Hola a todos! Mi nombre es Pavel Agaletsky. Trabajo como líder de equipo en un equipo que desarrolla un sistema de entrega Lamoda. En 2018, hablé en la conferencia HighLoad ++, y hoy quiero presentar una transcripción de mi informe.
Mi tema está dedicado a la experiencia de nuestra empresa en la implementación de sistemas y servicios en diferentes entornos. Comenzando desde nuestros tiempos prehistóricos, cuando implementamos todos los sistemas en servidores virtuales regulares, terminando con una transición gradual de Nomad a una implementación en Kubernetes. Te diré por qué hicimos esto y qué problemas tuvimos en el proceso.
Implementar aplicaciones en VM
Para empezar, hace 3 años, todos los sistemas y servicios de la compañía se implementaron en servidores virtuales comunes. Técnicamente, se organizó para que todo el código de nuestros sistemas se distribuyera y ensamblara utilizando herramientas de compilación automáticas con jenkins. Con Ansible, estaba implementando nuestro sistema de control de versiones en servidores virtuales. Además, cada sistema que estaba en nuestra empresa se implementó al menos en 2 servidores: uno de ellos, en la cabeza, el segundo, en la cola. Estos dos sistemas eran absolutamente idénticos entre sí en todos sus ajustes, potencia, configuración y más. La única diferencia entre ellos era que la cabeza recibía tráfico de usuarios, mientras que la cola nunca recibía tráfico de usuarios.
¿Por qué se hizo esto?
Cuando implementamos nuevas versiones de nuestra aplicación, queríamos ofrecer la posibilidad de un despliegue continuo, es decir, sin consecuencias notables para los usuarios. Esto se logró debido al hecho de que la próxima versión ensamblada con Ansible se lanzó en cola. Allí, las personas que participaron en el despliegue pudieron verificar y asegurarse de que todo estaba bien: todas las métricas, secciones y aplicaciones funcionaron; Se inician los scripts necesarios. Solo después de que se convencieron de que todo está bien, se cambió el tráfico. Comenzó a ir al servidor que antes era cola. Y el que era la cabeza antes, se quedó sin tráfico de usuarios, mientras que con la versión anterior de nuestra aplicación.
Por lo tanto, para los usuarios fue perfecto. Porque la conmutación es simultánea, ya que es solo una conmutación equilibradora. Es muy fácil volver a la versión anterior simplemente cambiando el balanceador hacia atrás. También podríamos verificar la capacidad de producción de la aplicación incluso antes de que el tráfico de usuarios llegue a ella, lo cual fue lo suficientemente conveniente.
¿Qué ventajas vimos en todo esto?
- En primer lugar, funciona de manera bastante simple. Todos entienden cómo funciona este esquema de implementación, porque la mayoría de las personas se han implementado en servidores virtuales comunes.
- Esto es bastante confiable , ya que la tecnología de implementación es simple, probada por miles de empresas. Millones de servidores se implementan de esa manera. Es difícil romper algo.
- Y finalmente, podríamos obtener despliegues atómicos . Implementaciones que ocurren a los usuarios simultáneamente, sin una etapa notable de cambio entre la versión anterior y la nueva.
Pero en esto también vimos varias deficiencias:
- Además del entorno de producción, el entorno de desarrollo, hay otros entornos. Por ejemplo, qa y preproducción. En ese momento, teníamos muchos servidores y unos 60 servicios. Por esta razón, era necesario que cada servicio mantuviera la versión de la máquina virtual que le era relevante . Además, si desea actualizar bibliotecas o instalar nuevas dependencias, debe hacerlo en todos los entornos. También era necesario sincronizar la hora en la que iba a implementar la próxima versión nueva de su aplicación con la hora en que los desarrolladores hicieron la configuración de entorno necesaria. En este caso, es fácil entrar en una situación en la que nuestro entorno será ligeramente diferente a la vez en todos los entornos seguidos. Por ejemplo, en el entorno de QA habrá algunas versiones de bibliotecas, y en producción, otras, lo que generará problemas.
- Dificultad para actualizar las dependencias de su aplicación. No depende de ti, sino del otro equipo. Es decir, desde el comando devops, que admite el servidor. Debe establecer una tarea adecuada para ellos y dar una descripción de lo que desea hacer.
- En ese momento, también queríamos dividir los grandes monolitos grandes que teníamos en pequeños servicios separados, ya que entendimos que habría más y más de ellos. En ese momento, ya teníamos más de 100 de ellos. Era necesario que cada nuevo servicio creara una nueva máquina virtual separada, que también necesita ser reparada e implementada. Además, no necesita un automóvil, sino al menos dos. A esto, el entorno de control de calidad todavía se está agregando. Esto causa problemas y hace que crear y lanzar nuevos sistemas sea más difícil, costoso y lento para usted.
Por lo tanto, decidimos que sería más conveniente pasar de la implementación de máquinas virtuales ordinarias a la implementación de nuestras aplicaciones en el contenedor docker. Si tiene docker, necesita un sistema que pueda ejecutar la aplicación en el clúster, ya que no puede simplemente levantar el contenedor. Por lo general, desea realizar un seguimiento de cuántos contenedores se levantan para que se eleven automáticamente. Por esta razón, tuvimos que elegir un sistema de control.
Pensamos durante mucho tiempo sobre cuál se puede tomar. El hecho es que en ese momento esta pila de implementaciones en servidores virtuales comunes estaba algo desactualizada, ya que no había las últimas versiones de los sistemas operativos allí. En algún momento, incluso FreeBSD se quedó allí, lo que no era muy conveniente de mantener. Entendemos que debe migrar a Docker lo más rápido posible. Nuestros desarrolladores analizaron su experiencia existente con diferentes soluciones y eligieron un sistema como Nomad.
Cambiar a nómada
Nomad es un producto de HashiCorp. También son conocidos por sus otras decisiones:
 Consul
Consul es una herramienta para el descubrimiento de servicios.
Terraform es un sistema de administración de servidores que le permite configurarlos a través de una configuración llamada infraestructura como código.
Vagrant le permite implementar máquinas virtuales localmente o en la nube a través de archivos de configuración específicos.
