La IA de hoy es técnicamente "débil"; sin embargo, es compleja y puede afectar significativamente a la sociedad
 No necesita ser Cyrus Dully para saber cuán aterradora puede ser una inteligencia inteligente [un actor estadounidense que interpretó el papel del astronauta Dave Bowman en la película "Space Odyssey 2001" / aprox. perev.]
No necesita ser Cyrus Dully para saber cuán aterradora puede ser una inteligencia inteligente [un actor estadounidense que interpretó el papel del astronauta Dave Bowman en la película "Space Odyssey 2001" / aprox. perev.]La IA, o inteligencia artificial, es ahora una de las áreas de conocimiento más importantes. Se están resolviendo problemas "irresolubles", se están invirtiendo miles de millones de dólares, y Microsoft incluso
contrata a Common para que nos diga con calma poética, qué cosa tan maravillosa es esto: AI. Eso es correcto
Y, como con cualquier tecnología nueva, puede ser difícil superar toda esta exageración. He estado investigando en el campo de los drones y la IA durante años, pero incluso para mí puede ser difícil seguir el ritmo de todo esto. En los últimos años, pasé mucho tiempo buscando respuestas incluso a las preguntas más simples como:
- ¿Qué quiere decir la gente al decir "AI"?
- ¿Cuál es la diferencia entre IA, aprendizaje automático y aprendizaje profundo?
- ¿Qué tiene de bueno el aprendizaje profundo?
- ¿Qué tareas difíciles anteriores ahora son fáciles de resolver y qué sigue siendo difícil?
Sé que a nadie le interesan esas cosas. Por lo tanto, si está interesado en lo que todos estos entusiasmos con la IA están conectados al nivel más simple, es hora de mirar detrás de escena. Si eres un experto en IA y lees los informes de la Conferencia sobre Procesamiento de Información Neurológica (NIPS) por diversión, el artículo no será nada nuevo para ti; sin embargo, esperamos aclaraciones y correcciones de ti en los comentarios.
¿Qué es la IA?
Hay una broma tan antigua en informática: ¿cuál es la diferencia entre IA y automatización? La automatización es algo que se puede hacer usando una computadora, y la IA es algo que nos gustaría poder hacer. Tan pronto como aprendemos cómo hacer algo, pasa del campo de la IA a la categoría de automatización.
Esta broma es válida hoy, ya que la IA no está definida con suficiente claridad. Inteligencia artificial simplemente no es un término técnico. Si entras en Wikipedia, dice que la IA es "la inteligencia demostrada por las máquinas, en contraste con la inteligencia natural demostrada por las personas y otros animales". No se puede decir con menos claridad.
En general, hay dos tipos de IA: fuerte y débil. La mayoría de las personas imaginan una IA fuerte cuando escuchan acerca de la IA: es una especie de intelecto omnisciente divino como Skynet o Hal 9000, capaz de razonar y comparable al humano, mientras excede sus capacidades.
Las IA débiles son algoritmos altamente especializados diseñados para responder preguntas útiles específicas en áreas estrechamente definidas. Por ejemplo, un muy buen programa de ajedrez entra en esta categoría. Lo mismo puede decirse sobre el software que ajusta con mucha precisión los pagos del seguro. En su campo, tales IA logran resultados impresionantes, pero en general son muy limitadas.
Con la excepción de las elecciones de Hollywood, hoy ni siquiera nos hemos acercado a una IA fuerte. Hasta ahora, cualquier IA es débil, y la mayoría de los investigadores en esta área están de acuerdo en que las técnicas que inventamos para crear grandes IA débiles no nos acercarán a crear una IA fuerte.
Entonces, la IA de hoy es más un término de marketing que técnico. La razón por la que las empresas anuncian su IA en lugar de la automatización es porque quieren introducir Hollywood AI en la mente del público. Sin embargo, esto no es tan malo. Si esto no se toma de manera demasiado estricta, las compañías solo quieren decir que, aunque todavía estamos muy lejos de una IA fuerte, la IA débil de hoy es mucho más capaz que la que existía hace varios años.
Y si te distraes del marketing, entonces es así. En ciertas áreas, las capacidades de las máquinas han aumentado dramáticamente, y principalmente gracias a dos frases más que ahora están de moda: aprendizaje automático y aprendizaje profundo.
 Disparo de un breve video de ingenieros de Facebook que muestra cómo la IA en tiempo real reconoce a los gatos (una tarea también conocida como el Santo Grial de Internet)
Disparo de un breve video de ingenieros de Facebook que muestra cómo la IA en tiempo real reconoce a los gatos (una tarea también conocida como el Santo Grial de Internet)Aprendizaje automático
MO es una forma especial de crear inteligencia artificial. Supongamos que desea lanzar un cohete y predecir a dónde irá. En general, no es tan difícil: la gravedad está bastante bien estudiada, puede escribir las ecuaciones y calcular a dónde irá, en función de varias variables, como la velocidad y la posición inicial.
Sin embargo, este enfoque se vuelve incómodo si pasamos a un área cuyas reglas no son tan conocidas y claras. Suponga que quiere que la computadora le diga si hay gatos en algunas imágenes. ¿Cómo escribirás las reglas que describen la vista en todos los puntos de vista posibles sobre todas las combinaciones posibles de bigote y orejas?
Hoy, el enfoque MO es bien conocido: en lugar de tratar de escribir todas las reglas, se crea un sistema que puede derivar independientemente un conjunto de reglas internas después de estudiar una gran cantidad de ejemplos. En lugar de describir gatos, simplemente le muestra a su IA un montón de fotos de gatos y le permite comprender por sí mismo qué es un gato y qué no.
Y hoy es el enfoque perfecto. Un sistema de autoaprendizaje basado en datos puede mejorarse simplemente agregando datos. Y si nuestra especie es capaz de hacer algo muy bien, es generar, almacenar y administrar datos. ¿Quieres aprender a reconocer mejor a los gatos? Internet está generando millones de ejemplos en este momento.
El flujo cada vez mayor de datos es una de las razones del crecimiento explosivo de los algoritmos de MO en los últimos tiempos. Otras razones están relacionadas con el uso de estos datos.
Además de los datos, hay dos cuestiones más relacionadas con esto para la Región de Moscú:
- ¿Cómo recuerdo lo que aprendí? ¿Cómo almacenar y presentar en la computadora las comunicaciones y las reglas que deduje de los datos?
- ¿Como aprendo? ¿Cómo cambiar la representación almacenada en respuesta a nuevos ejemplos y mejorar?
