El artículo en cuestión.
Introduccion
Los sistemas de reconocimiento modernos se limitan a clasificar en un número relativamente pequeño de clases semánticamente no relacionadas. La atracción de información textual, incluso sin relación con las imágenes, permite enriquecer el modelo y, en cierta medida, resolver los siguientes problemas:
- si el modelo de reconocimiento comete un error, a menudo este error no está semánticamente cerca de la clase correcta;
- no hay forma de predecir un objeto que pertenezca a una nueva clase que no se haya representado en el conjunto de datos de entrenamiento.
El enfoque propuesto sugiere mostrar imágenes en un rico espacio semántico en el que las etiquetas de clases más similares están más cercanas entre sí que las etiquetas de clases menos similares. Como resultado, el modelo da menos semánticamente distante de la verdadera clase de predicciones. Además, el modelo, teniendo en cuenta la proximidad visual y semántica, puede clasificar correctamente las imágenes relacionadas con una clase que no estaba representada en el conjunto de datos de entrenamiento.
Algoritmo Arquitectura
- Preparamos previamente el modelo de lenguaje, que proporciona buenas incorporaciones semánticamente significativas. La dimensión del espacio es n. A continuación, n se tomará igual a 500 o 1000.
- Preparamos previamente el modelo visual, que clasifica los objetos en 1000 clases.
- Cortamos la última capa softmax del modelo visual pre-entrenado y agregamos una capa completamente conectada de 4096 a n neuronas. Entrenamos el modelo resultante para cada imagen para predecir la incrustación correspondiente a la etiqueta de la imagen.
Vamos a explicar con la ayuda de los mapeos. Deje que LM sea un modelo de lenguaje, VM sea un modelo visual con softmax cortado y una capa completamente conectada agregada, imagen I, etiqueta L de imagen, incrustación de etiqueta LM (L) en el espacio semántico. Luego, en el tercer paso, entrenamos la VM para que:
VM(I)=LM(L)
Arquitectura:
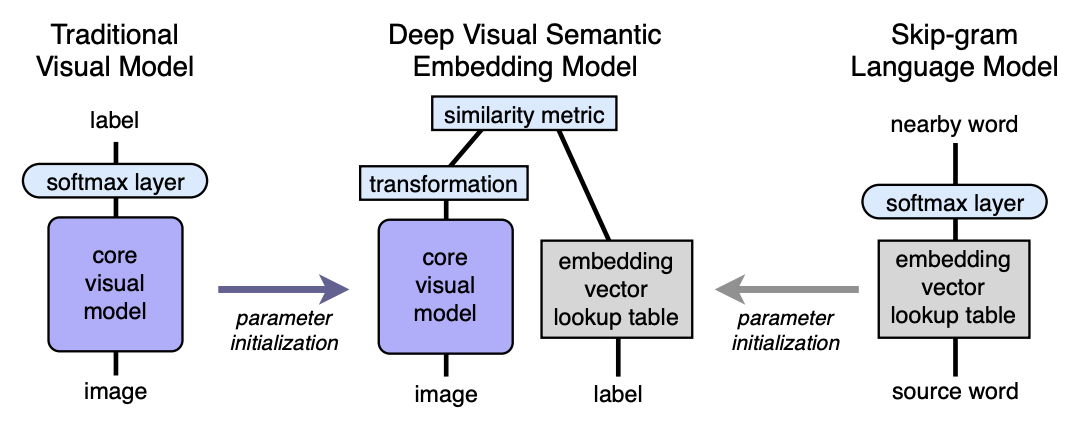
Modelo de idioma
Para aprender el modelo de lenguaje, se utilizó el modelo skip-gram, un corpus de 5.4 billones de palabras tomadas de wikipedia.org. El modelo usó una capa jerárquica softmax para predecir conceptos relacionados, una ventana - 20 palabras, el número de pasadas a través del cuerpo - 1. Se estableció experimentalmente que el tamaño de incrustación es mejor para tomar 500-1000.
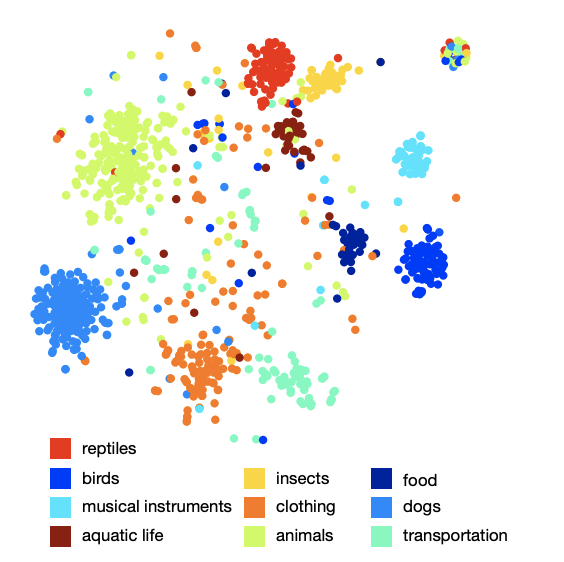
La imagen de la disposición de las clases en el espacio muestra que el modelo ha aprendido una estructura semántica rica y cualitativa. Por ejemplo, para una determinada especie de tiburones en el espacio semántico resultante, 9 vecinos más cercanos son los otros 9 tipos de tiburones.
