
Con el advenimiento de las cámaras de alta calidad en los teléfonos móviles, estamos fotografiando cada vez más y filmando videos de los momentos brillantes e importantes de nuestras vidas. Muchos de nosotros tenemos archivos fotográficos que datan de decenas de años y miles de fotografías, en los que cada vez es más difícil navegar. Recuerde cuánto tiempo llevó encontrar la foto correcta hace varios años.
Uno de los objetivos de Mail.ru Cloud es proporcionar el acceso y la búsqueda más convenientes en su archivo de fotos y videos. Para hacer esto, nosotros, el equipo de visión artificial de Mail.ru, hemos creado e implementado sistemas inteligentes de procesamiento de fotos: búsqueda por objetos, escenas, caras, etc. Otra tecnología tan llamativa es el reconocimiento de imágenes. Y hoy hablaré sobre cómo resolvimos este problema con la ayuda de Deep Learning.
Imagina la situación: te fuiste de vacaciones y trajiste un montón de fotos. Y en una conversación con amigos, te pidieron que mostraras cómo visitaste un palacio, castillo, pirámide, templo, lago, cascada, montaña, etc. Empiezas a desplazarte frenéticamente por la carpeta con fotos, tratando de encontrar la correcta. Lo más probable es que no lo encuentre entre cientos de imágenes y diga que lo mostrará más tarde.
Resolvemos este problema agrupando fotos personalizadas en álbumes. Esto facilita encontrar las imágenes correctas con solo unos pocos clics. Ahora tenemos álbumes en caras, en objetos y escenas, así como en atracciones.
Las fotos con puntos de referencia son importantes porque a menudo muestran momentos importantes de nuestras vidas (por ejemplo, viajes). Estas pueden ser fotografías en el fondo de alguna estructura arquitectónica o un rincón de la naturaleza que el hombre no haya tocado. Por lo tanto, necesitamos encontrar estas fotos y darles a los usuarios un acceso fácil y rápido a ellas.
Reconocimiento de funciones
Pero hay un matiz: no puedes simplemente tomar y entrenar algún modelo para reconocer las vistas, hay muchas dificultades.
- En primer lugar, no podemos describir claramente qué es un "hito". No podemos decir por qué un edificio es un hito, y estar junto a él no lo es. Este no es un concepto formalizado, lo que complica la formulación del problema de reconocimiento.
- En segundo lugar, las vistas son extremadamente diversas. Pueden ser edificios históricos o culturales: templos, palacios, castillos. Estos pueden ser los monumentos más diversos. Pueden ser objetos naturales: lagos, cañones, cascadas. Y un modelo debe poder encontrar todas estas atracciones.
- En tercer lugar, hay muy pocas imágenes con vistas, según nuestros cálculos, solo se encuentran en el 1-3% de las fotos de los usuarios. Por lo tanto, no podemos permitirnos errores en el reconocimiento, porque si mostramos a una persona una foto sin un punto de interés, se notará de inmediato y causará desconcierto y reacción negativa. O, por el contrario, le mostramos a la persona una foto con un punto de referencia en Nueva York, y nunca había estado en Estados Unidos. Por lo tanto, el modelo de reconocimiento debe tener una FPR baja (tasa de falsos positivos).
- Cuarto, aproximadamente el 50% de los usuarios, o incluso más, apagan el almacenamiento de información geográfica al fotografiar. Necesitamos tener esto en cuenta y determinar el lugar únicamente a partir de la imagen. La mayoría de los servicios que hoy en día logran trabajar con lugares de interés lo hacen gracias a los datos geográficos. Nuestros requisitos iniciales fueron más estrictos.
Mostraré ahora con ejemplos.
Aquí hay objetos similares, tres catedrales góticas francesas. A la izquierda está la Catedral de Amiens, en el centro de la Catedral de Reims, a la derecha está Notre Dame de Paris.

Incluso una persona necesita algo de tiempo para mirarlos y comprender que se trata de catedrales diferentes, y que la máquina también debe ser capaz de manejarlo, y más rápido que una persona.
Y aquí hay un ejemplo de otra dificultad: las tres fotos en la diapositiva son Notre Dame de Paris, tomadas desde diferentes ángulos. Las fotos resultaron ser muy diferentes, pero todas necesitan ser reconocidas y encontradas.