Nomad en ese momento parecía una solución bastante simple a la que puede cambiar rápidamente sin cambiar toda la infraestructura. Además, se domina con bastante facilidad. Por lo tanto, lo elegimos como nuestro sistema de filtro para nuestro contenedor.
¿Qué se necesita para implementar completamente su sistema en Nomad?
- En primer lugar, necesita la imagen acoplable de su aplicación. Debe compilarlo y colocarlo en el almacenamiento de imágenes de la ventana acoplable. En nuestro caso, esto es un artefacto, un sistema que le permite insertar varios artefactos de varios tipos. Puede almacenar archivos, imágenes acoplables, paquetes de compositor PHP, paquetes NPM, etc.
- También necesita un archivo de configuración que le indique a Nomad qué, dónde y cuánto desea implementar.
Cuando hablamos de Nomad, utiliza el lenguaje HCL como un formato de archivo de información, que significa
HashiCorp Configuration Language . Este es un superconjunto de Yaml que le permite describir su servicio en términos de Nomad.

Le permite decir cuántos contenedores desea implementar, desde qué imágenes transferirles varios parámetros durante la implementación. Por lo tanto, alimenta este archivo Nomad y lanza contenedores en producción de acuerdo con él.
En nuestro caso, nos dimos cuenta de que simplemente escribir exactamente los mismos archivos HLC idénticos para cada servicio no sería muy conveniente, porque hay muchos servicios y, a veces, desea actualizarlos. Sucede que un servicio se implementa no en una instancia, sino en las más diferentes. Por ejemplo, uno de los sistemas que tenemos en producción tiene más de 100 instancias en la producción. Se inician desde las mismas imágenes, pero difieren en la configuración y los archivos de configuración.
Por lo tanto, decidimos que sería conveniente para nosotros almacenar todos nuestros archivos de configuración para la implementación en un repositorio común. Por lo tanto, se volvieron observables: eran fáciles de mantener y era posible ver qué sistemas teníamos. Si es necesario, también es fácil actualizar o cambiar algo. Agregar un nuevo sistema tampoco es difícil: solo ingrese el archivo de configuración dentro del nuevo directorio. En su interior están los archivos: service.hcl, que contiene una descripción de nuestro servicio, y algunos archivos env que permiten que este servicio, que se implementa en producción, se configure.

Sin embargo, algunos de nuestros sistemas se implementan en el producto no en una copia, sino en varias a la vez. Por lo tanto, decidimos que sería conveniente para nosotros no almacenar configuraciones en su forma pura, sino en su forma de plantilla. Y como lenguaje de plantilla elegimos
jinja 2 . En este formato, almacenamos tanto las configuraciones del servicio como los archivos env necesarios para ello.
Además, colocamos en el repositorio un despliegue de secuencia de comandos común para todos los proyectos, lo que le permite lanzar e implementar su servicio en producción, en el entorno deseado, en el objetivo deseado. En el caso en que convertimos nuestra configuración HCL en una plantilla, el archivo HCL, que anteriormente era una configuración Nomad normal, en este caso comenzó a verse un poco diferente.
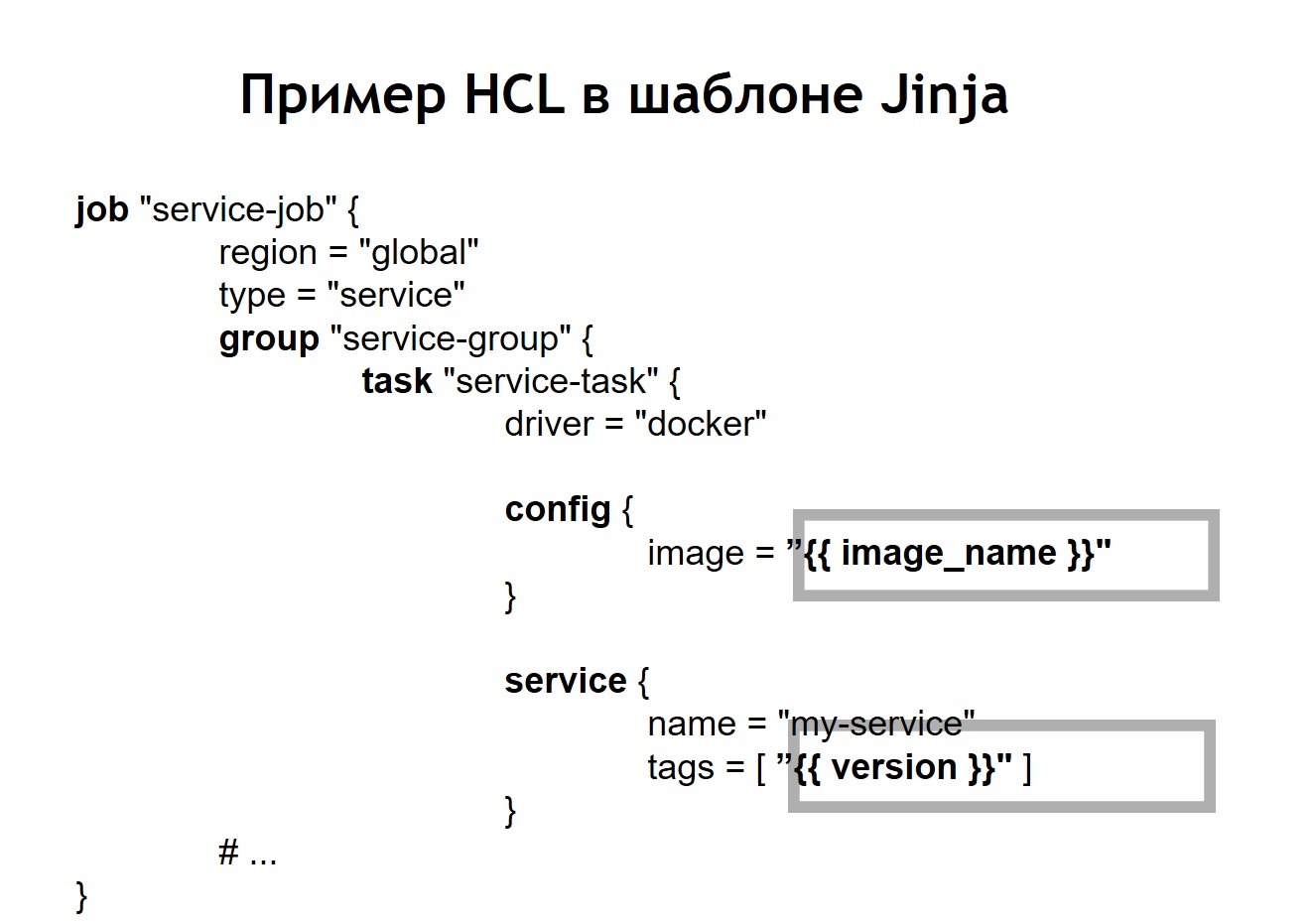
Es decir, reemplazamos algunas variables en el archivo de configuración con inserciones variables, que se toman de los archivos env o de otras fuentes. Además, pudimos recopilar archivos HL dinámicamente, es decir, podemos usar no solo las inserciones variables habituales. Dado que jinja admite bucles y condiciones, también puede crear archivos de configuración allí, que varían según dónde implemente exactamente sus aplicaciones.
