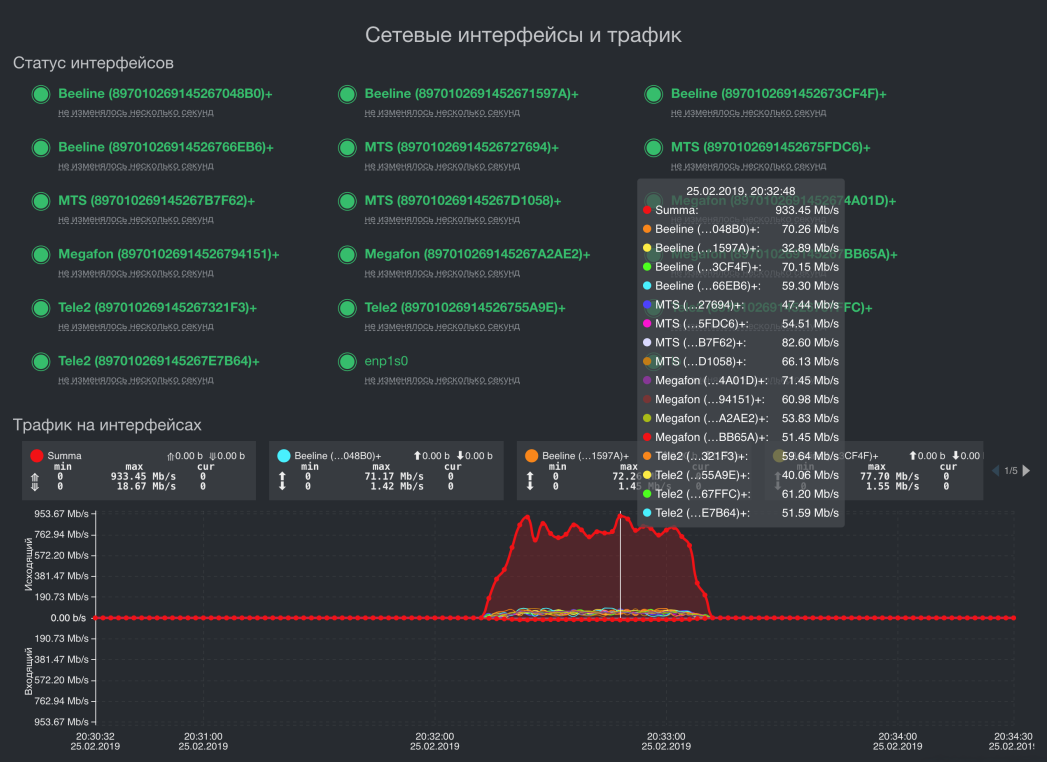
Suma de velocidad en 16 módems de 4 operadores móviles. Velocidad de salida en una transmisión: 933.45 Mbps
Introduccion
Hola Este artículo trata sobre cómo escribimos un nuevo sistema de monitoreo para nosotros mismos. Se diferencia de las existentes por la posibilidad de adquisición síncrona de alta frecuencia de métricas y muy bajo consumo de recursos. La frecuencia de sondeo puede alcanzar 0.1 milisegundos con una precisión de sincronización entre métricas de 10 nanosegundos. Todos los archivos binarios ocupan 6 megabytes.
Sobre el proyecto
Tenemos un producto bastante específico. Producimos una solución integral para resumir el rendimiento y la tolerancia a fallas de los canales de datos. Esto es cuando hay varios canales, por ejemplo, Operador1 (40Mbit / s) + Operador2 (30Mbit / s) + Algo más (5 Mbit / s), el resultado es un canal estable y rápido, cuya velocidad será algo así: (40+ 30 + 5) x0.92 = 75x0.92 = 69 Mbps.
Dichas soluciones tienen demanda cuando la capacidad de cualquier canal es insuficiente. Por ejemplo, transporte, sistemas de videovigilancia y transmisión de video en tiempo real, transmisiones de televisión y radio en vivo, cualquier objeto fuera de la ciudad donde los operadores de telecomunicaciones solo tengan representantes de los Cuatro Grandes, y la velocidad en un módem / canal no es suficiente.
Para cada una de estas áreas, producimos una línea separada de dispositivos, sin embargo, su parte de software es casi la misma y un sistema de monitoreo de alta calidad es uno de sus módulos principales, sin la implementación correcta de la cual el producto sería imposible.
