Si alguna vez comparó los datos de dos herramientas analíticas en el mismo sitio o comparó análisis con informes y ventas, probablemente notó que no siempre coinciden. En este artículo, explicaré por qué no hay datos en las estadísticas de las plataformas de análisis web y qué tan grandes pueden ser estas pérdidas.
En este artículo, nos centraremos en Google Analytics, como el servicio analítico más popular, aunque la mayoría de las plataformas analíticas implementadas en la página tienen los mismos problemas. Los servicios que dependen de los registros del servidor evitan algunos de estos problemas, pero se usan tan raramente que no los cubriremos en este artículo.
Configuraciones de prueba de análisis en Destilado
En Distilled.net, tenemos un recurso estándar de Google Analtics que funciona desde una etiqueta HTML en Google Tag Manager. Además, en los últimos dos años, he usado tres implementaciones paralelas adicionales de Google Analytics, diseñadas para medir las diferencias entre las diferentes configuraciones.
Dos de estas implementaciones adicionales, una en GTM y la otra en la página, administran copias renombradas almacenadas localmente del archivo JavaScript de Google Analytics (www.distilled.net/static/js/au3.js en lugar de
www.google-analytics.com/ analytics.js ) para hacerlos más difíciles de detectar para los bloqueadores de anuncios.
También utilicé las funciones de JavaScript renombradas ("tcap" y "Bufón" en lugar del "ga" estándar) y los rastreadores renombrados ("FredTheUnblockable" y "AlbertTheImmutable") para evitar el problema de rastreadores duplicados (que a menudo pueden causar problemas).
Finalmente, tenemos la configuración "DianaTheIndefatigable", que tiene un rastreador renombrado, pero usa código estándar y se implementa a nivel de página.
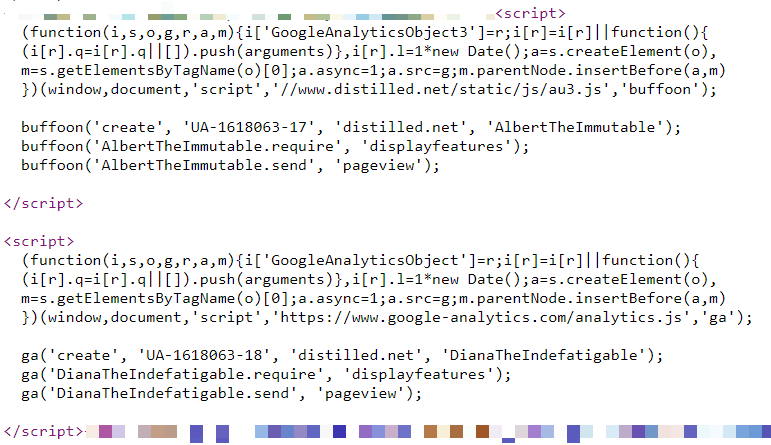
Todas nuestras configuraciones se muestran en la tabla a continuación:

Probé su funcionalidad en diferentes navegadores y bloqueadores de anuncios mediante el análisis de páginas vistas que aparecen en las herramientas de desarrollo del navegador:
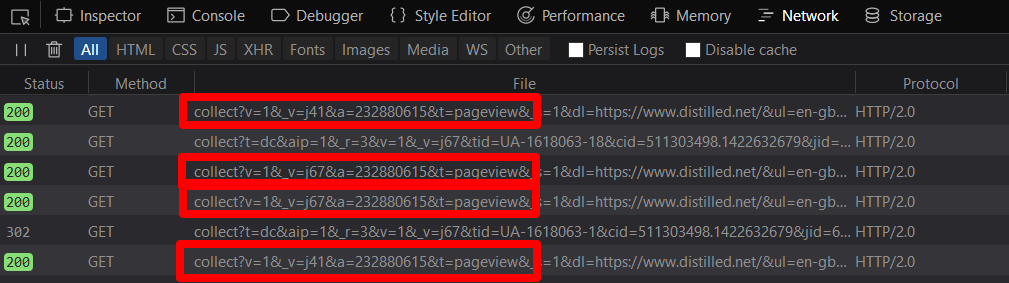
Razones para la pérdida de datos.
1. Bloqueadores de anuncios
Los bloqueadores de anuncios, principalmente en forma de extensiones de navegador, son cada vez más comunes. Inicialmente, la razón principal para su uso fue mejorar el rendimiento y la experiencia de interacción en sitios con una gran cantidad de publicidad. En los últimos años, el énfasis en la privacidad de los datos ha aumentado, lo que también ha contribuido a la popularidad de los bloqueadores de anuncios.