En otras palabras, ¿qué se está formando exactamente sobre la base de todos estos datos?
En MO, la representación computacional de la capacitación que almacenamos es un modelo. El tipo de modelo utilizado es muy importante: determina cómo aprende su IA, de qué datos puede aprender y qué preguntas puede hacerle.
Veamos un ejemplo muy simple. Supongamos que compramos higos en una tienda de abarrotes y queremos hacer una IA con el MO que nos diga si está maduro. Esto debería ser fácil de hacer, porque en el caso de los higos, cuanto más blando, más dulce.
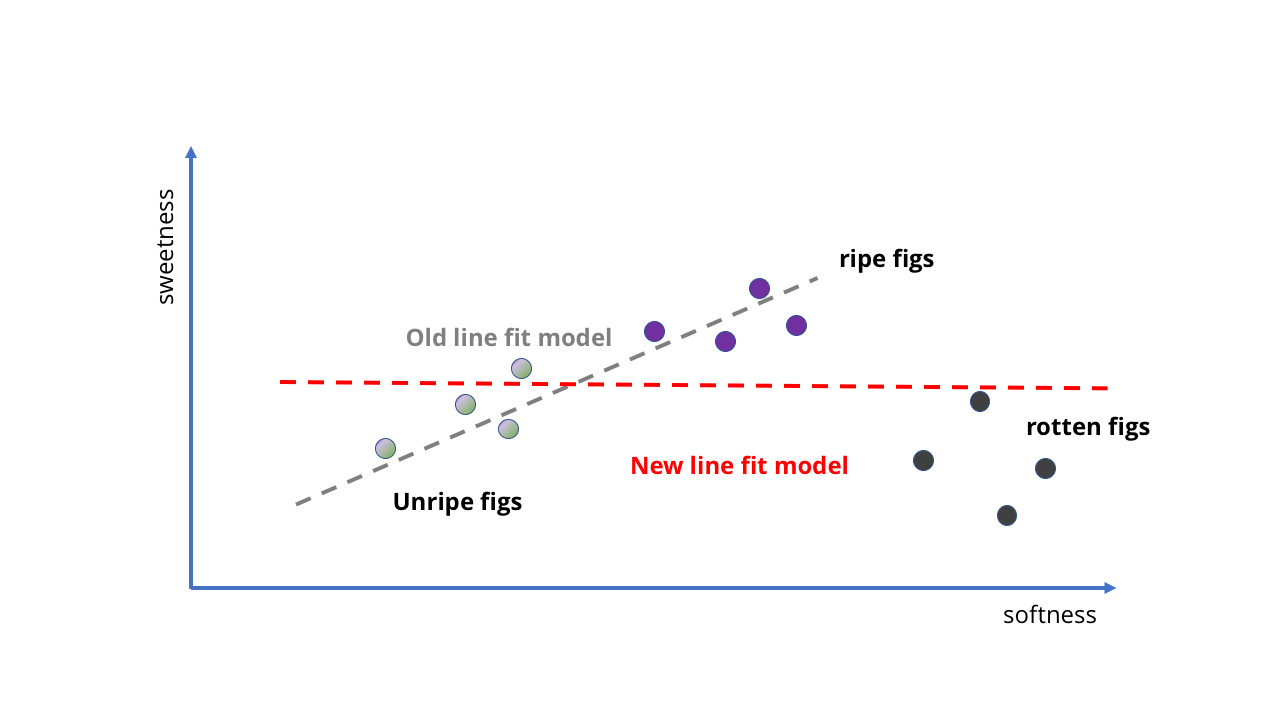
Podemos tomar varias muestras de higos maduros e inmaduros, ver qué tan dulces son, y luego colocarlos en la tabla y ajustar la línea recta. Esta línea será nuestro modelo.
 Embrión AI en forma de "cuanto más suave, más dulce"
Embrión AI en forma de "cuanto más suave, más dulce" Con la adición de nuevos datos, la tarea se vuelve más complicada.
Con la adición de nuevos datos, la tarea se vuelve más complicada.¡Echa un vistazo! La línea recta sigue implícitamente la idea de que "cuanto más suaves son, más dulces", y ni siquiera tuvimos que escribir nada. Nuestro feto AI no sabe nada sobre el contenido de azúcar o la maduración de la fruta, pero puede predecir la dulzura de una fruta al exprimirla.
¿Cómo entrenar un modelo para mejorarlo? Podemos recolectar aún más muestras y dibujar otra línea recta para obtener predicciones más precisas (como en la segunda imagen de arriba). Sin embargo, los problemas se hacen evidentes de inmediato. Hasta ahora, hemos estado entrenando nuestra IA de higos en bayas de calidad: ¿qué pasa si tomamos datos del huerto? De repente, no solo tenemos frutas maduras, sino también podridas. Son muy suaves, pero definitivamente no son aptos para comer.
Que hacemos Bueno, dado que este es un modelo MO, podemos alimentarla con más datos, ¿verdad?
Como muestra la primera imagen a continuación, en este caso obtendremos resultados completamente sin sentido. La línea simplemente no es adecuada para describir lo que sucede cuando la fruta está demasiado madura. Nuestro modelo ya no se ajusta a la estructura de datos.
En cambio, tenemos que cambiarlo y usar un modelo mejor y más complejo, tal vez una parábola o algo similar. Este cambio complica el aprendizaje porque dibujar curvas requiere una matemática más sofisticada que dibujar una línea recta.