Por ejemplo, desea implementar su servicio en preproducción y en producción. Suponga que en la preproducción no desea ejecutar scripts de corona, solo desea ver el servicio en un dominio separado para asegurarse de que esté funcionando. Para cualquiera que implemente un servicio, el proceso parece muy simple y transparente. Es suficiente para ejecutar el archivo deploy.sh, especifique qué servicio desea implementar y en qué destino. Por ejemplo, desea implementar un determinado sistema en Rusia, Bielorrusia o Kazajstán. Para hacer esto, simplemente cambie uno de los parámetros y tendrá el archivo de configuración correcto.
Cuando el servicio Nomad ya está implementado en su clúster, se ve así.
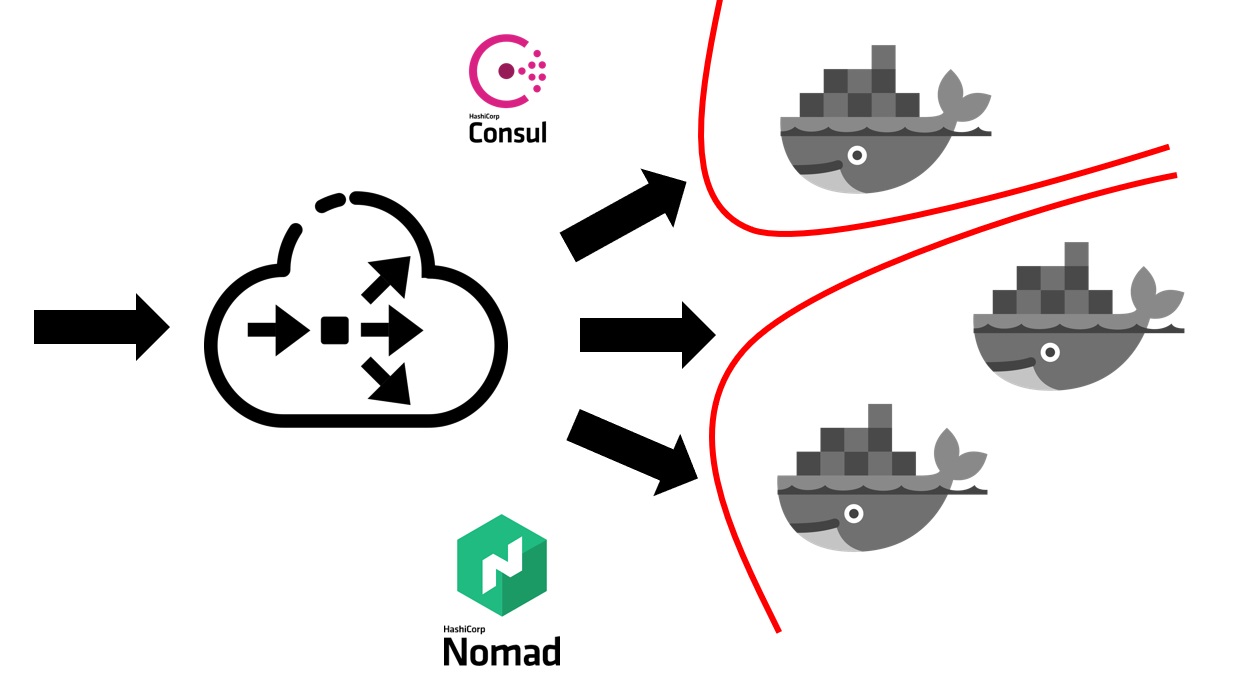
Primero, necesita un equilibrador externo que incorpore todo el tráfico de usuarios. Trabajará junto con Cónsul y descubrirá de él dónde, en qué nodo, en qué dirección IP hay un servicio específico que corresponde a un nombre de dominio particular. Los servicios en Consul provienen del propio Nomad. Como se trata de productos de la misma empresa, están bien conectados. Podemos decir que Nomad listo para usar puede registrar todos los servicios lanzados en él dentro de Consul.
Después de que su equilibrador externo descubre a qué servicio es necesario enviar tráfico, lo redirige al contenedor apropiado oa varios contenedores que corresponden a su aplicación. Naturalmente, también es necesario pensar en la seguridad. Aunque todos los servicios se ejecutan en las mismas máquinas virtuales en contenedores, esto generalmente requiere la prohibición del acceso gratuito de cualquier servicio a cualquier otro. Logramos esto a través de la segmentación. Cada servicio se lanzó en su propia red virtual, en la que se prescribieron reglas de enrutamiento y reglas para permitir / denegar el acceso a otros sistemas y servicios. Podrían ubicarse tanto dentro de este grupo como fuera de él. Por ejemplo, si desea evitar que un servicio se conecte a una base de datos específica, esto puede hacerse mediante la segmentación a nivel de red. Es decir, incluso por error, no puede conectarse accidentalmente desde un entorno de prueba a su base de producción.
¿Cuánto nos costó la transición en términos de recursos humanos?
La transición de toda la compañía a Nomad tomó alrededor de 5-6 meses. Cambiamos sin servicio, pero a un ritmo bastante rápido. Cada equipo tuvo que crear sus propios contenedores para los servicios.
