Introduccion
Implementando el siguiente sistema, ante la necesidad de procesar una gran cantidad de registros diferentes. Como la herramienta elegida ELK. Este artículo discutirá nuestra experiencia con el ajuste de esta pila.
No nos proponemos describir todas sus posibilidades, pero queremos concentrarnos precisamente en resolver problemas prácticos. Esto se debe al hecho de que, en presencia de una cantidad suficientemente grande de documentación e imágenes prefabricadas, hay muchas trampas, al menos las encontramos.
Implementamos la pila a través de docker-compose. Además, teníamos un docker-compose.yml bien escrito, lo que nos permitió aumentar la pila casi sin problemas. Y nos pareció que la victoria ya estaba cerca, ahora giraremos un poco para adaptarnos a nuestras necesidades y eso es todo.
Desafortunadamente, un intento de ajustar el sistema para recibir y procesar registros de nuestra aplicación no fue coronado con éxito. Por lo tanto, decidimos que valía la pena explorar cada componente por separado y luego volver a sus relaciones.
Entonces, comenzamos con logstash.
Entorno, implementación, lanzamiento de Logstash en el contenedor
Para la implementación, utilizamos docker-compose, los experimentos descritos aquí se realizaron en MacOS y Ubuntu 18.0.4.
La imagen de logstash registrada con nosotros en el docker-compose.yml original es docker.elastic.co/logstash/logstash:6.3.2
Lo usaremos para experimentos.
Para ejecutar logstash, escribimos un docker-compose.yml separado. Por supuesto, fue posible iniciar la imagen desde la línea de comandos, pero resolvimos una tarea específica, donde se inicia todo, desde docker-compose.
Brevemente sobre los archivos de configuración
Como se deduce de la descripción, logstash se puede ejecutar tanto para un canal, en este caso, necesita transferir el archivo * .conf o para varios canales, en este caso necesita ser transferido el archivo pipelines.yml, que, a su vez, se vinculará a los archivos .conf para cada canal.
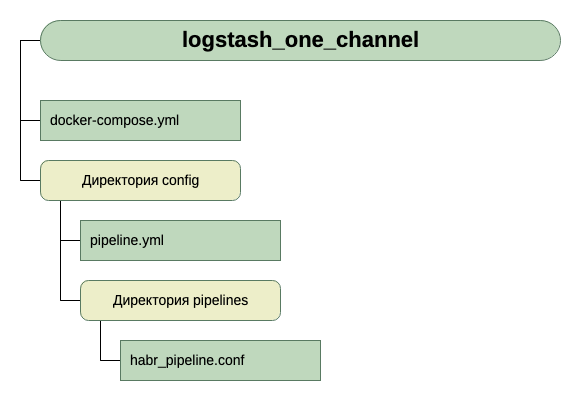
Fuimos por el segundo camino. Nos pareció más universal y escalable. Por lo tanto, creamos pipelines.yml e hicimos el directorio de tuberías en el que colocaremos los archivos .conf para cada canal.
Dentro del contenedor hay otro archivo de configuración: logstash.yml. No lo tocamos, utilízalo como está.
Entonces, la estructura de nuestros directorios:
Para obtener la entrada, por ahora, creemos que es tcp en el puerto 5046, y para la salida usaremos stdout.
Aquí hay una configuración tan simple para la primera ejecución. Dado que la tarea inicial es lanzar.
Entonces, tenemos este docker-compose.yml
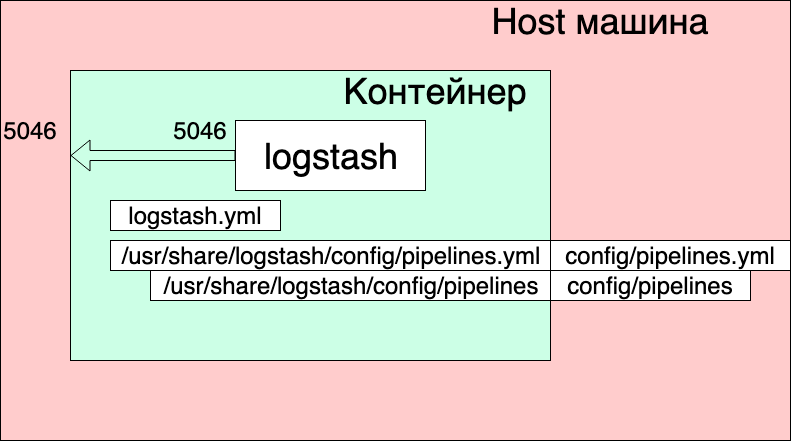
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro
¿Qué vemos aquí?
- Las redes y los volúmenes se tomaron del docker-compose.yml original (aquel donde se lanza toda la pila) y creo que no afectan significativamente la imagen general aquí.