 De acuerdo, probablemente la idea de usar una línea recta para una IA compleja no tuvo mucho éxito
De acuerdo, probablemente la idea de usar una línea recta para una IA compleja no tuvo mucho éxito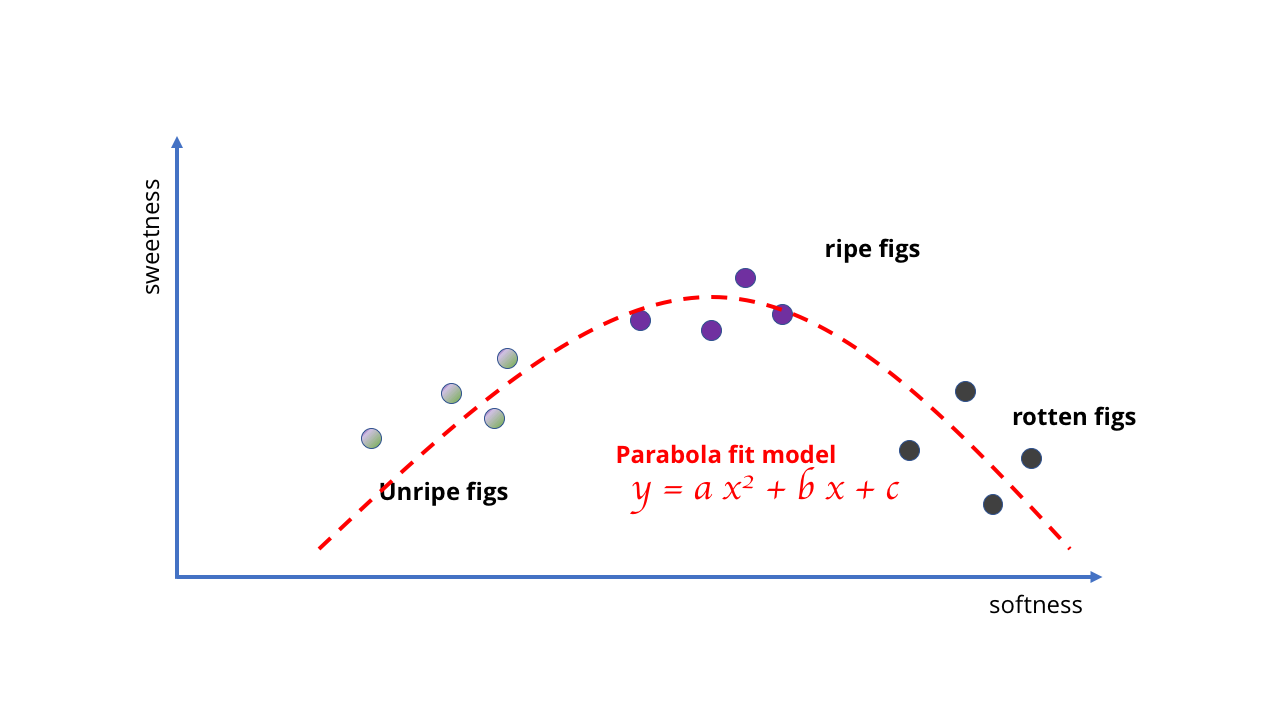 Matemáticas más complicadas requeridas
Matemáticas más complicadas requeridasEl ejemplo es bastante estúpido, pero muestra que la elección del modelo determina las posibilidades de aprendizaje. En el caso de los higos, los datos son simples y los modelos pueden ser simples. Pero si está tratando de aprender algo más complejo, se requieren modelos más complejos. Al igual que ninguna cantidad de datos hace que un modelo lineal refleje el comportamiento de las bayas podridas, es imposible seleccionar una curva simple correspondiente a un montón de imágenes para crear un algoritmo de visión por computadora.
Por lo tanto, la dificultad para el MO es crear y seleccionar los modelos correctos para las tareas correspondientes. Necesitamos un modelo que sea lo suficientemente complejo como para describir las relaciones y estructuras realmente complejas, pero lo suficientemente simple como para que pueda trabajar con él y capacitarlo. Entonces, aunque Internet, los teléfonos inteligentes, etc. han creado montañas increíbles de datos para aprender, todavía necesitamos los modelos correctos para aprovechar estos datos.
Aquí es donde entra en juego el aprendizaje profundo.

Aprendizaje profundo
El aprendizaje profundo es el aprendizaje automático que utiliza un cierto tipo de modelo: redes neuronales profundas.
Las redes neuronales son un tipo de modelo MO que utiliza una estructura que se asemeja a las neuronas en el cerebro para los cálculos y las predicciones. Las neuronas en las redes neuronales se organizan en capas: cada capa realiza un conjunto de cálculos simples y pasa la respuesta a la siguiente.
El modelo en capas permite cálculos más complejos. Una red simple con un pequeño número de capas neuronales es suficiente para reproducir la línea recta o parábola que usamos anteriormente. Las redes neuronales profundas son redes neuronales con una gran cantidad de capas, con docenas o incluso cientos; de ahí su nombre. Con tantas capas, puedes crear modelos increíblemente potentes.
Esta oportunidad es una de las principales razones de la gran popularidad de las redes neuronales profundas en los últimos tiempos. Pueden aprender varias cosas complejas sin obligar a un investigador humano a definir ninguna regla, y esto nos permitió crear algoritmos que pueden resolver una variedad de problemas que las computadoras no podían abordar antes.
Sin embargo, otro aspecto contribuyó al éxito de las redes neuronales: el entrenamiento.
La "memoria" de un modelo es un conjunto de parámetros numéricos que determina cómo proporciona respuestas a las preguntas formuladas. Entrenar un modelo significa ajustar estos parámetros para que el modelo dé las mejores respuestas posibles.
En nuestro modelo con higos, buscamos la ecuación de la línea. Esta es una tarea de regresión simple, y hay fórmulas que le darán la respuesta en un solo paso.
 Red neuronal simple y red neuronal profunda
Red neuronal simple y red neuronal profundaCon modelos más complejos, las cosas no son tan simples. Una línea recta y una parábola pueden representarse fácilmente con varios números, pero una red neuronal profunda puede tener millones de parámetros, y el conjunto de datos para su entrenamiento también puede consistir en millones de ejemplos. No existe una solución analítica en un solo paso.
Afortunadamente, hay un truco extraño: puedes comenzar con una red neuronal mala y luego mejorarla con ajustes graduales.
Aprender el modelo MO de esta manera es similar a evaluar a un estudiante usando pruebas. Cada vez que recibimos una evaluación comparamos qué respuestas deberían estar en la opinión del modelo con las respuestas "correctas" en los datos de capacitación. Luego hacemos una mejora y ejecutamos la prueba nuevamente.
¿Cómo sabemos qué parámetros ajustar y cuánto? Las redes neuronales tienen una característica tan genial cuando para muchos tipos de entrenamiento no solo puede obtener una evaluación en la prueba, sino también calcular cuánto cambiará en respuesta a un cambio en cada parámetro. En términos matemáticos, una estimación es una función de valor, y para la mayoría de estas funciones podemos calcular fácilmente el gradiente de esta función con respecto al espacio de parámetros.
Ahora sabemos exactamente de qué manera necesitamos ajustar los parámetros para aumentar la puntuación, y podemos ajustar la red por pasos sucesivos en todas las mejores y mejores "direcciones" hasta que llegue a un punto en el que nada se pueda mejorar. Esto a menudo se conoce como subir una colina, porque realmente es como subir una colina: si constantemente te mueves, terminarás en la cima.
 Has visto Arriba!