Los objetos naturales son completamente diferentes de los arquitectónicos. A la izquierda está Cesarea en Israel, a la derecha está el Parque Inglés en Munich.

En estas fotografías hay muy pocos detalles característicos para los cuales el modelo puede "captar".
Nuestro metodo
Nuestro método se basa completamente en redes neuronales convolucionales profundas. Como enfoque del aprendizaje, eligieron el llamado aprendizaje curricular: aprendizaje en varias etapas. Para trabajar de manera más eficiente tanto en presencia de geodatos como en ausencia de ellos, hicimos una inferencia especial (conclusión). Te contaré sobre cada una de las etapas con más detalle.
Datacet
El combustible para el aprendizaje automático son los datos. Y antes que nada, necesitábamos recopilar un conjunto de datos para la capacitación modelo.
Dividimos el mundo en 4 regiones, cada una de las cuales se utiliza en diferentes etapas de entrenamiento. Luego, se tomaron países en cada región, para cada país se compiló una lista de ciudades y se compiló una base de datos de fotografías de sus atracciones. A continuación se presentan ejemplos de datos.

Primero, tratamos de entrenar nuestro modelo en la base resultante. Los resultados fueron malos. Comenzaron a analizar, y resultó que los datos están muy "sucios". Cada atracción tenía una gran cantidad de basura. Que hacer La revisión manual de toda la gran cantidad de datos es costosa, triste y poco inteligente. Por lo tanto, hicimos una limpieza automática de la base, durante la cual el procesamiento manual se usa solo en un paso: para cada atracción, seleccionamos manualmente 3-5 fotografías de referencia que contienen con precisión la atracción deseada en una perspectiva más o menos correcta. Resulta bastante rápido, porque el volumen de dichos datos de referencia es pequeño en relación con toda la base de datos. Luego, ya se realiza una limpieza automática basada en redes neuronales convolucionales profundas.
Además, usaré el término "incrustación", por el cual entenderé lo siguiente. Tenemos una red neuronal convolucional, la entrenamos para la clasificación, cortamos la última capa de clasificación, tomamos algunas imágenes, atravesamos la red y obtuvimos un vector numérico en la salida. Lo llamaré incrustación.
Como dije, nuestra capacitación se llevó a cabo en varias etapas, correspondientes a partes de nuestra base de datos. Por lo tanto, primero tomamos una red neuronal de la etapa anterior o una red de inicialización.
Realizaremos las fotos de los lugares de interés a través de la red y realizaremos varias incrustaciones. Ahora puedes limpiar la base. Tomamos todas las imágenes del conjunto de datos para esta atracción, y también manejamos cada imagen a través de la red. Obtenemos un montón de incrustaciones y para cada una de ellas consideramos las distancias a la incrustación de estándares. Luego calculamos la distancia promedio, y si es más de un cierto umbral, que es el parámetro del algoritmo, consideramos que esta no es una atracción turística. Si la distancia promedio es menor que el umbral, entonces dejamos esta foto.
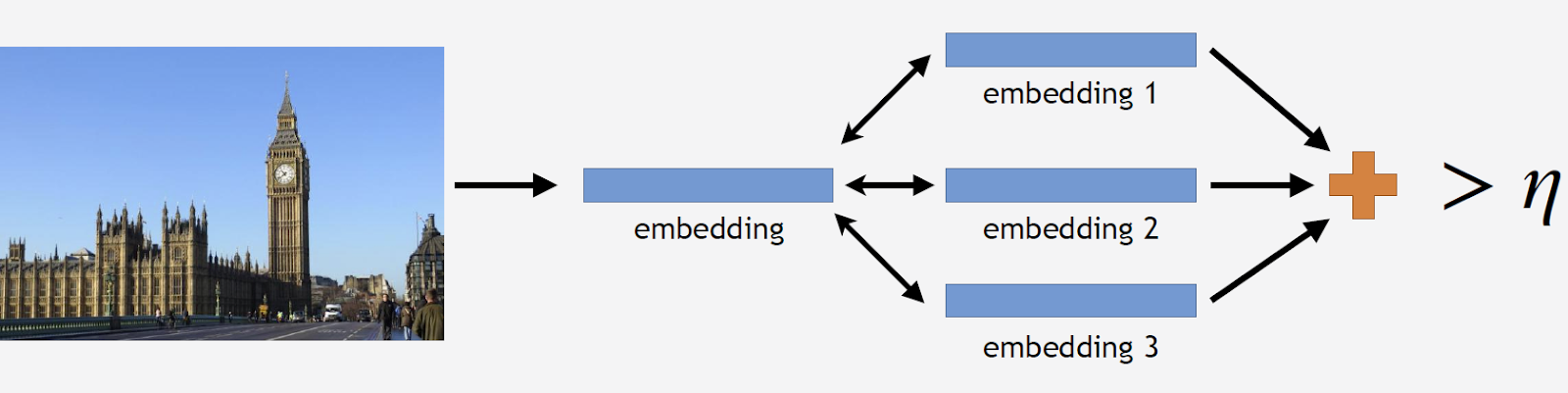
Como resultado, obtuvimos una base de datos que contiene más de 11 mil atracciones de más de 500 ciudades en 70 países del mundo, más de 2.3 millones de fotos. Ahora es el momento de recordar que la mayoría de las fotos no contienen atracciones en absoluto. Esta información debe ser compartida de alguna manera con nuestros modelos. Por lo tanto, agregamos 900 mil fotos sin vistas a nuestra base de datos y capacitamos a nuestro modelo en el conjunto de datos resultante.
