El mercado de computación distribuida y big data, según las
estadísticas , está creciendo a un 18-19% por año. Por lo tanto, la cuestión de elegir software para estos fines sigue siendo relevante. En esta publicación, comenzaremos con por qué se necesita computación distribuida, nos detendremos en la elección del software, hablaremos sobre el uso de Hadoop con Cloudera y, finalmente, hablemos sobre la elección del hardware y cómo afecta el rendimiento de diferentes maneras.
¿Por qué necesitamos computación distribuida en un negocio regular? Todo es simple y complicado al mismo tiempo. Simple: porque en la mayoría de los casos realizamos cálculos relativamente simples por unidad de información. Es difícil porque hay mucha información de este tipo. Mucho Como resultado, debe
procesar terabytes de datos en 1000 subprocesos . Por lo tanto, los escenarios de uso son bastante universales: los cálculos se pueden aplicar donde sea necesario para tener en cuenta una gran cantidad de métricas en una matriz de datos aún mayor.
Un ejemplo reciente: la cadena de pizzerías Dodo Pizza
determinó, basándose en un análisis de la base de pedidos del cliente, que al elegir una pizza con relleno arbitrario, los usuarios generalmente operan con solo seis conjuntos básicos de ingredientes más un par de al azar. De acuerdo con esto, la pizzería ajustó las compras. Además, pudo recomendar mejor a los usuarios productos adicionales ofrecidos en la etapa de pedido, lo que ayudó a aumentar las ganancias.
Otro ejemplo: el
análisis de las posiciones
de los productos básicos permitió a la tienda H&M reducir el rango en tiendas individuales en un 40%, mientras se mantenía el nivel de ventas. Esto se logró eliminando posiciones de venta deficientes, y la estacionalidad se tuvo en cuenta en los cálculos.
Selección de herramienta
El estándar de la industria para este tipo de computación es Hadoop. Por qué Debido a que Hadoop es un marco excelente y bien documentado (el mismo Habr emite muchos artículos detallados sobre este tema), que se acompaña de un conjunto completo de utilidades y bibliotecas. Puede ingresar grandes conjuntos de datos estructurados y no estructurados, y el sistema mismo los distribuirá entre la potencia informática. Además, estas mismas capacidades se pueden aumentar o desactivar en cualquier momento, la misma escalabilidad horizontal en acción.
En 2017, la influyente empresa de consultoría Gartner
concluyó que Hadoop pronto quedaría obsoleto. La razón es bastante banal: los analistas creen que las empresas migrarán masivamente a la nube, porque allí pueden pagar por el uso de la potencia informática. El segundo factor importante, supuestamente capaz de "enterrar" a Hadoop, es la velocidad del trabajo. Porque opciones como Apache Spark o Google Cloud DataFlow son más rápidas que MapReduce subyacente de Hadoop.
Hadoop se apoya en varios pilares, entre los que destacan las tecnologías MapReduce (un sistema de distribución de datos para la computación entre servidores) y el sistema de archivos HDFS. Este último está diseñado específicamente para almacenar información distribuida entre nodos en un clúster: cada bloque de un tamaño fijo se puede colocar en varios nodos y, gracias a la replicación, el sistema es inmune a las fallas de los nodos individuales. En lugar de una tabla de archivos, se usa un servidor especial llamado NameNode.
La siguiente ilustración muestra el flujo de trabajo de MapReduce. En la primera etapa, los datos se dividen de acuerdo con una determinada característica, en la segunda, se distribuyen de acuerdo con la potencia de cálculo, en la tercera, se realiza el cálculo.
MapReduce fue creado originalmente por Google para las necesidades de su búsqueda. Luego MapReduce entró en código libre y Apache se hizo cargo del proyecto. Bueno, Google ha migrado gradualmente a otras soluciones. Un matiz interesante: en este momento Google tiene un proyecto llamado Google Cloud Dataflow, posicionado como el siguiente paso después de Hadoop, como un reemplazo rápido.
Una mirada más cercana revela que Google Cloud Dataflow se basa en una variedad de Apache Beam, mientras que Apache Beam incluye un marco Apache Spark bien documentado, que nos permite hablar sobre casi la misma velocidad de ejecución de decisiones. Bueno, Apache Spark funciona bien en el sistema de archivos HDFS, lo que le permite implementarlo en servidores Hadoop.
Agregamos aquí el volumen de documentación y soluciones llave en mano para Hadoop y Spark contra Google Cloud Dataflow, y la elección de la herramienta se vuelve obvia. Además, los ingenieros pueden decidir por sí mismos qué código, en Hadoop o Spark, ejecutar para ellos, centrándose en la tarea, la experiencia y las calificaciones.