- Creamos un servicio logstash desde la imagen docker.elastic.co/logstash/logstash:6.3.2 y le damos el nombre de logstash_one_channel.
- Reenviamos el puerto 5046 dentro del contenedor al mismo puerto interno.
- Asignamos nuestro archivo de configuración de canal ./config/pipelines.yml al archivo /usr/share/logstash/config/pipelines.yml dentro del contenedor, donde logstash lo recogerá y lo hará de solo lectura, por si acaso.
- Mostramos el directorio ./config/pipelines, donde tenemos los archivos con la configuración del canal, en el directorio / usr / share / logstash / config / pipelines y también lo hacemos de solo lectura.
Archivo Pipelines.yml
- pipeline.id: HABR pipeline.workers: 1 pipeline.batch.size: 1 path.config: "./config/pipelines/habr_pipeline.conf"
Aquí, se describe un canal con el identificador HABR y la ruta a su archivo de configuración.
Y finalmente el archivo "./config/pipelines/habr_pipeline.conf"
input { tcp { port => "5046" } } filter { mutate { add_field => [ "habra_field", "Hello Habr" ] } } output { stdout { } }
No entremos en su descripción por ahora, intente ejecutar:
docker-compose up
Que vemos
El contenedor se puso en marcha. Podemos verificar su funcionamiento:
echo '13123123123123123123123213123213' | nc localhost 5046
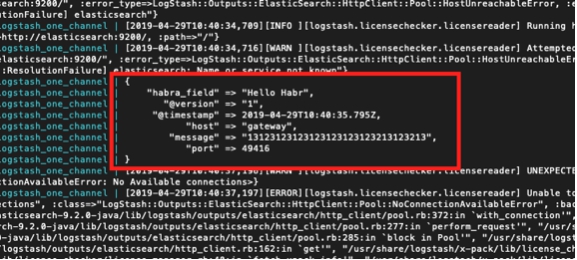
Y vemos la respuesta en la consola del contenedor:
Pero al mismo tiempo, también vemos:
logstash_one_channel | [2019-04-29T11: 28: 59,790]
[ERROR] [logstash.licensechecker.licensereader] No se puede recuperar la información de la licencia del servidor de licencias {: mensaje => "Elasticsearch inalcanzable: [http: // elasticsearch: 9200 /] [Manticore :: ResolutionFailure] elasticsearch ", ...
logstash_one_channel | [2019-04-29T11: 28: 59,894] [INFO] [logstash.pipeline] La canalización se
inició correctamente {: pipeline_id => ". Monitoring-logstash" ,: thread => "# <Thread: 0x119abb86 run>"}
logstash_one_channel | [2019-04-29T11: 28: 59,988] [INFO] [logstash.agent] Tuberías en ejecución {: count => 2 ,: running_pipelines => [: HABR ,: ". Monitoring-logstash"] ,: non_running_pipelines => [ ]}
logstash_one_channel | [2019-04-29T11: 29: 00,015]
[ERROR] [logstash.inputs.metrics] X-Pack está instalado en Logstash pero no en Elasticsearch. Instale X-Pack en Elasticsearch para usar la función de monitoreo. Otras características pueden estar disponibles.logstash_one_channel | [2019-04-29T11: 29: 00,526] [INFO] [logstash.agent] Se inició con éxito el punto final de la API de Logstash {: port => 9600}
logstash_one_channel | [2019-04-29T11: 29: 04,478] [INFO] [logstash.outputs.elasticsearch] Ejecutando la comprobación de estado para ver si una conexión Elasticsearch está funcionando {: healthcheck_url => http: // elasticsearch: 9200 / ,: path => "/"}
l
ogstash_one_channel | [2019-04-29T11: 29: 04,487]
[WARN] [logstash.outputs.elasticsearch] Intenté resucitar la conexión a una instancia ES muerta, pero recibí un error. {: url => “ elasticsearch : 9200 /” ,: error_type => LogStash :: Salidas :: ElasticSearch :: HttpClient :: Pool :: HostUnreachableError ,: error => “Elasticsearch inalcanzable: [http: // elasticsearch: 9200 / ] [Manticore :: ResolutionFailure] elasticsearch ”}logstash_one_channel | [2019-04-29T11: 29: 04,704] [INFO] [logstash.licensechecker.licensereader] Ejecutando la comprobación de estado para ver si una conexión Elasticsearch está funcionando {: healthcheck_url => http: // elasticsearch: 9200 / ,: path => "/"}
logstash_one_channel | [2019-04-29T11: 29: 04,710]
[WARN] [logstash.licensechecker.licensereader] Intenté resucitar la conexión a una instancia ES muerta, pero recibí un error. {: url => “ elasticsearch : 9200 /” ,: error_type => LogStash :: Salidas :: ElasticSearch :: HttpClient :: Pool :: HostUnreachableError ,: error => “Elasticsearch inalcanzable: [http: // elasticsearch: 9200 / ] [Manticore :: ResolutionFailure] elasticsearch ”}Y nuestro registro se está arrastrando todo el tiempo.