Durante varios años, hemos logrado crear un sistema de monitoreo multinivel, rápido, multiplataforma y liviano. Lo que queremos compartir con una comunidad de buena reputación.
Declaración del problema.
El sistema de monitoreo proporciona métricas para dos clases fundamentalmente diferentes: métricas en tiempo real y todo lo demás. El sistema de monitoreo tenía los siguientes requisitos:
- Adquisición síncrona de alta frecuencia de métricas en tiempo real y su transferencia al sistema de control de comunicación sin demora.
La alta frecuencia y sincronización de diferentes métricas no solo es importante, es vital para el análisis de la entropía de los canales de transmisión de datos. Si hay un retraso promedio de 30 milisegundos en un canal de datos, entonces un error en la sincronización entre las métricas restantes en solo un milisegundo conducirá a la degradación de la velocidad del canal resultante en aproximadamente un 5%. Si cometemos un error en la sincronización de 1 milisegundo en 4 canales, la degradación de la velocidad puede caer fácilmente al 30%. Además, la entropía en los canales cambia muy rápidamente, por lo que si la medimos menos de una vez cada 0.5 milisegundos, en canales rápidos con un pequeño retraso, obtendremos una degradación de alta velocidad. Por supuesto, dicha precisión no es necesaria para todas las métricas y no en todas las condiciones. Cuando el retraso en el canal es de 500 milisegundos, y trabajamos con eso, el error de 1 milisegundo apenas se notará. Además, para las métricas de los sistemas de soporte vital, las frecuencias de sondeo y sincronización de 2 segundos son suficientes para nosotros, sin embargo, el sistema de monitoreo en sí mismo debería poder trabajar con frecuencias de sondeo ultra altas y sincronización métrica ultra precisa. - Mínimo consumo de recursos y una sola pila.
El dispositivo final puede ser un poderoso complejo a bordo que puede analizar la situación en el camino o registrar la biometría de las personas, o una computadora del tamaño de una palma de una sola placa que es usada por un soldado de las fuerzas especiales debajo de la armadura para transmitir video en tiempo real en malas condiciones de comunicación. A pesar de tal variedad de arquitecturas y poder de cómputo, nos gustaría tener la misma pila de software. - Arquitectura de paraguas
Las métricas deben recopilarse y agregarse en el dispositivo final, tener un sistema de almacenamiento local y visualización en tiempo real y retrospectivamente. Si hay comunicación disponible, transfiera datos al sistema de monitoreo central. Cuando no hay conexión, la cola de envío debe acumularse y no consumir RAM. - Una API para la integración en el sistema de monitoreo de un cliente, porque nadie necesita muchos sistemas de monitoreo. El cliente debe recopilar datos de cualquier dispositivo y red en un solo monitoreo.
Que paso
Para cargar el ya impresionante longrid, no daré ejemplos y mediciones de todos los sistemas de monitoreo. Esto sacará otro artículo. Solo diré que no pudimos encontrar un sistema de monitoreo que sea capaz de tomar dos métricas al mismo tiempo con un error de menos de 1 milisegundo y que funcione igualmente eficientemente tanto en una arquitectura ARM con 64 MB de RAM como en una arquitectura x86_64 con 32 GB de RAM. Por lo tanto, decidimos escribir el nuestro, que puede hacer exactamente eso. Esto es lo que tenemos:
Sumar el rendimiento de tres canales para diferentes topologías de red.
Visualización de algunas métricas clave.