El efecto de los bloqueadores de anunciosAlgunos bloqueadores de anuncios bloquean las plataformas de análisis web de forma predeterminada; otros pueden configurarse aún más para realizar esta función. Probé el sitio web de Destilled con Adblock Plus y uBlock Origin, las dos extensiones de navegador de escritorio más populares para el bloqueo de anuncios, pero vale la pena señalar que los bloqueadores de anuncios también se usan cada vez más en los teléfonos inteligentes.
Se obtuvieron los siguientes resultados (todas las cifras corresponden a abril de 2018):
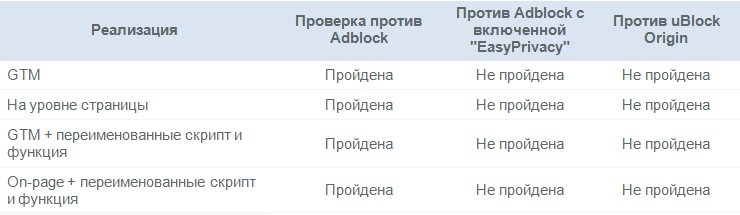
Como se puede ver en la tabla, la configuración cambiada de GA no ayuda mucho a resistir los bloqueadores.
Pérdida de datos debido a bloqueadores de anuncios: ~ 10%El uso de bloqueadores de anuncios puede estar en el nivel de 15-25% dependiendo de la región, pero muchas de estas configuraciones son AdBlock Plus con configuraciones predeterminadas, en las cuales, como vimos anteriormente, el seguimiento no está bloqueado.
La participación de AdBlock Plus en el mercado de bloqueadores de anuncios varía entre 50-70%.
Según estimaciones recientes , esta cifra está más cerca del 50%. Por lo tanto, si suponemos que no más del 50% de los bloqueadores de anuncios instalados bloquean el análisis, obtendremos una pérdida de datos de aproximadamente el 10%.
2. No rastrear la función en los navegadores
Esta es otra característica motivada por la protección de la privacidad. Pero esta vez no se trata del complemento, sino de la función de los navegadores. La solicitud No rastrear no es necesaria para sitios y plataformas, pero, por ejemplo, Firefox ofrece una función más sólida bajo el mismo conjunto de parámetros, que también decidí probar.
El efecto de No rastrearLa mayoría de los navegadores ahora ofrecen la opción de mensaje No rastrear. Probé las últimas versiones de los navegadores Firefox y Chrome para Windows 10.
 De nuevo, parece que la configuración modificada aquí tampoco ayuda mucho.Pérdida de datos debido a "No rastrear": <1%
De nuevo, parece que la configuración modificada aquí tampoco ayuda mucho.Pérdida de datos debido a "No rastrear": <1%Las pruebas mostraron que solo la función de Protección de seguimiento en el navegador Firefox Quantum afecta a los rastreadores. Firefox ocupa el 5% del mercado de navegadores, pero la protección de seguimiento no está habilitada de forma predeterminada. Por lo tanto, el lanzamiento de esta función no afectó las tendencias del tráfico de Firefox en Distilled.net.
3. Filtros
Los filtros que configura en el sistema de análisis pueden subestimar intencionalmente o no el volumen de tráfico recibido en los informes.
Por ejemplo, un filtro que excluye ciertas resoluciones de pantalla, que pueden ser bots o tráfico interno, conducirá claramente a una subestimación del tráfico.
Pérdida de datos debido a filtros: N / A
El impacto de este factor es difícil de evaluar, ya que esta configuración varía según el sitio. Pero le recomiendo tener una vista "principal" duplicada (sin filtros) para que pueda ver rápidamente la pérdida de información importante.
4. GTM vs en la página vs código ubicado incorrectamente
En los últimos años, Google Tag Manager se ha convertido en una forma cada vez más popular de implementar análisis debido a su flexibilidad y facilidad para realizar cambios. Sin embargo, hace mucho que noté que este método de implementación de GA puede conducir a una subestimación en comparación con la configuración de nivel de página.
También tenía curiosidad por saber qué sucedería si no seguía las recomendaciones de Google para configurar el código en la página.
Al combinar mis propios datos con los datos del
sitio de mi colega Dom Woodman, que usa la extensión analítica Drupal, así como GTM, pude ver la diferencia entre el Administrador de etiquetas y el código ubicado incorrectamente en la página (ubicado en la parte inferior de la etiqueta). Luego combiné estos datos con mis propios datos de GTM para ver la imagen completa en las 5 configuraciones.
