Comenzamos una serie de artículos que describen diversas situaciones en las que el uso de herramientas Intel para desarrolladores ha aumentado significativamente la velocidad del software y ha mejorado su calidad.
Nuestra primera historia sucedió en la Universidad de Novosibirsk, donde los investigadores desarrollaron una herramienta de software para simular numéricamente problemas magnetohidrodinámicos durante la ionización de hidrógeno. Este trabajo se llevó a cabo como parte del proyecto de modelado de astrofísica global
AstroPhi ;
Los procesadores Intel Xeon Phi se utilizaron como plataforma de hardware. Como resultado del uso de
Intel Advisor e
Intel Trace Analyzer and Collector , el rendimiento informático aumentó 3 veces y la velocidad para resolver un problema disminuyó de una semana a dos días.
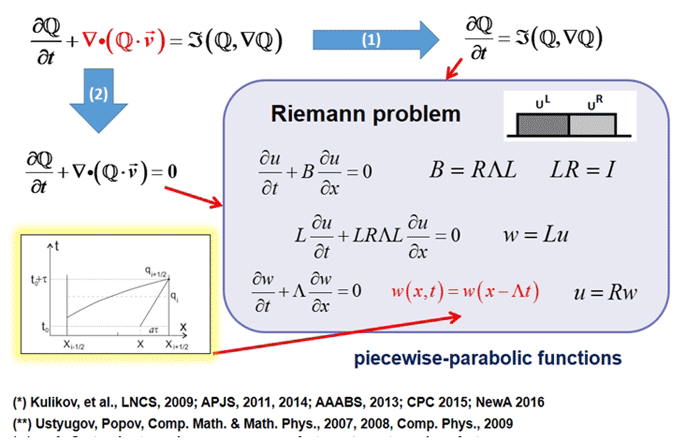
Descripción de la tarea
El modelado matemático juega un papel importante en la astrofísica moderna, como en cualquier ciencia; Esta es una herramienta universal para estudiar procesos evolutivos no lineales en el universo. El modelado de alta resolución de procesos astrofísicos complejos requiere enormes recursos computacionales. Proyecto AstroPhi NSU está desarrollando un código de software astrofísico para supercomputadoras basadas en procesadores Intel Xeon Phi. Los estudiantes aprenden a escribir programas de simulación para un tiempo de ejecución extremadamente paralelo, obteniendo un conocimiento importante que necesitarán cuando trabajen con otras supercomputadoras.
El método de modelado numérico utilizado en el proyecto tenía varias ventajas importantes:
- falta de viscosidad artificial
- Invariancia galileana,
- garantía de no reducción de entropía,
- paralelización simple
- Extensibilidad potencialmente infinita.
Los primeros tres factores son clave para el modelado realista de efectos físicos significativos en problemas astrofísicos.
El equipo de investigación ha creado una nueva herramienta de modelado para arquitecturas multiparalelas basada en Intel Xeon Phi. Su tarea principal era evitar cuellos de botella en el intercambio de datos entre nodos y simplificar el refinamiento del código tanto como sea posible. La solución de paralelización utiliza MPI, y para la vectorización, las instrucciones de Intel Advanced Vector Extensions 512 (Intel AVX-512) agregan soporte para SIMD de 512 bits y permiten que el programa empaque 8 números de punto flotante de doble precisión o 16 números de precisión simple (32 bits) ) a vectores de 512 bits de longitud. Por lo tanto, se procesan el doble de elementos de datos por instrucción que cuando se usa AVX / AVX2 y cuatro veces más que cuando se usa SSE.
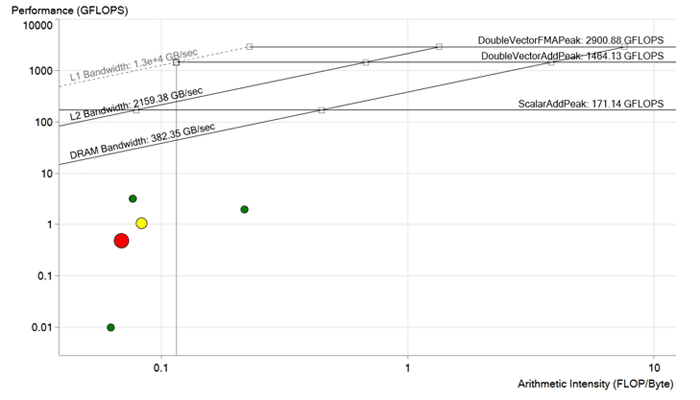 Imagen antes de la optimización. Cada punto es un ciclo de procesamiento. Cuanto más grande y rojo es el punto, más largo continúa el ciclo y más notable es el efecto de su optimización. El punto rojo se encuentra muy por debajo del límite de ancho de banda de DRAM y se calcula con un rendimiento inferior a 1 GFLOP. Tiene un gran potencial de mejora.