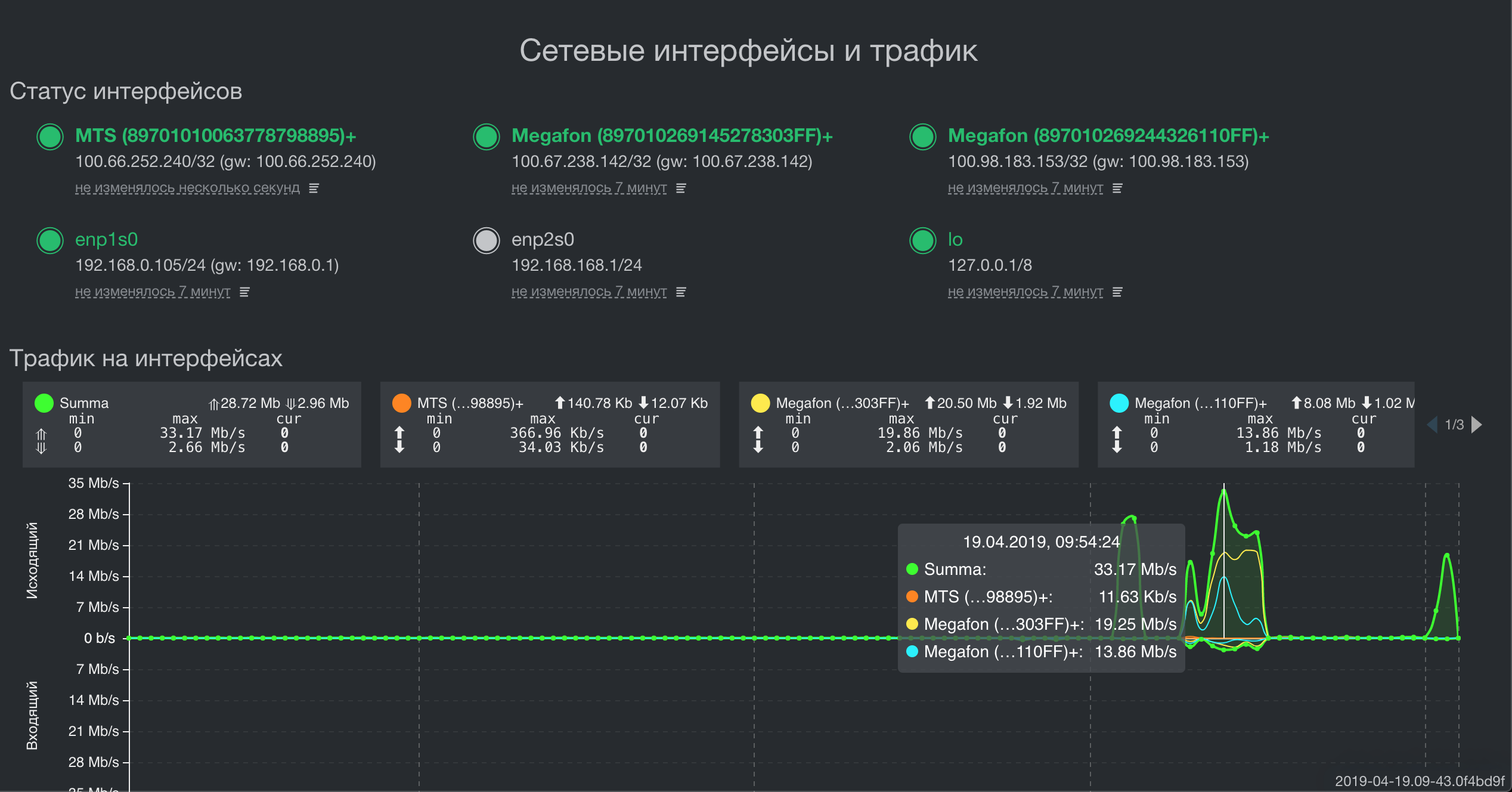
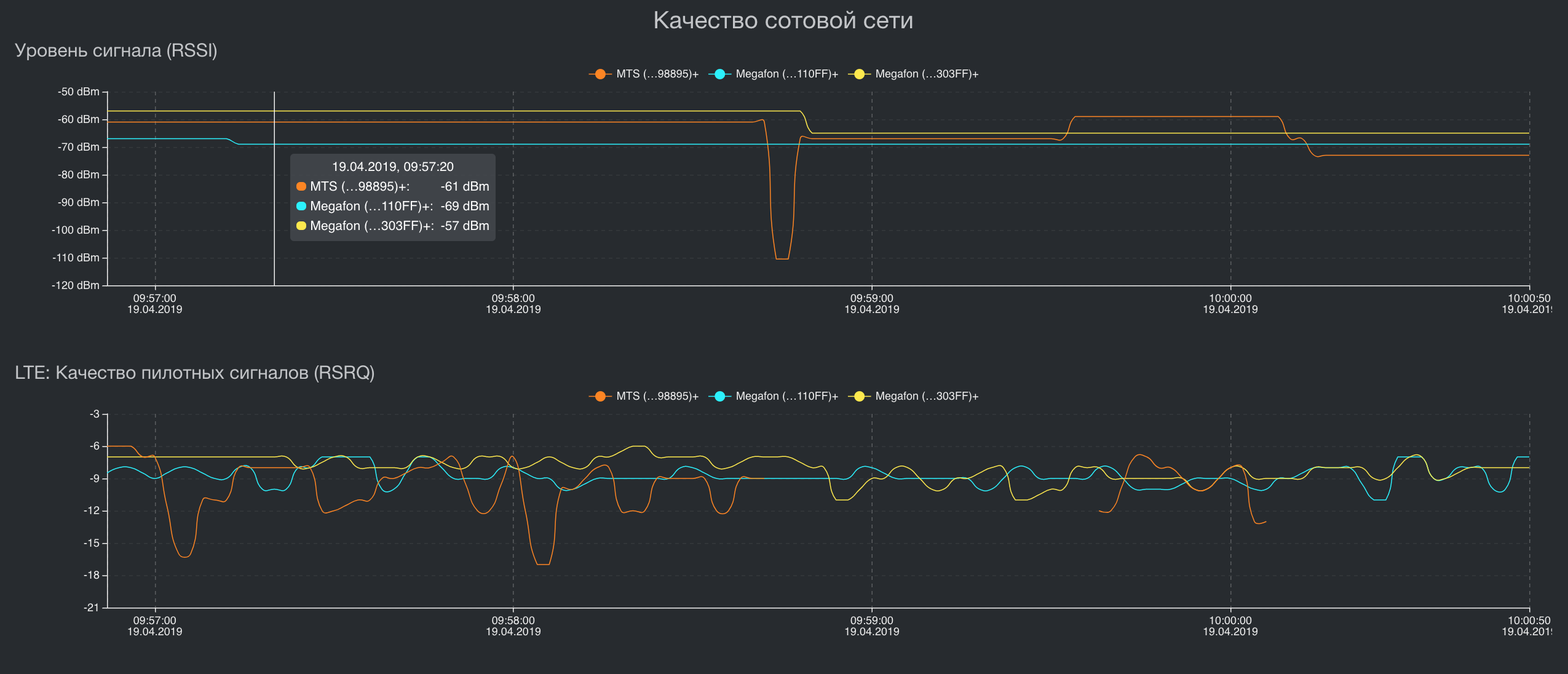
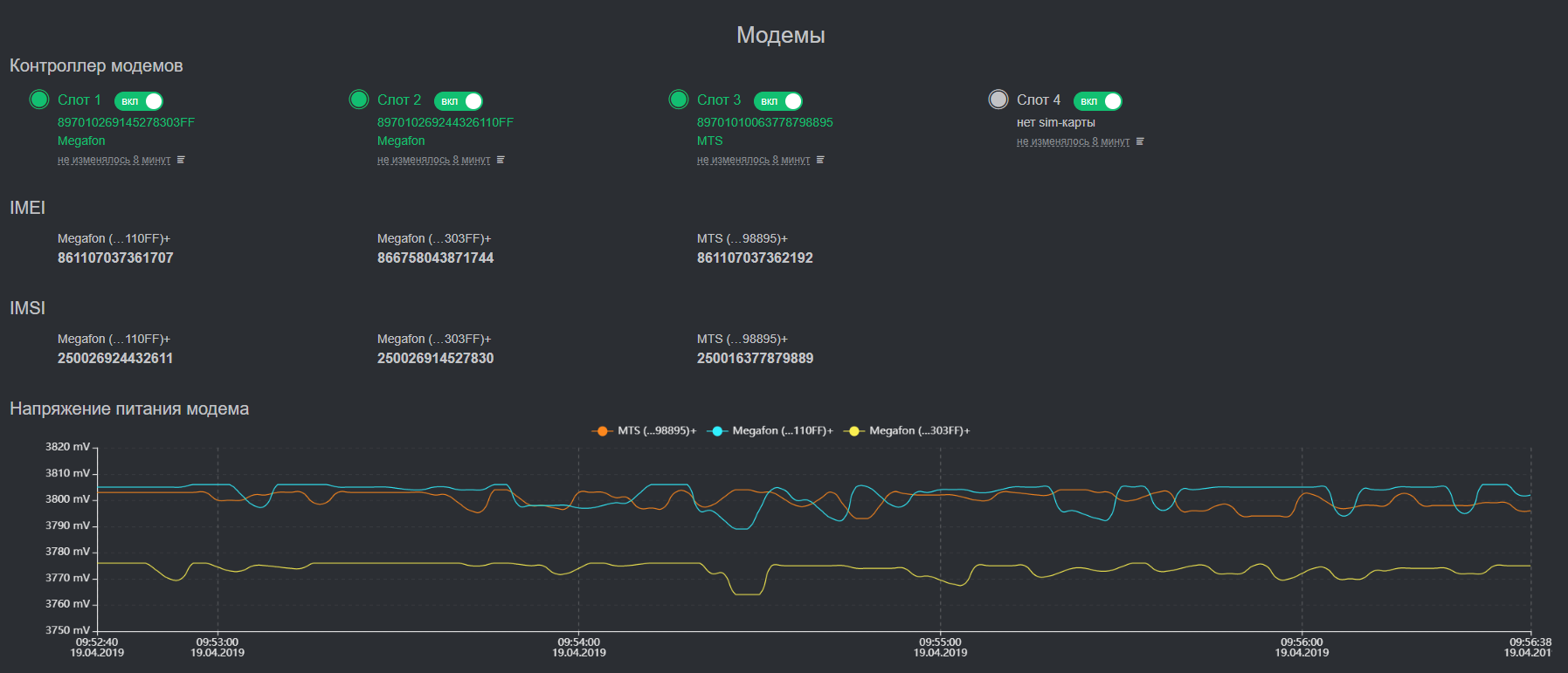
Arquitectura
Como lenguaje principal de programación, tanto en el dispositivo como en el centro de datos, utilizamos Golang. Simplificó enormemente su vida al implementar la multitarea y la capacidad de obtener un binario ejecutable vinculado estáticamente para cada servicio. Como resultado, ahorramos significativamente en recursos, métodos y tráfico de implementación de servicios para dispositivos finales, tiempo de desarrollo y depuración de código.
El sistema se implementa de acuerdo con el principio modular clásico y contiene varios subsistemas:
- Registro de métricas.
Cada métrica es servida por su propia secuencia y sincronizada a través de canales. Logramos una precisión de sincronización de hasta 10 nanosegundos. - Almacenamiento métrico
Elegimos entre escribir nuestro repositorio para series temporales o usar uno de los disponibles. La base de datos es necesaria para los datos retrospectivos, que están sujetos a una visualización posterior, es