Hemos adoptado un enfoque tal que cada equipo es responsable de las imágenes acopladas de sus sistemas por su cuenta. Los Devops también proporcionan la infraestructura general necesaria para la implementación, es decir, soporte para el clúster en sí, soporte para el sistema CI, etc. Y en ese momento teníamos más de 60 sistemas trasladados a Nomad, que resultó en unos 2 mil contenedores.
Devops es responsable de la infraestructura general de todo lo relacionado con la implementación, con los servidores. Y cada equipo de desarrollo, a su vez, es responsable de la implementación de contenedores para su sistema específico, ya que es el equipo que sabe lo que generalmente necesita en un contenedor en particular.
Razones para abandonar a Nomad
¿Qué ventajas obtuvimos al cambiar a implementar usando Nomad y Docker también?
- Proporcionamos las mismas condiciones para todos los entornos. En una empresa de desarrollo, entorno de control de calidad, preproducción, producción, se utilizan las mismas imágenes de contenedor, con las mismas dependencias. En consecuencia, prácticamente no tiene posibilidades de que la producción resulte ser diferente de lo que probó anteriormente localmente o en un entorno de prueba.
- También descubrimos que es bastante fácil agregar un nuevo servicio . Desde el punto de vista de la implementación, cualquier sistema nuevo se lanza de manera muy simple. Es suficiente ir al repositorio que almacena las configuraciones, agregar la siguiente configuración para su sistema allí y ya está listo. Puede implementar su sistema en producción sin esfuerzo adicional de los desarrolladores.
- Todos los archivos de configuración en un repositorio común resultaron ser monitoreados . En ese momento, cuando implementamos nuestros sistemas usando servidores virtuales, usamos Ansible, en el que las configuraciones se encuentran en el mismo repositorio. Sin embargo, para la mayoría de los desarrolladores fue un poco más difícil trabajar con ellos. Aquí, el volumen de configuraciones y código que necesita agregar para implementar el servicio se ha vuelto mucho más pequeño. Además para devops es muy fácil arreglarlo o cambiarlo. En el caso de las transiciones, por ejemplo, en la nueva versión de Nomad, pueden tomar y actualizar masivamente todos los archivos operativos que se encuentran en el mismo lugar.
Pero también enfrentamos varias deficiencias:
Resultó que no
pudimos lograr implementaciones sin problemas en el caso de Nomad. Al sacar los contenedores de diferentes condiciones, podría resultar que se estaba ejecutando, y Nomad lo percibió como un contenedor listo para aceptar el tráfico. Esto sucedió incluso antes de que la aplicación en su interior se iniciara. Por esta razón, el sistema comenzó a producir 500 errores por poco tiempo, porque el tráfico comenzó a ir al contenedor, que aún no está listo para recibirlo.
Nos encontramos con algunos
errores . El error más significativo es que Nomad no acepta muy bien un clúster grande si tiene muchos sistemas y contenedores. Cuando desee poner en servicio uno de los servidores incluidos en el clúster Nomad, existe una alta probabilidad de que el clúster no se sienta muy bien y se desmorone. Parte de los contenedores puede, por ejemplo, caerse y no elevarse, lo que posteriormente será muy costoso para usted si todos sus sistemas de producción están ubicados en un clúster administrado por Nomad.
Por lo tanto, decidimos pensar a dónde ir después. En ese momento, nos dimos cuenta de lo que queríamos lograr. A saber: queremos confiabilidad, un poco más de funciones que las que ofrece Nomad y un sistema más maduro y estable.
En este sentido, nuestra elección recayó en Kubernetes como la plataforma más popular para el lanzamiento de clústeres. Especialmente siempre que el tamaño y la cantidad de nuestros contenedores fuera bastante grande. Para tales propósitos, Kubernetes parecía el sistema más adecuado de los que podíamos ver.
Yendo a Kubernetes
Hablaré un poco sobre los conceptos básicos de Kubernetes y cómo se diferencian de Nomad.
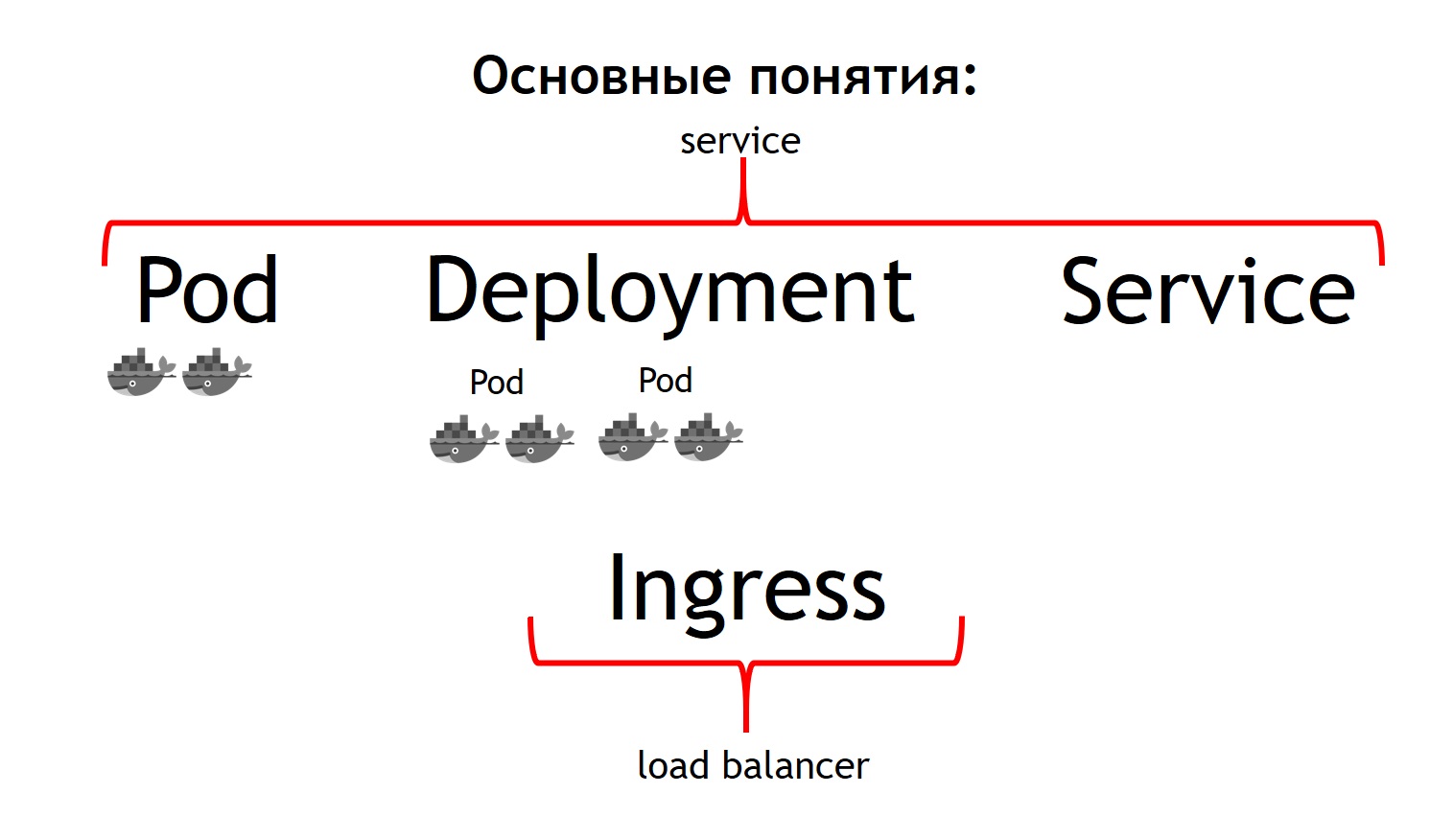
En primer lugar, el concepto más básico en Kubernetes es el concepto de pod.