Modelo visual
La arquitectura que ganó el concurso ILSVRC 2012 se tomó como modelo visual. Se eliminó Softmax y se agregó una capa completamente conectada para obtener el tamaño de incrustación deseado en la salida.
Función de pérdida
Resultó que la elección de la función de pérdida es importante. Se usó una combinación de similitud de coseno y pérdida de rango de bisagra. La función de pérdida alentó un producto escalar más grande entre el vector resultante de la red visual y la incrustación de la etiqueta correspondiente, y multado por un producto escalar grande entre el resultado de la red visual y las incrustaciones de posibles etiquetas de imagen al azar. El número de etiquetas aleatorias arbitrarias no fue fijo, pero estaba limitado por la condición bajo la cual la suma de productos escalares con etiquetas falsas se convirtió en más que un producto escalar con una etiqueta válida menos un margen fijo (constante igual a 0.1). Por supuesto, todos los vectores fueron pre-normalizados.
pérdida(I,L)= sumjmax[0,margen−(L,VM(I))+(incorrectoLj,VM(I))]
Proceso de entrenamiento
Al principio, solo se entrenó la última capa totalmente conectada agregada, el resto de la red no actualizó el peso. En este caso, se utilizó el método de optimización SGD. Luego, toda la red visual se descongeló y se entrenó utilizando el optimizador Adagrad para que durante la propagación hacia atrás en diferentes capas de la red los gradientes se escalen correctamente.
Predicción
Durante la predicción, a partir de la imagen que usa la red visual, obtenemos algunos vectores en nuestro espacio semántico. A continuación, encontramos los vecinos más cercanos, es decir, algunas etiquetas posibles y, de manera especial, las mostramos de nuevo en los sistemas de imagen de ImageNet para su puntuación. El procedimiento para la última visualización no es tan simple, ya que las etiquetas en ImageNet son un conjunto de sinónimos, no solo una etiqueta. Si el lector está interesado en conocer los detalles, recomiendo el artículo original (apéndice 2).
Resultados
El resultado del modelo DEVISE se comparó con dos modelos:
- Modelo de referencia de Softmax: un modelo de visión de vanguardia (SOTA, en el momento de la publicación)
- El modelo de incrustación aleatorio es una versión del modelo DEVISE descrito, donde las incrustaciones no se aprenden mediante el modelo de lenguaje, sino que se inicializan arbitrariamente.
Para evaluar la calidad, se utilizaron métricas hit @ k planas y métrica @ k de precisión jerárquica. La métrica "plana" hit @ k es el porcentaje de imágenes de prueba para las cuales la etiqueta correcta está presente entre las primeras k opciones predichas. La precisión jerárquica @ k métrica se utilizó para evaluar la calidad de la correspondencia semántica. Esta métrica se basó en la jerarquía de etiquetas en ImageNet. Para cada etiqueta verdadera y k fija, el conjunto
etiquetas semánticamente correctas: lista de verdad básica. Obtener la predicción (vecinos más cercanos) fue el porcentaje de intersección con la lista de verdad del terreno.

Los autores esperaban que el modelo softmax mostrara los mejores resultados en la métrica plana debido al hecho de que minimiza la pérdida de entropía cruzada, lo cual es muy adecuado para las métricas hit @ k "planas". Los autores se sorprendieron de lo cerca que está el modelo DEVISE del modelo softmax, alcanza la paridad en k grande e incluso supera en k = 20.
En la métrica jerárquica, el modelo DEVISE se muestra en todo su esplendor y supera al béisbol softmax en un 3% para k = 5 y en un 7% para k = 20.
Aprendizaje de tiro cero
Una ventaja particular del modelo DEVISE es la capacidad de proporcionar una predicción adecuada para las imágenes cuyas etiquetas la red nunca ha visto durante el entrenamiento. Por ejemplo, durante el entrenamiento, la red vio imágenes etiquetadas de tiburón tigre, tiburón toro y tiburón azul y nunca alcanzó la marca de tiburón. Dado que el modelo de lenguaje tiene una representación de tiburón en el espacio semántico y está cerca de incrustaciones de diferentes tipos de tiburón, es muy probable que el modelo dé una predicción adecuada. Esto se llama la capacidad de generalizar: generalización.
Demostremos algunos ejemplos de predicciones Zero-Shot:

Tenga en cuenta que el modelo DEVISE, incluso en sus supuestos erróneos, está más cerca de la respuesta correcta que los supuestos erróneos del modelo softmax.
Entonces, el modelo presentado pierde un poco a softmax en la línea de base en métricas planas, pero gana significativamente en precisión jerárquica @ k métrica. El modelo tiene la capacidad de generalizar, produciendo predicciones adecuadas para imágenes cuyas etiquetas no ha cumplido la red (aprendizaje de disparo cero).
El enfoque descrito se puede implementar fácilmente, ya que se basa en dos modelos previamente entrenados: el lenguaje y el visual.