Imagen antes de la optimización. Cada punto es un ciclo de procesamiento. Cuanto más grande y rojo es el punto, más largo continúa el ciclo y más notable es el efecto de su optimización. El punto rojo se encuentra muy por debajo del límite de ancho de banda de DRAM y se calcula con un rendimiento inferior a 1 GFLOP. Tiene un gran potencial de mejora.Optimización de código
Antes de la optimización, el código tenía ciertos problemas con dependencias y tamaños de vectores. El objetivo de la optimización era eliminar las dependencias de los vectores y mejorar las operaciones de carga de datos en la memoria utilizando el tamaño óptimo de vectores y matrices para Xeon Phi. Para la optimización, utilizamos
Intel Advisor e
Intel Trace Analyzer and Collector , dos herramientas de
Intel Parallel Studio XE .
Intel Advisor es, como su nombre lo indica, un asesor, una herramienta de software que evalúa el grado de optimización: vectorización (usando instrucciones AVX o SIMD) y paralelización para lograr el máximo rendimiento. Usando esta herramienta, el equipo pudo hacer un análisis general de los ciclos, destacando aquellos con baja productividad, indicando el potencial de mejora y determinando qué podría mejorarse y si el juego valía la pena. Intel Advisor ordenó los ciclos por mensajes potenciales y agregados a la fuente para una mejor legibilidad del informe del compilador. También proporcionó información importante como tiempos de ciclo, dependencias de datos y patrones de acceso a la memoria para una vectorización segura y eficiente.
Intel Trace Analyzer and Collector es otra forma de optimizar su código. Incluye la creación de perfiles de comunicaciones MPI y la funcionalidad de análisis para mejorar el escalado débil y fuerte. Esta herramienta gráfica ayudó al equipo a comprender el comportamiento MPI de la aplicación, encontrar rápidamente cuellos de botella y, lo más importante, aumentar el rendimiento de la arquitectura Intel.
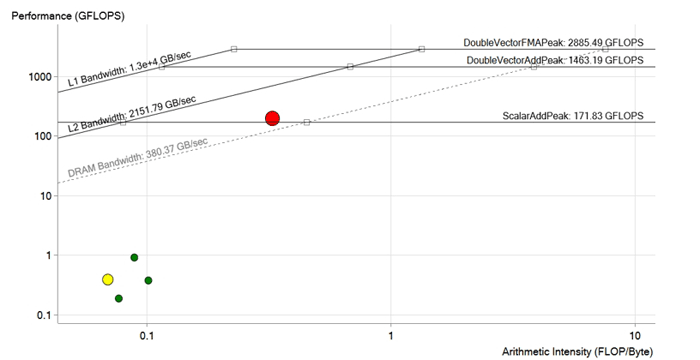 Imagen después de la optimización. Durante la optimización del ciclo rojo, se eliminaron las dependencias de vectorización, se optimizaron las operaciones de carga en la memoria, se adaptaron los tamaños de los vectores y las matrices para las instrucciones Intel Xeon Phi y AVX-512. El rendimiento aumentó a 190 GFLOPS, es decir, unas 200 veces. Ahora está por encima del límite de DRAM y lo más probable es que esté limitado por las características del caché L2
Imagen después de la optimización. Durante la optimización del ciclo rojo, se eliminaron las dependencias de vectorización, se optimizaron las operaciones de carga en la memoria, se adaptaron los tamaños de los vectores y las matrices para las instrucciones Intel Xeon Phi y AVX-512. El rendimiento aumentó a 190 GFLOPS, es decir, unas 200 veces. Ahora está por encima del límite de DRAM y lo más probable es que esté limitado por las características del caché L2Resultado
Entonces, después de todas las mejoras y optimizaciones, el equipo logró un rendimiento de 190 GFLOPS con una intensidad aritmética de 0.3 FLOP / b, 100% de utilización y 573 GB / s de ancho de banda de memoria.
 Fragmento de código optimizado
Fragmento de código optimizado