Para medir la calidad de la capacitación, presentamos una prueba fuera de línea. Basado en el hecho de que las vistas se encuentran solo en aproximadamente el 1-3% de las fotografías, compilamos manualmente un conjunto de 290 fotografías que muestran vistas. Estas son fotografías diferentes y bastante complejas con una gran cantidad de objetos tomados desde diferentes ángulos, por lo que la prueba es lo más difícil posible para el modelo. Por el mismo principio, seleccionamos 11 mil fotografías sin vistas, que también son bastante complejas, e intentamos encontrar objetos que sean muy similares a las vistas disponibles en nuestra base de datos.
Para evaluar la calidad de la capacitación, medimos la precisión de nuestro modelo a partir de fotografías con y sin vistas. Estas son nuestras dos métricas principales.
Enfoques existentes
Hay relativamente poca información sobre el reconocimiento de la vista en la literatura científica. La mayoría de las soluciones se basan en características locales. La idea es que tenemos una determinada imagen de solicitud y una imagen de la base de datos. En estas imágenes encontramos signos locales, puntos clave y los comparamos. Si el número de coincidencias es lo suficientemente grande, creemos que hemos encontrado un punto de interés.
Hasta la fecha, el mejor método es el método propuesto por Google, DELF (funciones locales profundas), en el que una comparación de las funciones locales se combina con el aprendizaje profundo. Al ejecutar la imagen de entrada a través de la red de convolución, obtenemos algunos signos DELF.

¿Cómo es el reconocimiento de atracciones? Tenemos una base de datos de fotos y una imagen de entrada, y queremos entender si hay una atracción turística en ella o no. Corremos todas las imágenes a través de DELF, obtenemos los signos correspondientes para la base y para la imagen de entrada. Luego realizamos una búsqueda utilizando el método de vecinos más cercanos y en la salida obtenemos imágenes candidatas con signos. Comparamos estos signos con la ayuda de la verificación geométrica: si lo pasan con éxito, entonces creemos que hay un punto de interés en la imagen.
Red neuronal convolucional
Para el aprendizaje profundo, la capacitación previa es crucial. Por lo tanto, tomamos la base de escenas y preentrenamos en ella nuestra red neuronal. Por qué Una escena es un objeto complejo que incluye una gran cantidad de otros objetos. Y la atracción es un caso especial de la escena. Como modelo de pre-entrenamiento sobre esa base, podemos darle al modelo una idea de algunas características de bajo nivel que luego pueden generalizarse para el reconocimiento exitoso de las atracciones.
Como modelo, utilizamos una red neuronal de la familia de redes residuales. Su característica principal es que usan un bloque residual, que incluye una conexión de salto, que permite que la señal pase libremente sin meterse en capas con pesas. Con esta arquitectura, puede entrenar cualitativamente redes profundas y lidiar con el efecto de desenfoque de gradiente, que es muy importante al aprender.
Nuestro modelo es Wide ResNet 50-2, una modificación de ResNet 50, en la que el número de convoluciones en el bloque de cuello de botella interno se duplica.