Has visto Arriba!Gracias a esto, es fácil mejorar la red neuronal. Si su red tiene una buena estructura, después de haber recibido nuevos datos, no necesita comenzar desde cero. Puede comenzar con los parámetros disponibles y volver a aprender de los nuevos datos. Su red mejorará gradualmente. Las IA más destacadas de la actualidad, desde el reconocimiento de gatos en Facebook hasta las tecnologías que Amazon (probablemente) usa en tiendas sin vendedores, se basan en este simple hecho.
Esta es la clave para una razón más por la cual GO se ha extendido tan rápido y tan ampliamente: escalar una colina le permite tomar una red neuronal entrenada para alguna tarea y volver a entrenarla para realizar otra, pero similar. Si ha entrenado IA para reconocer bien a los gatos, esta red se puede usar para entrenar IA que reconozca perros o jirafas sin tener que comenzar desde cero. Comience con la IA para gatos, evalúela por la calidad del reconocimiento del perro y luego suba la colina, ¡mejorando la red!
Por lo tanto, en los últimos 5-6 años, ha habido una mejora notable en las capacidades de la IA. Varias piezas del rompecabezas se unieron de manera sinérgica: Internet generó una gran cantidad de datos para aprender. Las computaciones, especialmente las computaciones paralelas en GPU, permitieron procesar estos enormes conjuntos. Finalmente, las redes neuronales profundas permitieron aprovechar estos kits y crear modelos MO increíblemente potentes.
Y todo esto significa que algunas cosas que antes eran extremadamente difíciles ahora son muy fáciles de hacer.
¿Y qué podemos hacer ahora? Reconocimiento de patrones
Quizás lo más profundo (perdón por el juego de palabras) y el impacto más temprano que tuvo el aprendizaje profundo en el campo de la visión por computadora, en particular, en el reconocimiento de objetos en fotografías. Hace unos años, este cómic xkcd describió perfectamente la vanguardia de la informática:

Hoy, el reconocimiento de aves e incluso ciertos tipos de aves es una tarea trivial que un estudiante de secundaria correctamente motivado puede resolver. ¿Qué ha cambiado?
La idea del reconocimiento visual de objetos es fácil de describir, pero difícil de implementar: los objetos complejos consisten en conjuntos de objetos más simples, que a su vez consisten en formas y líneas más simples. Las caras consisten en ojos, narices y bocas, y esas consisten en círculos y líneas, y así sucesivamente.
Por lo tanto, el reconocimiento facial se convierte en una cuestión de reconocer patrones en los que se encuentran los ojos y la boca, lo que puede requerir el reconocimiento de la forma del ojo y la boca a partir de líneas y círculos.
Estos patrones se llaman características, y antes del aprendizaje profundo para el reconocimiento, era necesario describir todas las características manualmente y programar la computadora para encontrarlas. Por ejemplo, existe el famoso algoritmo de reconocimiento facial
Viola-Jones , basado en el hecho de que las cejas y la nariz son generalmente más claras que las cuencas de los ojos, por lo que forman una forma de T brillante con dos puntos oscuros. El algoritmo, de hecho, está buscando formas T similares.
El método Viola-Jones funciona bien y es sorprendentemente rápido, y sirve como base para el reconocimiento facial en cámaras baratas, etc. Pero, obviamente, no todos los objetos que necesita reconocer se prestan a tal simplificación, y las personas idearon patrones cada vez más complejos y de bajo nivel. Para que los algoritmos funcionaran correctamente, se requería un equipo de doctores en ciencias, que eran muy sensibles y propensos a fallar.
El gran avance se produjo gracias a la defensa civil, y en particular a un cierto tipo de red neuronal llamada red neuronal convolucional. Redes neuronales convolucionales, las redes sociales son redes profundas con una determinada estructura, inspiradas en la estructura de la corteza visual del cerebro de los mamíferos. Esta estructura permite que el SNA aprenda independientemente la jerarquía de líneas y patrones para reconocer objetos, en lugar de esperar a que los doctores en ciencias pasen años investigando qué características son las más adecuadas para esto. Por ejemplo, el SCN, entrenado en caras, aprenderá su propia representación interna de líneas y círculos que se forman en los ojos, oídos y narices, y así sucesivamente.
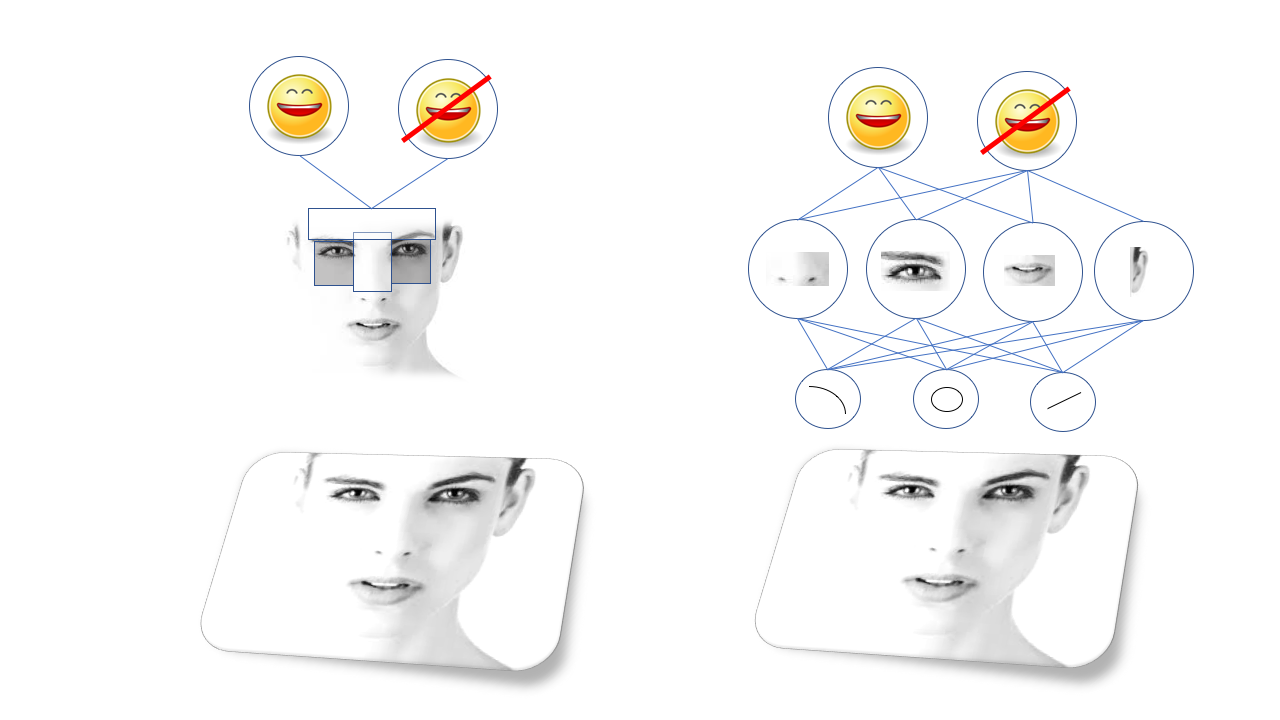 Los algoritmos visuales antiguos (método Viola-Jones, izquierda) se basan en características seleccionadas manualmente y redes neuronales profundas (derecha) en su propia jerarquía de características más complejas compuestas de otras más simples.