Impacto de GTM y código en la página fuera de lugar
Tráfico como porcentaje de la línea de base (implementación estándar usando Tag Manager):
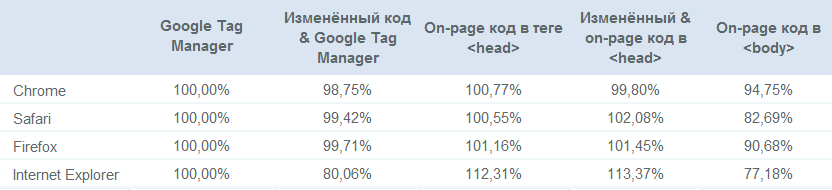
Resultados clave
- El código en la página generalmente registra más tráfico que GTM;
- El código modificado generalmente está dentro del margen de error, excepto el código GTM modificado en Internet Explorer;
- Un código de seguimiento ubicado incorrectamente le costará hasta el 30% de su tráfico en comparación con el código en la página implementado correctamente, dependiendo del navegador (!);
- Las configuraciones personalizadas diseñadas para recibir más tráfico al evitar los bloqueadores de anuncios no lo hacen.
También vale la pena señalar que las implementaciones de usuarios de hecho reciben menos tráfico que las estándar. En el caso del código en la página, las pérdidas están dentro del margen de error, pero en el caso de GTM hay otro matiz que podría afectar los datos finales.
Como utilicé perfiles sin filtrar para comparar, había mucho spam bot en el perfil principal, que en su mayoría estaba disfrazado de Internet Explorer.
Hoy, nuestro perfil principal es el más spam, pero también se utiliza como el nivel elegido para la comparación, por lo que la diferencia entre el código en la página y el Administrador de etiquetas es en realidad un poco mayor.
Pérdida de datos GTM: 1-5%
Las pérdidas asociadas con GTM varían según los navegadores y dispositivos que utilizan los visitantes de su sitio. En Distilled.net, la diferencia es de aproximadamente 1.7%, nuestra audiencia usa activamente escritorios y es técnicamente avanzada, Internet Explorer rara vez se usa. Dependiendo de la vertical, las pérdidas pueden alcanzar el 5%.
También hice un desglose por dispositivo:

Pérdida de datos debido a código incorrectamente ubicado en la página: ~ 10%
En Teflsearch.com, aproximadamente el 7,5% de los datos se perdieron debido a un código ubicado incorrectamente, contra GTM. Dado que el Tag Manager en sí subestima los datos, la pérdida total podría alcanzar fácilmente el 10%.
Bonus: pérdida de datos de canales
Arriba, examinamos áreas en las que puede perder datos en general. Sin embargo, hay otros factores que conducen a datos incompletos. Los consideraremos más brevemente. Los principales problemas aquí son el tráfico oscuro y la atribución.
Tráfico oscuroEl tráfico oscuro es tráfico directo, que no es realmente tráfico directo.
Y esto se está convirtiendo en una situación cada vez más común.
Causas típicas del tráfico oscuro:
- Campañas de marketing por correo electrónico sin marcar;
- Campañas sin marcar en aplicaciones (especialmente Facebook, Twitter, etc.);
- Tráfico orgánico distorsionado;
- Datos enviados debido a errores cometidos durante el proceso de configuración del seguimiento (también pueden aparecer como autorreferencias);
También vale la pena señalar una tendencia en la dirección del crecimiento del tráfico verdaderamente directo, que históricamente ha sido orgánico. Por ejemplo, en relación con la mejora de la función de autocompletar en los navegadores, la sincronización del historial de búsqueda en diferentes dispositivos, etc., las personas parecen "ingresar" la URL que buscaban antes.
Atribución
En general, una sesión en Google Analytics (y en cualquier otra plataforma) es una construcción bastante arbitraria. Puede resultarle obvio cómo se debe combinar un grupo de llamadas en una o más sesiones, pero en realidad, este proceso se basa en una serie de suposiciones bastante dudosas. En particular, vale la pena señalar que Google Analytics generalmente atribuye el tráfico directo (incluido el tráfico oscuro) a la fuente no directa anterior, si existe.
Conclusión
Algunos de los resultados que recibí me sorprendieron un poco, pero estoy seguro de que no cubrí todo, y hay otras formas de perder datos. Por lo tanto, la investigación en esta área puede continuar más.
Se pueden leer más artículos de este tipo en mi
canal de telegramas (proroas).