Servidor local o en la nube
La tendencia hacia una transición universal a la nube incluso ha generado un término tan interesante como Hadoop-as-a-service. En este escenario, la administración de los servidores conectados se ha vuelto muy importante. Porque, por desgracia, a pesar de su popularidad, Hadoop puro es una herramienta bastante difícil de configurar, ya que muchas cosas deben hacerse con las manos. Por ejemplo, configure individualmente los servidores, monitoree su rendimiento, configure cuidadosamente muchos parámetros. En general, trabajar para un aficionado es una gran oportunidad para arruinar algo o perderse algo.
Por lo tanto, varias distribuciones, que inicialmente están equipadas con herramientas de implementación y administración convenientes, ganaron gran popularidad. Una de las distribuciones más populares que admiten Spark y facilitan las cosas es Cloudera. Tiene una versión paga y una versión gratuita, y en esta última toda la funcionalidad básica está disponible, y sin limitar el número de nodos.

Durante la configuración, Cloudera Manager se conectará a través de SSH a sus servidores. Un punto interesante: durante la instalación es mejor indicar que debe llevarse a cabo mediante los llamados
paquetes : paquetes especiales, cada uno de los cuales contiene todos los componentes necesarios que están configurados para funcionar entre sí. De hecho, esta es una versión mejorada del administrador de paquetes.
Después de la instalación, obtenemos la consola de administración del clúster, donde puede ver telemetría por clúster, servicios instalados, además de que puede agregar / eliminar recursos y editar la configuración del clúster.
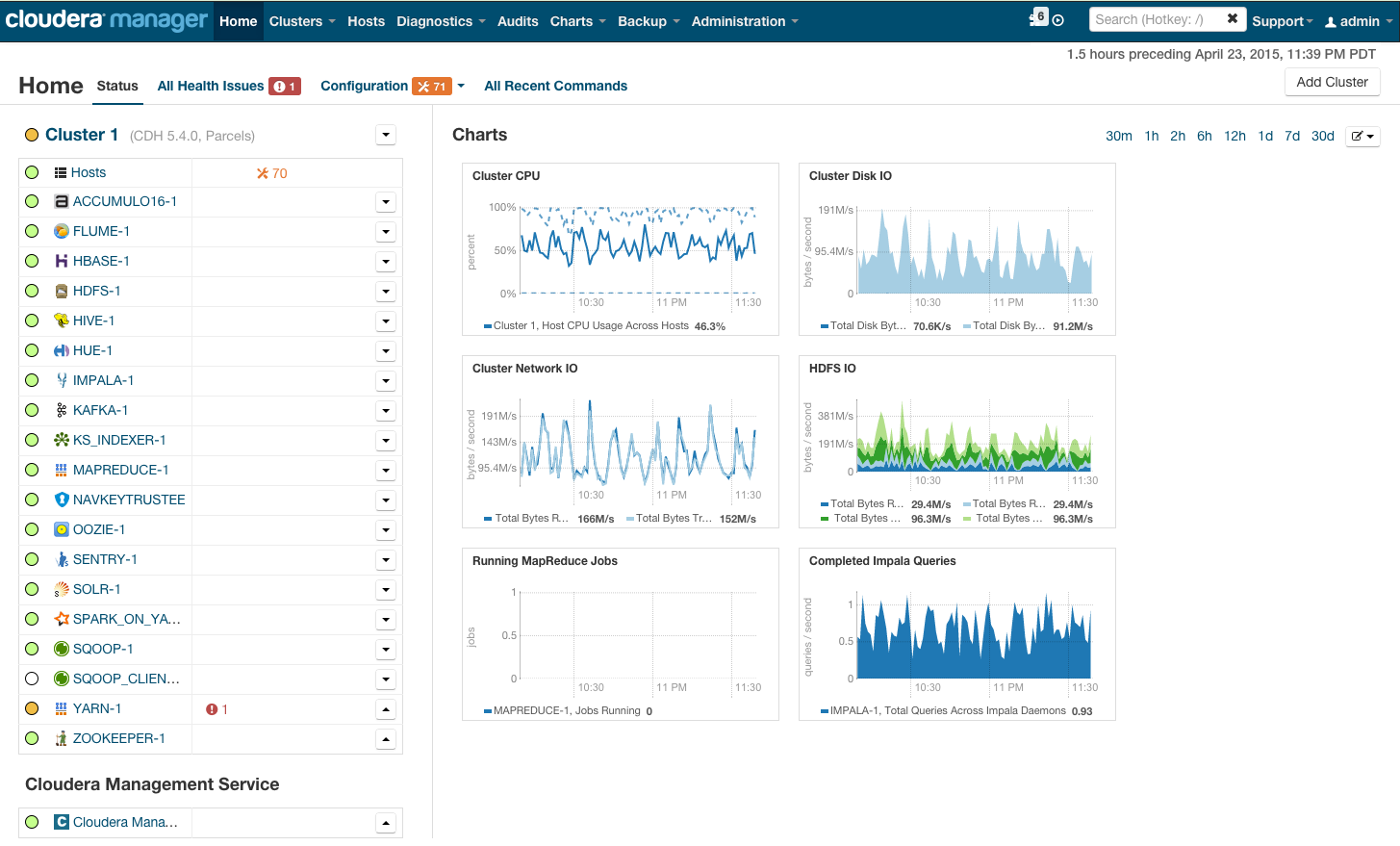
Como resultado, verá la cabina del cohete que lo llevará al brillante futuro de BigData. Pero antes de decir "vámonos", vamos a ponernos bajo el capó.