Los algoritmos visuales antiguos (método Viola-Jones, izquierda) se basan en características seleccionadas manualmente y redes neuronales profundas (derecha) en su propia jerarquía de características más complejas compuestas de otras más simples.El SNA fue increíblemente bueno para la visión por computadora, y pronto los investigadores pudieron entrenarlos para realizar todo tipo de tareas de reconocimiento visual, desde encontrar gatos en la foto hasta identificar a los peatones que se metieron en la cámara de un robot robótico.
Todo esto es maravilloso, pero hay otra razón para una difusión tan rápida y generalizada del SCN: esta es la facilidad con la que se adaptan. ¿Recuerdas subir una colina?
Si nuestro estudiante de secundaria quiere reconocer un determinado pájaro, puede tomar cualquiera de las muchas redes visuales con código abierto y entrenarlo en su propio conjunto de datos, sin siquiera comprender cómo funcionan las matemáticas subyacentes.Naturalmente, esto se puede ampliar aún más.Quien esta ahi (reconocimiento facial)
Suponga que desea entrenar una red que reconoce no solo caras, sino una cara específica. Puede entrenar a la red para reconocer a una persona específica, luego a otra persona, y así sucesivamente. Sin embargo, lleva tiempo entrenar redes, y eso significaría que para cada nueva persona, sería necesario volver a capacitar a la red. No realmente.En cambio, podemos comenzar con una red capacitada para reconocer rostros en general. Sus neuronas están configuradas para reconocer todas las estructuras faciales: ojos, oídos, bocas, etc. Luego solo cambia la salida: en lugar de obligarla a reconocer ciertas caras, le ordena que dé una descripción de la cara en forma de cientos de números que describen la curvatura de la nariz o la forma de los ojos, y así sucesivamente. La red puede hacer esto porque ya "sabe" en qué componentes está compuesta la cara.Por supuesto, no define todo esto directamente. En cambio, entrena la red mostrándole un conjunto de caras y luego comparando la salida. También le enseñas a ella para que dé descripciones similares entre sí de la misma persona, y descripciones muy diferentes entre sí de diferentes personas. Hablando matemáticamente, entrenas una red para construir una correspondencia con las imágenes de caras de un punto en un espacio de características, donde la distancia cartesiana entre puntos puede usarse para determinar su similitud. Cambiar la red neuronal desde el reconocimiento de caras (a la izquierda) a la descripción de caras (a la derecha) solo requiere cambiar el formato de los datos de salida, sin cambiar su base.
Cambiar la red neuronal desde el reconocimiento de caras (a la izquierda) a la descripción de caras (a la derecha) solo requiere cambiar el formato de los datos de salida, sin cambiar su base. Ahora puede reconocer caras comparando las descripciones de cada una de las caras creadas por la red neuronalHabiendo entrenado la red, puede reconocer fácilmente las caras. Tomas a la persona original y obtienes su descripción. Luego tome una nueva cara y compare la descripción provista por la red con su original. Si están lo suficientemente cerca, dices que es la misma persona. ¡Y ahora ha pasado de una red capaz de reconocer una cara a lo que se puede usar para reconocer cualquier cara!Esta flexibilidad estructural es otra razón de la utilidad de las redes neuronales profundas. Ya se han desarrollado una gran cantidad de varios modelos de MO para la visión por computadora, y aunque se están desarrollando en direcciones muy diferentes, la estructura básica de muchos de ellos se basa en los primeros SNA como Alexnet y Resnet.Incluso escuché historias sobre personas que usan redes neuronales visuales para trabajar con datos de series temporales o mediciones de sensores. En lugar de crear una red especial para analizar el flujo de datos, capacitaron a una red neuronal de código abierto diseñada para la visión por computadora a fin de observar literalmente las formas de los gráficos de líneas.Tal flexibilidad es algo bueno, pero no infinito. Para resolver otros problemas, se requieren otros tipos de redes.