Un pod es un grupo de uno o más contenedores que siempre se ejecutan juntos. Y parecen funcionar siempre estrictamente en la misma máquina virtual. Están disponibles entre sí a través de IP 127.0.0.1 en diferentes puertos.
Supongamos que tiene una aplicación PHP que consiste en nginx y php-fpm, un circuito clásico. Lo más probable es que desee que los contenedores nginx y php-fpm estén siempre juntos. Kubernetes hace esto describiéndolos como una vaina común. Esto es exactamente lo que no pudimos obtener con la ayuda de Nomad.
El segundo concepto es el
despliegue . El hecho es que la cápsula en sí es algo efímero, comienza y desaparece. Ya sea que desee eliminar primero todos sus contenedores anteriores y luego lanzar nuevas versiones a la vez, o si desea implementarlos gradualmente, este es el concepto del que es responsable la implementación. Describe cómo despliega sus pods, en cuántos y cómo actualizarlos.
El tercer concepto es el
servicio . Su servicio es en realidad su sistema, que recibe algo de tráfico y luego lo dirige a uno o más pods que corresponden a su servicio. Es decir, le permite decir que todo el tráfico entrante a dicho servicio con dicho nombre debe enviarse a estos pods en particular. Y al mismo tiempo, le proporciona equilibrio de tráfico. Es decir, puede ejecutar dos pods de su aplicación, y todo el tráfico entrante se equilibrará de manera uniforme entre los pods relacionados con este servicio.
Y el cuarto concepto básico es
Ingress . Este es un servicio que se ejecuta en un clúster de Kubernetes. Actúa como un equilibrador de carga externo, que acepta todas las solicitudes. Debido a la API, Kubernetes Ingress puede determinar dónde se deben enviar estas solicitudes. Y lo hace con mucha flexibilidad. Puede decir que todas las solicitudes a este host y dicha URL se envían a este servicio. Y enviamos estas solicitudes a este host y a otra URL a otro servicio.
Lo mejor desde el punto de vista de quien desarrolla la aplicación es que puede administrarlo todo usted mismo. Una vez configurada la configuración de Ingress, puede enviar todo el tráfico que llega a dicha API a contenedores separados registrados, por ejemplo, a Go. Pero este tráfico que llega al mismo dominio, pero a una URL diferente, debe enviarse a contenedores escritos en PHP, donde hay mucha lógica, pero no son muy rápidos.
Si comparamos todos estos conceptos con Nomad, entonces podemos decir que los primeros tres conceptos están todos juntos. Servicio. Y falta el último concepto en Nomad. Usamos un equilibrador externo, ya que puede ser haproxy, nginx, nginx +, etc. En el caso de un cubo, no necesita introducir este concepto adicional por separado. Sin embargo, si miras a Ingress por dentro, es nginx, o haproxy, o traefik, pero como si estuviera integrado en Kubernetes.
Todos los conceptos que he descrito son esencialmente los recursos que existen dentro del clúster de Kubernetes. Para describirlos en el cubo, se utiliza el formato yaml, que es más legible y familiar que los archivos HCl en el caso de Nomad. Pero estructuralmente describen en el caso de, por ejemplo, pod lo mismo. Dicen: quiero desplegar tal y tal vaina allí y allá, con tal y tal imagen, en tal y tal cantidad.

Además, nos dimos cuenta de que no queríamos crear cada recurso individual con nuestras propias manos: implementación, servicios, Ingress y más. En cambio, queríamos describir cada sistema implementado en términos de Kubernetes durante la implementación para que no tuviéramos que recrear manualmente todas las dependencias de recursos necesarias en el orden correcto. Helm fue elegido como el sistema que nos permitió hacer esto.
Conceptos clave en Helm
Helm es un
administrador de paquetes para Kubernetes. Es muy similar a cómo funcionan los gestores de paquetes en lenguajes de programación. Le permiten almacenar un servicio que consiste, por ejemplo, en implementación nginx, implementación php-fpm, una configuración para Ingress, configmaps (esta es una entidad que le permite configurar env y otros parámetros para su sistema) en forma de los llamados gráficos. Al mismo tiempo, Helm
corre sobre Kubernetes . Es decir, este no es un tipo de sistema que se hace a un lado, sino simplemente otro servicio que se ejecuta dentro del cubo. Interactúa con él a través de su API a través de un comando de consola. Su conveniencia y encanto es que incluso si el timón se rompe o lo elimina del clúster, sus servicios no desaparecerán, ya que el timón esencialmente solo sirve para iniciar el sistema. Kubernetes es responsable del tiempo de actividad y el estado de los servicios.