Requisitos de hardware
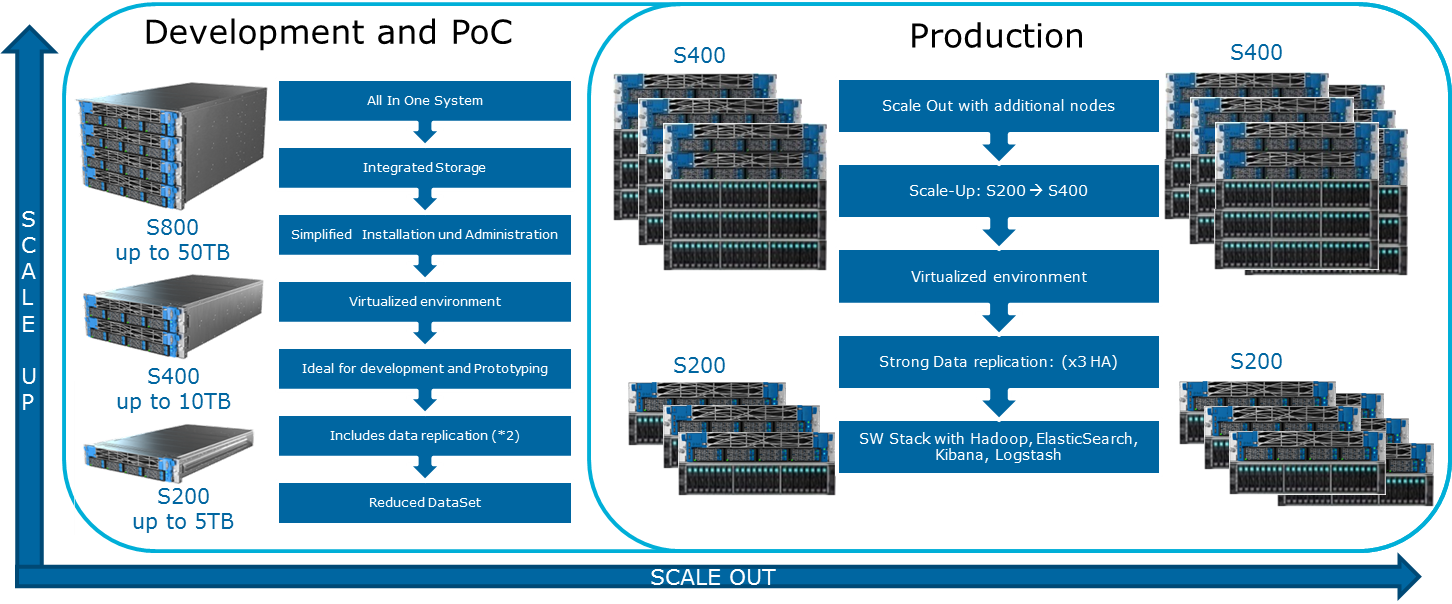
Cloudera menciona varias configuraciones posibles en su sitio web. Los principios generales por los cuales se construyen se muestran en la ilustración:
Para lubricar esta imagen optimista puede MapReduce. Si vuelve a mirar el diagrama de la sección anterior, resulta obvio que en casi todos los casos el trabajo de MapReduce puede encontrarse con un cuello de botella al leer datos del disco o de la red. Esto también aparece en el blog de Cloudera. Como resultado, para cualquier cálculo rápido, incluso a través de Spark, que a menudo se usa para cálculos en tiempo real, la velocidad de E / S es muy importante. Por lo tanto, cuando se usa Hadoop, es muy importante que las máquinas equilibradas y rápidas ingresen al clúster, lo que, por decirlo suavemente, no siempre se proporciona en la infraestructura de la nube.