La red es muy eficiente. Realizamos pruebas en nuestra base de datos de escenas y esto es lo que obtuvimos:
Wide ResNet resultó ser casi el doble de rápido que la red ResNet 200 bastante grande. Y la velocidad de operación es muy importante para la operación. En base a la totalidad de estas circunstancias, tomamos Wide ResNet 50-2 como nuestra red neuronal principal.
Entrenamiento
Para entrenar la red, necesitamos pérdida (función de pérdida). Para seleccionarlo, decidimos utilizar el enfoque de aprendizaje métrico: se entrena una red neuronal para que los representantes de la misma clase se unan en un grupo. Al mismo tiempo, los grupos para diferentes clases deben estar lo más separados posible. Para las atracciones, utilizamos la pérdida de centro, que reúne puntos de la misma clase en un determinado centro. Una característica importante de este enfoque es que no requiere muestreo negativo, que en las últimas etapas del entrenamiento es un procedimiento bastante difícil.
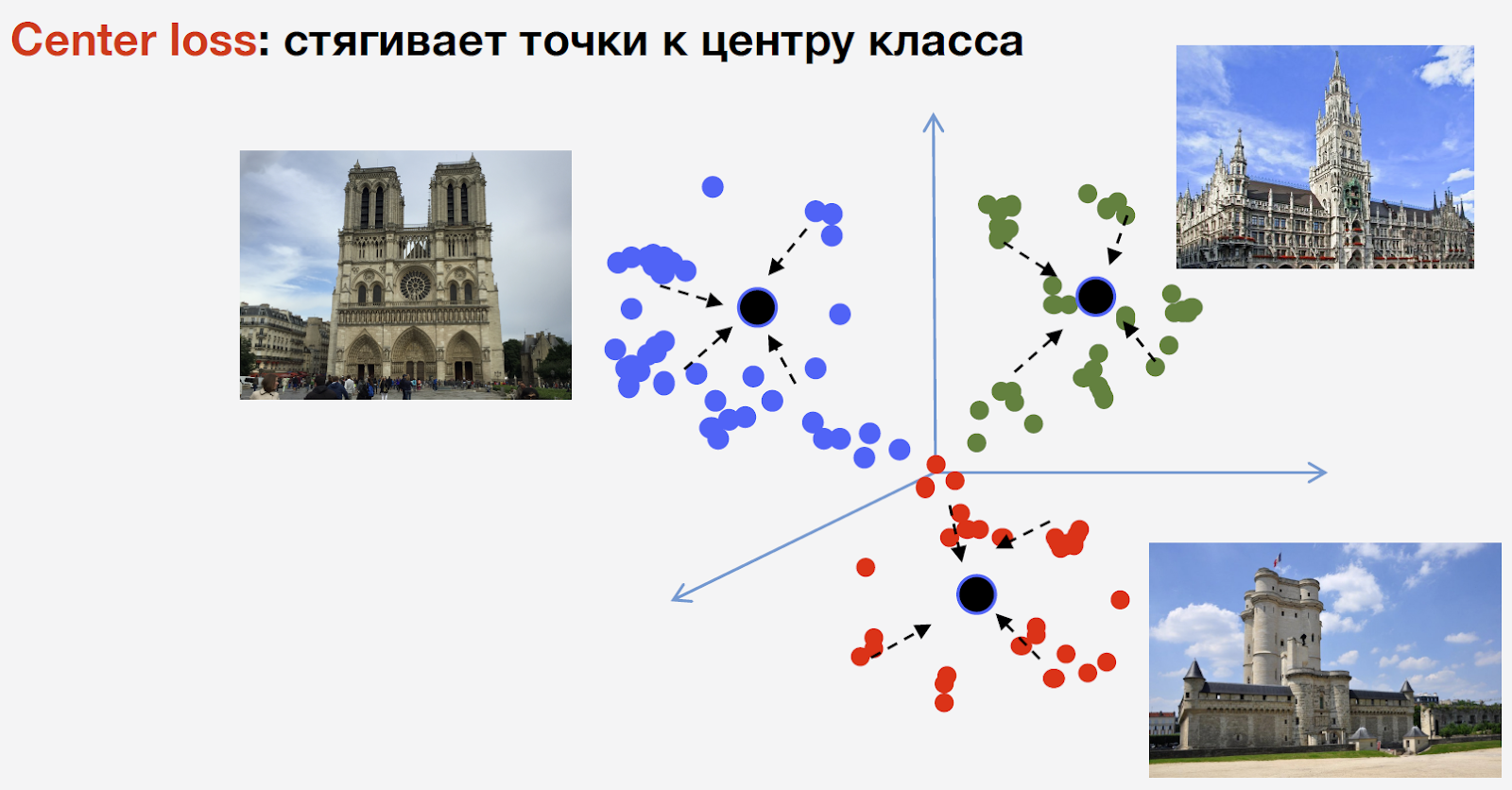
Permítame recordarle que tenemos n clases de atracciones y otra clase de "no atracciones", la pérdida de Centro no se utiliza para ello. Queremos decir que un punto de referencia es el mismo objeto y que tiene una estructura, por lo tanto, es aconsejable considerar un centro para él. Pero una atracción turística no puede ser nada, y considerar el centro para él no es razonable.