Aquí destaqué en verde un mensaje de que la tubería comenzó con éxito, rojo, un mensaje de error y amarillo, un mensaje sobre un intento de contactar con
Elasticsearch : 9200.
Esto sucede porque el logstash.conf incluido en la imagen tiene una verificación de disponibilidad de elasticsearch. Después de todo, logstash supone que funciona como parte de la pila de Elk, y lo separamos.
Puedes trabajar, pero no es conveniente.
La solución es deshabilitar esta verificación a través de la variable de entorno XPACK_MONITORING_ENABLED.
Realice un cambio en docker-compose.yml y ejecútelo de nuevo:
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro
Ahora todo está bien. El contenedor está listo para la experimentación.
Podemos escribir nuevamente en la próxima consola:
echo '13123123123123123123123213123213' | nc localhost 5046
Y mira:
logstash_one_channel | { logstash_one_channel | "message" => "13123123123123123123123213123213", logstash_one_channel | "@timestamp" => 2019-04-29T11:43:44.582Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "host" => "gateway", logstash_one_channel | "port" => 49418 logstash_one_channel | }
Trabajar dentro de un canal
Entonces, empezamos. Ahora puede tomarse el tiempo para configurar logstash directamente. No tocaremos el archivo pipelines.yml por ahora, veremos qué puede obtener trabajando con un canal.
Debo decir que el principio general de trabajar con el archivo de configuración del canal está bien descrito en la guía oficial,
aquíSi desea leer en ruso, utilizamos este
artículo aquí (pero la sintaxis de la consulta es antigua allí, debemos tener esto en cuenta).
Vayamos secuencialmente desde la sección de Entrada. Ya vimos trabajo en tcp. ¿Qué más podría ser de interés aquí?
Probar mensajes usando latidos
Existe una oportunidad tan interesante para generar mensajes de prueba automáticos.
Para hacer esto, debe incluir el complemento heartbean en la sección de entrada.
input { heartbeat { message => "HeartBeat!" } }
Encienda, comience una vez por minuto para recibir
logstash_one_channel | { logstash_one_channel | "@timestamp" => 2019-04-29T13:52:04.567Z, logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "HeartBeat!", logstash_one_channel | "@version" => "1", logstash_one_channel | "host" => "a0667e5c57ec" logstash_one_channel | }
Queremos obtener más a menudo, necesitamos agregar el parámetro de intervalo.
Así es como recibiremos un mensaje cada 10 segundos.
input { heartbeat { message => "HeartBeat!" interval => 10 } }
Recuperando datos de un archivo
También decidimos ver el modo de archivo. Si funciona normalmente con el archivo, entonces es posible que no se necesite ningún agente, bueno, al menos para uso local.
Según la descripción, el modo de funcionamiento debería ser similar a tail -f, es decir lee nuevas líneas o, como opción, lee todo el archivo.
Entonces, lo que queremos obtener:
- Queremos obtener líneas que se agregan a un archivo de registro.
- Queremos recibir datos que se escriben en varios archivos de registro, al tiempo que podemos compartir lo que vino.
- Queremos verificar que al reiniciar logstash no vuelva a recibir estos datos.
- Queremos verificar que si logstash está deshabilitado y los datos continúan siendo escritos en archivos, cuando los ejecutemos, obtendremos estos datos.
Para realizar el experimento, agregue otra línea a docker-compose.yml, abriendo el directorio en el que colocamos los archivos.
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro - ./logs:/usr/share/logstash/input
Y cambie la sección de entrada en habr_pipeline.conf
input { file { path => "/usr/share/logstash/input/*.log" } }
Empezamos:
docker-compose up
Para crear y grabar archivos de registro, usaremos el comando:
echo '1' >> logs/number1.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:28:53.876Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log" logstash_one_channel | }
Si, funciona!
Al mismo tiempo, vemos que agregamos automáticamente el campo de ruta. Entonces, en el futuro, podemos filtrar registros por él.
Intentemos de nuevo:
echo '2' >> logs/number1.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:28:59.906Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "2", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log" logstash_one_channel | }
Y ahora a otro archivo:
echo '1' >> logs/number2.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:29:26.061Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log" logstash_one_channel | }
Genial El archivo fue recogido, la ruta era correcta, todo está bien.
Detenga logstash y reinicie. Vamos a esperar El silencio Es decir No recibimos estos registros nuevamente.
Y ahora el experimento más atrevido.