decir, no tiene datos sobre retrasos en el canal cada 0,5 milisegundos o indicaciones de error en la red de transporte, pero hay una velocidad en cada interfaz cada 500 milisegundos. Además de los altos requisitos para multiplataforma y bajo consumo de recursos, es extremadamente importante para nosotros poder procesar. datos en el mismo lugar donde se almacenan. Esto ahorra tremendamente los recursos informáticos. Desde 2016, hemos estado usando DBMS Tarantool en este proyecto y hasta ahora no vemos un reemplazo para él en el horizonte. Flexible, con consumo óptimo de recursos, soporte técnico más que adecuado. Tarantool también tiene un módulo SIG. Ciertamente no es tan poderoso como PostGIS, pero es suficiente para nuestras tareas de almacenar algunas métricas vinculadas a una ubicación (relevante para el transporte). - Visualización de métricas
Aquí todo es relativamente simple. Tomamos los datos del almacenamiento y los mostramos en tiempo real o retrospectivamente. - Sincronización de datos con un sistema de monitoreo central.
El sistema de monitoreo central recibe datos de todos los dispositivos, los almacena con una retrospectiva dada y los envía a través de la API al sistema de monitoreo del Cliente. A diferencia de los sistemas de monitoreo clásicos, en los que la "cabeza" camina y recopila datos, tenemos el esquema opuesto. Los dispositivos mismos envían datos cuando hay una conexión. Este es un punto muy importante, ya que le permite recibir datos del dispositivo durante esos períodos de tiempo en los que no estaba disponible y no cargar canales y recursos mientras el dispositivo no está disponible. Como sistema de monitoreo central, utilizamos el servidor de monitoreo Influx. A diferencia de los análogos, puede importar datos retrospectivos (es decir, con una marca de tiempo diferente al momento en que se recibió la métrica) Las métricas recopiladas se visualizan mediante un archivo Grafana modificado. Esta pila estándar también se eligió porque tiene API de integración listas para usar con casi cualquier sistema de monitoreo del cliente. - Sincronización de datos con un sistema central de gestión de dispositivos.