Luego lo armamos todo y obtuvimos un modelo para el entrenamiento. Consta de tres partes principales:
- Red neuronal convolucional Wide ResNet 50-2, pre-entrenada en base a escenas;
- Partes de incrustación que consisten en una capa completamente conectada y una capa de norma de Batch;
- Un clasificador, que es una capa totalmente conectada, seguido de un par de pérdida Softmax y pérdida central.

Como recordará, nuestra base está dividida en 4 partes por región del mundo. Utilizamos estas 4 partes como parte del paradigma de aprendizaje curricular. En cada etapa, tenemos el conjunto de datos actual, le agregamos otra parte del mundo y obtenemos un nuevo conjunto de datos de capacitación.
El modelo consta de tres partes, y para cada una de ellas utilizamos nuestra propia tasa de aprendizaje en la capacitación. Esto es necesario para que la red no solo pueda aprender las vistas de la nueva parte del conjunto de datos que agregamos, sino también que no olvide los datos ya aprendidos. Después de muchos experimentos, este enfoque resultó ser el más efectivo.
Entonces, entrenamos al modelo. Necesitas entender cómo funciona. Usemos el mapa de activación de clase para ver qué parte de la imagen responde mejor a nuestra red neuronal. En la siguiente imagen, en la primera fila, las imágenes de entrada, y en la segunda, se superponen el mapa de activación de clase de la cuadrícula, que hemos entrenado en el paso anterior.

El mapa de calor muestra en qué partes de la imagen se está enfocando la red. Del mapa de activación de clase se puede ver que nuestra red neuronal ha aprendido con éxito el concepto de atracción.
Inferencia
Ahora necesita utilizar de alguna manera este conocimiento para obtener el resultado. Como utilizamos la pérdida del Centro para el entrenamiento, parece lógico deducir que también se calcula el tserotoide para las atracciones.
Para esto, tomamos parte de las imágenes del conjunto de entrenamiento para algún tipo de atracción, por ejemplo, para el Jinete de Bronce. Los ejecutamos a través de la red, obtenemos incrustaciones, promediamos y obtenemos un centroide.
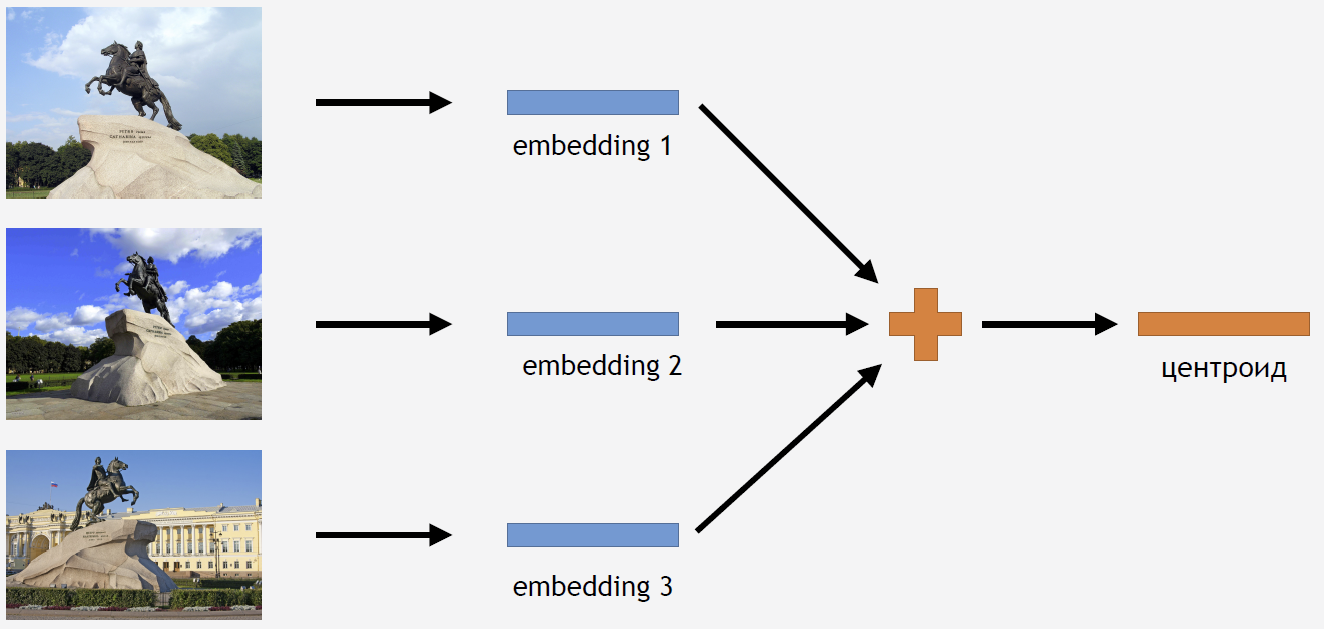
Pero surge la pregunta: ¿cuántos centroides para una atracción tiene sentido calcular? Al principio, la respuesta parece clara y lógica: un centroide. Pero esto resultó no ser así. Al principio, también decidimos hacer un centroide y obtuvimos un resultado bastante bueno. Entonces, ¿por qué necesitas tomar algunos centroides?
En primer lugar, nuestros datos no están completamente limpios. Aunque limpiamos el conjunto de datos, solo eliminamos la basura. Y podríamos tener imágenes que no podrían considerarse basura, pero que empeorarían el resultado.