También nos dimos cuenta de que la estandarización , que antes tenía que hacerse de forma independiente mediante la introducción de jinja en nuestras configuraciones, es una de las principales características de helm. Todas las configuraciones que cree para sus sistemas se almacenan en helm en forma de plantillas similares a jinja, pero, de hecho, utilizando la plantilla de idioma Go en la que está escrito helm, como Kubernetes.Helm nos agrega algunos conceptos adicionales.El cuadro es una descripción de su servicio. Otros administradores de paquetes lo llamarían paquete, paquete o algo así. Esto se llama gráfico aquí.Los valores son las variables que desea usar para construir sus configuraciones a partir de plantillas.Lanzamiento. Cada vez que un servicio que se implementa usando helm recibe una versión incremental de la versión. Helm recuerda cuál era la configuración del servicio en el año anterior, el año anterior al último lanzamiento, y así sucesivamente. Por lo tanto, si necesita retroceder, simplemente ejecute el comando de devolución de llamada helm, que le indica la versión anterior de la versión. Incluso si en el momento de la reversión, la configuración correspondiente en su repositorio no está disponible, Helm aún recuerda lo que era y revierte su sistema al estado que tenía en la versión anterior.En el caso cuando usamos helm, las configuraciones usuales para Kubernetes también se convierten en plantillas, en las cuales es posible usar variables, funciones, aplicar operadores condicionales. Por lo tanto, puede recopilar la configuración de su servicio según el entorno.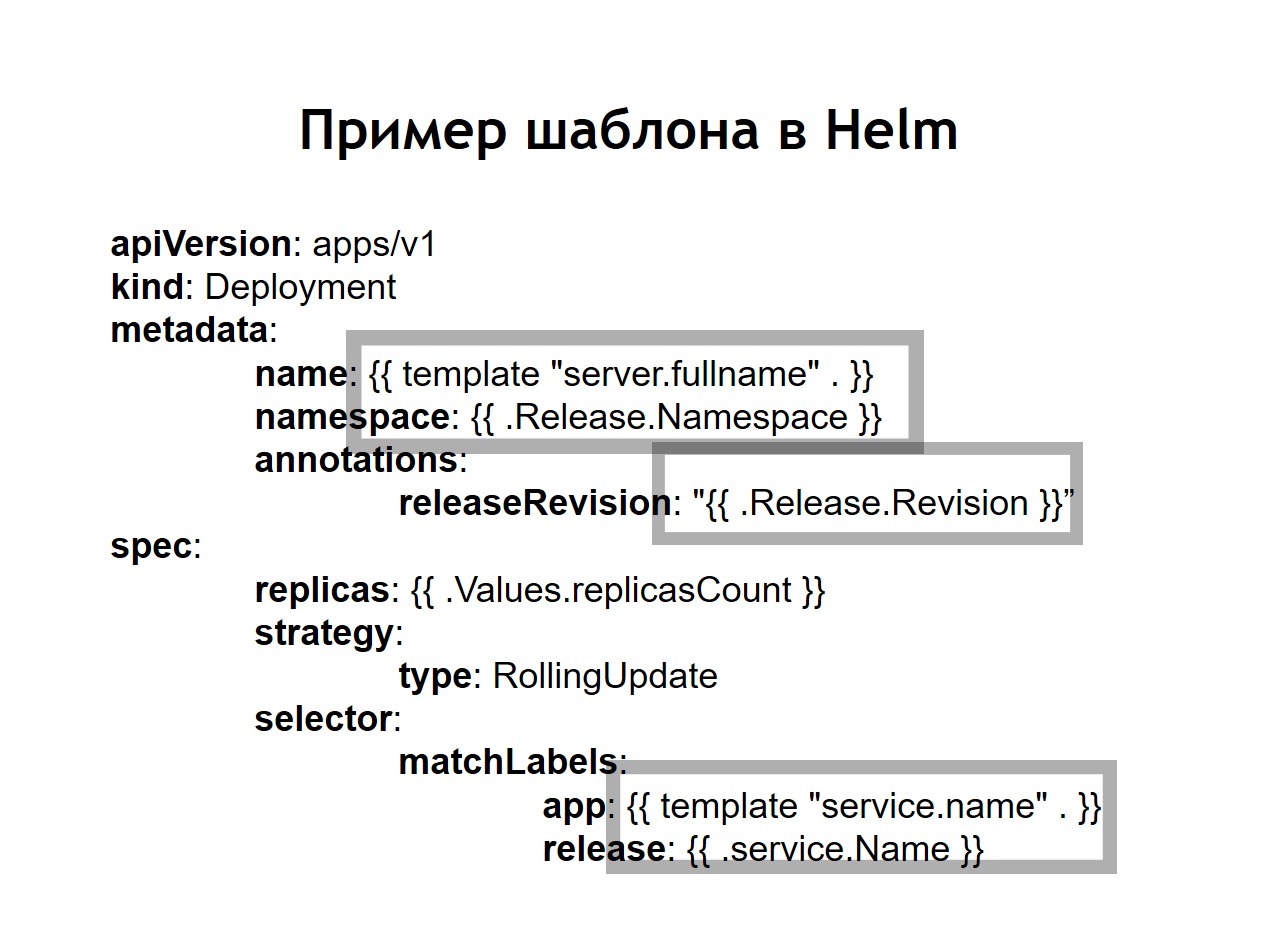 En la práctica, decidimos hacer un poco diferente de lo que hicimos en el caso de Nomad. Si en Nomad en el mismo repositorio se almacenaban tanto las configuraciones para la implementación como las n variables que se necesitaban para implementar nuestro servicio, aquí decidimos dividirlas en dos repositorios separados. Solo las n variables necesarias para el despliegue se almacenan en el repositorio de despliegue, y las configuraciones o gráficos se almacenan en el repositorio de timón.