Ahora puede reconocer caras comparando las descripciones de cada una de las caras creadas por la red neuronalHabiendo entrenado la red, puede reconocer fácilmente las caras. Tomas a la persona original y obtienes su descripción. Luego tome una nueva cara y compare la descripción provista por la red con su original. Si están lo suficientemente cerca, dices que es la misma persona. ¡Y ahora ha pasado de una red capaz de reconocer una cara a lo que se puede usar para reconocer cualquier cara!Esta flexibilidad estructural es otra razón de la utilidad de las redes neuronales profundas. Ya se han desarrollado una gran cantidad de varios modelos de MO para la visión por computadora, y aunque se están desarrollando en direcciones muy diferentes, la estructura básica de muchos de ellos se basa en los primeros SNA como Alexnet y Resnet.Incluso escuché historias sobre personas que usan redes neuronales visuales para trabajar con datos de series temporales o mediciones de sensores. En lugar de crear una red especial para analizar el flujo de datos, capacitaron a una red neuronal de código abierto diseñada para la visión por computadora a fin de observar literalmente las formas de los gráficos de líneas.Tal flexibilidad es algo bueno, pero no infinito. Para resolver otros problemas, se requieren otros tipos de redes. E incluso hasta este punto, los asistentes virtuales tomaron mucho tiempo
E incluso hasta este punto, los asistentes virtuales tomaron mucho tiempoQue dijiste (Reconocimiento de voz)
La catalogación de imágenes y la visión por computadora no son las únicas áreas del resurgimiento de la IA. Otra área en la que las computadoras han llegado muy lejos es el reconocimiento de voz, especialmente en la traducción del habla a la escritura.La idea básica en el reconocimiento de voz es bastante similar al principio de la visión por computadora: reconocer cosas complejas en forma de conjuntos de cosas más simples. En el caso del habla, el reconocimiento de oraciones y frases se basa en el reconocimiento de palabras, que se basa en el reconocimiento de sílabas o, para ser más precisos, fonemas. Entonces, cuando alguien dice "Bond, James Bond", en realidad escuchamos BON + DUH + JAY + MMS + BON + DUH.En visión, las características están organizadas espacialmente, y el SCN procesa esta estructura. En el rumor, estas características están organizadas en el tiempo. Las personas pueden hablar rápida o lentamente, sin un comienzo y un final claros del discurso. Necesitamos un modelo que sea capaz de percibir los sonidos a medida que llega, como persona, en lugar de esperar y buscar oraciones completas en ellos. No podemos, como en física, decir que el espacio y el tiempo son uno y lo mismo.Reconocer sílabas individuales es bastante fácil, pero son difíciles de aislar. Por ejemplo, "Hola" puede sonar como "demonios, no están" ... Entonces, para cualquier secuencia de sonidos, generalmente hay varias combinaciones de sílabas que se hablan.Para comprender todo esto, necesitamos la oportunidad de estudiar la secuencia en un contexto determinado. Si escucho un sonido, ¿qué es más probable que la persona diga "hola, cariño" o "demonios, no, son ciervos?" Aquí nuevamente, el aprendizaje automático viene al rescate. Con un conjunto suficientemente grande de patrones de palabras habladas, puede aprender las frases más probables. Y cuantos más ejemplos tenga, mejor resultará.Para esto, las personas usan redes neuronales recurrentes, RNS. En la mayoría de los tipos de redes neuronales, como el SNA involucrado en la visión por computadora, las conexiones entre las neuronas funcionan en una dirección, de entrada a salida (matemáticamente hablando, estos son gráficos acíclicos dirigidos). En RNS, la salida de las neuronas se puede redirigir a neuronas del mismo nivel, a sí mismas o incluso más. Esto permite que el RNS tenga su propia memoria (si está familiarizado con la lógica binaria, entonces esta situación es similar a la operación de los disparadores).SNA funciona para un enfoque: le damos una imagen y ella da una descripción. El RNS mantiene la memoria interna de lo que se le dio anteriormente y da respuestas basadas en lo que ya ha visto, más lo que ve ahora.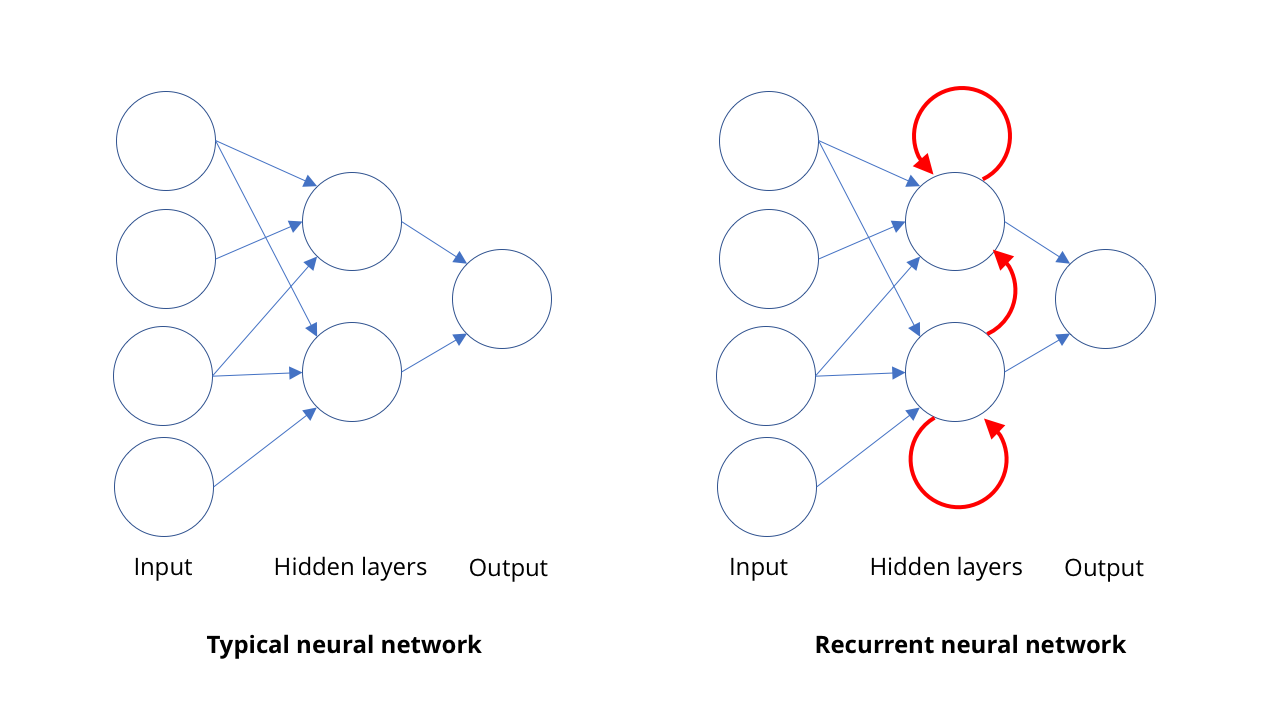 Esta propiedad de la memoria en el RNS les permite no solo "escuchar" las sílabas que le llegan una por una. Esto permite que la red aprenda qué sílabas se unen para formar una palabra y cuán probable es que ciertas secuencias sean.Usando RNS, es posible obtener una muy buena transcripción del habla humana, hasta tal punto que las computadoras ahora pueden superar a los humanos en algunas mediciones de precisión de la transcripción. Por supuesto, los sonidos no son la única área donde aparecen las secuencias. Hoy, RNS también se usa para determinar secuencias de movimientos para reconocer acciones en video.