Por ejemplo, tengo una clase histórica de Palacio de Invierno. Quiero contar un centroide para él. Pero el conjunto incluía una serie de fotografías con la Plaza del Palacio y el arco del Edificio del Estado Mayor. Si consideramos el centroide en todas las imágenes, resultará no demasiado estable. Es necesario agrupar de alguna manera sus incrustaciones, que se obtienen de la cuadrícula habitual, tomar solo el centroide que es responsable del Palacio de Invierno y calcular el promedio de acuerdo con estos datos.

En segundo lugar, se pueden tomar fotografías desde diferentes ángulos.
Citaré el campanario de Belfort en Brujas como una ilustración de este comportamiento. Se cuentan dos centroides para ella. En la fila superior de la imagen están las fotos que están más cerca del primer centroide, y en la segunda fila, las que están más cerca del segundo centroide:

El primer centroide es responsable de las fotografías de primeros planos más "inteligentes" tomadas desde la Plaza del Mercado de Brujas. Y el segundo centroide es responsable de las fotografías tomadas desde lejos, desde las calles adyacentes.
Resulta que al calcular varios centroides por clase de un punto de interés, podemos mostrar diferentes ángulos de este punto de interés en inferencia.
Entonces, ¿cómo encontramos estos conjuntos para calcular los centroides? Aplicamos agrupamiento jerárquico a los conjuntos de datos para cada punto de interés: enlace completo. Con su ayuda, encontramos grupos válidos mediante los cuales calcularemos los centroides. Por grupos válidos nos referimos a aquellos que, como resultado de la agrupación, contienen al menos 50 fotografías. Los grupos restantes se descartan. Como resultado, resultó que aproximadamente el 20% de las vistas tienen más de un centroide.
Ahora inferencia. Lo calculamos en dos etapas: primero, ejecutamos la imagen de entrada a través de nuestra red neuronal convolucional y realizamos la incrustación, y luego, usando el producto escalar, comparamos la incrustación con los centroides. Si las imágenes contienen geodatos, restringimos la búsqueda a los centroides, que se relacionan con las atracciones ubicadas en un cuadrado de 1 por 1 km desde el lugar de disparo. Esto le permite buscar con mayor precisión, elegir un umbral más bajo para la comparación posterior. Si la distancia obtenida es mayor que el umbral, que es un parámetro del algoritmo, entonces decimos que en la foto hay un punto de interés con el valor máximo del producto escalar. Si menos, entonces esto no es una atracción turística.