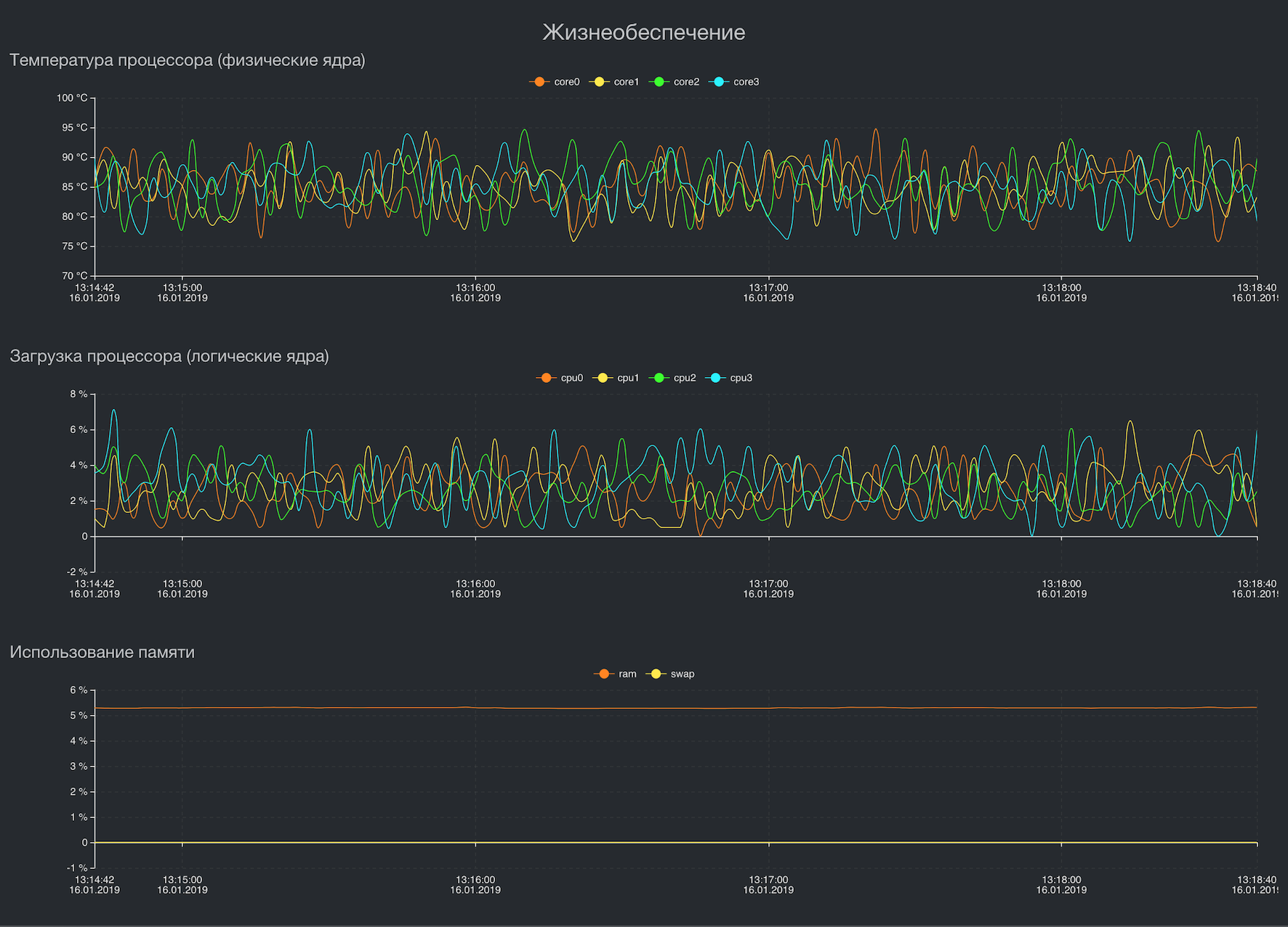
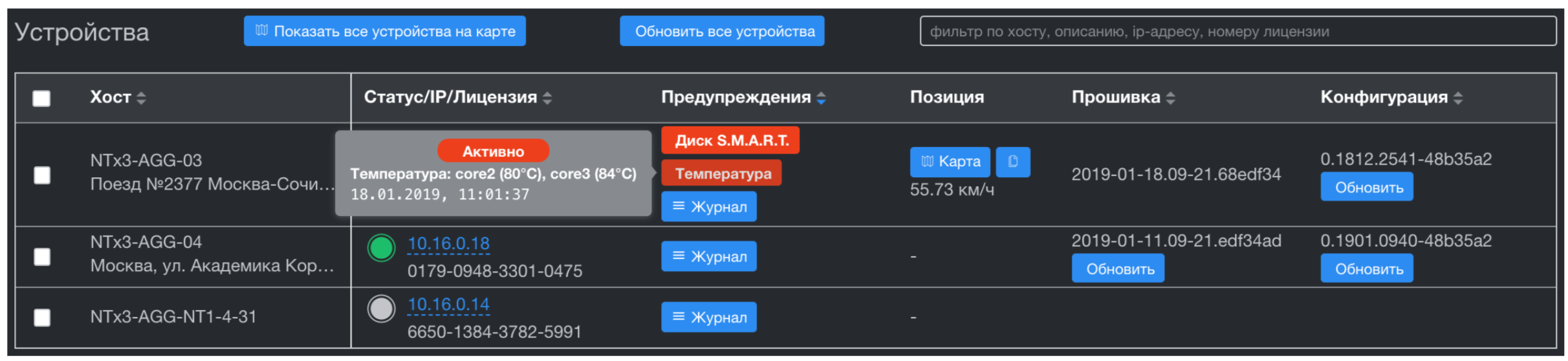
El sistema de administración de dispositivos implementa el aprovisionamiento Zero Touch (actualización de firmware, configuración, etc.) y, a diferencia del sistema de monitoreo, solo recibe problemas del dispositivo. Estos son los desencadenantes de los servicios de vigilancia de hardware a bordo y todas las métricas de los sistemas de soporte vital: temperatura de CPU y SSD, carga de CPU, espacio libre y salud SMART en discos. El subsistema de almacenamiento también se basa en Tarantool. Esto nos da una velocidad significativa en la agregación de series temporales en miles de dispositivos, y también resuelve completamente el problema de la sincronización de datos con estos dispositivos. Tarantool tiene un excelente sistema de colas y entrega garantizada. Obtuvimos esta característica importante de fábrica, ¡genial!
Sistema de gestión de red
Que sigue
Hasta ahora, el eslabón más débil en nuestro país es el sistema central de monitoreo. Se implementa al 99.9% en la pila estándar y tiene una serie de desventajas:
- InfluxDB pierde datos cuando se apaga la alimentación. Como regla general, el Cliente toma rápidamente todo lo que proviene de los dispositivos y no hay datos de más de 5 minutos en la base de datos, pero en el futuro esto puede ser un problema.
- Grafana tiene varios problemas con la agregación de datos y la sincronización de su visualización. El problema más común es cuando la base de datos contiene una serie de tiempo con un intervalo de 2 segundos a partir de, digamos, 00:00:00, y Grafana comienza a mostrar datos en agregación desde +1 segundo. Como resultado, el usuario ve una tabla de baile.
- Exceso de código para la integración API con sistemas de monitoreo de terceros. Se puede hacer mucho más compacto y, por supuesto, reescribir a Go)
Supongo que todos vieron perfectamente cómo se ve Grafana y sin mí conocen sus problemas, por lo tanto, no sobrecargaré la publicación con fotos.
Conclusión
Deliberadamente no describí detalles técnicos, sino que describí solo el diseño de soporte de este sistema. En primer lugar, para describir técnicamente completamente el sistema, se requiere un artículo más. En segundo lugar, no todos estarán interesados. Escriba en los comentarios qué detalles técnicos le gustaría saber.
Si alguien tiene preguntas fuera de este artículo, puedo escribir a a.rodin @ qedr.com