El equilibrio de carga equilibrado se logra mediante el uso de la virtualización Openstack en servidores con potentes CPU de varios núcleos. Los nodos de datos tienen asignados sus recursos de procesador y discos específicos. En nuestra solución
Atos Codex Data Lake Engine , se logra una virtualización amplia, por lo que ganamos tanto en rendimiento (se minimiza la influencia de la infraestructura de red) como en TCO (se eliminan los servidores físicos innecesarios).
En el caso de usar servidores BullSequana S200, obtenemos una carga muy uniforme, sin algunos cuellos de botella. La configuración mínima incluye 3 servidores BullSequana S200, cada uno con dos JBOD, más S200 adicionales opcionales que contienen cuatro nodos de datos están conectados opcionalmente. Aquí hay un ejemplo de carga en la prueba TeraGen:
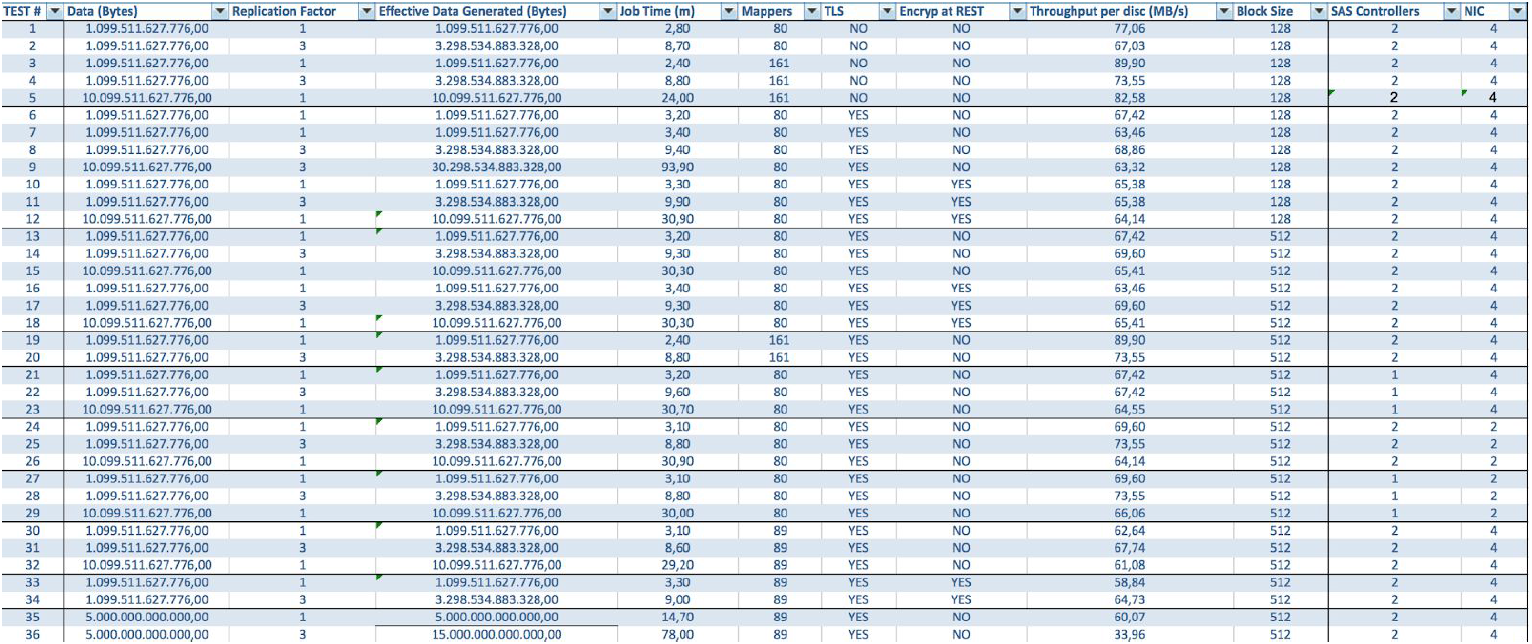
Las pruebas con diferentes volúmenes de datos y valores de replicación muestran los mismos resultados en términos de equilibrio de carga entre los nodos del clúster. A continuación se muestra un gráfico de la distribución del acceso al disco mediante pruebas de rendimiento.