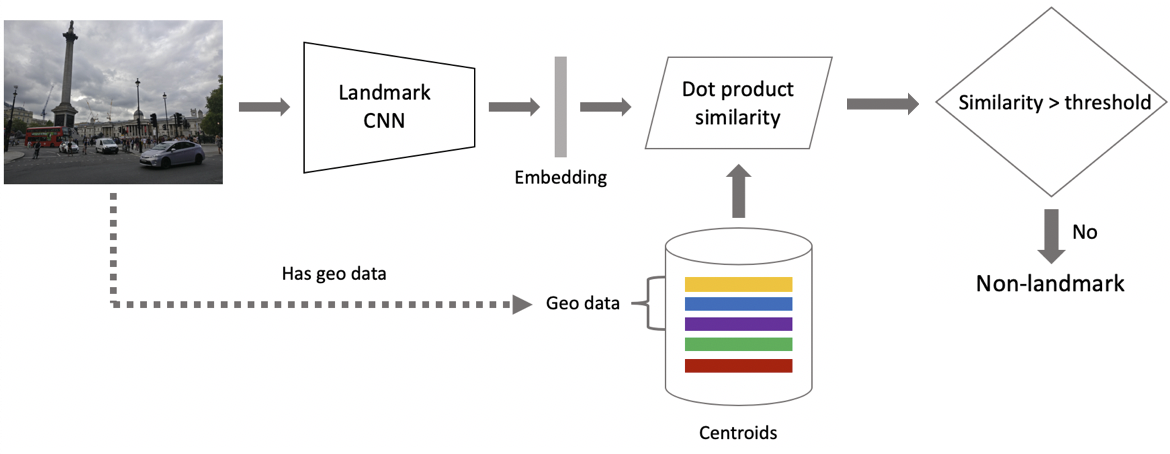
Supongamos que la foto contiene un hito. , . , . , . , -. - , , . , , .
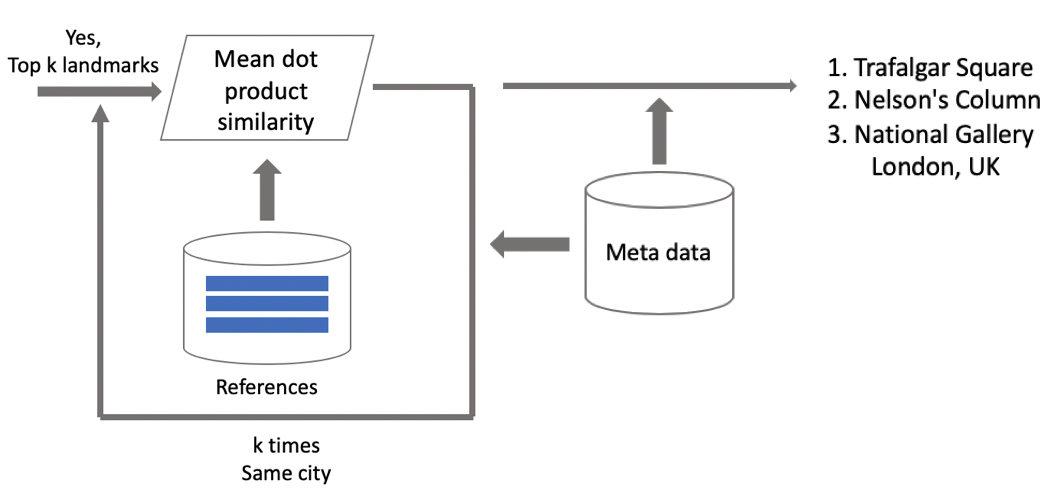
Resultados de la prueba
DELF, , . .
: ( 100 ), 87 % , . : 85,3 %. 46 %, — .
/B- . 10 %, 3 %, 13 %.
DELF. GPU DELF 7 , 7 , 1 . CPU DELF . CPU 15 . , .
:
. .