Esta propiedad de la memoria en el RNS les permite no solo "escuchar" las sílabas que le llegan una por una. Esto permite que la red aprenda qué sílabas se unen para formar una palabra y cuán probable es que ciertas secuencias sean.Usando RNS, es posible obtener una muy buena transcripción del habla humana, hasta tal punto que las computadoras ahora pueden superar a los humanos en algunas mediciones de precisión de la transcripción. Por supuesto, los sonidos no son la única área donde aparecen las secuencias. Hoy, RNS también se usa para determinar secuencias de movimientos para reconocer acciones en video.Muéstrame cómo puedes moverte (falsificaciones profundas y redes generativas)
Hasta ahora, hemos estado hablando de modelos MO diseñados para el reconocimiento: dime qué se muestra en la imagen, dime qué dijo la persona. Pero estos modelos son capaces de más: los modelos GO actuales también se pueden usar para crear contenido.Esto es cuando la gente habla de deepfake: videos e imágenes falsos increíblemente realistas creados con GO. Hace algún tiempo, un funcionario de la televisión alemana provocó una extensa discusión política al crear un video falsoen el que el ministro de finanzas griego le mostró a Alemania el dedo medio. Para crear este video, necesitábamos un equipo de editores que trabajaran para crear un programa de televisión, pero en el mundo moderno, cualquiera que tenga acceso a una computadora de juegos de tamaño mediano puede hacerlo en pocos minutos.Todo esto es bastante triste, pero no tan sombrío en esta área: mi video favorito sobre el tema de esta tecnología se muestra en la parte superior.Este equipo creó un modelo capaz de procesar un video con los movimientos de baile de una persona y crear un video con otra persona repitiendo estos movimientos, realizándolos mágicamente al nivel experto. También es interesante leer el trabajo científico que lo acompaña .Uno puede imaginar que, usando todas las técnicas discutidas por nosotros, es posible entrenar una red que recibe la imagen de un bailarín y le dice dónde están sus brazos y piernas. Y en este caso, obviamente, en algún nivel, la red aprendió a conectar los píxeles de la imagen con la ubicación de las extremidades humanas. Dado que una red neuronal es solo datos almacenados en una computadora, no un cerebro biológico, debería ser posible tomar estos datos e ir en la dirección opuesta, para obtener píxeles que correspondan a la ubicación de las extremidades.Comience con una red que extraiga poses de imágenes de personas.
Los modelos MO que pueden hacer esto se denominan modelos generativos. generar - generar, producir, crear / aprox. transl.]. Todos los modelos anteriores que hemos considerado se denominan discriminatorios [ing. discriminar - para distinguir / aprox. transl.]. La diferencia entre ellos se puede imaginar de la siguiente manera: un modelo discriminatorio para gatos mira fotos y distingue entre fotos que contienen gatos y fotos donde no están. El modelo generativo crea imágenes de gatos basadas, por ejemplo, en una descripción de cómo debería ser un gato. Los modelos generativos que "dibujan" imágenes de objetos se crean utilizando las mismas estructuras SNA que los modelos utilizados para reconocer estos objetos. Y estos modelos se pueden entrenar de la misma manera que otros modelos MO.Sin embargo, el truco es llegar a una "evaluación" para su entrenamiento. Al entrenar un modelo discriminatorio, hay una manera simple de evaluar la corrección y la incorrección de la respuesta, como por ejemplo si la red distinguió correctamente al perro del gato. Sin embargo, ¿cómo evaluar la calidad de la imagen del gato resultante o su precisión?Y aquí, para una persona que ama las teorías de conspiración y cree que todos estamos condenados, la situación se vuelve un poco aterradora. Verá, la mejor manera que inventamos para aprender redes generativas es no hacerlo usted mismo. Para esto, simplemente usamos una red neuronal diferente.Esta tecnología se llama una red de confrontación generativa, o GSS. Obliga a dos redes neuronales a competir entre sí: una red está tratando de crear falsificaciones, por ejemplo, dibujando un nuevo bailarín basado en las viejas posturas. Otra red está entrenada para encontrar la diferencia entre ejemplos reales y falsos utilizando un montón de ejemplos de bailarines reales.Y estas dos redes juegan un juego competitivo. De ahí la palabra "adversarial" en el título. La red generativa intenta hacer falsificaciones convincentes, y la red discriminatoria intenta comprender dónde está la falsificación y dónde está la realidad.En el caso de un video con un bailarín, se creó una red discriminatoria separada durante el proceso de capacitación, dando respuestas simples de sí / no. Miró la imagen de la persona y la descripción de la posición de sus extremidades, y decidió si la imagen era una fotografía real o una imagen dibujada por un modelo generativo.
Los modelos generativos que "dibujan" imágenes de objetos se crean utilizando las mismas estructuras SNA que los modelos utilizados para reconocer estos objetos. Y estos modelos se pueden entrenar de la misma manera que otros modelos MO.Sin embargo, el truco es llegar a una "evaluación" para su entrenamiento. Al entrenar un modelo discriminatorio, hay una manera simple de evaluar la corrección y la incorrección de la respuesta, como por ejemplo si la red distinguió correctamente al perro del gato. Sin embargo, ¿cómo evaluar la calidad de la imagen del gato resultante o su precisión?Y aquí, para una persona que ama las teorías de conspiración y cree que todos estamos condenados, la situación se vuelve un poco aterradora. Verá, la mejor manera que inventamos para aprender redes generativas es no hacerlo usted mismo. Para esto, simplemente usamos una red neuronal diferente.Esta tecnología se llama una red de confrontación generativa, o GSS. Obliga a dos redes neuronales a competir entre sí: una red está tratando de crear falsificaciones, por ejemplo, dibujando un nuevo bailarín basado en las viejas posturas. Otra red está entrenada para encontrar la diferencia entre ejemplos reales y falsos utilizando un montón de ejemplos de bailarines reales.Y estas dos redes juegan un juego competitivo. De ahí la palabra "adversarial" en el título. La red generativa intenta hacer falsificaciones convincentes, y la red discriminatoria intenta comprender dónde está la falsificación y dónde está la realidad.En el caso de un video con un bailarín, se creó una red discriminatoria separada durante el proceso de capacitación, dando respuestas simples de sí / no. Miró la imagen de la persona y la descripción de la posición de sus extremidades, y decidió si la imagen era una fotografía real o una imagen dibujada por un modelo generativo. GSS obliga a dos redes a competir entre sí: una produce falsificaciones y la otra trata de distinguir las falsas de las originales.
