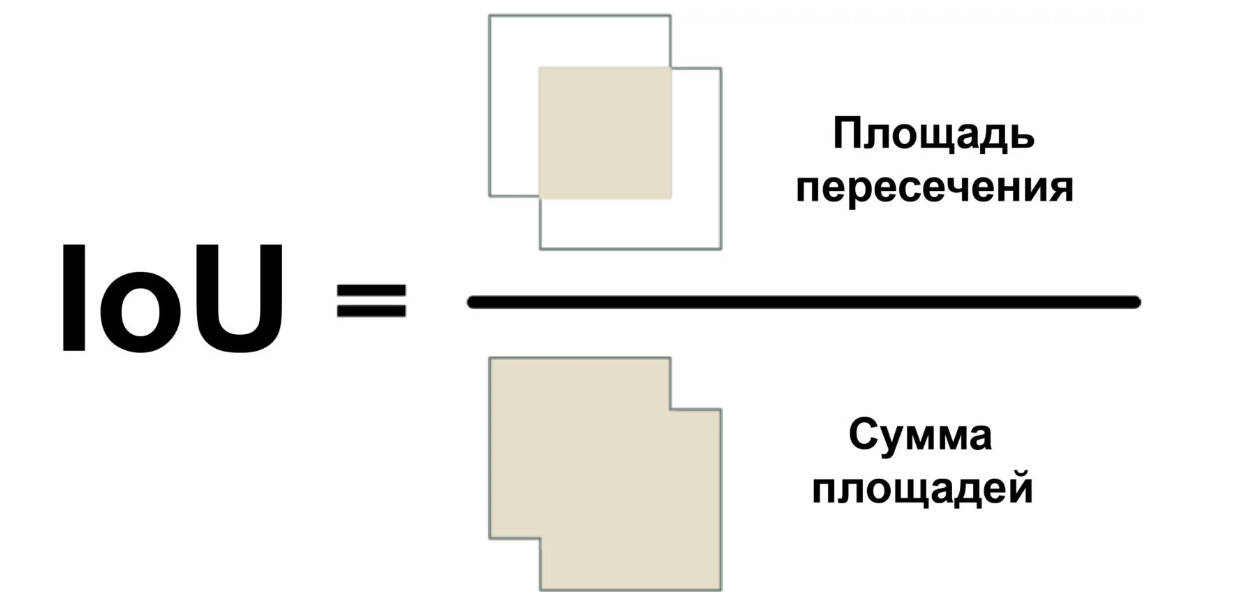
Entonces podemos entender cómo el marco muy delimitado del automóvil se cruza con el marco del espacio de estacionamiento. Esto facilitará determinar si el estacionamiento es gratuito. Si el valor de IoU es bajo, como 0.15, entonces el automóvil ocupa una pequeña parte del espacio de estacionamiento. Y si es alto, como 0.6, entonces esto significa que el automóvil ocupa la mayor parte del espacio y no se puede estacionar allí.
Dado que IoU se usa con bastante frecuencia en la visión por computadora, es muy probable que las bibliotecas correspondientes implementen esta medida. En nuestra biblioteca Mask R-CNN, se implementa como una función mrcnn.utils.compute_overlaps ().
Si tenemos una lista de cuadros delimitadores para espacios de estacionamiento, puede agregar un cheque por la presencia de automóviles en este marco agregando una línea completa o dos de código:
El resultado debería verse así:
[ [1. 0.07040032 0. 0.] [0.07040032 1. 0.07673165 0.] [0. 0. 0.02332112 0.] ]
En esta matriz bidimensional, cada fila refleja un cuadro del espacio de estacionamiento. Y cada columna indica qué tan fuertemente cada uno de los lugares se cruza con una de las máquinas detectadas. Un resultado de 1.0 significa que todo el lugar está completamente ocupado por el automóvil, y un valor bajo como 0.02 indica que el automóvil se ha subido un poco al lugar, pero aún puede estacionarse en él.
Para encontrar lugares desocupados, solo necesita verificar cada fila en esta matriz. Si todos los números están cerca de cero, ¡lo más probable es que el lugar sea libre!
Sin embargo, tenga en cuenta que el reconocimiento de objetos no siempre funciona perfectamente con video en tiempo real. Aunque el modelo basado en la máscara R-CNN es bastante preciso, de vez en cuando puede perder un automóvil o dos en un cuadro del video. Por lo tanto, antes de afirmar que el lugar es gratuito, debe asegurarse de que permanezca así durante los próximos 5 a 10 cuadros siguientes del video. De esta manera, podemos evitar situaciones en las que el sistema marca erróneamente un lugar vacío debido a una falla en un cuadro del video. ¡Tan pronto como nos aseguremos de que el lugar permanezca libre durante varios fotogramas, puede enviar un mensaje!
Enviar SMS
La última parte de nuestro transportador es enviar notificaciones por SMS cuando aparece un espacio de estacionamiento gratuito.
Enviar un mensaje desde Python es muy fácil si usa Twilio. Twilio es una API popular que le permite enviar SMS desde casi cualquier lenguaje de programación con solo unas pocas líneas de código. Por supuesto, si prefiere un servicio diferente, puede usarlo. No tengo nada que ver con Twilio, es lo primero que me viene a la mente.
Para usar Twilio, regístrese para obtener una
cuenta de prueba , cree un número de teléfono de Twilio y obtenga la información de autenticación de su cuenta. Luego instale la biblioteca del cliente:
$ pip3 install twilio
Después de eso, use el siguiente código para enviar el mensaje:
from twilio.rest import Client
Para agregar la capacidad de enviar mensajes a nuestro script, simplemente copie este código allí. Sin embargo, debe asegurarse de que el mensaje no se envíe en cada cuadro, donde el espacio libre es visible. Por lo tanto, tendremos una bandera que en el estado instalado no permitirá enviar mensajes por algún tiempo o hasta que se desocupe otro lugar.
Poniendo todo junto
import numpy as np import cv2 import mrcnn.config import mrcnn.utils from mrcnn.model import MaskRCNN from pathlib import Path from twilio.rest import Client
Para ejecutar ese código, primero debe instalar Python 3.6+,
Matterport Mask R-CNN y
OpenCV .
Específicamente escribí el código lo más simple posible. Por ejemplo, si ve un automóvil en el primer cuadro, concluye que todos están estacionados. Intente experimentar con él y vea si puede mejorar su confiabilidad.
Simplemente cambiando los identificadores de los objetos que está buscando el modelo, puede convertir el código en algo completamente diferente. Por ejemplo, imagine que está trabajando en una estación de esquí. Después de hacer un par de cambios, puede convertir este script en un sistema que reconoce automáticamente a los snowboarders que saltan desde una rampa y graba videos con saltos geniales. O, si trabaja en una reserva natural, puede crear un sistema que cuente las cebras. Estás limitado solo por tu imaginación.
Se pueden leer más artículos de este tipo en el canal de telegramas
Neuron (@neurondata)
Enlace de traducción alternativa:
tproger.ru/translations/parking-searching/Todo conocimiento Experimento!