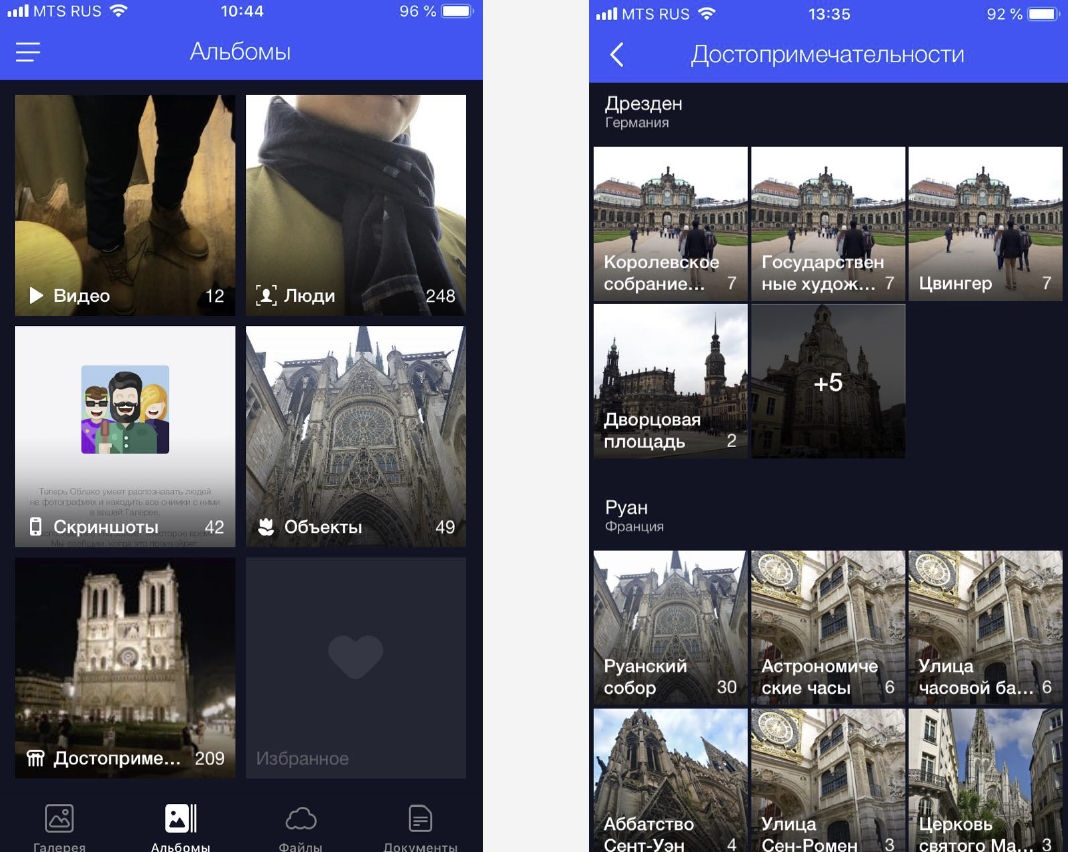
, . «», «», «». , . , .
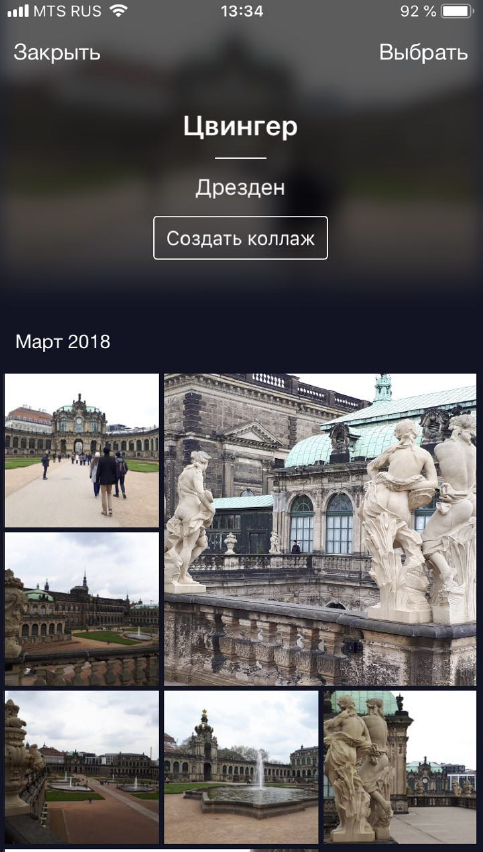
: , , . Instagram , , — .
.
- . , . .
- deep metric learning, .
- curriculum learning — . . inference , .
, — . , , . - . !