Ponemos logstash y ejecutamos:
echo '3' >> logs/number2.log echo '4' >> logs/number1.log
Ejecute logstash nuevamente y vea:
logstash_one_channel | { logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "3", logstash_one_channel | "@version" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log", logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.589Z logstash_one_channel | } logstash_one_channel | { logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "4", logstash_one_channel | "@version" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log", logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.856Z logstash_one_channel | }
¡Hurra! Todo fue recogido.
Pero, debemos advertir sobre lo siguiente. Si se elimina el contenedor con logstash (docker stop logstash_one_channel && docker rm logstash_one_channel), no se recogerá nada. Dentro del contenedor, se guardó la posición del archivo en el que se leyó. Si se ejecuta desde cero, solo aceptará nuevas líneas.
Leer archivos existentes
Supongamos que ejecutamos logstash por primera vez, pero ya tenemos registros y nos gustaría procesarlos.
Si ejecutamos logstash con la sección de entrada que utilizamos anteriormente, no obtendremos nada. Logstash solo procesará las nuevas líneas.
Para extraer líneas de archivos existentes, agregue una línea adicional a la sección de entrada:
input { file { start_position => "beginning" path => "/usr/share/logstash/input/*.log" } }
Además, hay un matiz, esto solo afecta a los archivos nuevos que logstash aún no ha visto. Para los mismos archivos que ya cayeron en el campo de visión de logstash, ya recordó su tamaño y ahora solo tomará nuevas entradas en ellos.
Detengámonos en el estudio de la sección de entrada. Hay muchas más opciones, pero para nosotros, para más experimentos por ahora es suficiente.
Enrutamiento y conversión de datos
Intentemos resolver el siguiente problema, digamos que tenemos mensajes de un canal, algunos de ellos son informativos y, en parte, un mensaje de error. Difieren en la etiqueta. Algunos INFO, otros ERROR.
Necesitamos separarlos en la salida. Es decir Escribimos mensajes informativos en un canal y mensajes de error en otro.
Para hacer esto, vaya desde la sección de entrada a filtro y salida.
Usando la sección de filtro, analizaremos el mensaje entrante, obteniendo de él hash (pares clave-valor), con el que ya puede trabajar, es decir. Desmontar por condiciones. Y en la sección de salida, seleccionamos mensajes y enviamos cada uno a nuestro canal.
Analizando un mensaje usando grok
Para analizar cadenas de texto y obtener un conjunto de campos de ellas, hay un complemento especial en la sección de filtro: grok.
Sin el objetivo de dar aquí una descripción detallada aquí (para esto me refiero a la
documentación oficial ), daré mi ejemplo simple.
Para hacer esto, debe decidir el formato de las líneas de entrada. Los tengo
1 mensaje INFO1
2 mensaje de ERROR2
Es decir El identificador viene primero, luego INFO / ERROR, luego algunas palabras sin espacios.
No es difícil, pero es suficiente para entender cómo funciona.
Entonces, en la sección de filtro, en el plugin grok, necesitamos definir un patrón para analizar nuestras líneas.
Se verá así:
filter { grok { match => { "message" => ["%{INT:message_id} %{LOGLEVEL:message_type} %{WORD:message_text}"] } } }
Esto es esencialmente una expresión regular. Se utilizan patrones preparados, como INT, LOGLEVEL, WORD. Su descripción, así como otros patrones, se pueden encontrar
aquí.Ahora, pasando por este filtro, nuestra cadena se convertirá en un hash de tres campos: message_id, message_type, message_text.
Se mostrarán en la sección de salida.
Enrutamiento de mensajes en la sección de salida utilizando el comando if
En la sección de salida, como recordamos, íbamos a dividir los mensajes en dos flujos. Algunos, que iNFO, enviaremos a la consola, y con errores, enviaremos a un archivo.
¿Cómo dividimos estas publicaciones? La condición del problema ya indica la solución: ya tenemos el campo message_type seleccionado, que solo puede tomar dos valores INFO y ERROR. Es por él que haremos una elección usando la declaración if.
if [message_type] == "ERROR" { # } else { # stdout }
La descripción del trabajo con campos y operadores se puede encontrar en esta sección del
manual oficial .
Ahora, sobre la conclusión en sí misma.
La salida a la consola, todo está claro aquí - stdout {}
Y aquí está la salida del archivo: recuerde que lo ejecutamos todo desde el contenedor y para que el archivo en el que escribimos el resultado sea accesible desde el exterior, debemos abrir este directorio en docker-compose.yml.
Total:
La sección de salida de nuestro archivo se ve así:
output { if [message_type] == "ERROR" { file { path => "/usr/share/logstash/output/test.log" codec => line { format => "custom format: %{message}"} } } else {stdout { } } }
En docker-compose.yml agregue otro volumen a la salida:
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro - ./logs:/usr/share/logstash/input - ./output:/usr/share/logstash/output
Comenzamos, intentamos, vemos división en dos flujos.