En la práctica, decidimos hacer un poco diferente de lo que hicimos en el caso de Nomad. Si en Nomad en el mismo repositorio se almacenaban tanto las configuraciones para la implementación como las n variables que se necesitaban para implementar nuestro servicio, aquí decidimos dividirlas en dos repositorios separados. Solo las n variables necesarias para el despliegue se almacenan en el repositorio de despliegue, y las configuraciones o gráficos se almacenan en el repositorio de timón. ¿Qué nos dio?A pesar de que no almacenamos datos realmente confidenciales en los archivos de configuración. Por ejemplo, contraseñas de bases de datos. Se almacenan como secretos en Kubernetes, pero, sin embargo, todavía hay algunas cosas allí que no queremos dar acceso a todos en una fila. Por lo tanto, el acceso al repositorio de implementación es más limitado, y el repositorio de helm simplemente contiene una descripción del servicio. Por esta razón, es posible dar acceso a un círculo más grande de personas de manera segura.Dado que no solo tenemos producción, sino también otros entornos, gracias a esta separación, podemos reutilizar nuestros gráficos de timón para implementar servicios no solo en producción, sino también, por ejemplo, en el entorno de control de calidad. Incluso desplegarlos localmente usando Minikube es algo así como ejecutar Kubernetes localmente.Dentro de cada repositorio, dejamos una separación en directorios separados para cada servicio. Es decir, dentro de cada directorio hay plantillas relacionadas con el gráfico correspondiente y que describen los recursos que deben implementarse para iniciar nuestro sistema. En el repositorio de despliegue, solo dejamos enves. En este caso, no utilizamos plantillas con jinja, porque el timón mismo proporciona plantillas fuera de la caja, esta es una de sus funciones principales.Dejamos el script de implementación, deploy.sh, que simplifica y estandariza el lanzamiento para la implementación usando helm. Por lo tanto, para cualquier persona que quiera implementar, la interfaz de implementación se ve exactamente igual que en el caso de la implementación a través de Nomad. El mismo deploy.sh, el nombre de su servicio y dónde desea implementarlo. Esto hace que el timón comience dentro. Él, a su vez, recopila configuraciones de plantillas, sustituye los archivos de valores necesarios en ellas, luego las implementa y las coloca en Kubernetes.
¿Qué nos dio?A pesar de que no almacenamos datos realmente confidenciales en los archivos de configuración. Por ejemplo, contraseñas de bases de datos. Se almacenan como secretos en Kubernetes, pero, sin embargo, todavía hay algunas cosas allí que no queremos dar acceso a todos en una fila. Por lo tanto, el acceso al repositorio de implementación es más limitado, y el repositorio de helm simplemente contiene una descripción del servicio. Por esta razón, es posible dar acceso a un círculo más grande de personas de manera segura.Dado que no solo tenemos producción, sino también otros entornos, gracias a esta separación, podemos reutilizar nuestros gráficos de timón para implementar servicios no solo en producción, sino también, por ejemplo, en el entorno de control de calidad. Incluso desplegarlos localmente usando Minikube es algo así como ejecutar Kubernetes localmente.Dentro de cada repositorio, dejamos una separación en directorios separados para cada servicio. Es decir, dentro de cada directorio hay plantillas relacionadas con el gráfico correspondiente y que describen los recursos que deben implementarse para iniciar nuestro sistema. En el repositorio de despliegue, solo dejamos enves. En este caso, no utilizamos plantillas con jinja, porque el timón mismo proporciona plantillas fuera de la caja, esta es una de sus funciones principales.Dejamos el script de implementación, deploy.sh, que simplifica y estandariza el lanzamiento para la implementación usando helm. Por lo tanto, para cualquier persona que quiera implementar, la interfaz de implementación se ve exactamente igual que en el caso de la implementación a través de Nomad. El mismo deploy.sh, el nombre de su servicio y dónde desea implementarlo. Esto hace que el timón comience dentro. Él, a su vez, recopila configuraciones de plantillas, sustituye los archivos de valores necesarios en ellas, luego las implementa y las coloca en Kubernetes.Conclusiones