GSS obliga a dos redes a competir entre sí: una produce falsificaciones y la otra trata de distinguir las falsas de las originales.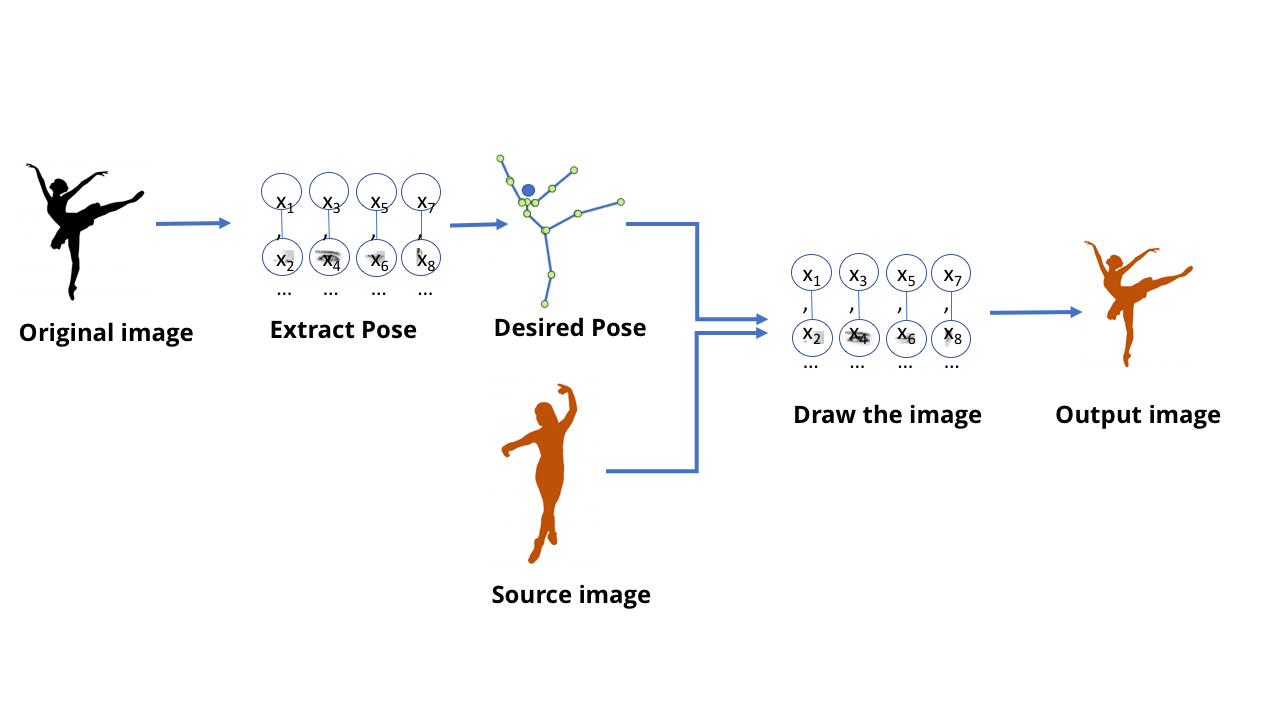 En el flujo de trabajo final, solo se utiliza un modelo generativo que crea las imágenes necesariasDurante las rondas repetidas de entrenamiento, los modelos mejoraron y mejoraron. Esto es similar a una competencia entre un experto en joyería y un experto en valoración: compitiendo con un oponente fuerte, cada uno de ellos se vuelve más fuerte e inteligente. Finalmente, cuando los modelos funcionan lo suficientemente bien, puede tomar un modelo generativo y usarlo por separado.Los modelos generativos posteriores al entrenamiento pueden ser muy útiles para crear contenido. Por ejemplo, pueden generar imágenes de caras (que pueden usarse para entrenar programas de reconocimiento de caras) o fondos para videojuegos.Para que todo esto funcione correctamente, se requiere mucho trabajo en ajustes y correcciones, pero en esencia la persona aquí actúa como árbitro. Es la IA la que funciona una contra la otra, haciendo grandes mejoras.
En el flujo de trabajo final, solo se utiliza un modelo generativo que crea las imágenes necesariasDurante las rondas repetidas de entrenamiento, los modelos mejoraron y mejoraron. Esto es similar a una competencia entre un experto en joyería y un experto en valoración: compitiendo con un oponente fuerte, cada uno de ellos se vuelve más fuerte e inteligente. Finalmente, cuando los modelos funcionan lo suficientemente bien, puede tomar un modelo generativo y usarlo por separado.Los modelos generativos posteriores al entrenamiento pueden ser muy útiles para crear contenido. Por ejemplo, pueden generar imágenes de caras (que pueden usarse para entrenar programas de reconocimiento de caras) o fondos para videojuegos.Para que todo esto funcione correctamente, se requiere mucho trabajo en ajustes y correcciones, pero en esencia la persona aquí actúa como árbitro. Es la IA la que funciona una contra la otra, haciendo grandes mejoras.Entonces, ¿deberíamos esperar la aparición de Skynet y Hal 9000 en el futuro cercano?
En cada documental sobre la naturaleza al final hay un episodio donde los autores hablan sobre cómo toda esta grandiosa belleza pronto desaparecerá debido a lo terrible que es la gente. Creo que con el mismo espíritu, cada discusión responsable con respecto a la IA debería incluir una sección sobre sus limitaciones y consecuencias sociales.
Primero, enfaticemos una vez más las limitaciones actuales de la IA: la idea principal que espero que haya aprendido al leer este artículo es que el éxito del MO o la IA depende en gran medida de los modelos de entrenamiento que hemos elegido. Si las personas no organizan bien la red o utilizan materiales inadecuados para la capacitación, estas distorsiones pueden ser muy obvias para todos.
Las redes neuronales profundas son increíblemente flexibles y poderosas, pero no tienen propiedades mágicas. A pesar de que utiliza redes neuronales profundas para RNS y SNA, su estructura es muy diferente y, por lo tanto, las personas deberían determinarlo de todos modos. Entonces, incluso si puede tomar el SNA para automóviles y volver a entrenarlo para el reconocimiento de aves, no puede tomar este modelo y volver a entrenarlo para el reconocimiento de voz.
Si lo describimos en términos humanos, entonces todo parece como si entendiéramos cómo funcionan la corteza visual y la corteza auditiva, pero no tenemos idea de cómo funciona la corteza cerebral y dónde podemos comenzar a abordarla.
Esto significa que en el futuro cercano, probablemente no veremos la inteligencia artificial de Hollywood. Pero esto no significa que, en su forma actual, la IA no pueda tener un impacto serio en la sociedad.
A menudo imaginamos cómo la IA nos “reemplaza”, es decir, cómo los robots literalmente hacen nuestro trabajo, pero en realidad esto no sucederá. Eche un vistazo a la radiología, por ejemplo: a veces las personas, observando el éxito de la visión por computadora, dicen que la IA reemplazará a los radiólogos. Quizás no alcanzaremos el punto en el que no tendremos un solo radiólogo humano. Pero es posible un futuro en el que, para un centenar de radiólogos de hoy, la IA permita que de cinco a diez de ellos hagan el trabajo de todos los demás. Si tal escenario se realiza, ¿a dónde irán los 90 médicos restantes?
Incluso si la generación moderna de IA no está a la altura de las esperanzas de sus partidarios más optimistas, aún tendrá consecuencias muy amplias. Y tendremos que resolver estos problemas, por lo que un buen comienzo probablemente será dominar los conceptos básicos de esta área.