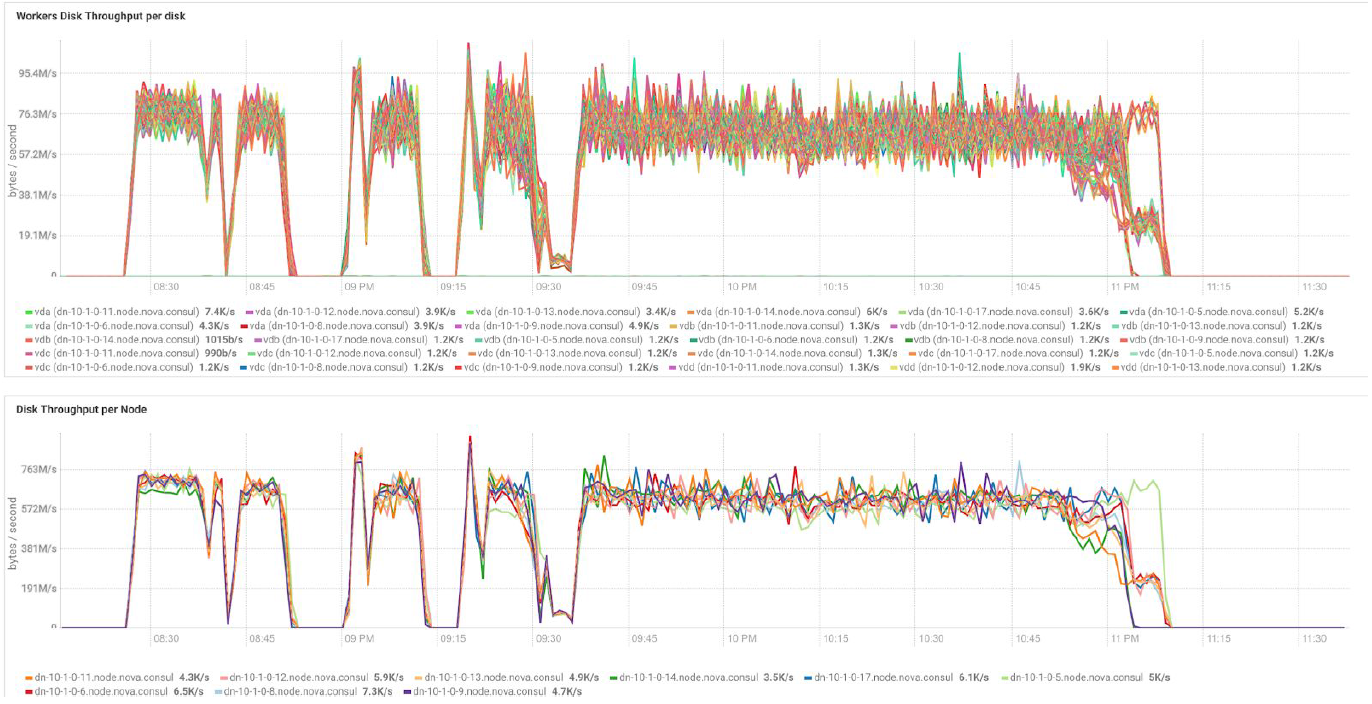
Los cálculos se basan en la configuración mínima de 3 servidores BullSequana S200. Incluye 9 nodos de datos y 3 nodos principales, así como máquinas virtuales reservadas en caso de implementación de protección basada en OpenStack Virtualization. Resultado de la prueba TeraSort: el tamaño de bloque de 512 MB del coeficiente de replicación de tres con cifrado es de 23.1 minutos.
¿Cómo puedo expandir el sistema? Hay varios tipos de extensiones disponibles para Data Lake Engine:
- Nodos de datos: por cada 40 TB de espacio utilizable
- Nodos analíticos con la capacidad de instalar una GPU
- Otras opciones dependiendo de las necesidades del negocio (por ejemplo, si necesita Kafka y similares)
Atos Codex Data Lake Engine incluye tanto los propios servidores como el software preinstalado, incluida una suite con licencia de Cloudera; Hadoop, OpenStack con máquinas virtuales basadas en el kernel RedHat Enterprise Linux, un sistema de replicación de datos y respaldo (incluido el uso del nodo de respaldo y Cloudera BDR - Respaldo y recuperación ante desastres). Atos Codex Data Lake Engine fue la primera solución de virtualización certificada por
Cloudera .
Si está interesado en los detalles, estaremos encantados de responder nuestras preguntas en los comentarios.