El servicio de Kubernetes parece más complejo que Nomad.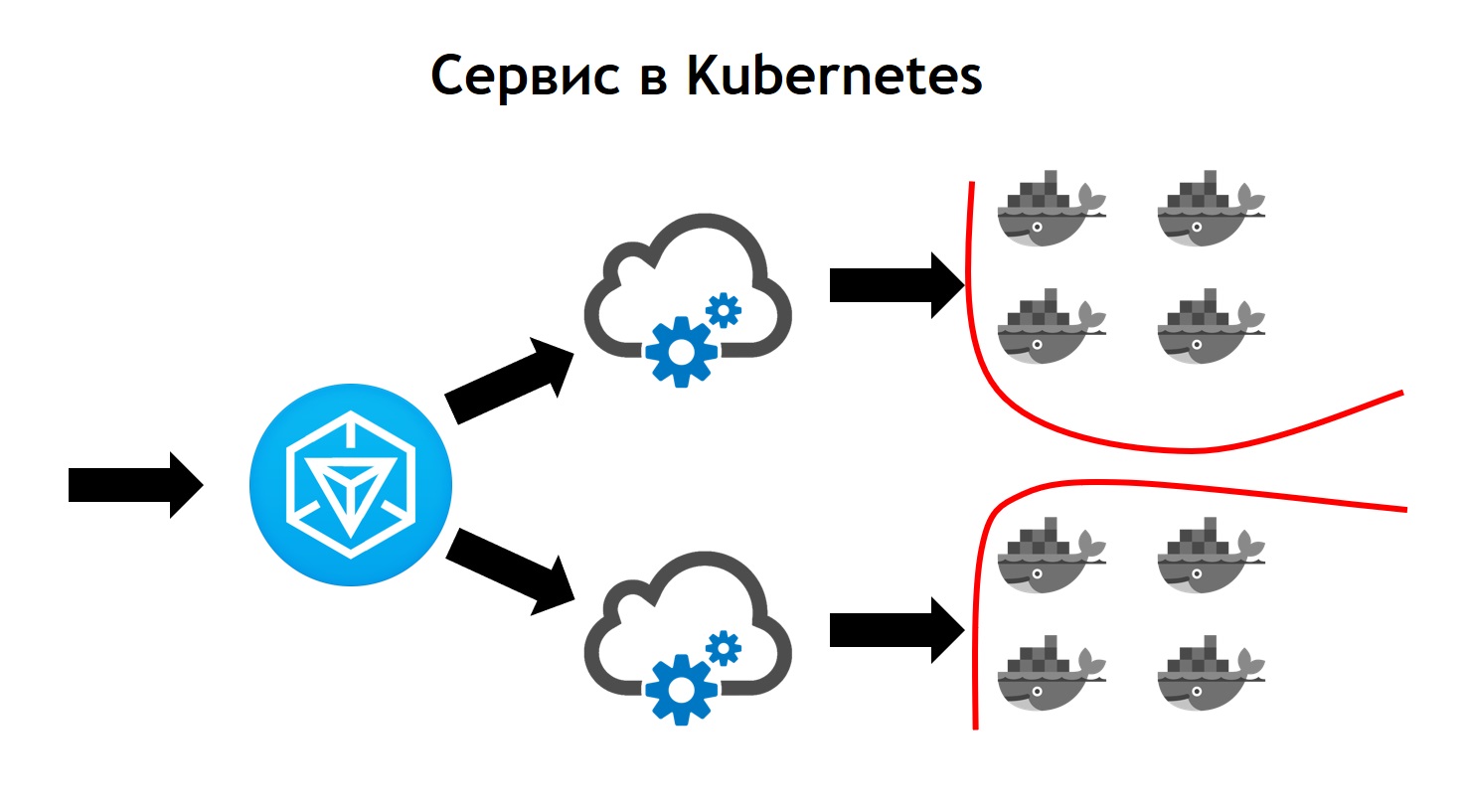 Aquí es donde el tráfico saliente llega a Ingress. Este es solo el controlador frontal, que recibe todas las solicitudes y posteriormente las envía a los servicios correspondientes a los datos de la solicitud. Los define sobre la base de configuraciones, que son parte de la descripción de su aplicación en timón y que los desarrolladores configuran de forma independiente. El servicio envía solicitudes a sus pods, es decir, contenedores específicos, equilibrando el tráfico entrante entre todos los contenedores que pertenecen a este servicio. Bueno, por supuesto, no olvides que no debemos ir desde la seguridad a nivel de red. Por lo tanto, el clúster de Kubernetes opera la segmentación, que se basa en el etiquetado. Todos los servicios tienen ciertas etiquetas, a las cuales los derechos de acceso de los servicios a ciertos recursos externos / internos están unidos dentro o fuera del clúster.Al completar la transición, vimos que Kubernetes tiene todas las características de Nomad, que usamos antes, y también agrega muchas cosas nuevas. Se puede ampliar a través de complementos y, de hecho, a través de tipos de recursos personalizados. Es decir, tiene la oportunidad no solo de usar algo que entra en Kubernetes de forma inmediata, sino de crear su propio recurso y servicio que leerá su recurso. Esto proporciona opciones adicionales para expandir su sistema sin la necesidad de reinstalar Kubernetes y sin la necesidad de cambios.Un ejemplo de esto es Prometheus, que se ejecuta dentro de nuestro clúster de Kubernetes. Para que pueda comenzar a recopilar métricas de un servicio en particular, necesitamos agregar un tipo de recurso adicional, el denominado monitor de servicio, a la descripción del servicio. Prometheus, debido al hecho de que puede leer, al lanzarse en Kubernetes, un tipo personalizado de recursos, automáticamente comienza a recopilar métricas del nuevo sistema. Es bastante conveniente.El primer despliegue que hicimos en Kubernetes fue en marzo de 2018. Y durante este tiempo nunca tuvimos problemas con él. Funciona de manera estable sin errores importantes. Además, podemos ampliarlo aún más. Hoy, tenemos suficientes oportunidades, y realmente nos gusta el ritmo de desarrollo de Kubernetes. Actualmente, más de 3.000 contenedores se encuentran en Kubernetes. El clúster toma varios nodos. Al mismo tiempo, tiene servicio, es estable y está muy controlado.
Aquí es donde el tráfico saliente llega a Ingress. Este es solo el controlador frontal, que recibe todas las solicitudes y posteriormente las envía a los servicios correspondientes a los datos de la solicitud. Los define sobre la base de configuraciones, que son parte de la descripción de su aplicación en timón y que los desarrolladores configuran de forma independiente. El servicio envía solicitudes a sus pods, es decir, contenedores específicos, equilibrando el tráfico entrante entre todos los contenedores que pertenecen a este servicio. Bueno, por supuesto, no olvides que no debemos ir desde la seguridad a nivel de red. Por lo tanto, el clúster de Kubernetes opera la segmentación, que se basa en el etiquetado. Todos los servicios tienen ciertas etiquetas, a las cuales los derechos de acceso de los servicios a ciertos recursos externos / internos están unidos dentro o fuera del clúster.Al completar la transición, vimos que Kubernetes tiene todas las características de Nomad, que usamos antes, y también agrega muchas cosas nuevas. Se puede ampliar a través de complementos y, de hecho, a través de tipos de recursos personalizados. Es decir, tiene la oportunidad no solo de usar algo que entra en Kubernetes de forma inmediata, sino de crear su propio recurso y servicio que leerá su recurso. Esto proporciona opciones adicionales para expandir su sistema sin la necesidad de reinstalar Kubernetes y sin la necesidad de cambios.Un ejemplo de esto es Prometheus, que se ejecuta dentro de nuestro clúster de Kubernetes. Para que pueda comenzar a recopilar métricas de un servicio en particular, necesitamos agregar un tipo de recurso adicional, el denominado monitor de servicio, a la descripción del servicio. Prometheus, debido al hecho de que puede leer, al lanzarse en Kubernetes, un tipo personalizado de recursos, automáticamente comienza a recopilar métricas del nuevo sistema. Es bastante conveniente.El primer despliegue que hicimos en Kubernetes fue en marzo de 2018. Y durante este tiempo nunca tuvimos problemas con él. Funciona de manera estable sin errores importantes. Además, podemos ampliarlo aún más. Hoy, tenemos suficientes oportunidades, y realmente nos gusta el ritmo de desarrollo de Kubernetes. Actualmente, más de 3.000 contenedores se encuentran en Kubernetes. El clúster toma varios nodos. Al mismo tiempo, tiene servicio, es estable y está muy controlado.